llama-factory 各参数详解
llama-factory web页面:
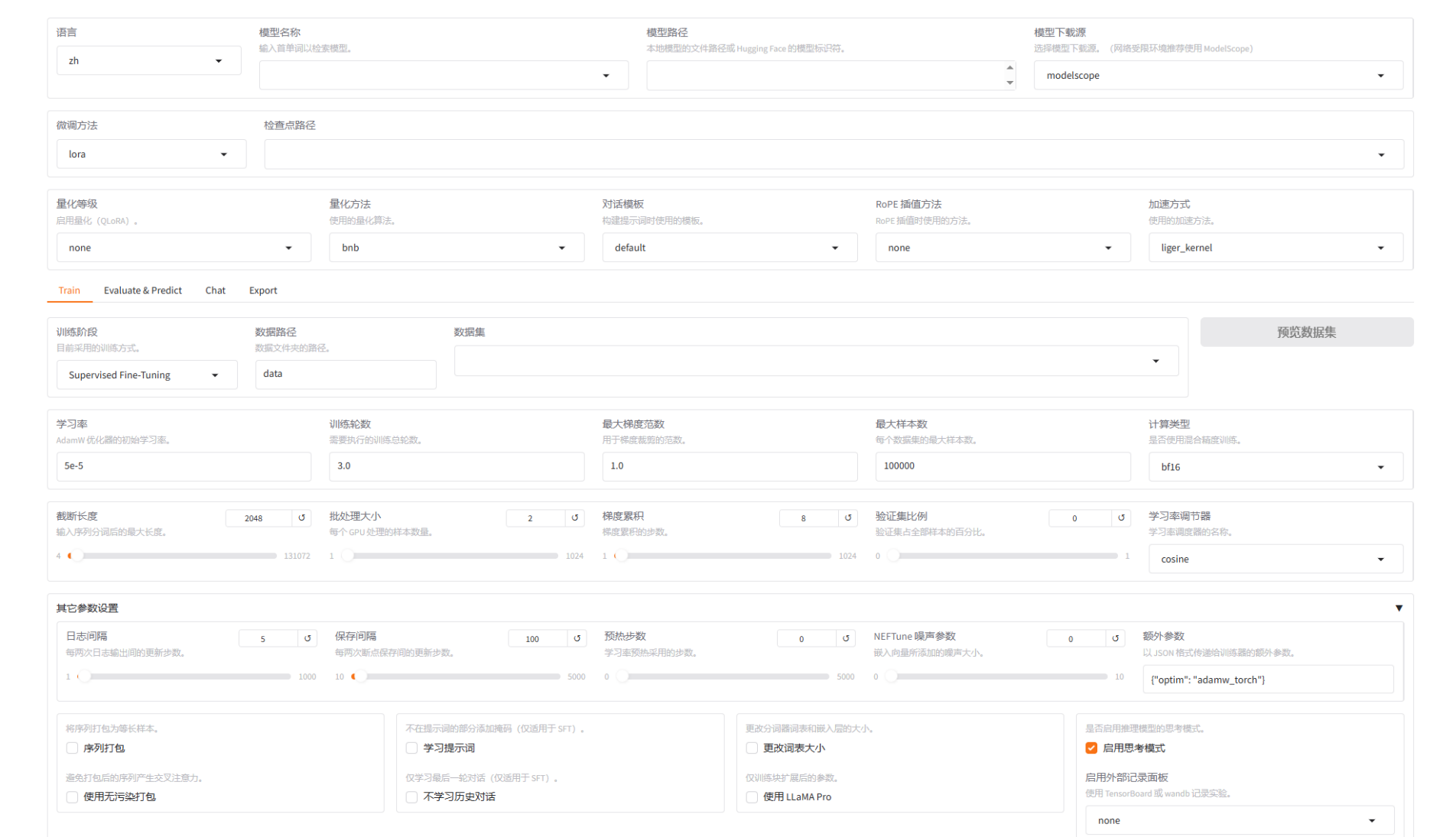
1. 模型与数据配置
| 参数/选项 | 详细说明 |
|---|---|
| 模型名称或路径 | - 作用:指定要微调的基座模型。可以是 Hugging Face 上的模型标识符(如 meta-llama/Llama-2-7b-chat-hf),也可以是本地模型文件夹的路径。 |
| - 注意:需要确保 LLaMA Factory 支持该模型架构,并且你有权限访问该模型。 | |
| 适配器名称或路径 | - 作用:如果之前进行过 LoRA 微调,可以在这里加载已有的 LoRA 适配器权重,用于继续训练或进行推理。 |
| 微调方法 | - 作用:选择核心的微调策略。 |
| - Full:全参数微调。消耗资源巨大,通常只在资源充足且需要最大程度改变模型时使用。 | |
| - Freeze:冻结微调。只训练模型的部分层(如最后几层),其余层参数冻结。是一种轻量级方法。 | |
| - LoRA:最常用。在原始模型旁增加低秩适配器,只训练这些小的适配器参数,极大减少显存和计算需求。 | |
| - QLoRA:LoRA 的量化版本。将基座模型以 4-bit 等量化方式加载,进一步降低显存需求,使得在消费级显卡上微调大模型成为可能。 | |
| 数据集 | - 作用:选择用于训练和评估的数据集。 |
- 格式:支持多种格式,如 alpaca_gpt4_en(指令微调常用格式)、自定义的 JSON 文件等。 |
|
| - 组成:通常需要指定训练集和评估集。 |
| 参数名称 | 详细说明 |
|---|---|
stage |
微调阶段,可选以下类型: |
pt(Pretraining):预训练阶段。 |
|
sft(Supervised Fine-tuning):监督微调阶段。 |
|
rm(Reward Modeling):奖励建模阶段。 |
|
ppo(Proximal Policy Optimization):基于奖励的强化微调阶段。 |
|
dpo(Direct Preference Optimization):偏好优化阶段。 |
|
kto(Knowledge Transfer Optimization):知识迁移优化阶段。 |
|
do_train |
是否执行训练。true 表示执行训练,false 表示跳过训练过程,仅用于推理或验证。 |
数据集
| 参数名称 | 解释 |
|---|---|
dataset |
在 dataset_info.json 中预设的数据集名称,以 , 分隔启用多个数据集。 |
template |
数据处理模板。设置为 llama3,表明按照适配 Llama 3 模型的格式预处理数据。 |
cutoff_len |
输入序列的最大长度。2048 表示限制每条样本的最大 token 数。 |
max_samples |
数据集中的最大样本数量,设置为 1000,用于减少训练规模或调试。 |
overwrite_cache |
是否覆盖缓存的预处理数据,true 表示重新处理。 |
preprocessing_num_workers |
数据预处理的并行线程数,设置为 16,提高处理效率。 |
2. 训练配置
| 参数 | 详细说明 |
|---|---|
| 学习率 | - 作用:控制模型参数更新的步长。是最重要的超参数之一。 |
- 值域:通常是一个很小的值,如 1e-4 到 5e-5。太大可能导致训练不稳定(损失爆炸),太小则收敛缓慢。 |
|
| 训练轮数 | - 作用:整个训练数据集会被模型“看过”多少次。 |
| - 选择:并非越多越好。太多会导致过拟合,即模型在训练集上表现很好,但在新数据上表现很差。需要配合评估损失来观察。 | |
| 最大样本数 | - 作用:限制每个训练轮次中使用的最大样本数量。用于快速测试或在小规模数据上实验。 |
| 学习率调度器 | - 作用:动态调整学习率的策略。 |
| - Linear:线性衰减,学习率从初始值线性下降到 0。 | |
| - Cosine:余弦衰减,学习率按余弦曲线平滑下降,是常用且效果较好的选择。 | |
| - Constant:保持学习率不变。 | |
| 最大梯度范数 | - 作用:梯度裁剪的阈值。当梯度的范数超过此值时,会将其缩放至此范数。 |
- 目的:防止梯度爆炸,稳定训练过程。通常设置为 1.0 或 0.5。 |
