1. 风景视频类型(无需对口型)
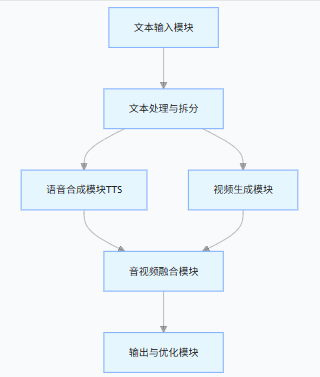
- 职责:接收用户的原始文本(支持纯文本、带情绪标注的文本,比如
[欢快]今天天气很好),做基础校验(非空、长度限制)。
- 设计要点:支持文本分段(比如按句号 / 逗号拆分,匹配视频镜头节奏)、保留文本的情绪 / 语速标注。
- 职责:将原始文本拆分为 “视频描述文本” 和 “语音合成文本”(可复用同一文本,也可分开),并对齐时间轴。
- 例:原始文本 “清晨的阳光洒在湖面,微风拂过,波光粼粼” → 拆分后,每句对应视频的一个镜头,同时作为语音合成的分句,确保语音节奏和视频画面匹配。
- 选型:优先用阿里云的语音合成(TTS)(和通义万相同生态,调用更便捷),也可选用讯飞 TTS、百度 TTS。
- 核心能力:
- 支持文本转语音(可选音色、语速、情绪);
- 返回语音文件(mp3/wav)和精准的语音时长(用于对齐视频)。
- 核心调整:
- 基于拆分后的文本片段生成对应时长的视频(比如某段文本语音时长 8 秒,就要求通义万相生成 8 秒的视频片段);
- 通义万相 API 调用时,需指定
duration参数(视频时长),确保每个视频片段的时长和对应语音片段时长一致。
- 核心工具:使用
ffmpeg(行业标准,跨平台)将生成的语音文件和视频文件合并,确保音画同步。
- 职责:
- 校验最终视频的音画同步性(比如检测语音和视频时长是否匹配,偏差超过 0.5 秒则调整);
- 支持视频格式转换(mp4/webm 等)、分辨率调整;
- 提供预览 / 下载接口。
人物叙述类视频(需要对口型)
声音分析:把音频拆解成音素和节奏。
嘴型生成:AI 模型根据音素预测嘴唇动作,再贴合到视频人脸。
阿里的 EchoMimic 系列 (根据人物底座和音频,生成带手势和口型的半身视频)链接:https://www.modelscope.cn/models/BadToBest/EchoMimicV2
虚拟主播口播大模型架构的核心是 **“LLM 中枢 + 多模态协同”**,通过分层设计实现模块化复用与灵活扩展。关键在于时序对齐(音素 - 唇形 - 帧)与跨模态融合(语音 - 表情 - 动作)
| 问题 | 原因 | 解决方法 |
|---|
| 口型不同步 |
音素时间戳误差 |
用 MFA 重新对齐,或手动调整 Viseme 映射表 |
| 语音生硬 |
缺乏情感建模 |
在 TTS 中加入情绪特征(如 ChatTTS 的emotion参数) |
| 实时延迟高 |
模型推理慢 |
使用轻量化模型(如 Qwen-1.8B)+ GPU 加速 |
- 核心职责:生成口播脚本、理解上下文、控制情感与节奏
- 工具选型:Qwen-1.8B / 通义千问(轻量化)、GPT-4o(复杂场景)
- 关键能力:支持情绪标注(如
[兴奋])、停顿控制([break:500ms])、口语化改写
- 核心职责:生成自然语音,输出音素时间戳(用于唇形同步)
- 工具选型:
- 实时场景:ChatTTS(开源,低延迟)、阿里云 TTS(高音质)
- 批量场景:VITS+Vocos(自定义音色)
- 核心职责:将音素时间戳映射为虚拟人唇形序列,实现口型精准对齐
- 工具选型:
- 轻量实时:Wav2Lip-GAN(GPU 延迟 < 50ms)
- 高精度:MuseTalk(端到端唇形生成)、OmniTalker(音视频一体化)
- 关键技术:音素→Viseme 映射表(中文 8-10 个基础口型)、协同发音处理
Wav2Lip 的输入是音频文件(如 WAV/MP3/M4A),而非音素文本;音素级处理由模型内部自动完成,无需手动提供音素序列。
-
必填输入
- 人脸源:图片或视频(含清晰唇部)
- 目标音频:任意 FFmpeg 支持的音频文件(推荐 16kHz 单声道 WAV)
-
内部处理
- 音频端:自动提取 Mel 频谱特征,通过 Speech Encoder 编码为时序特征
- 音素映射:模型隐式学习音素 - 唇形关联,无需用户显式提供音素文本
- 输出:生成与音频同步的唇部动作视频
# Wav2Lip实时唇形同步(命令行示例)
git clone https://github.com/Rudrabha/Wav2Lip.git
cd Wav2Lip
pip install -r requirements.txt
# 生成对口型视频(输入:虚拟人底图 + 语音)
python inference.py \
--checkpoint_path checkpoints/wav2lip_gan.pth \
--face "virtual_host.png" \
--audio "output.wav" \
--outfile "lip_sync.mp4" \
--fps 30 # 匹配直播帧率
- 核心职责:融合唇形、表情、动作,生成最终虚拟人视频
- 工具选型:
- 实时渲染:Unity/Unreal Engine(高质量)、Live2D(2D 虚拟人)
- 轻量化:D-ID(API 调用)、PaddleGAN(表情增强)
- 关键优化:GPU 加速渲染(FP16)、多线程处理(唇形 + 表情并行)
- 实时直播:通过 RTMP 协议推流到抖音 / 快手(使用 ffmpeg)
- 批量生成:保存为 MP4 格式,支持分辨率调整(720p/1080p)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号