Privacy-Preserving Deep Learning

1.introduction
在本文中,我们设计、实现和评估了一个实用的系统,该系统使多方能够针对给定目标共同学习一个精确的神经网络模型,而无需共享其输入数据集。我们利用了一个事实,即现代深度学习中使用的优化算法,即基于随机梯度下降的优化算法,可以并行化并异步执行。我们的系统允许参与者在自己的数据集上独立训练,并在训练期间有选择地共享其模型关键参数的小子集。这在效用/隐私权衡空间中提供了一个有吸引力的点:参与者在保持各自数据的隐私的同时仍然受益于其他参与者的模型,从而提高了他们的学习准确性,而不仅仅是他们自己的输入可以实现的。我们证明了我们在基准数据集上进行深度学习的准确性。
我们的贡献。我们设计、实现并评估了一个实用的协作式深度学习系统,该系统在实用性和隐私性之间提供了一个有吸引力的折衷方案。
我们的系统使多个参与者能够根据自己的输入学习神经网络模型,而无需共享这些输入,但可以从同时学习类似模型的其他参与者那里获益。
我们的关键技术创新是在培训期间选择性共享模型参数。在随机梯度下降过程中,这种参数共享与局部参数更新交织在一起,允许参与者从其他参与者的模型中获益,而无需显式共享训练输入。我们的方法独立于用于为特定任务构建模型的特定算法。
因此,在不改变核心协议的情况下,它可以很容易地适应神经网络训练的未来发展。
选择性参数共享是有效的,因为作为现代神经网络训练基础的随机梯度下降算法可以并行化和异步运行。
它们对不可靠的参数更新、竞赛条件、参与者退出等具有鲁棒性。使用从其他参与者处获得的值更新一小部分参数可使每个参与者在寻找最佳参数的过程中避免局部极小值。可以调整参数共享以控制交换的信息量和结果模型的准确性之间的权衡
我们在两个数据集MNIST和SVHN上对我们的系统进行了实验评估,这两个数据集用作图像分类算法的基准。在我们的系统中,分布式参与者生成的模型的准确性接近于集中式的、侵犯隐私的情况,即一方持有整个数据集并使用它来训练模型。对于MNIST数据集,当参与者共享其10%(分别为1%)的参数时,我们获得了99.14%的准确率(分别为98.71%)。相比之下,集中式隐私侵犯模型的最大准确率为99.17%,而参与者单独学习的非协作模型的最大准确率为93.16%。对于SVHN数据集,当参与者共享其10%(1%)的参数时,我们达到93.12%(89.86%)的准确率。相比之下,集中式、违反隐私的模型的最大准确率为92.99%,非协作模型的最大准确率为81.82%。
即使没有额外的保护,我们的系统已经实现了比任何现有方法都强得多的隐私,效用损失可以忽略不计。我们系统中唯一的泄漏不是直接显示所有训练数据,而是通过一小部分神经网络参数间接泄漏。为了最大限度地减少这种泄漏,我们展示了如何使用稀疏向量技术将差异隐私应用于参数更新,从而减少由于参数选择(即选择共享哪些参数)和共享参数值而造成的隐私损失。然后,我们定量地衡量准确性和隐私之间的权衡。
4 Distributed Selective SGD
我们的方法的核心是一个分布式、协作的深度学习协议,它依赖于以下观察结果:
(i)梯度下降过程中对不同参数的更新本质上是独立的,
(ii)不同的训练数据集产生不同的参数,
(iii)不同的特征对目标函数的贡献并不相等。
我们的选择性随机梯度下降(选择性SGD或SSGD)协议实现了与传统SGD相当的精度,但在每次学习迭代中更新的参数要少1个甚至2个数量级。
选择性参数更新。选择性参数更新背后的主要直觉是,在SGD过程中,某些参数对神经网络目标函数的贡献更大,因此在给定的训练迭代过程中会经历更大的更新。梯度值取决于训练样本(小批量),并随样本的不同而变化。此外,输入数据的某些特征比其他特征更重要,而帮助计算这些特征的参数在学习过程中更为关键,并且会发生更大的变化。
在选择性SGD中,学习者选择在每次迭代中更新的一小部分参数。这种选择可以是完全随机的,但明智的策略是选择当前值远离其局部最优值的参数,即具有较大梯度的参数。
最后,以与(1)中相同的方式更新参数向量ws,以便不在S中的参数保持不变。我们将θ与参数总数之比作为参数选择率。
Distributed collaborative learning.
