2. 机器学习模型选择
关于模型选择的引言
Key takeaway: The most effective algorithms typically offer a combination of regularization, automatic feature selection, ability to express nonlinear relationships, and/or ensembling.1
重视数据,算法工程师必须参与数据标注;不要尝试用一个模型解决所有问题;设计合理的测试方案,没有做过大量测试前千万不要上线。 -- 知乎上一个计算视觉方向博士回答落地算法最佳模型技巧。
机器学习算法分类
- 非监督机器学习算法
- 训练数据:无标注,未处理数据
- 两类典型任务:聚类(Clustering),降维(Dimensionality Reduction)
- 聚类:不会告诉类别对象含义,但具有区分类别的作用
- 降维:通过去除冗余特征和非关键特征,以简化数据,可用作机器学习项目的中间一步
- 监督机器学习算法
- 训练数据:标签数据,清洗过,随机化结构数据
- 三类典型任务:回归(Regression)、分类(Classification)、预测(Forecasting)
- 回归:寻找变量间联系,预测值输出为连续值
- 分类:类似于聚类,但可识别对象含义,可以是二分类,也是可以是多分类。
- 预测:寻找内在模式,预测未来趋势
- 半监督学习算法
- 融合监督和半监督

How to choose between supervised and unsupervised ML algorithms
- 融合监督和半监督
- 增强机器学习算法
- 在一套规则和目标基础上训练
- 训练的没步骤都需要系统正面或负面响应
更全面的分析可以参考算法模型。
线性回归算法
概念:
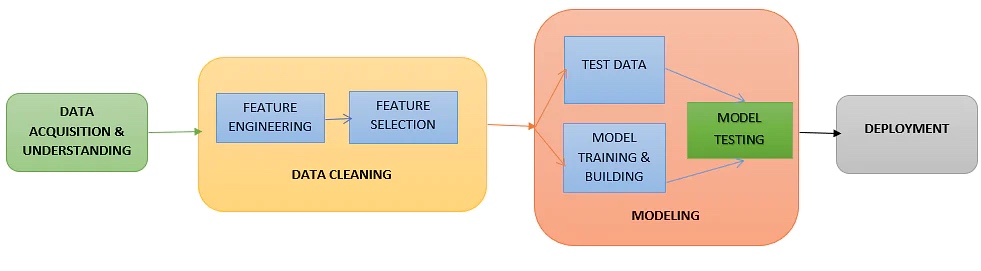
