Fast RCNN 中的 Hard Negative Mining
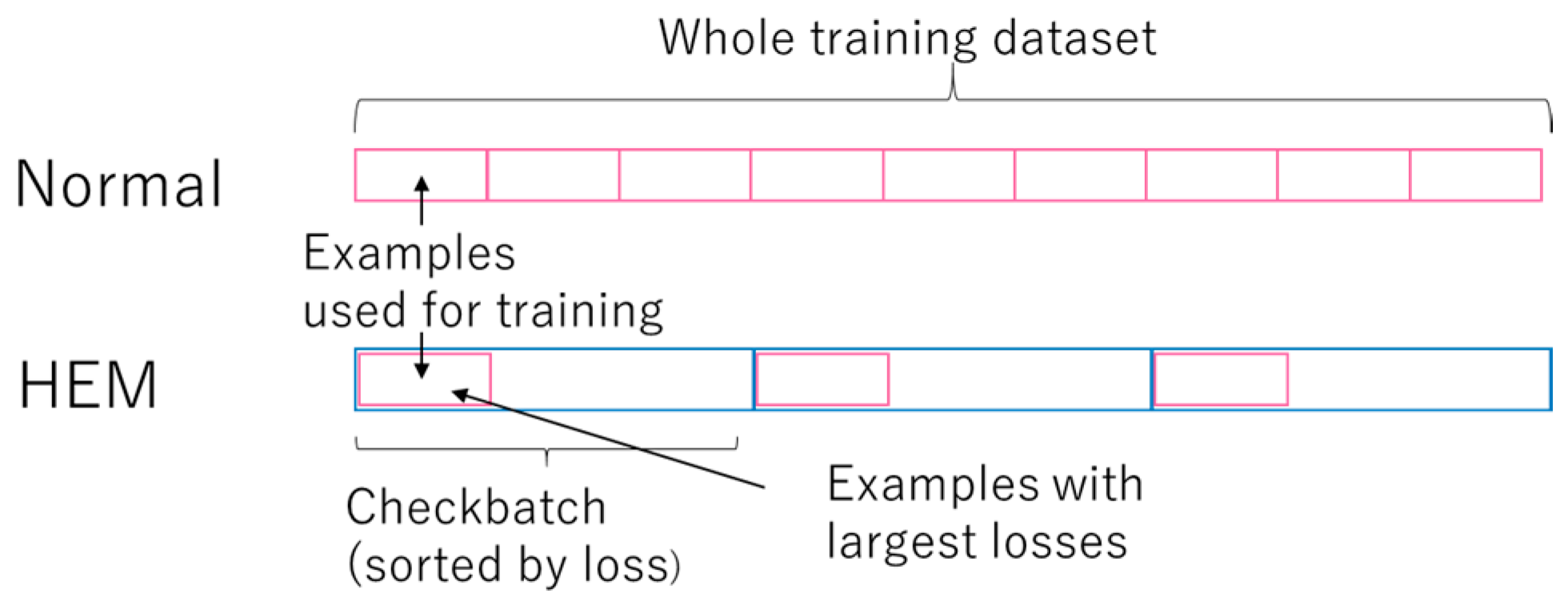 

Fast RCNN 中将与 groud truth 的 IoU 在 [0.1, 0.5) 之间标记为负例, [0, 0.1) 的 example 用于 hard negative mining. 在训练时一般输入为N=2张图片, 选择 128 个 RoI, 即每张图片 64 个 RoI. 每张图片, 按照1:3的比例来抽取的 RoI 的话, 要在负例中抽取 48 个, Fast RCNN 采用 random sampling 策略.
hard negative example
首先我们看看 hard negative example 是怎么定义?
negative,即负样本,hard 说明是难以正确分类的样本,也就是说在对负样本分类时候,loss比较大(label与prediction相差较大)的那些样本,也可以说是容易将负样本看成正样本的那些样本;
然后我们看看Fast RCNN 中的一些概念
对于目标检测, 我们会事先标记 ground truth,然后再算法中会生成一系列 proposal,这些 proposal有跟 ground truth重合的也有没重合的,那么 IoU 超过一定阈值(通常0.5)的则认定为是正样本,以下的则是负样本, 然后扔进网络中训练。 然而,这也许会出现一个问题那就是正样本的数量远远小于负样本,这样训练出来的分类器的效果总是有限的,会出现许多 false negative, 即预测为负例的正样本
一般来说, 负样本远多于正样本, 如 99% 的负样本, 那么算法不需要训练直接输出为负例, 准确率也会有 99%, 那么正负样本不均衡时, 预测偏向于样本多的一方, 对于目标检测而言, 负例多, 所以被预测为 false negative(即预测为负例的正样本) 可能性比较大.