分布式选择性SGD假设两名或两名以上参与者同时独立培训。在每一轮本地培训后,学员异步他们为某些参数计算的梯度会彼此共享。每个参与者完全控制要共享的梯度和频率。为给定参数计算的所有梯度之和决定了朝向参数局部最优值的全局下降幅度(“局部”这里指的是参数值的空间,并不意味着仅限于单个参与者)。因此,参与者可以从彼此的培训数据中获益,而不会实际看到这些数据-并生成更精确的模型,这些模型本可以独立学习,仅限于他们自己的训练数据。参与者可以直接交换梯度,也可以通过可信的中央服务器,甚至可以使用安全多方计算“不知不觉地”交换梯度,模拟隐藏每次更新来源的可信服务器的功能。出于本讨论的目的,我们假设一个中心服务器的抽象,参与者将梯度异步上传到该服务器。服务器将所有渐变添加到相应参数的值中。每个参与者从服务器下载一部分参数,并使用它们更新其本地模型。给定参数的下载标准可以是更新的频率或最近程度,也可以是添加到该参数的渐变的移动平均值。
5 System Architecture
5.1概述
图2展示了我们协作式深度学习系统的主要组件和协议。我们假设有N个参与者,每个参与者都有一个可用于培训的本地私有数据集。所有参与者事先就共同的网络架构和共同的学习目标达成一致。我们假设存在一个参数服务器,负责维护各方可用的最新参数值。这个参数服务器是一个抽象,可以由实际的服务器实现,也可以由分布式系统仿真。
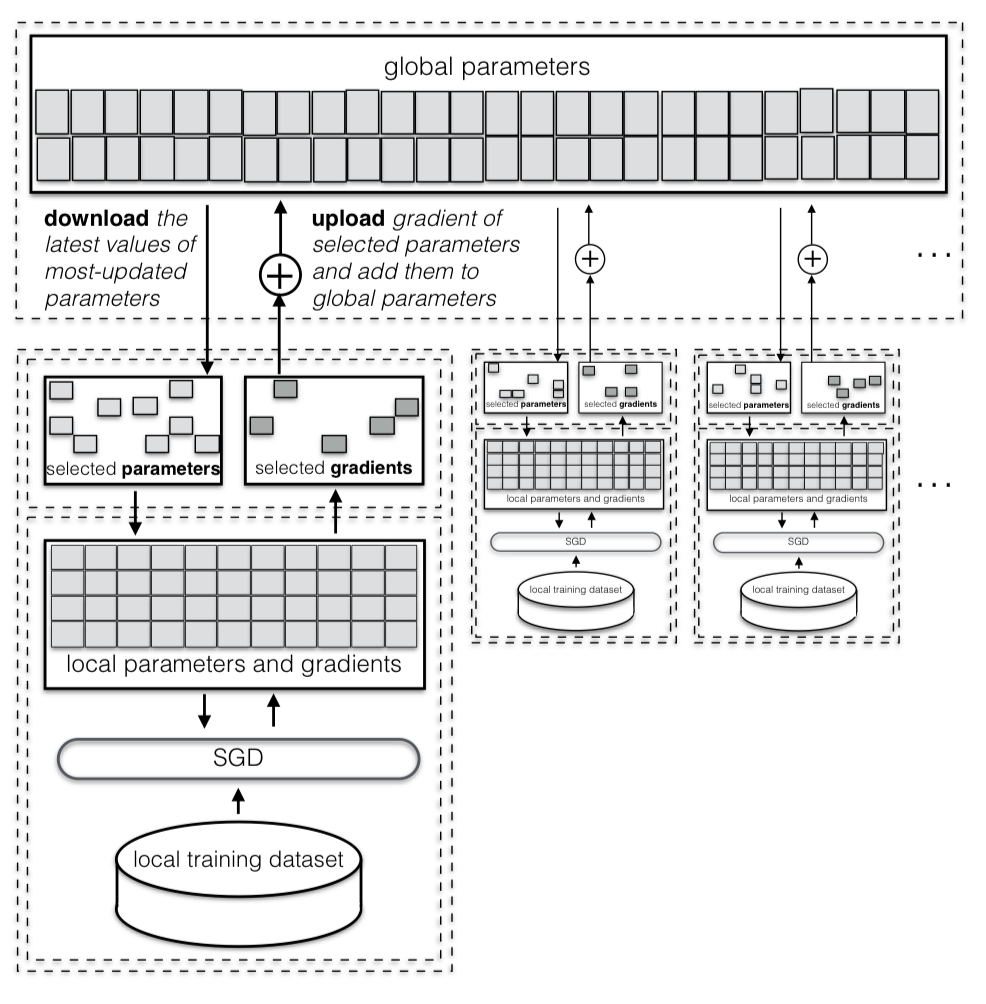
每个参与者初始化参数,然后在自己的数据集上运行培训。该系统包括一个参数交换协议,使参与者能够将所选神经网络参数的梯度上传到参数服务器,并下载每个本地SGD历元的最新参数值。这使得参与者能够
(i)独立地收敛到一组参数,关键是,
(ii)避免将这些参数过度拟合到单个参与者的本地培训数据集。一旦网络经过培训,每个参与者都可以在新数据上独立、私下地对其进行评估,而无需与其他参与者交互。
下面,我们将详细描述系统的所有组件。表1列出了我们系统的元参数。这些参数控制协作学习过程,而不是正在学习的实际神经网络参数。
5.2 本地培训
我们假设每个参与者i维护一个神经网络参数的局部向量w(i)。参数服务器维护一个单独的参数向量w(全局)。每个参与者可以随机初始化其本地参数,也可以从参数服务器下载其最新值。然后,每个参与者使用标准SGD算法训练神经网络,在多个时期内迭代其局部训练数据。在当地培训期间,不同参与者之间无需进行任何协调。它们通过参数服务器间接影响彼此的培训。图3显示了分布式选择性SGD(DSSGD)算法的伪代码。DSSGD由每个参与者独立运行,在每个学习阶段由五个步骤组成。首先,参与者从服务器下载θd部分参数,并用下载的值覆盖其本地参数。然后,他在本地数据集上运行了一次新纪元训练。该培训可在一系列小批量上进行;小批量是随机选择的大小为M的训练数据点集。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号