| 算法 | 优点 | 缺点 |
|---|---|---|
| 线性回归 | 容易解释和理解 | 1. 多个特征输入时会存在过拟合 2. 非线性问题表征困难 |
针对第一个问题:多特征输入容易造成过拟合
- 利用正则化,人工调整模型系数
- 避免过大模型系数
- 摒弃无用特征
- 惩罚强度可调整
- 正则化回归算法
- Lasso 回归算法
- Ridge 回归算法
- Elastic-Net 算法
针对第二个问题:非线性问题表征困难
- 引入分类算法-决策树算法,将非线性问题通过层级结构,局部问题简化成线性问题,通过树状结构来记忆非线性信息
- 决策树算法缺点:不受限的决策分支会造成过拟合,该缺陷可通过集合体(Ensemble,组合多个独立的模型预测结果的机器学习方法)来解决
- 通过 Bagging(整合强者,每个模型倾向于综合问题) 和 Boosting(分化弱者,每个模型解决单独问题) 思路实现两种算法
- 随机森林(Random Forests)算法
- 加速树(Boosted Trees)算法
算法比较
选择机器学习模型步骤
graph TB
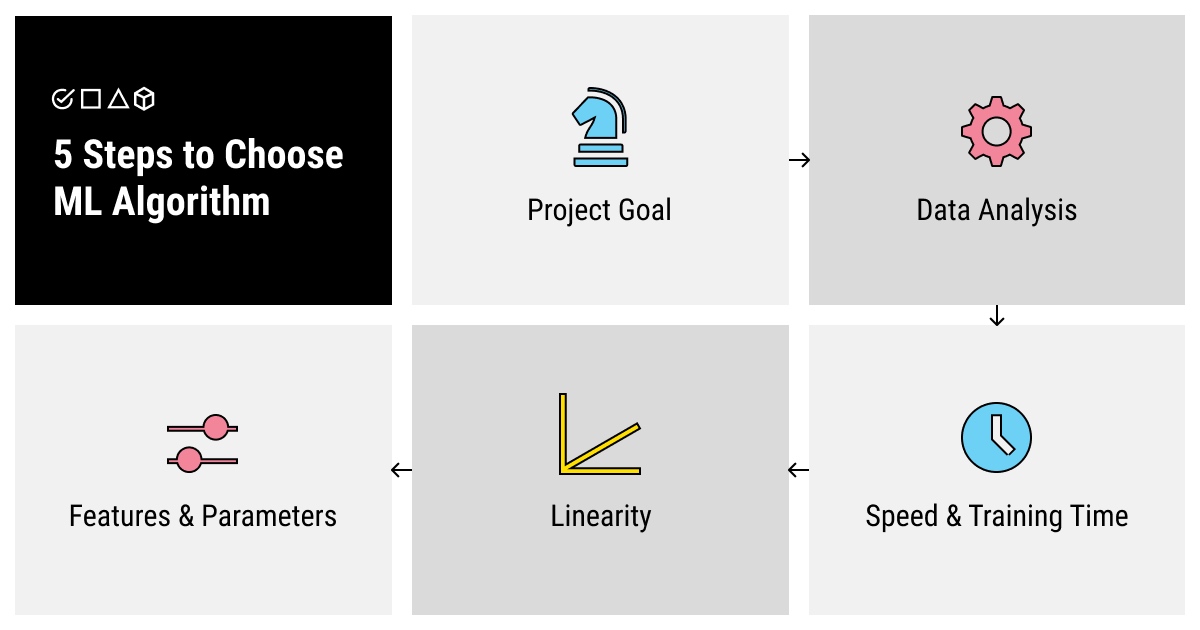
subgraph 5 Simple Steps to Choose the Best Machine Learning Algorithm
1[Step 1. Understand Your Project Goal] -->2[Step 2. Analyze Your Data by Size, Processing, and Annotation Required]
2 --> 3[Step 3. Evaluate the Speed and Training Time]
3 --> 4[Step 4. Find Out the Linearity of Your Data]
