Federated f-Differential Privacy
Qinqing Zheng, Shuxiao Chen, Qi Long, Weijie Su Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, PMLR 130:2251-2259, 2021.

摘要
联邦学习 (FL) 是一种培训范例,客户可以通过反复共享信息来协作学习模型,而不会损害其本地敏感数据的隐私。在本文中,我们基于高斯微分隐私框架,介绍了联邦微分隐私,这是一种专门针对联邦设置量身定制的新概念。联邦高级隐私在记录级别上运行: 它在针对对手的客户数据的每个单独记录上提供隐私保证。然后,我们提出了一个通用的私有联合学习框架PriFedSync,该框架可容纳大量最先进的FL算法,这些算法可证明实现了联合的潜在隐私。最后,我们从经验上证明了PriFedSync在计算机视觉任务中训练的模型的隐私保证和预测性能之间的贸易关系。
Introduction
联合学习 (McMahan等人,2017) 是一种新兴范例,它使多个客户能够协作学习预测模型,而无需显式共享数据。与传统的将所有数据上传到中央服务器的分布式训练方法不同,联合学习执行设备上的训练,并且仅在客户端之间交换本地数据或本地模型的一些摘要。通常,客户端将其本地模型上传到服务器,并以重复的方式共享全局平均。这为解决关键问题提供了合理的解决方案数据隐私问题: 关于个人的敏感信息,如打字历史、购物交易、地理位置、医疗记录,将保持本地化。
尽管如此,参与联合学习的恶意客户端仍可能能够通过共享模型的权重来学习有关其他客户端数据的信息。这是因为对手有可能通过简单地调整输入数据集并探测算法的输出来了解或甚至识别某些个体 (Fredrikson等,2015; Shokri等,2017)。这引起了对保护隐私的联合学习算法的迫切呼吁。因此,我们迫切需要一个严格而有原则的框架来增强数据隐私,并定量回答重要问题:
另一个客户可以在联合学习中识别我的数据中是否存在任何个人记录?更糟糕的是,如果所有其他客户都互相盟友攻击我的数据怎么办?
许多作品试图从不同的角度回答类似的问题 (McMahan等人,2018; Geyer等人,2017; Li等人,2019; Singh等人,2020),提出了许多隐私概念和相关方法来解决相关问题,然而,他们都没有完全直接回答这些问题。据我们所知,所有现有的作品都将经典的隐私定义概括为联合设置: 对手可以删除一个客户的整个数据集,并且这种类型的攻击不会导致算法输出的巨大变化。由此产生的隐私保证在用户层面执行: 客户是否参加过培训,对手无法推断,客户的整个数据集都是私有的。
虽然用户级别的隐私在联合学习中有重要的应用,但在记录级别考虑较弱的隐私概念是相辅相成的,同样重要。
首先,隐私通常与性能不一致。用户级隐私保证通常太强,并且人们经常寻求保护隐私免受更实际攻击的较弱概念 (Li等,2019)。更重要的是,考虑到不同国家的多家医院希望合作学习新型冠状病毒肺炎预测模型的情况。在此示例中,医院是否参与此协作根本不是敏感信息,真正需要保护的是每个患者的隐私。这是一个创纪录的隐私概念闪耀的制度。
在这项工作中,我们引入了一种粒度的隐私概念,称为弱联邦性隐私,它可以保护一个客户数据的每个单独记录。
我们研究攻击模型,即对手可以操纵客户端数据集的单个记录,并为这种情况提供隐私保证。我们提出了一个统一的私有联合学习框架PriFedSync,其中包含大量的联合学习算法。此外,我们还提供了一个扩展的隐私概念,称为 “强联合f-diential隐私”,以解决多个恶意客户端共同攻击客户端的情况,这在以前的任何工作中都没有考虑过。我们的主要贡献如下。
