llm 绝对位置编码/相对位置编码/旋转位置编码
位置编码(Positional Encoding, PE)是Transformer架构能够理解序列顺序的关键组件,
Transformer 的核心组件 ——自注意力机制(Self-Attention) 是置换不变性(Permutation Invariant)的,即它本身不感知输入序列中 token 的顺序,因此通过位置编码将序列的顺序信息注入到模型中。
1. 绝对位置编码 (Absolute Positional Encoding, APE)
(1) 固定正弦余弦编码 (Sinusoidal PE)
- 原理:利用正弦(sin)和余弦(cos)函数生成一个固定的、预定义的矩阵。对于位置 pos 和维度 i,其计算公式为:
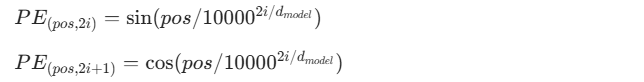
- 特点:
- 无需训练:参数是数学生成的,不占用模型参数量。
- 外推性好:由于是函数生成的,模型在训练时如果只见过长度为 512 的序列,测试时可以处理长度为 1024 的序列(虽然效果会衰减,但不会报错)。
- 相对位置暗示:利用三角恒等式(sin(α+β)=…),绝对位置可以线性表示相对位置信息,但这需要模型自己去学习这种映射关系。
原始论文作者明确指出,他们选择这个函数形式,是因为它允许模型轻松地学习到关注相对位置。
采用cos和sin 的最根本原因,对于任意固定的位置偏移量 k,位置 pos+k的位置编码可以表示为位置 pos的位置编码的线性函数。

模型(特别是自注意力机制中的线性变换层)完全有能力通过一组固定的权重(由 cos(β)cos(β) 和 sin(β)sin(β) 决定),从 PE(pos)PE(pos) 计算出 PE(pos+k)PE(pos+k)。
换句话说,只要模型学会了这组权重,它就能理解“偏移k个位置”这个概念,从而捕捉到相对位置信息。
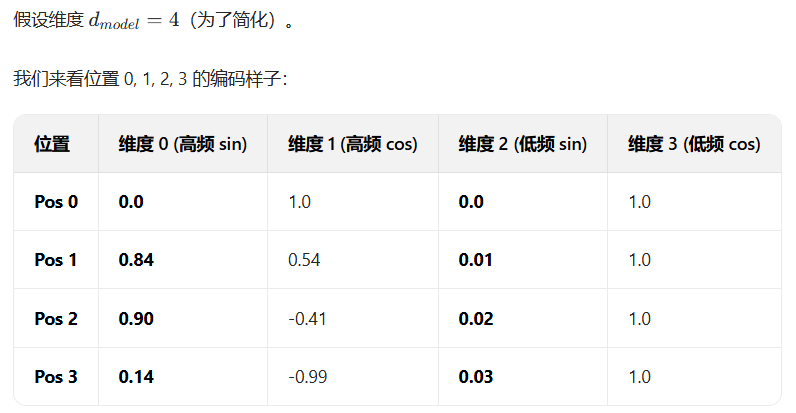
Sin/Cos 编码在设计时,将向量的不同维度分配了不同的频率(Frequency)。
函数是周期性的,但由于频率 ωi在维度 i上呈几何级数变化(10000的幂),不同维度上的周期长度差异巨大。这就好比多个不同频率、不同波长的波叠加在一起。
-
在低维度(i 较小),ωi 很大,周期很长,在这个维度上编码值变化缓慢,可以编码长程的、粗略的位置信息。
-
在高维度(i 较大),ωi 很小,周期很短,编码值变化剧烈,可以编码精细的、短程的位置信息。
(2) 可学习位置编码 (Learned PE)
- 原理:
初始化一个大小为[Max_Seq_Length, Embedding_Dim]的参数矩阵,这个矩阵是随机初始化的,然后作为模型参数的一部分参与梯度下降训练。 - 特点:
- 效果通常更好:在固定长度内,通过训练学到的位置信息往往比人工设计的正弦波更贴合任务。
- 外推性差:如果训练时最大长度是 512,测试时输入 513,模型就没有对应的编码可用了(通常做法是截断或复制最后一个位置的编码,效果很差)。
绝对位置编码的核心问题:
2. 相对位置编码 (Relative Positional Encoding, RPE)
经典方法(如Transformer-XL, T5)
- 原理:
在计算 Attention Score 时,不仅计算 Query 和 Key 的点积,还额外加上一个相对位置偏置项 aij,这个偏置项取决于 i 和 j 的距离。 - 公式逻辑:

