Qwen-VL-8B-Instruct(多模态大语言模型 / 图生文)
模型:https://www.modelscope.cn/models/Qwen/Qwen3-VL-8B-Instruct
1. 多模态理解
-
图像理解:识别物体、场景、文字(OCR)
-
多图推理:支持多张图像输入进行综合推理
-
文档解析:表格、图表、公式识别
-
细粒度理解:支持区域级别的视觉定位(通过文本边界框描述)
2. 对话交互
-
指令跟随:遵循复杂的多模态指令
-
上下文学习:支持少样本学习
-
多轮对话:保持对话上下文的一致性
架构:
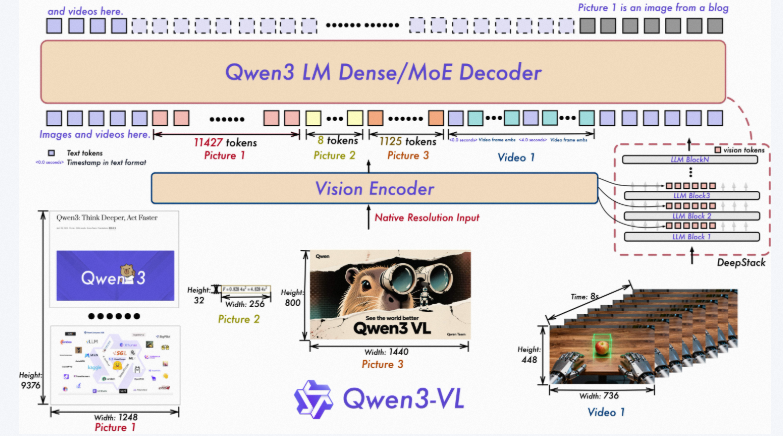
-
交错 MRoPE:通过鲁棒的位置嵌入,在时间、宽度和高度上进行全频分配,增强长时间范围的视频推理。
-
DeepStack:融合多级 ViT 特征以捕捉细粒度细节并锐化图像-文本对齐。
-
文本-时间戳对齐:超越 T-RoPE,实现精确的时间戳定位,以加强视频时间建模。
[图像] → ViT编码器 → 视觉特征
[文本] → 语言模型 → 文本特征
↓
特征融合模块
↓
解码器生成回答
ViT(Vision Transformer(视觉变换器))
-
Transformer架构在计算机视觉领域的创新应用
-
将图像处理成一系列的“图像块”(patches),类似文本中的单词
-
用处理自然语言的思路来处理图像

 浙公网安备 33010602011771号
浙公网安备 33010602011771号