1.我们引入了两个隐私概念,即弱联邦性隐私和强联邦性隐私,它们分别描述了针对单个对手和一组对手的隐私保证。这两个概念都具有the finest resolution,因为它们可以保护一个客户数据的单个记录。我们依赖的隐私定义是潜在隐私f-differential privacy,是其高斯潜在隐私 (GDP) 的子家族 (Dong等人,2019)。
2.我们提出了一个通用的联合学习框架PriFedSync,其中包含最先进的联合学习算法。框架不假定可信的中央聚合器。它可以容纳个性化或非个性化的方法。我们利用GDP的组成定理来分析PriFedSync的隐私保证,并证明其渐近收敛性。
3.我们进行数值实验来说明我们的隐私概念,并将私有模型与非私有模型的性能进行比较。当数据在客户之间是异构的时,我们的个性化方法证明了对全局模型的显著改进。通过我们的实验,我们还演示了隐私和准确性以及隐私和计算之间的权衡。
Related Work
越来越多的工作在联邦学习的背景下研究隐私属性。McMahan等人 (2018) 介绍了两种算法,分别为私有联邦随机梯度下降 (dp-fedsgd) 和私有联邦平均 (dp-fedavg),并研究了它们的隐私属性。隐私概念在用户级别。也就是说,如果可以通过从S中完全删除一个客户端的数据来获得S0,则两个数据集S和S0被称为相邻。这种攻击对于现实世界的应用可能是不切实际的。
在算法上,dp-fedsgd是 “非联合” dp-sgd (Abadi等,2016) 到分布式优化设置的直接扩展,其中每个客户端的梯度在每次迭代中被剪切和聚合,而dp-fedavg在服务器上执行近似dp-sgd。本质上,本地模型在本地训练之前和之后的差异被视为梯度的替代并发送到服务器。Geyer等人 (2017) 提出了近似dp-sgd的类似算法。Singh等人 (2020) 使用类似于dp-fedsgd的算法来解决体系结构搜索问题,并且它们的隐私保证也作用于用户级别。Li等人 (2019) 研究了在线转移学习,并引入了一种名为任务全局隐私的概念,该概念在记录级别上起作用。但是,在线设置假定客户端仅与服务器交互一次,并且不扩展到联合设置。Truex等人 (2019) 将中心空间隐私推广到分布式设置中,当数据集在不同的机器上分割成几个分区时,可以将其视为训练单个共享私有模型。即使作者考虑了记录级别的隐私,这项工作也没有设置,例如单个客户端有自己的模型,客户端采样等。
与联邦学习中的隐私的一般概念相关的一个隐私概念是本地独立隐私 (evievski等,2003; Kasiviswanathan等,2011)。本地空间隐私不假定受信任的数据聚合器。每个数据记录在发送到数据聚合器之前都会被随机扰动,聚合器使用有噪声的数据来构建模型。如果任何一对可能的数据记录的放置都是无法区分的,扰动算法是局部差分私有的。
尽管具有概念上的联系,但本地差异隐私并不能完美地扩展到一般的联合学习环境。在本地独立隐私框架下,嘈杂的数据被集中在一个中央聚合器中,所有的训练都在那里发生; 而联合学习的一般形式允许参与者拥有自己对数据和模型的控制。此外,局部空间隐私是一个很强的概念,通常需要大量噪声,从而导致模型性能下降。
另一个相关的概念是由Kearns等人 (2014) 提出的用于研究大型游戏的 “推荐机制” 行为的联合隐私。它已被应用于私有凸规划的上下文中,该问题的解决方案可以在不同的代理之间划分 (Hsu等人,2016a,b),例如多商品问题。非正式地,联合独立隐私确保代理的输出的联合分配对代理i提供的输入不敏感。它类似于我们的一个与所有概念的强联合独立隐私 (见定义3.6),但在用户级别上起作用。
尽管隐私保证的粒度和具体概念,但需要正式的隐私定义来精确量化隐私损失。迄今为止最流行的统计隐私定义是 ( )-dient privacy (Dwork等人,2006a,b)。它被广泛应用于工业应用和学术研究,包括一些以前关于私人联合学习的工作 (McMahan等人,2017; Geyer等人,2017; Li等人,2019)。