我们为了避免这样一种情况, 需要使用策略使得正负样本尽量的均衡一点, Fast RCNN 采用的是随机抽样, 使得正负样本的比例为 1:3, 为何是1:3, 而不是1:1呢? 可能是正样本太少了, 如果 1:1 的话, 一张图片处理的 ROI 就太少了, 不能充分的利用 Roi Pooling 前一层的共享计算, 训练的效率就太低了, 但是负例比例也不能太高了, 否则算法会出现上面所说的 false negative 太多的现象, 选择 1:3 这个比例是算法在性能和效率上的一个折中考虑, 同时 OHEM(online hard example mining)一文中也提到负例比例设的太大, Fast RCNN 的 mAP将有很大的下降.
一些思考
Fast RCNN中选用 IoU < 0.1 作为hard negative的话,这样的 IoU 值对应的负样本一般不会被误判。我的理解下,不是应该把那些IoU值较高但是标记为负样本的样本更容易被误判吗?所以 hard negative mining 应该从这些样本里面(比如在Fast Rcnn中 IoU 在 [0.1, 0.5) 定义的负样本) 挑选不是更加合理吗?
我们可以先验的认为, 如果 Roi 里没有物体,全是背景,这时候分类器很容易正确分类成背景,这个就叫 easy negative, 如果roi里有二分之一个物体,标签仍是负样本,这时候分类器就容易把他看成正样本,这时候就是 hard negative。
确实, 不是一个框中背景和物体越混杂, 越难区分吗? 框中都基本没有物体特征, 不是很容易区分吗?
那么我认为 Fast RCNN 也正是这样做的, 为了解决正负样本不均衡的问题(负例太多了), 我们应该剔除掉一些容易分类负例, 那么与 ground truth 的 IOU 在 [0, 0.1)之间的由于包含物体的特征很少, 应该是很容易分类的, 也就是说是 easy negitive, 为了让算法能够更加有效, 也就是说让算法更加专注于 hard negitive examples, 我们认为 hard negitive examples 包含在[0.1, 0.5) 的可能性很大, 所以训练时, 我们就在[0.1, 0.5)区间做 random sampling, 选择负例.
我们先验的认为 IoU 在[0, 0.1)之内的是 easy example, 但是, [0, 0.1) 中包含 hard negitive examples 的可能性并非没有, 所以我们需要对其做 hard negitive mining, 找到其中的 hard negitive examples 用于训练网络.
按照常理来说 IOU 在[0, 0.1)之内 会被判定为真例的概率很小, 如果这种现象发生了, 可能对于我们训练网络有很大的帮助, 所以 Fast RCNN 会对与 ground truth 的 IoU 在 [0, 0.1)之内的是 example 做 hard negitive examples.
传统 hard example mining 流程
R-CNN 关于 hard negative mining 的部分引用了两篇论文, 下面两句话是摘自这两篇论文中
先要理解什么是 hard negative example?
1. Bootstrapping methods train a model with an initial subset of negative examples, and then collect negative examples that are incorrectly classified by this initial model to form a set of hard negatives. A new model is trained with the hard negative examples, and the process may be repeated a few times.
2. We use the following “bootstrap” strategy that incrementally selects only those “nonface” patterns with high utility value:
- Start with a small set of “nonface” examples in the training database.
- Train the MLP classifier with the current database of examples.
- Run the face detector on a sequence of random images. Collect all the “nonface” patterns that the current system wrongly classifies as “faces” (see Fig. 5b). Add these “nonface” patterns to the training database as new negative examples.
- Return to Step2
[17] P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. TPAMI, 2010.
[37] K. Sung and T. Poggio. Example-based learning for viewbased human face detection. Technical Report A.I. Memo No. 1521, Massachussets Institute of Technology, 1994.
**什么是 hard negative mining? **
在 bootstrapping 方法中, 我们先用初始的正负样本(一般是正样本+与正样本同规模的负样本的一个子集)训练分类器, 然后再用训练出的分类器对样本进行分类, 把其中负样本中错误分类的那些样本(hard negative)放入负样本集合, 再继续训练分类器, 如此反复, 直到达到停止条件(比如分类器性能不再提升).
we expect these new examples to help steer the classifier away from its current mistakes.
hard negative 就是每次把那些顽固的棘手的错误, 再送回去继续练, 练到你的成绩不再提升为止. 这一个过程就叫做'hard negative mining'.
R-CNN的实现直接看代码:rcnn/rcnn_train.m at master · rbgirshick/rcnn Line:214开始的函数定义
作者:R2D2
链接:https://www.zhihu.com/question/46292829/answer235112564
来源:知乎, 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号