4 --> 5[Step 5. Decide on the Number of Features and Parameters]
end
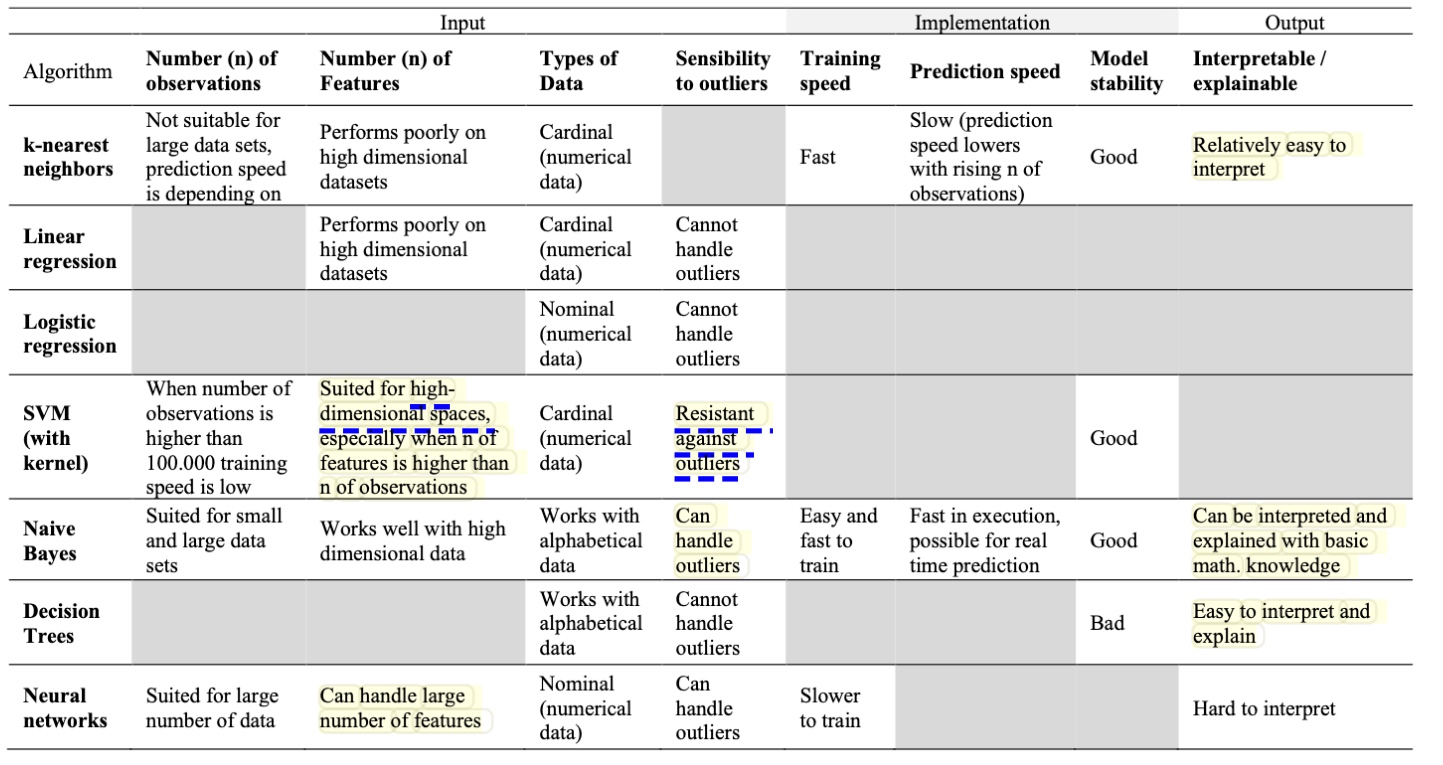
详细说明2:
- 确定输出:不同的算法模型设计出来是为了解决特定问题的,清晰定义项目目标是选择机器学习的第一步。需要何种类型输出(数值还是分类布尔值),是否是基于已有数据做预测(监督和非监督),数据降维,玩一个新游戏
- 确定输入:监督学习需要充足的、高质量的、预处理数据。开展前,需要评估数据的质量、数据处理耗费的时间和成本。若感觉投入过大,也可以训练非监督算法,但在使用前,要将其存在的缺陷了然于心。
- 有偏差?
- 有误差?
- 数据标注了?
- 数据量足够?
- 评估训练速度和时间:数据集质量决定训练模型的质量,因此开展前需要评估为了更好地训练结果,需要耗费的时间周期。
- 数据线性关系:评估线性模型是否足够了,虽然线性算法训练简单快速,但对于复杂多维度问题,存在复杂交叉关系,线性算法发挥总用有限。
- 特征参数数目:添加更多参数,花费更长时间训练,往往意味着输出的算法模型的准确性更高。
准备快速核验表
- Your input (the data: is it collected/sufficient/processed/annotated?)
- Your output (what goal do you pursue?)
- Your field of study (how linear or complex the data is?)
- Your limitations (can you spare time and resources?)
- Your preferences (what features do you absolutely need for success?)