不幸的是,这种隐私定义不能很好地处理私人算法组合下的累积隐私损失 (Kairouz等人,2017; Murtagh和Vadhan,2016),这是隐私分析中要解决的基本问题,并且在分析联邦学习算法时也需要。
对组合的更好处理的需求激励了许多工作,提出了基于差异的放松 ()dial-erential隐私放松 (Dwork和Rothblum,2016; Bun和Steinke,2016; Mironov,2017; Bun等人,2018)。同时,另一条研究领域已经建立了隐私与假设检验之间的联系 (Wasserman和Zhou,2010; Kairouz等人,2017; liu等人,2019; Balle等人,2019)。最近,dong等人 (2019) 提出了一种基于假设检验的隐私概念,被称为f-dial-erative隐私。这种隐私定义描述了使用通过相关假设检验问题给出的I型和II型错误之间的贸易的隐私保证。
2 Private Federated Learning
令m表示客户端的数量。每个客户端i都可以访问其本地数据集S (i),其中数据是从本地分布d i采样的i.D。经典的联合学习算法 (McMahan等人,2017; Kone-cn'y等人,2016) 旨在学习一种在所有客户中表现良好的全球模型-w global。这隐含地做出了一个基本假设,即数据是同质的,即D 1 = · · = D m,但实际上数据可能无法在客户端之间完全相同地分布。考虑到用户数据分布的异质性,人们对假设具有D i = 6 D j的可能性的不相同数据分布以及学习个性化模型的兴趣激增 (Dinh等人,2020; Huang等人,2020; Hanzely和Richt'arik,2020; 邓等人,2020)。
我们提出了一个统一的框架PriFedSync,该框架解决了异构和同质设置,请参见算法1。每个客户我将获得一个特定的本地模型〜w (i),并且仍然形成并使用全局模型〜w全局。同质设置可以归结为一种特殊情况,其中〜w (i) = 〜w全局, [m] (我们使用 [m] 表示 {1,。,m})。PriFedSync包含大量现有的联合学习算法,包括FedAvg (McMahan等人,2017) 和许多其他算法 (Li等人,2018; Dinh等人,2020; Huang等人,2020; Hanzely和Richt'arik,2020; Deng等人,2020)。
在PriFedSync中,所有客户端都从相同的模型w0开始。为了模仿并非所有客户端都同时与服务器同步的实际行为,在每个同步回合中,我们都会对客户端的子集进行采样,以执行本地训练并与服务器同步。如果选择了客户端i,它将从服务器中提取一个辅助模型〜h (i),然后对K次迭代执行本地私人训练。辅助模型〜h (i) 可以是全局聚合〜w全局 (McMahan等人,2017; Li等人,2018),或个性化 (Dinh等人,2020; Huang等人,2020)。已经提出了各种方法来利用〜h (i) 来改善本地训练,包括初始化本地模型 (Dinh等人,2020; Hanzely和Richt'arik,2020),正则化local training (Li等,2018年; Huang等,2020年),并与本地更新 (Deng et al., 2020年) 进行反选插值。

当地的私人培训也可以通过不同的方式进行。例如,可以使用无噪声的局部训练并在使用拉普拉斯或高斯机制进行同步之前对模型进行扰动。或者,可以直接进行dp-sgd (Abadi等人,2016),其中梯度在每次迭代中被扰动。Dp-sgd的缺点是计算速度慢,因为它需要在每次迭代中剪切每个样本的梯度。但是,我们观察到dp-sgd通常会导致更好的预测精度,因此我们将使用dp-sgd进行分析和实验。