|
| 验证步数 | - 作用:每训练多少步,就在验证集上评估一次并计算损失。 |
| 保存步数 | - 作用:每训练多少步,就保存一次模型检查点(通常是 LoRA 适配器)。 |
| 优化器 | - 作用:选择用于更新模型参数的算法。 |
| - AdamW:最常用的优化器,是 Adam 的一个变种,能更好地处理权重衰减。 | |
| - AdamW 8bit:AdamW 的 8 位量化版本,可以节省一些显存。 | |
| - SGD:随机梯度下降,更古老但稳定的算法。 |
| 参数名称 | 典型值 | 解释 |
|---|---|---|
per_device_train_batch_size |
1 | 每张 GPU 上的训练批量大小,影响梯度的估计质量。较大的批量能提供更稳定的梯度,适合较大的学习率;较小的批量可能导致噪声较大。小批量大小(例如 1)需要配合gradient_accumulation_steps才能等效于更大的批量。 |
gradient_accumulation_steps |
8 | 梯度累积步数,累积梯度可等效增大批量大小,影响模型的收敛性和泛化性能。 |
learning_rate |
2e-4 | 初始学习率,最关键的超参数之一,直接影响训练的稳定性和收敛性。 |
num_train_epochs |
3.0 | 训练总轮数,微调过程中,模型通常已经有良好的初始化,因此较少的轮数往往就足够。 |
lr_scheduler_type |
cosine | 学习率调度策略,决定了学习率如何变化;cosine 表示采用余弦退火策略,能够有效降低后期的学习率,通常对大模型训练表现较好。 |
warmup_ratio |
0.1 | 学习率预热阶段的比例,预热阶段可以防止训练一开始因为学习率过高而导致的梯度爆炸;0.1表示前 10%的训练步数用于学习率预热。 |
bf16 |
true | 是否启用 bfloat16 混合精度训练,启用可减小内存占用并加速训练。 |
ddp_timeout |
180000000 | 分布式数据并行的超时时间,设置为非常大的值,确保分布式训练不会因为超时失败。 |
3. LoRA/QLoRA 配置
当微调方法选择 LoRA 或 QLoRA 时,这些参数变得至关重要。
| 参数 | 详细说明 |
|---|---|
| LoRA Rank | - 作用:LoRA 适配器中矩阵的秩(r)。它决定了适配器的复杂度和参数量。 |
- 值域:通常是 8, 16, 32, 64。值越大,能力越强,但参数量和计算量也越大。对于大多数任务,8 或 16 已经足够。 |
|
| LoRA Alpha | - 作用:LoRA 适配器输出结果的缩放因子。可以理解为适配器对原始模型影响力的控制参数。 |
- 经验法则:通常设置为 LoRA Rank 的 1 到 2 倍(如 rank=8, alpha=16)。这被认为是一个好的起点。 |
|
| Dropout | - 作用:在 LoRA 适配器中应用 Dropout 的比例,是一种防止过拟合的正则化手段。 |
- 值域:0 到 1。在小数据集上可以设置一个较小的值(如 0.1),在大数据集上可以设为 0。 |
|
| LoRA 目标模块 | - 作用:指定在模型的哪些部分添加 LoRA 适配器。这是 LoRA 微调最关键的配置之一。 |
- 常见值:对于 Llama 类模型,通常是 q_proj, v_proj, k_proj, o_proj(注意力机制的核心投影层)。有时也会加上 gate_proj, up_proj, down_proj(FFN 层)。 |
|
| - All:如果选择 All,框架会自动为所有符合条件的线性层添加 LoRA。 | |
| 量化比特数 | - 作用:QLoRA 特有。指定基座模型的量化精度。 |
- 选项:4-bit 是最常用的,在性能和显存节省之间取得了很好的平衡。8-bit 也是一个选项。 |
4. 生成/推理配置
| 参数 | 详细说明 |
|---|---|
| Do Sample | - 作用:是否使用采样策略。如果为 False,则使用贪心解码(总是选择概率最大的下一个词),生成结果确定但可能枯燥。 |
| Temperature | - 作用:调整采样随机性的“温度”。 |
- 值域:0 到 1 或更高。 |
|
- ~0:输出更确定,倾向于高概率词。 |
|
- ~1:平衡的随机性。 |
|
- >1:输出更随机,更具创造性,但也可能不连贯。 |
