Differential Privacy – A Primer for the Perplexed

差分隐私是针对隐私保护数据分析,量身定做的隐私目标的定义(definition)。自从[DMNS06,Dwo06]诞生以来,差分隐私数据分析一直是算法和理论研究的主题。然而,不幸的是,有些文献是对deffnition的存在基本误解。在这份简短的邀请函中,我们将阐明并回应这些最常见的错误。
错误1:将definition与特定算法混淆
差分隐私(Differential Privacy)是一种隐私定义。它是发布关于数据集的统计信息的算法可以满足的数学保证,许多不同的算法都满足这一要求(Deffnition)。
我们将假设有一个包含n行的数据库X,每行是单个人的数据。如果每个个体的数据被描述为集合U中的一个元素,那么我们可以将数据集合看作U中的多个集合(即,其中每个元素可能出现不止一次的集合)。设D表示可能的数据集的空间。有一种算法M将数据库和查询(可选)作为输入,并返回响应。我们将这样的算法称为机制。目前,我们将阐述不同隐私权的定义。
然而,目前,我们注意到,如果随机化机制M在所有数据库上具有相同的输出分布,则其输出不会显示关于其输入的信息。实际上,这相当于以下语句,其中D是所有可能的数据库的集合,Q是所有可能的查询的集合:
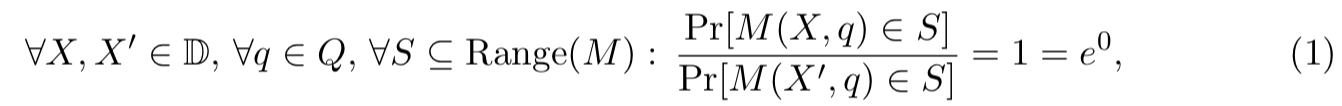
其中,在分子和分母中,概率空间都在由该机制作出的随机选择之上。请注意,如果确定性机制忽略其输入,则它也可以满足此属性。
如果算法具有此属性,则无论观察者-看到输出y的数据分析员知道或有权访问什么-它都是成立的。如果观察者已经知道数据库是X,或者数据库包含本笔记作者的医疗数据,或者即使观察者知道数据库中人的所有镰状细胞状态位的模2和,这也不能改变机制的行为保证。与满足fiES公式1的机制交互时,不能泄露有关数据库的任何进一步信息。
这是完全保密的定义,在Shannon[Sha49]的加密上下文中提出。这不是一种算法。相反,它是关于随机化算法的概率分布的条件;从信息论的意义上讲,任何满足条件的算法都不会显示有关数据的信息。
差分隐私:它的形式与公式1完全相同,只是现在我们允许发布一点信息:
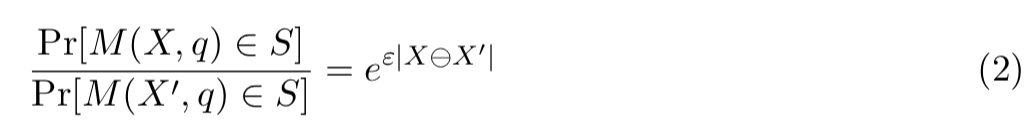
对此Definition的一种常见解释是,无论观察者(或攻击者)提前知道什么,差分隐私算法的输出几乎没有给出任何特定给定用户的数据是否包括在数据集中的指示。我们稍后再回到这一点。目前,我们总结出:Definition不是一个算法,而是一个被许多不同算法所满足的条件。注意,以这些术语制定隐私,作为可以以多种方式满足的要求,提供了一个框架,人们可以在其中研究算法,比较它们的隐私保证,并理解它们在隐私方面联合影响等。我们相信这是科学的隐私方法的必要步骤。
错误2:将输出与生成它们的进程混淆
正是生成输出的过程确保了这一点。因此,我们不谈论“安全”或“隐私保护”输出;相反,我们认为输出是根据隐私保护过程生成的。1位一次性便签簿是一个产生完美隐私的过程。
所有完美私有机制都是完全差分隐私的,但是这类完全差分隐私机制包含的机制并不能产生完美隐私;相反,它们提供了一些关于数据库的重要信息,如果我们对隐私保护数据分析感兴趣的话,我们会希望如此。
请注意,对于给定的数据库,没有所谓的“好”输出或“坏输出”。尽管如此,发布的值确实给出了关于两个1位数据库中哪一个更有可能的一点提示,但随机性提供了不确定性。像往常一样,我们指出,1位随机响应机制保留其不同的隐私属性,而与看到输出的任何人可能知道的关于数据库或其与其他数据库的连接无关。
