位段、联合体的使用
前言
在使用一些传感器或者通信协议的时候经常会出现某个字节中的某几个位代表某些数值,提取出来就需要使用位运算,表达式看起来就不是很清晰,这时候使用联合体和位段就可以解决这些问题。
实现
大小端
在stm32中定义一个16位的变量然后为其赋值

可以看出在内存上面0x20000002上保存0x36,0x20000003上保存0x58。
0x5836中0x58是高字节,0x36是低字节,低字节保存在0x20000002这个低地址上面,所以可以看出stm32中使用的是小端的结构。大小端总结一句话就是:低字节保存在低地址是小端,低字节保存在高地址是大端。
位段、联合体
typedef union
{
struct
{
unsigned short num : 2;
unsigned short p : 1;
unsigned short torque : 12;
unsigned short b0 : 1;
} UserData;
struct
{
unsigned char data0;
unsigned char data1;
}RowData;
} sensor_data_t;
TorqueData.RowData.data0 = 0x58;
TorqueData.RowData.data1 = 0x36;
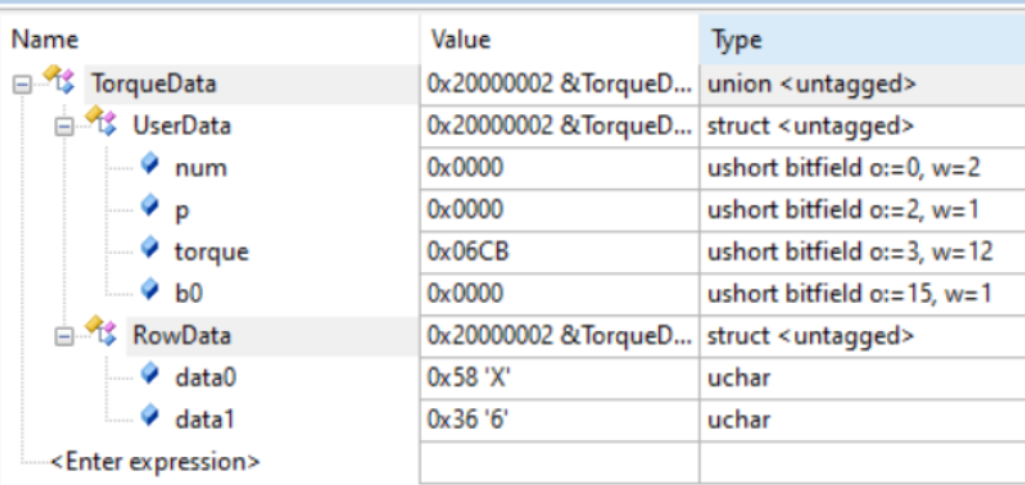

位段不具备移植性,不同的编译器不同的存储结构(大小端)都会导致不同的结果,所以移植程序的时候需要重点检查这个平台的编译结果。首先赋值的是RowData.data0 和 RowData.data1,可以看出data0保存在0x20000002,data1保存在0x20000003上面。对于UserData使用的是unsigned short申请了2个字节的内存,num先定义所以使用的是bit0、bit1,p使用的是bit2,torque使用的是bit3-bit14,b0使用的是bit15。由于STM32是小端的存储结构,所以实际UserData = 0x3658; 按bit15 -> bit0排列,从高位到低位排列。
使用位段、联合体和结构体去定义寄存器的结构可以快速提取出某几个数据位保存的数据,用来读取从器件的数据可以免去一些移位计算使用也简单。
正确使用方式
typedef union
{
struct
{
unsigned short b0 : 1; //该编译器中位段的定义是从bit0开始的
unsigned short torque : 12;
unsigned short p : 1;
unsigned short num : 2;
} UserData;
struct
{
unsigned char DataL; //低字节和高字节的位置互换
unsigned char DataH;
}RowData;
} sensor_data_t;
TorqueData.RowData.DataH = 0x58;
TorqueData.RowData.DataL = 0x36;
把从传感器中读取到的高字节和低字节分别赋值到TorqueData.RowData.DataH和TorqueData.RowData.DataL,就可以直接引用 torque
Torque = TorqueData.UserData.torque;
总结
联合体和位段在寄存器的定义、通信协议中使用比较多,例如esp32、瑞萨的芯片的SDK中就是使用这种方式去定义寄存器结构的,这样就可以具体去操作某一个位,相较于STM32使用位运算去赋值会更直观和简洁一些。但是在 MISRA 的C语言规范中禁止使用联合体,这个规定有点不近人情了芜湖

 浙公网安备 33010602011771号
浙公网安备 33010602011771号