|
| Top-p | - 作用:核采样。从累积概率超过 p 的最小词集合中采样。 |
- 效果:能动态控制候选词的范围,避免选择那些概率极低的词,同时保持多样性。通常与 Temperature 一起使用。常用值为 0.9。 |
|
| Top-k | - 作用:从概率最高的 k 个词中进行采样。 |
- 效果:另一种限制采样范围的方法。Top-p 通常比 Top-k 更灵活和有效。 |
|
| Max New Tokens | - 作用:生成文本的最大长度(Token 数量)。 |
| Repetition Penalty | - 作用:对已生成过的词进行惩罚,降低其再次被生成的概率,有效减少重复。 |
- 值域:通常 1.0 表示无惩罚,>1.0(如 1.1 到 1.2)表示施加惩罚。 |
数据集格式
llama-factory支持的数据集格式:
数据集通常是一个 JSON 文件(如 .json、.jsonl),每条数据包含一个对话或指令样本。
支持以下字段:
-
instruction:指令描述(可选,如果使用input和output) -
input:输入内容(可选) -
output:期望输出 -
messages:对话列表(用于多轮对话) -
system:系统提示(可选) -
history:历史对话(可选,用于多轮)
监督训练
单轮指令格式
格式1:
{ "instruction": "翻译成英文", "input": "今天天气真好", "output": "The weather is nice today." }
-
instruction:任务指令 -
input:任务输入(可为空) -
output:期望输出
格式2:(ChatML 格式)
{ "messages": [ {"role": "user", "content": "今天天气真好,请翻译成英文。"}, {"role": "assistant", "content": "The weather is nice today."} ] }
-
必须包含
user和assistant交替的对话。 -
可包含
system消息。
多轮对话格式
格式1:
{ "messages": [ {"role": "system", "content": "你是一个翻译助手。"}, {"role": "user", "content": "翻译:今天天气真好"}, {"role": "assistant", "content": "The weather is nice today."}, {"role": "user", "content": "改成过去时"}, {"role": "assistant", "content": "The weather was nice today."} ] }
严格按 user → assistant → user → assistant 顺序。
格式2:
{ "history": [ ["今天天气真好", "The weather is nice today."] ], "input": "改成过去时", "output": "The weather was nice today." }
-
history:列表形式,每轮是[用户输入, 助手回复]。 -
input:当前轮用户输入。 -
output:当前轮助手回复。
数据集目录通常包含:
-
-
dataset.json(或.jsonl) -
可拆分:
train.json、validation.json、test.json
-
无监督训练
格式1:JSONL
{"text": "这是第一个文档的内容,可以是任意长度的纯文本。\n可以包含换行符和标点。"}
{"text": "这是第二个文档。无监督训练只需要纯文本,不需要指令或回复。"}
{"text": "中文、英文或混合文本都可以。模型会根据上下文学习语言模式。"}
每个 JSON 对象包含一个 text 字段
参数含义
{'loss': 1.2992, ...} # 当前批次的训练损失
{'train_loss': 0.0, ...} # 最终平均训练损失(这里有问题,正常不应为0)
# 评估过程
{'eval_loss': 1.275} # 验证集上的损失
{'learning_rate': 1.0732e-05, ...} # 当前学习率
{'epoch': 2.10, ...} # 当前训练轮数(含小数表示进度)