错误3:将特定顺序私有算法的不良效用与差异隐私本身的故障混淆起来
1.差分隐私权是一种定义,而不是一种算法。
2.对于任何speific数据库,没有“好”或“坏”的输出。隐私(完美或差异)是从生成输出的过程中获得的。
3.特定的差分私有机制未能提供超准确的答案并不意味着差异隐私与该目标不兼容。
事实:差分隐私并不保证您认为是您的秘密的东西是保密的。差分隐私保证的是,您参与的调查不会泄露您对调查做出的特定贡献。从调查中得出的结论很有可能反映出有关你的统计信息。一项旨在发现某一特定疾病的早期迹象的健康调查可能会产生强有力的、甚至是决定性的结果;这些结论对你来说是成立的,但并不是侵犯隐私的不同证据。
事实上,您甚至可能没有参与过调查(同样,不同的隐私确保无论您是否参与调查都会以非常相似的概率获得这些结论结果)。
具体地说,如果调查告诉我们,特定的私有属性与公共属性有很强的相关性,这并不是对不同隐私的侵犯,因为无论是否存在任何受访者,都会以几乎相同的概率观察到这种相同的相关性。关于这一点,我们最喜欢的比喻是:
假设一个统计数据库告诉我们吸烟会致癌。众所周知的吸烟者爱丽丝因为保险费上涨而受到伤害。不管爱丽丝是否在数据库中,她(本质上)同样有可能受到伤害。爱丽丝也得到了帮助:因为这项研究,她参加了戒烟计划。
差分隐私的设计是为了确保爱丽丝和其他每个人都有动力加入这些对社会有益的研究。
错误4:对于 ε>1,差分隐私“没有意义”。
(奇怪的)经常有人声称,由于概率最多只能取值1,所以ε的值大于1就没有什么意义了。目前还不清楚这种特殊的选择来自哪里,因为exp(1)=e与概率的最大值没有特殊的关系,尽管大ε从根本上没有意义的精神是可以理解的。当然,较大的ε值导致的有意义的保证比较小的ε值小得多。
Error5: Differential privacy cannot work because no one can explain how to set the value of ε.
我们很好地理解数据位于多个独立操作的数据库中的个人所造成的累积隐私损失,即使是针对有权访问所有这些数据库的对手,这是差异隐私研究的进一步的优势,而不是弱点。我们对数据位于多个独立操作的数据库中的个人造成的累积隐私损失有了很好的理解。不同的隐私研究已经开发出在可能的协调答案时显著减少隐私损失的技术,这是额外的进一步的优势,而不是弱点。
差分的隐私研究人员已经确定,这种协调对于实现非常复杂的查询是必不可少的,并且是不可替代的,这是又一个额外的进一步的优势,而不是一个弱点。正是这条调查路线-在差分隐私领域,而不是在任何其他的私人数据分析方法-让我们能够通过ε了解并减轻隐私损失。是的,这项研究是不完整的。是的,下列形式的定理似乎具有可怕的限制性:
但除此之外,我们如何才能找到一个起点来理解如何放松我们对最坏情况下的对手的保护呢?除此之外,我们还能如何测量这样做的呢?还有什么其他技术允许人们证明这样的说法呢?
在更哲学的层面上,考虑一个时间的类比:你一生中只有那么几个小时,一旦这些小时被消耗掉,你就会死去。(这有时比别人了解你的私人信息更糟糕。)然而,不知何故,作为一个社会,我们已经找到了获得个人时间价值的方法,其中一个基本部分是定量衡量它的能力。
当然,关于隐私的价值有新的思考要做,但我们认为,现在能够做到这一点是一件特别好的事情;每一项有意义的隐私保障都应该是同样定量的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号