无监督-DEEP GRAPH INFOMAX
无监督-DEEP GRAPH INFOMAX
标签:图神经网络、无监督
动机
- 在真实世界中,图的标签是较少的,而现在图神经的高性能主要依赖于有标签的真是数据集
- 在无监督中,随机游走牺牲了图结构信息和强调的是邻域信息,并且性能高度依赖于超参数的选择
贡献
- 在无监督学习上,首次结合互信息提出了一个图节点表示学习方法-DGI
- 该方法不依赖随机游走目标,并且使用与直推式学习和归纳学习
- DGI 依赖于最大限度地扩大图增强表示和目前提取到的图信息之间的互信息
思想
符号定义
节点特征集合: \(X \in \mathbb{R}^{N \times F}\),邻接矩阵: \(A \in \mathbb{R}^{N \times N}\), 编码器: \(\varepsilon~~~~ \mathbb{R}^{N \times F} \times \mathbb{R}^{N \times N} \rightarrow \mathbb{R}^{N \times F'}\),鉴别器(discriminator): \(D~~ ~~ \mathbb{R}^{F} \times \mathbb{R}^{F} \rightarrow \mathbb{R}\),腐蚀函数(corruption function): \(C~~~\mathbb{R}^{N \times F} \times \mathbb{R}^{N \times N} \rightarrow \mathbb{R}^{M \times F} \times \mathbb{R}^{M \times M}\),节点的表示 (patch representations): \(\overrightarrow{h_i}\) , 图表示: \(\overrightarrow{s}\) .
核心
本质上利用大化局部互信息训练一个模型 (编码器) \(\varepsilon~~~~ \mathbb{R}^{N \times F} \times \mathbb{R}^{N \times N} \rightarrow \mathbb{R}^{N \times F'}\) ,其损失函数 (1) 所示,负例的来源是是通过 corruption function 得到
框架
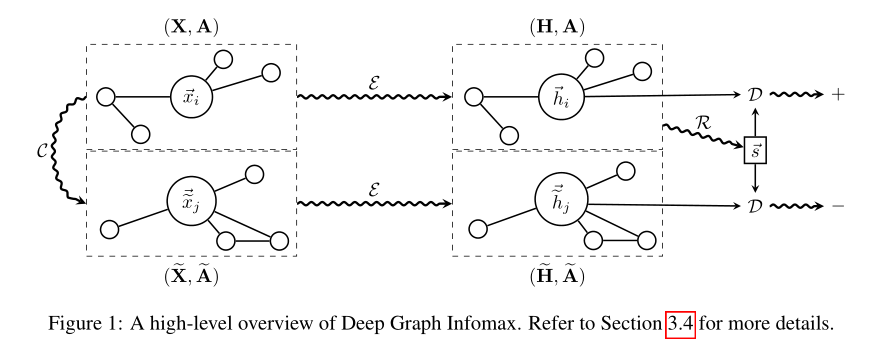
对于一个原图 \(G(X, A)\),首先利用 corruption function 得到一个破坏后的图 \(G'(\widetilde{X}, \widetilde{A})\),拿这两个图利用编码器 \(\varepsilon\) 进行编码, \(H = \varepsilon(X, A) = \{\overrightarrow{h_1},\overrightarrow{h_2},...,\overrightarrow{h_N}\} ~~~~~ H = \varepsilon(\widetilde{X}, \widetilde{A}) = \{\overrightarrow{\widetilde{h_1}},\overrightarrow{\widetilde{h_2}},...,\overrightarrow{\widetilde{h_N}}\}\) , 对于原图得到每个节点的表示利用一个读出函数 (readout function) 得到整个图的表示 \(\overrightarrow{s} = R(H)\) ,最后利用目标函数更新参数