接下来,客户端i将私有模型〜w (i) 发送到服务器。服务器聚合接收到的模型,然后更新相应的帮助器模型。有很多方法可以计算辅助模型。如果F i函数是身份映射F i (w) = w,i 2 [m],则所有客户端将收到相同的辅助模型〜w全局。这是在FedAvg中使用的设置 (McMahan等人,2017)。另一个简单但有效的观察是,〜h (i) 是噪声全局模型w全局模型和局部模型w (i) 的凸组合 (Dinh等人,2020; Hanzely和Richt'arik,2020):
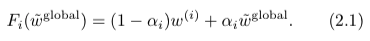
在我们的框架中,有更复杂的个性化助手模型的构造。
在本节结束时,我们将概述PriFedSync的隐私保证。
1.很容易看出,客户端i只能通过助手模型〜h (i) 来探测客户端j的数据集。这成为我们在本文中分析的重点。
2.给定一个全局模型〜w全局,辅助模型〜h (i) 是通过map〜w全局的转换Fi。无论Fi的形式如何,该步骤都不会引起额外的隐私泄漏,因为潜在隐私不受后处理的影响 (Dwork和Roth,2014)。然后自然会问以下问题:
(i) 为什么不仅仅计算一个无噪声的全局模型w全局并在转换之前或之后注入噪声?例如,在服务器上,一个人可以进行
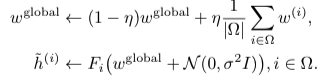
(ii) 是否等同于直接向客户端发送〜w global并让他们自己应用转换?
(i) 中的程序确实保护了客户端i的隐私,并减少了dp-sgd引起的计算负担。但是,计算无噪声的全局模型将需要所有客户端将无噪声的本地模型发送到服务器,这对可信赖的服务器施加了额外的假设。
(ii) 的答案取决于Fi的具体形式。如果映射Fi没有其他私有局部模型,确定性和可逆,则应用Fi之前和之后的隐私成本是相同的。在这种情况下,发送 ~ w全局或 ~ h (i) 之间没有差异。然而,后处理可能会放大隐私。考虑一个常数函数F ,它输出任何输入的零向量。这个简单的功能实现了完美的隐私。在这些情况下,发送 ~ wglobal将比发送 ~ h (i) 更不私密。为了使我们的分析对PriFedSync中的所有算法保持通用,我们将假设在我们的分析中不了解Fi。对于特定的 算法,可以通过获取Fi的先验知识来获得潜在的更严格的界限。
3 Privacy Analysis
我们首先在第3.1节中回顾高斯微分隐私,这是我们利用的分析工具。接下来我们在第3.2节中介绍我们的私人符号,并在第3.3节中分析PriFedSync的隐私保证。
3.1预赛
让我们从对间接隐私的假设检验解释开始,这是GDP的基础。令A表示将数据集S作为输入的随机算法。S0是S的相邻数据集,即S和S0仅在一个个体中存在差别。令P和Q分别表示A(S) 和A(S0) 的概率分布。差分隐私试图通过利用A的输出来衡量对手识别S中是否存在任何某一个人的难度。等效地,对手执行以下假设检验问题 (Wasserman和Zhou,2010):
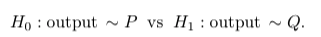
直觉上,如果对手做出正确的决定,就会发生隐私泄露,并且a的隐私保证归结为di # culty,对手可以将两个分布区分开。Dong等人 (2019) 提出使用在层-水平的最优似然比检验的I型和II型误差之间的trade-o什么作为隐私保证的量度,其中,的范围从0到1。正式地,让 & 成为针对H 0对H 1进行测试的拒绝规则。& 的类型I和类型II错误分别为E P (&) 和1% E Q (&)。贸易-o什么功能T: [0,1]![0,1] 两个概率分布P和Q之间的de fi ned为

 浙公网安备 33010602011771号
浙公网安备 33010602011771号