

决策树DecisionTree
模型亮点
- 初始测试集上评分为0.4,调参后测试集上评分为0.8
- 数据清洗方式得当
-----------------------------------------以下为模型具体实现-----------------------------------------
Step1.数据读取
import pandas as pd df=pd.read_csv('bankdebt.csv',index_col=0,header=None) df.columns=['house','marital','income','repayment'] df.head()
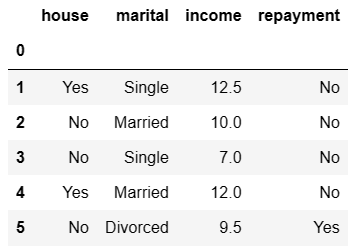
Step2.数据清洗
why 数据清洗?how 数据清洗?
- 决策树不要求标准化
- 分类数据,用0-1表示
- 顺序数据,用1、2、3表示
# 1.是否有房子,Yes->1,No->0 df.loc[df['house']=='Yes','house']=1 df.loc[df['house']=='No','house']=0
# 2.能否偿还贷款,Yes->1,No->0 df.loc[df['repayment']=='Yes','repayment']=1 df.loc[df['repayment']=='No','repayment']=0
# 3.婚姻状态,Single->1,Married->2,Divorced->3 df.loc[df['marital']=='Single','marital']=1 df.loc[df['marital']=='Married','marital']=2 df.loc[df['marital']=='Divorced','marital']=3
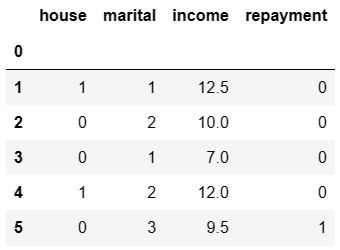
Step3.划分训练集和测试集
why 划分训练集和测试集?
- 把所有样本当作训练集,做过的题都是旧题,都会~
- 把部分样本当作训练集,在新题上做测试,起到检测效果~
from sklearn.model_selection import train_test_split x=df.drop('repayment',axis=1).astype(float) y=df['repayment'].astype(float) x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1)
Step4.启动决策树
how 启动决策树?
- 设定初始化参数
- 拟合训练集数据
from sklearn.tree import DecisionTreeClassifier def tree(n,x_train,y_train): model=DecisionTreeClassifier(max_depth=n) model.fit(x_train,y_train) return model model=tree(1,x_train,y_train) #初始决策树,max_depth设为1
Step5.模型评估
what 模型评估?
- 分类问题,model.score->accuracy_score
- 回归问题,model.score->r2_score
print("-----初始决策树-----") print("训练集上评分:",model.score(x_train,y_train)) def score(model,x_test,y_test): print("测试集上评分:",model.score(x_test,y_test)) score(model,x_test,y_test)

Step6.优化参数
why 优化参数?how 优化参数?
- 以提高测试集上评分
- 参数max_depth,对分类效果影响较大
for n in range(2,11): print("-----决策树最大深度为",n,"-----") model=tree(n,x_train,y_train) score(model,x_test,y_test)

Step7.可视化决策树结构
how 可视化决策树结构?
- https://blog.csdn.net/m0_37634594/article/details/122309924
from sklearn.tree.export import export_text branch_name=['house','marital','income'] export_text(model,feature_names=branch_name)

Step8.保存模型
why 保存模型?how 保存模型?
- for job-lib(工作自由)~
- dump转存模型,以pkl格式
- load加载模型
from sklearn.externals import joblib joblib.dump(model,'d:\DecisionTree.pkl') new_model=joblib.load('d:\DecisionTree.pkl') print("测试集上预测结果为:\n",new_model.predict(x_test))
-END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号