- T5:引入了相对位置偏置(Relative Position Bias),在多头注意力中,每个头都有一个可学习的距离偏置表。
- DeBERTa:提出了 Disentangled Attention,将内容(Content)和位置(Position)分开。它使用了两个矩阵:一个是内容注意力矩阵(基于 token 语义),一个是位置注意力矩阵(基于 token 间的距离)。
核心操作:不向输入嵌入添加绝对位置编码,而是在注意力计算过程中,修改注意力分数,引入一个与相对位置偏移(i-j)相关的偏置项。

相对位置编码的优点:
- 平移不变性:如果整句话在文章中上下移动,token 之间的相对距离不变,编码也不变,这符合人类语言习惯。
- 更好的长距离依赖:模型明确知道两个词隔了多远。
缺点:
- 计算开销:在计算 Attention Map 时需要额外的计算步骤,增加了实现复杂度和显存占用。
- 序列长度限制:通常也需要预设一个最大相对距离(例如超过 128 就都算作 128),否则参数量会爆炸。
3. 旋转位置编码 (Rotary Position Embedding, RoPE)
- 核心思想:
将位置编码看作是向量空间中的旋转操作。
它通过复数域(Complex Numbers)或高维空间的旋转矩阵,将位置信息 “旋转” 进 Query 和 Key 向量中。 - 原理:
对于每个 token 的向量,将其切分为实部和虚部(或者前后两半维度)。通过矩阵乘法,将 Query 和 Key 进行旋转。
关键数学性质在于:内积的旋转不变性。
⟨R(θ)q, R(θ+m)k⟩ = ⟨q, R(m)k⟩
这意味着,当 Query 和 Key 都经过 RoPE 编码后,旋转后的 Q 和 K 做点积时结果中自然包含了相对位置 m 的信息。

- 为什么叫 Rotary?
因为它利用了 eiθ=cosθ+isinθ 的欧拉公式性质,使得位置的增加对应于向量在复平面上的旋转角度增加。
-
核心操作:
-
将词嵌入向量视为一组二维向量对(即复数形式)。
-
对每一对分量,根据其绝对位置
pos,进行一个旋转。 -
旋转角度θ与位置
pos和维度i成比例:θ = pos * base^{-2i/d}。base是一个很大的常数(如10000)。
-
-
数学上:对于位置
m和n的查询q和键k,它们的内积<f(q, m), f(k, n)>只与(m-n)有关,即只依赖于相对位置。