{'throughput': 1226.07} # 吞吐量(tokens/秒)
{'train_samples_per_second': 80145.936} # 样本处理速度
{'train_steps_per_second': 5120.435} # 训练步数速度
{'trainable params: 5,046,272'} # 可训练参数(LoRA参数)
{'all params: 601,096,192'} # 总参数(原始模型+LoRA)
{'trainable%: 0.8395'} # 可训练参数占比
{'num_input_tokens_seen': 700704} # 处理的总token数
{'total_flos': 1744403GF'} # 总浮点运算次数(1.74×10^18)
'Upcasting trainable params to float32' # LoRA参数用FP32训练
'Fine-tuning method: LoRA' # 使用LoRA方法
'Loaded adapter(s): saves/Qwen3-0.6B-Base/lora/...' # 加载已有LoRA权重
'per_device_train_batch_size': 4 # 每个GPU的物理批次大小
'gradient_accumulation_steps': 8 # 梯度累积步数
实际有效批次大小 =per_device_train_batch_size×gradient_accumulation_steps×GPU数量
yaml文件配置
# 基础模型配置 model_name_or_path: Qwen/Qwen2.5-VL-7B-Instruct # 作用:指定预训练模型名称或本地路径 # 支持:HuggingFace模型ID或本地目录 image_max_pixels: 262144 # 作用:图像最大像素数(512×512) # 计算:512×512=262144 # 影响:图像分辨率,减少显存占用 video_max_pixels: 16384 # 作用:视频最大像素数(128×128) # 计算:128×128=16384 # 注意:视频通常需要更多显存 trust_remote_code: true # 作用:信任远程代码执行 # 必要性:某些模型需要自定义代码加载 #LORA配置 stage: sft # 作用:训练阶段 # 选项:pretrain(预训练)、sft(监督微调)、rm(奖励模型)、ppo(强化学习) do_train: true # 作用:是否执行训练 finetuning_type: lora # 作用:微调类型 # 选项:full(全参数)、lora(LoRA)、freeze(冻结)、none(仅推理) lora_rank: 8 # 作用:LoRA秩(低秩矩阵的维度) # 范围:通常4-64,越小参数量越少,能力可能下降 lora_target: all # 作用:LoRA适配的模块 # 选项:all(所有线性层)、q_proj,v_proj(仅注意力层)、自定义 # 影响:all参数量最多,但效果可能最好 # 数据集配置 dataset: mllm_demo,identity,alpaca_en_demo # 作用:使用的数据集名称 # 格式:dataset_info.json中定义的key,逗号分隔 template: qwen2_vl # 作用:对话模板 # 必要性:不同模型需要不同对话格式 # 选项:llama3、qwen、chatml等 cutoff_len: 2048 # 作用:序列最大长度 # 影响:超过部分截断,影响长文本处理 max_samples: 1000 # 作用:每个数据集最大样本数 # 用途:快速测试或限制数据量 overwrite_cache: true # 作用:覆盖已存在的缓存 # 用途:数据更新后重新预处理 preprocessing_num_workers: 16 # 作用:数据预处理的进程数 # 优化:CPU密集型任务,通常设CPU核心数 dataloader_num_workers: 4 # 作用:数据加载的进程数 # 优化:IO密集型任务,通常设4-8 #输出配置 output_dir: saves/qwen2_5vl-7b/lora/sft # 作用:输出目录 # 结构:包含模型权重、日志、配置 logging_steps: 10 # 作用:每多少训练步记录一次日志 # 监控:损失、学习率等指标 