langChain Function Calling/tool/mcp详解
Tool
Tool 是一个核心抽象概念,它代表了一个可以被大型语言模型(LLM)调用的功能或服务。
-
上层抽象:是 LangChain 框架中的概念
-
应用层封装:将函数调用、API 调用等各种能力统一封装成标准接口
-
框架概念:LangChain 提供的组织和管理外部能力的方式
Tools 通常会多次调用大模型进行整合。这正是 Agent 工作模式的核心特点。
LLM 本身是强大的推理引擎,但它们存在固有的局限性:
-
知识截止性: 它们的知识仅限于训练数据,无法获取最新信息。
-
缺乏执行能力: 它们无法执行外部操作,如查询数据库、调用 API、操作文件等。
-
无法进行精确计算: 它们可能不擅长进行复杂的数学运算或代码执行。
将各种功能封装成统一的 Tool 接口,LangChain 使得 LLM 能够根据用户的请求,智能地选择并调用相应的 Tool 来完成任务。
1. Tool 的核心组成部分
一个标准的 Tool 通常包含以下几个关键部分:
-
名称(name):
-
一个简短、描述性的字符串,用于标识这个 Tool。
-
LLM 通过名称来识别和选择要使用的 Tool。因此,名称应该清晰明了,例如
"search","calculator","sql_db_query"。
-
-
描述(description):
-
一段详细的文本,说明这个 Tool 的功能、用途以及最重要的——何时应该使用它。
-
描述是 Tool 的灵魂。LLM 的决策严重依赖于描述。一个模糊的描述会导致 LLM 错误地选择或忽略该 Tool。例如,一个计算器的描述应该是:“当需要回答数学问题时非常有用。输入应该是一个数学表达式。”
-
-
函数(func)或可调用对象(coroutine):
-
实际执行任务的代码。这可以是一个普通的 Python 函数,也可以是一个异步函数。
-
当 LLM 决定调用某个 Tool 时,LangChain 就会执行这个函数,并将函数的返回值作为 Tool 的执行结果返回给 LLM。
-
2. 如何创建和使用 Tool
LangChain 提供了多种灵活的方式来创建和使用 Tool。
方法一:使用 @tool 装饰器(最简洁)
from langchain.agents import tool import requests @tool def get_weather(city: str) -> str: """根据城市名获取当前的天气信息。""" # 这里是一个模拟的 API 调用 # 实际应用中,你会调用真实的天气 API if city == "北京": return "北京:晴,25°C" elif city == "上海": return "上海:多云,28°C" else: return f"无法找到{city}的天气信息" # 现在 get_weather 就是一个 Tool 对象了 print(get_weather.name) # 输出:get_weather print(get_weather.description) # 输出:get_weather(city: str) -> str - 根据城市名获取当前的天气信息。
方法二:继承 BaseTool 类(最灵活)
当需要对 Tool 的行为进行更精细的控制时(例如,自定义输入验证、更复杂的逻辑),可以继承 BaseTool 类。
from langchain.tools import BaseTool from pydantic import Field class CustomCalculatorTool(BaseTool): name: str = "advanced_calculator" description: str = "用于执行复杂数学计算的计算器。输入必须是一个完整的数学表达式。" precision: int = Field(default=2, description="结果保留的小数位数") def _run(self, expression: str) -> str: """同步执行方法""" try: # 警告:在生产环境中,直接使用 eval 是危险的,这里仅作演示。 result = eval(expression) return f"结果是:{round(result, self.precision)}" except Exception as e: return f"计算错误:{e}" async def _arun(self, expression: str) -> str: """异步执行方法(可选)""" # 如果不需要异步,可以直接抛出 NotImplementedError return self._run(expression) # 使用自定义 Tool calc_tool = CustomCalculatorTool(precision=4)
方法三:使用 Tool.from_function 方法
这是一种介于装饰器和继承类之间的方式,可以直接将一个现有的函数包装成 Tool。
def search_web(query: str) -> str: # 模拟网络搜索 return f"关于 '{query}' 的搜索结果:..." # 创建 Tool search_tool = Tool.from_function( func=search_web, name="web_search", description="当需要搜索最新或未知信息时使用此工具。" )
示例:
tool 本身不会自动被调用,它们需要在一个 Agent 的框架下工作。Agent 是 LLM 的“大脑”,它负责:
-
理解用户意图。
-
规划行动步骤。
-
从可用的 Tools 中选择最合适的一个。
-
调用该 Tool 并获取结果。
-
根据结果决定下一步:是直接回答用户,还是继续调用其他 Tool。