RoPE 的革命性优势:
- 绝对位置编码的形式,相对位置编码的效果:
它在实现上是对每个位置的向量进行独立编码(像 APE),但在最终计算 Attention Score 时,起作用的是它们之间的相对角度差(像 RPE)。 - 完美的外推性 (Extrapolation):
这是 RoPE 最大的杀手锏。如果模型在 2048 长度下训练,当输入 4096 长度时,RoPE 依然可以计算出合理的旋转角度(虽然没见过,但数学上是连续的)。配合 NTK-Aware Scaling 等技术,RoPE 可以让 LLaMA 轻松处理 100k 以上的超长文本。 - 无额外参数:
它是通过矩阵运算生成的,不增加模型参数。
对比总结
| 特性 | 绝对位置编码 (如Sinusoidal) | 相对位置编码 (如T5式) | 旋转位置编码 (RoPE) |
|---|---|---|---|
| 核心思想 | 为每个位置分配唯一编码,相对位置信息需要模型自身进行学习 | 直接建模标记间的相对距离 | 通过旋转嵌入注入位置,使内积仅依赖相对位置 |
| 注入方式 | 加法,在输入或每层 | 加法偏置,在注意力分数 | 乘法旋转,在查询和键向量上 |
| 外推性 | 较差 | 较好 | 极好 (配合技巧) |
| 实现复杂度 | 简单 | 中等 | 中等 |
| 流行程度 | 早期Transformer基础 | 在需要精确相对位置的任务中常用 | 当前大模型主流 |
Qwen3上下文长度32K -> 128K扩展
Qwen3 8B原生支持32K上下文,但通过位置外推技术(Position Interpolation)可以处理更长的序列:
-
不截断:整个序列(如128K)会被输入模型
-
位置重映射:通过数学变换将[0, 128K)的位置映射到模型熟悉的[0, 32K)范围
-
注意力计算:模型对全部token计算注意力,但位置编码经过了调整
| 方面 | 32K原生 | 128K扩展 | 注意事项 |
|---|---|---|---|
| 推理速度 | 快 | 较慢(约降低30-50%) | 注意力计算复杂度增加 |
| 显存占用 | 较低 | 显著增加(~4倍) | 需要更多GPU内存 |
| 长文档精度 | 一般 | 前32K最佳,后续可能衰减 | 可能出现"中间迷失"现象 |
| 成本 | 低 | 较高 | 需要更多计算资源 |
位置范围 相对效果 原因
0-32K ~100% 原生训练范围
32K-64K ~85-95% 轻度位置压缩
64K-96K ~70-85% 中度位置压缩
96K-128K ~60-75% 重度位置压缩
# 使用Qwen3的官方长上下文支持
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-8B-Instruct",
torch_dtype="auto",
device_map="auto",
# 启用长上下文支持
use_flash_attn=True,
trust_remote_code=True
)
# 明确指定最大长度
response = model.chat(
tokenizer,
"长文档内容...",
max_length=131072, # 指定128K
truncation=True
)
YaRN(Yet another RoPE extensioN method)是一种针对基于旋转位置编码(RoPE)的大语言模型(如 LLaMA、GPT - NeoX、Qwen 等)的上下文窗口高效扩展方法,核心是通过改进 RoPE 的频率插值与注意力缩放,以极低微调成本将上下文窗口扩展至原生长度的数倍(如 Qwen32B 从 32K 扩至 131K)
YaRN 本质是 NTK - by - parts 插值的升级版,核心由两大关键技术构成:
- NTK - by - parts 插值:将位置编码的频率按不同频段拆分处理。低频段(对应长距离依赖)采用 NTK - aware 缩放,保证长距离相对位置信息不丢失;高频段(对应短距离细节)采用常规插值,保留局部语义连贯性,避免长文本扩展时的性能断崖式下降。
- 注意力预 softmax 缩放:在计算注意力权重的 softmax 前,对注意力分数进行自适应缩放,补偿长距离注意力衰减问题,确保模型在长序列中仍能有效捕捉全局依赖,同时避免梯度消失或爆炸。
- 动态 β 缩放(推理时):可根据输入序列长度,动态调整 RoPE 的旋转角度参数 β,实现无需额外微调即可进一步扩展上下文窗口,适配不同长度的文本输入。
实现流程
- 预训练适配:无需重新预训练,仅需在原有预训练模型基础上,修改 RoPE 的频率计算逻辑,引入 NTK - by - parts 插值公式。
- 高效微调
- 数据:仅使用原始预训练数据量的 0.1%(约数十亿 token)的长文本数据(如 64K 长度)进行微调。
- 步骤:训练步数仅为传统 Position Interpolation(PI)方法的 1/2.5(如扩展至 64K 仅需 400 步),大幅降低计算成本。
- 目标:让模型快速适配新的位置编码规则,学会在长序列中保持语义理解与生成能力。
- 推理扩展:微调后模型可支持 “训练短、测试长”,如用 64K 数据训练的模型可稳定推理 128K 长度文本;结合动态 β 缩放,还能进一步提升至 131K 等更长序列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号