机器学习算法
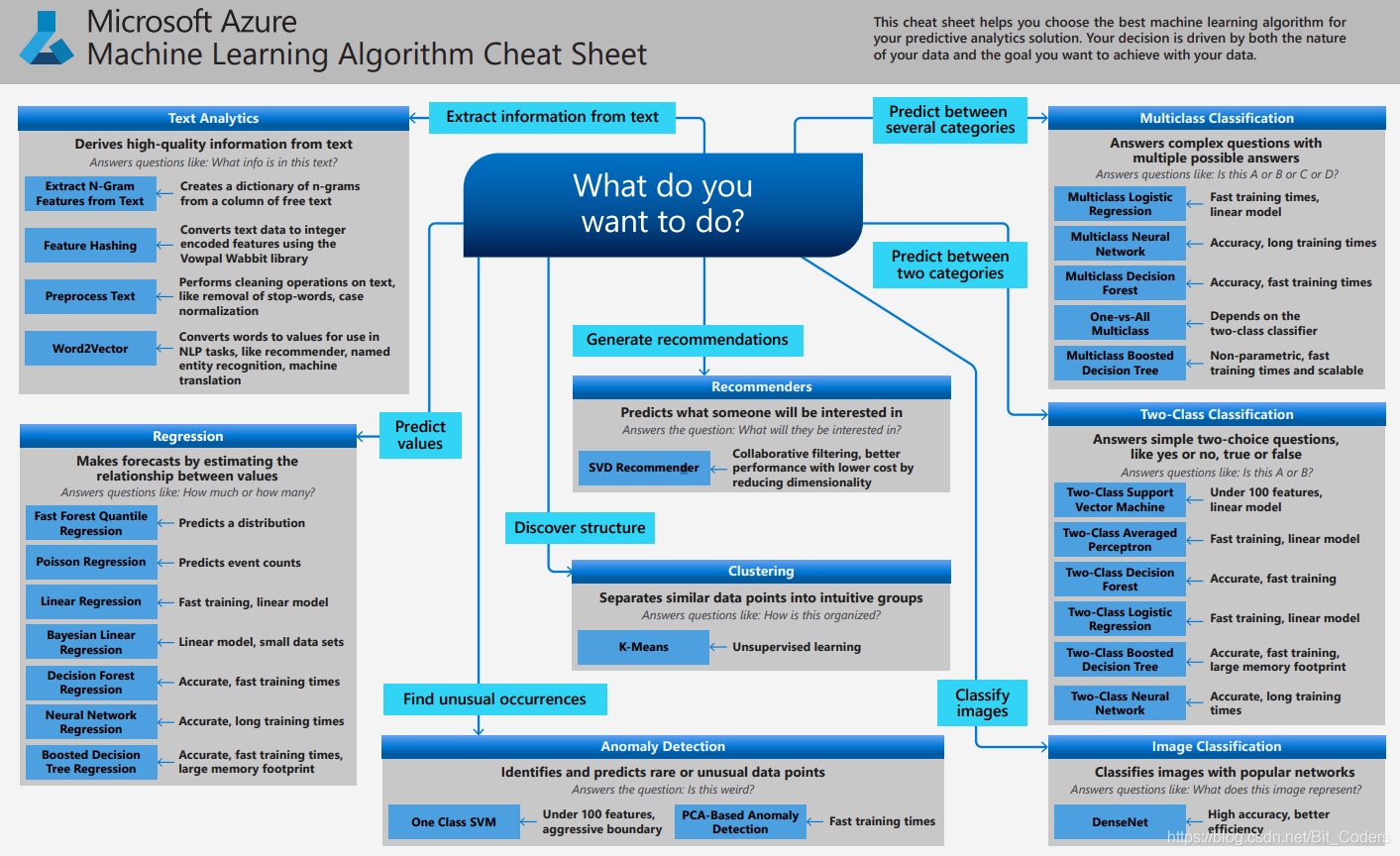
使用参考https://docs.microsoft.com/en-us/azure/machine-learning/algorithm-cheat-sheet
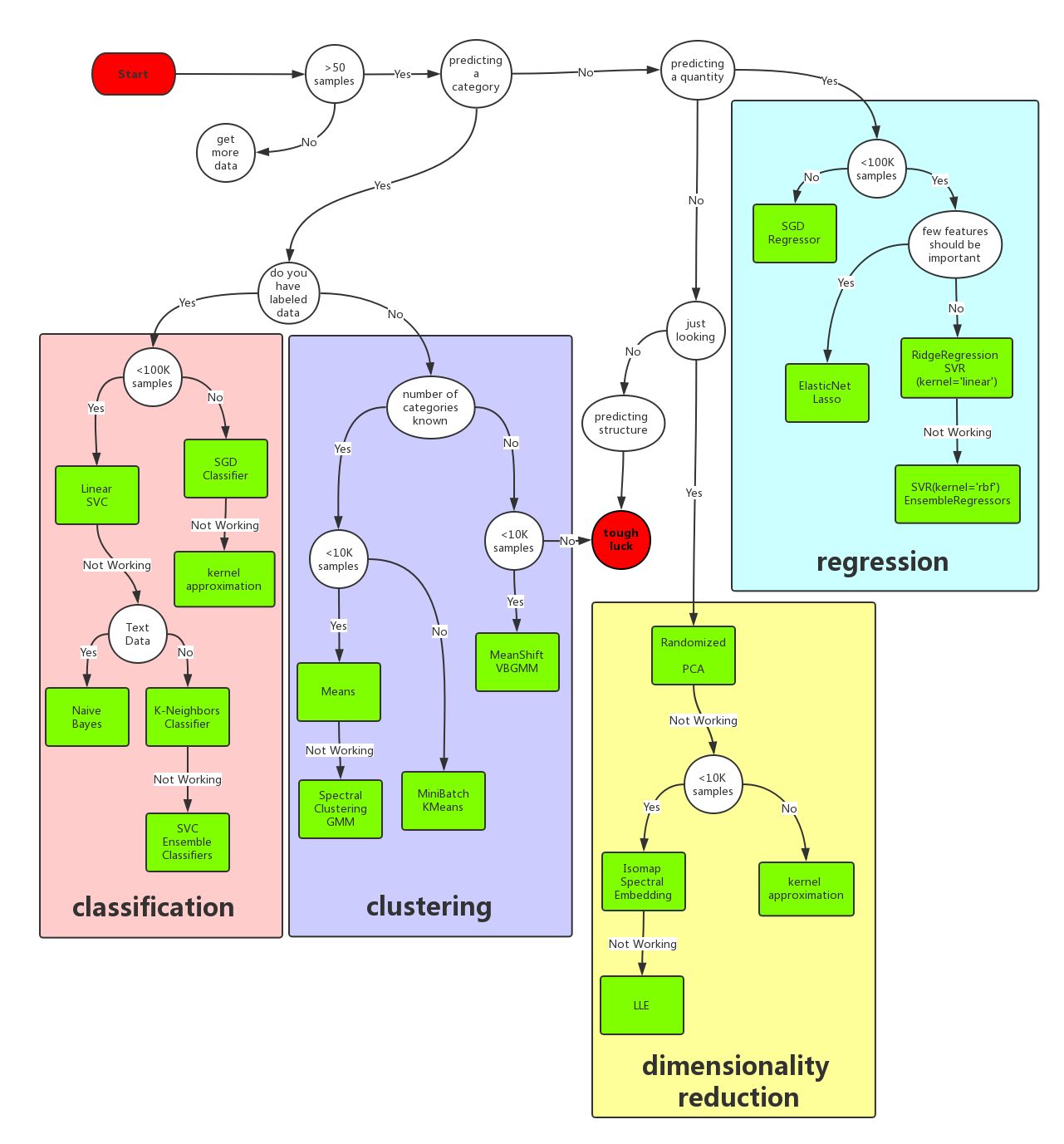
说明3:
- 样本量如果非常少的话,其实所有的机器学习算法都没有办法从里面“学到”通用的规则和模式
- 有/无监督学习和连续值/离散值预测,分成了分类、聚类、回归和维度约减四个方法类
- 为了提高算法训练效率,更好解释性,可以使用降维算法用更少的信息(更低维的信息)总结和描述出原始信息的大部分内容
- 逻辑回归 >= SVM >= 决策树(随机森林) >= Adaboost 算法
- SVM 在特征的数量和观测样本特别多,资源和时间充足时,可以尝试(存疑)
- 试试决策树(随机森林)看看是否可以大幅度提升你的模型性能。即便最后你并没有把它当做为最终模型,你也可以使用随机森林来移除噪声变量,做特征选择
- 特征属性少而样本多的话,就用表达能力强的模型,比如神经网络,梯度决策树一类的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号