from langchain.agents import initialize_agent, AgentType from langchain_openai import ChatOpenAI from langchain.agents import tool # 1. 定义 Tools @tool def get_weather(city: str) -> str: """根据城市名获取当前的天气信息。""" # ... (实现同上) return f"{city}的天气是..." @tool def search_web(query: str) -> str: """用于搜索最新信息。""" # ... (实现同上) return f"搜索结果:..." # 2. 初始化 LLM 和 Tools 列表 llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0) tools = [get_weather, search_web] # 3. 创建 Agent # ZERO_SHOT_REACT_DESCRIPTION 是一种常用的代理类型,它鼓励 LLM 进行一步步的推理(Reasoning)和行动(Acting)。 agent = initialize_agent( tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True # 开启详细日志,可以看到代理的思考过程 ) # 4. 运行! result = agent.run("北京今天的天气怎么样?然后再帮我搜一下北京有什么室内活动推荐。") print(result)
Thought: 用户问了两个问题,一个是北京的天气,一个是室内活动推荐。我需要按顺序处理。首先,我需要获取北京的天气。有一个叫 `get_weather` 的工具可以做到这一点。
Action: get_weather
Action Input: {"city": "北京"}
Observation: 北京:晴,25°C
Thought: 好的,我已经得到了北京的天气。现在用户还想要室内活动推荐。这需要最新的信息,我应该使用搜索工具。
Action: search_web
Action Input: {"query": "北京 室内活动 推荐"}
Observation: 搜索结果:... (关于北京室内活动的信息)
Thought: 我现在有了两个问题的答案,可以综合起来回复用户了。
Final Answer: 北京今天天气晴朗,25°C。关于室内活动,根据搜索结果显示,... (综合后的回答)
# LangChain 自动:
# 1. 思考:调用大模型:需要先获取天气信息
# 2. 行动:调用天气工具
# 3. 观察:北京今天下雨
# 4. 思考:调用大模型:既然下雨,应该搜索室内活动
# 5. 行动:调用搜索工具
# 6. 最终回答
Function Calling
Function Calling(函数调用):Function Calling 不是让 LLM 直接执行代码,而是让 LLM 理解用户请求,并识别出需要调用哪个外部函数,同时生成符合函数要求的参数。
-
底层机制:是 LLM 本身具备的一种能力
-
协议标准:一种让 LLM 识别何时应该调用外部函数、调用哪个函数、以及传递什么参数的标准化方式
-
模型原生能力:由 OpenAI 等模型提供商在模型层面实现
import openai import json import requests # 1. 定义真实的天气函数 def get_weather(city: str) -> str: """实际获取天气数据的函数""" # 这里应该是真实的 API 调用,简化为例 weather_data = { "北京": "晴,25°C,湿度40%", "上海": "多云,28°C,湿度60%", "广州": "雨,30°C,湿度80%" } return weather_data.get(city, f"未找到{city}的天气信息") # 2. 定义函数 schema(给模型看的说明书) weather_function_schema = { "name": "get_weather", "description": "根据城市名称获取当前天气信息", "parameters": { "type": "object", "properties": { "city": { "type": "string", "description": "城市名称,如北京、上海" } }, "required": ["city"], # 必填参数 "additionalProperties": False } }
def process_user_query(user_query: str): """处理用户查询的主函数""" print("=== 第一次调用:识别意图和参数 ===") # 第一次调用:让模型判断是否需要调用函数 response = openai.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "user", "content": user_query} ], functions=[weather_function_schema], # 告诉模型可用的函数 function_call="auto", # 让模型自动决定是否调用函数 temperature=0 ) message = response.choices[0].message print(f"模型原始响应: {message}") return message
def execute_function_call(message): """执行函数调用""" # 检查模型是否决定调用函数 if hasattr(message, 'function_call') and message.function_call: function_name = message.function_call.name arguments = json.loads(message.function_call.arguments) print(f"\n=== 执行函数调用 ===") print(f"函数名: {function_name}") print(f"参数: {arguments}") # 根据函数名调用对应的真实函数 if function_name == "get_weather": city = arguments.get("city") function_response = get_weather(city) print(f"函数执行结果: {function_response}") return function_name, function_response else: print("模型决定不调用函数,直接回答") return None, message.content