save_steps: 500 # 作用:每多少步保存一次检查点 # 容灾:训练中断后可恢复 plot_loss: true # 作用:绘制损失曲线图 # 输出:training_loss.png overwrite_output_dir: true # 作用:覆盖已有输出目录 # 警告:会删除之前的内容 save_only_model: false # 作用:是否只保存模型权重 # true:只保存pytorch_model.bin # false:保存完整检查点(含优化器状态) report_to: none # 作用:实验跟踪工具 # 选项:wandb、tensorboard、mlflow等 #训练参数配置 per_device_train_batch_size: 1 # 作用:每个GPU的物理批次大小 # 显存:决定单次前向传播的样本数 gradient_accumulation_steps: 8 # 作用:梯度累积步数 # 计算:有效批次 = 1 × 8 = 8 # 显存:用8倍时间换8倍显存节省 learning_rate: 1.0e-4 # 作用:学习率 # 范围:LoRA通常1e-4到5e-4,全参数微调更小 num_train_epochs: 3.0 # 作用:训练轮数 # 经验:SFT通常3-10轮 lr_scheduler_type: cosine # 作用:学习率调度器 # 选项:linear、cosine、cosine_with_restarts、constant # cosine:余弦衰减,平滑收敛 warmup_ratio: 0.1 # 作用:学习率预热比例 # 计算:前10%的步数从0线性增加到目标学习率 # 目的:稳定训练初期 bf16: true # 作用:使用bfloat16混合精度 # 要求:Ampere架构以上GPU(A100/3090/4090等) # 替代:fp16(V100等旧卡) ddp_timeout: 180000000 # 作用:分布式训练超时时间(秒) # 默认:1800秒,这里设很大(约5.7年) # 用途:禁用超时,用于长时间训练 # 评估参数配置 val_size: 0.1 # 作用:验证集比例 # 计算:从训练数据中划分10%作为验证集 per_device_eval_batch_size: 1 # 作用:评估时的批次大小 # 注意:通常比训练批次大,因为不计算梯度 eval_strategy: steps # 作用:评估策略 # 选项:steps(按步数)、epoch(按轮数)、no(不评估) eval_steps: 500 # 作用:每多少训练步评估一次
数据集template模板
# 原始数据 { "instruction": "解释人工智能", "input": "", "output": "人工智能是..." } # 应用 template 后 """ <|im_start|>user 解释人工智能<|im_end|> <|im_start|>assistant 人工智能是...<|im_end|> """
不同模型所需的模板:
# Llama 3 模板 <|begin_of_text|><|start_header_id|>user<|end_header_id|> {instruction}<|eot_id|><|start_header_id|>assistant<|end_header_id|> {output}<|eot_id|> # Qwen 模板 <|im_start|>user {instruction}<|im_end|> <|im_start|>assistant {output}<|im_end|> # ChatGLM 模板 [gMASK]sop<|user|> {instruction} <|assistant|> {output} # 添加特殊分隔符 bos_token: "<s>" # 开始符 eos_token: "</s>" # 结束符 pad_token: "[PAD]" # 填充符 # 角色标记 user_token: "Human:" assistant_token: "Assistant:" system_token: "System:"
# 正确模板:模型能识别对话结构
# 错误模板:模型学习混乱的格式,难以收敛
# 训练时用的模板必须与推理时一致
# 否则生成的内容格式错误

 浙公网安备 33010602011771号
浙公网安备 33010602011771号