步骤
- 用 corruption function 进行采样负样例得到 \((\widetilde{X}, \widetilde{A}) \approx C(X,A)\)
- 将原图(正例)喂给编码器获得节点的表示 patch representations \(\overrightarrow{h_i}\), \(H = \varepsilon(X, A) = \{\overrightarrow{h_1},\overrightarrow{h_2},...,\overrightarrow{h_N}\}\)
- 将破坏后的图(负例)喂给编码器获得节点的表示 patch representations \(\overrightarrow{\widetilde{h_i}}\), \(H = \varepsilon(\widetilde{X}, \widetilde{A}) = \{\overrightarrow{\widetilde{h_1}},\overrightarrow{\widetilde{h_2}},...,\overrightarrow{\widetilde{h_N}}\}\)
- 通过读出函数 (readout function) 传递输入图的patch representations 来得到总的图的表示 \(\overrightarrow{s} = R(H)\)
- 通过应用梯度下降最大化 (1) 来更新 \(\varepsilon、R、D\) 的参数
损失函数
实验
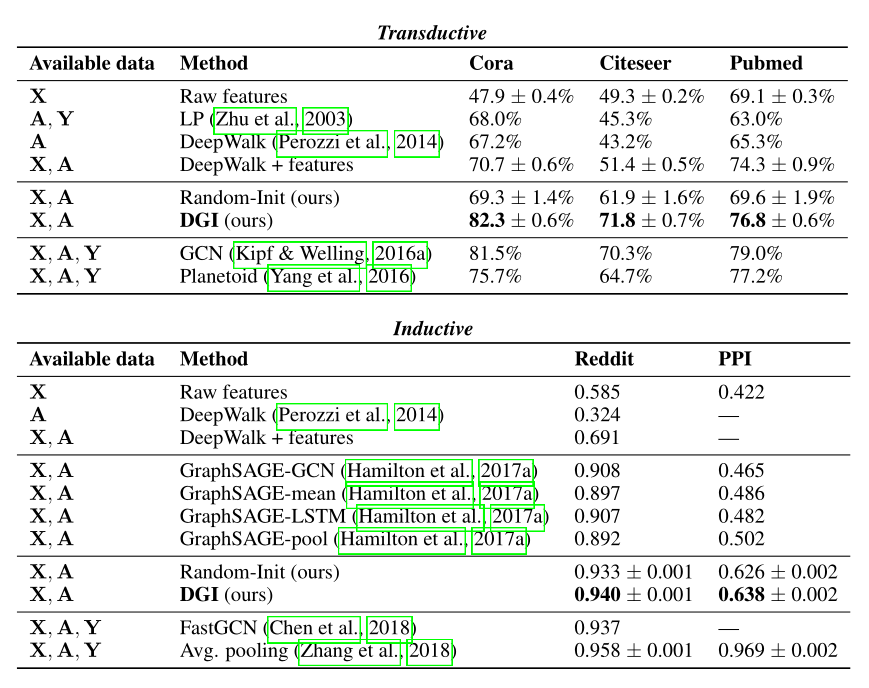
直推式学习 (Transductive Learn)
GCN 传播规则: \(\varepsilon(X, A) = \sigma(\hat{D}^{-\frac{1}{2}}\hat{A} \hat{D}^{-\frac{1}{2}}X\Theta)\)
其中, \(\hat{A} = A + I_N\) 代表加上自环的邻接矩阵, \(\hat{D}\) 代表相应的度矩阵,满足 \(\hat{D_{ii} = \sum_{j}\hat{A_{ij}}}\) 对于非线性激活函数 \(\sigma\) ,选择 PReLU(parametric ReLU)。\(\Theta \in R^{F \times F'}\) 是应用于每个节点的可学习线性变换。
对于 corruption function C ,直接采用 \(\widetilde{A} = A\),但是 \(\widetilde{X}\) 是由原本的特征矩阵 \(X\) 经过随机变换得到的。也就是说,损坏的图(corrupted graph)由与原始图完全相同的节点组成,但它们位于图中的不同位置,因此将得到不同的邻近表示。
归纳式学习 (Inductive Learn)
对于归纳学习,不再在编码器中使用 GCN 更新规则(因为学习的滤波器依赖于固定的和已知的邻接矩阵);相反,我们应用平均池( mean-pooling)传播规则,GraphSAGE-GCN:\(MP(X,A) = \hat{D}^{-1}\hat{A}X\Theta\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号