def generate_final_answer(user_query, message, function_name, function_response): """生成最终回答""" print(f"\n=== 第二次调用:生成最终回答 ===") # 准备对话历史 messages = [ {"role": "user", "content": user_query} ] if function_name: # 如果调用了函数,包含函数调用和结果 messages.append(message) # 包含 function_call 的助理消息 messages.append({ "role": "function", "name": function_name, "content": function_response }) else: # 如果没有调用函数,直接使用第一次的回复 return function_response # 第二次调用:让模型基于函数结果生成友好回答 second_response = openai.chat.completions.create( model="gpt-3.5-turbo", messages=messages, temperature=0 ) final_answer = second_response.choices[0].message.content print(f"最终回答: {final_answer}") return final_answer
def main(): # 用户查询 user_query = "北京今天天气怎么样?" print(f"用户查询: {user_query}") # 1. 第一次调用:识别意图 message = process_user_query(user_query) # 2. 执行函数调用 function_name, function_response = execute_function_call(message) # 3. 生成最终回答 final_answer = generate_final_answer(user_query, message, function_name, function_response) return final_answer # 运行示例 if __name__ == "__main__": result = main()
MCP(Model Context Protocol)
MCP(Model Context Protocol) 是一个开放协议,用于在 AI 应用程序(如 Claude)和外部数据源、工具之间建立标准化的连接方式。
-
标准化接口:为 AI 模型访问外部资源和工具定义统一标准
-
解耦设计:将工具/数据源开发与具体 AI 应用分离
-
跨平台兼容:一次开发,多处使用
解决问题:
问题1:供应商锁定
问题2:重复开发
问题3:维护困难
-
每个平台版本更新可能导致工具失效
-
安全更新需要在多个地方重复进行
-
文档和测试需要维护多份
# 传统方式:直接绑定到特定平台 # LangChain 工具 from langchain.tools import Tool @tool def my_tool(): # 这个工具只能在 LangChain 中使用 pass # 如果想把工具移到其他框架,需要重写 # 同一个工具需要为不同平台重复实现 # 对于 LangChain class LangChainWeatherTool(BaseTool): # LangChain 特定的实现 pass # 对于 LlamaIndex class LlamaIndexWeatherTool(BaseTool): # LlamaIndex 特定的实现 pass # 对于自定义应用 class CustomWeatherTool: # 自定义实现 pass
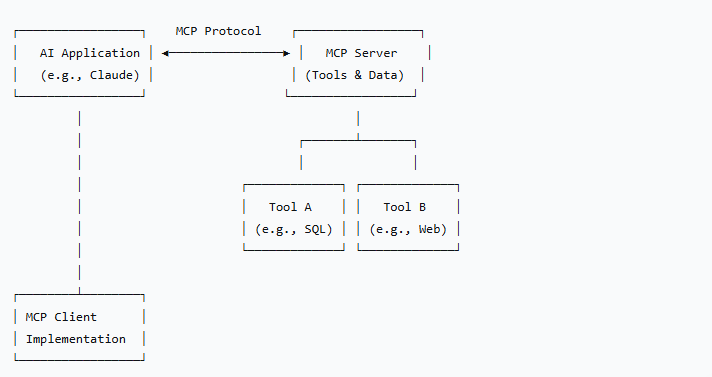
MCP 使用 JSON-RPC 2.0 进行通信,支持两种模式:
1. STDIO 模式(本地)
// AI 应用 → MCP 服务器 { "jsonrpc": "2.0", "id": 1, "method": "tools/call", "params": { "name": "weather", "arguments": {"city": "Beijing"} } } // MCP 服务器 → AI 应用 { "jsonrpc": "2.0", "id": 1, "result": { "content": [{"type": "text", "text": "Beijing: Sunny, 25°C"}] } }
2. HTTP 模式(远程)
# MCP 服务器作为 HTTP 服务运行 curl -X POST http://localhost:3000/mcp \ -H "Content-Type: application/json" \ -d '{ "jsonrpc": "2.0", "id": 1, "method": "tools/list", "params": {} }'
三者区别
| 特性维度 | Function Calling | Tools (LangChain) | MCP (Model Context Protocol) |
|---|---|---|---|
| 本质 | 底层协议/机制 | 应用层框架抽象 | 跨应用层协议标准 |
| 抽象层级 | 低层级 | 中层级 | 高层级/跨平台 |
| 核心目标 | 让LLM可靠调用外部函数 | 在LangChain中构建AI代理 | 标准化AI与外部服务的连接 |
| 供应商绑定 | 中等(主要OpenAI) | 高(绑定LangChain) | 低(开放协议) |
| 开发模式 | 手动流程控制 | 声明式框架集成 | 协议驱动标准化 |
| 技术实现 | Function Calling | Tools (LangChain) | MCP (Model Context Protocol) |
|---|---|---|---|
| 通信协议 | OpenAI API规范 | Python类和方法调用 | JSON-RPC 2.0 (STDIO/HTTP) |
| 集成方式 | 直接API调用 | 装饰器/类继承 | MCP服务器客户端模式 |
| 工具定义 | JSON Schema | Python函数/类 | 标准化接口定义 |
| 执行流程 | 手动多步调用 | Agent自动管理 | 协议驱动的请求响应 |
tools相比function calling,是对function calling进行了封装,作为基础类,增加了异步调用。
mcp是将工具和模型进行了解耦,可以跨平台部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号