关于CLR 2.0中托管泛型的理解
这两天在csdn上围绕着C# 2.0中的泛型特性引发了一场大讨论,一时间热闹非凡,场面蔚为壮观:) 讨论的焦点就是:C# 2.0中的泛型技术是否有用,并由此衍生出两个子问题,其一是C# 2.0泛型究竟是如何处理值类型、引用类型差异的(值类型泛型需不需要boxing/unboxing)?其二是,C# 2.0泛型能否提高性能? 如果能,究竟能提高多少性能?
从字面上来揣度,我的第一感觉是讨论的主题很有点意思:“C# 2.0中的泛型技术”。在对泛型的定位方面,我还是坚持自己的一贯观点,准确的说,Generic并不是一种独独绑定在C#或C++/CLI上面的语言特性(Language Specification,而C# 2.0中的yield、partial则应该算是),而应当理解成为一种CLR平台基础特性 (Common-Language Runtime Mechanism) 或是CLS特性(Common Language Specification)。就动机而言,语言中立性是Generic所追求的主要目标之一,同时它所追求的简洁性、实效性(有效前提下的高效)也不容忽视;而就技术特点而言,.net泛型区别于其他泛型技术的最大特色应当在于“运行时”(运行时强类型约束、运行时二阶特化、运行时代码重用等)这三个字上面。基于上述理解,如果要探讨Generic这一机制的可用性及其性能,我们的立足点应该是对CLR的理解,而不仅仅只是对C#表面语法的考察。同时鉴于C#语法固有的模糊性(主要是变量的值、引用类型不够知文见义),我在下文的论述中将采用C++/CLI语法来讨论上述问题。
1. 二阶段延迟特化机制
既然决定从CLR下手,不妨让我们来先看看托管泛型的具体特化机制。从编译的角度,对于泛型技术而言,一直以来存在着两种底层实现机制:一种称为代码特化(Code Specilization),如C++模板,编译器将根据不同的类型参数对模板进行特化,其结果就是n份模板,m种类型参数组合,编译后一共n×m份本地代码,异常灵活是其主要特点,其缺陷在于代码膨胀,过分特化导致Name Mangling泛滥,给调试造成了不便;而另一方面,Java则采用了另一种泛型模式:代码共享(Code Sharing),这主要是因为它具备纯粹面向对象的类型系统,举个例子,List<T>,不管List<String>还是List<int>,均共享同一份代码,在使用泛型时Java对String和int均当作引用类型看待;这种方式具有近乎完美的类型结构,代码简洁、轻便,但操作效率低,同时丧失了部分灵活性。
.net CLR中的托管泛型机制非常有意思,它权衡了上述两种方式的优缺点,采用了一种混合模式(Hybrid Model)来实现托管泛型的特化,其过程分为两大步骤,这里我专门画了张图,图中以C++/CLI中的托管数组array<T>为例给出了整个过程:
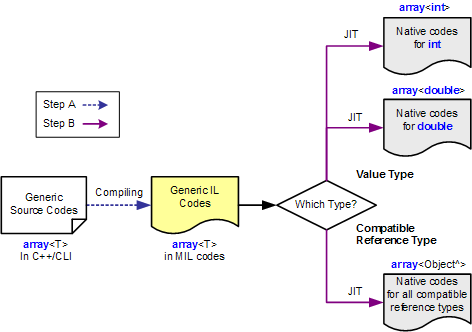
Step B:在CLR运行时JIT编译过程中,将IL代码即时编译成本地代码的特化过程;
步骤A中,存在着一个非常有意思的现象,那就是:无论存在着多少种类型参数组合,也无论类型参数是值类型的还是引用类型的,泛型的源码总是被编译成为唯一的一份IL代码,这份代码为所有特化所共用;即步骤A这一从源程序到IL的编译过程采用的是Code Sharing的泛型实现机制(这里的Code指的是IL代码)。以IL这种中间代码表示在Assembly级别上实现Code Sharing是托管泛型实现“编译后的抽象代码复用”的一个技术关键,因为保证了泛型不会过早特化,使得Assembly之间能够实现泛型代码的相互引用和复用,相比之下,缺失了中间代码表述层的传统C++模板技术就做不到这一点。
那么,IL形式的“抽象”代码究竟是在何时、何处被特化成具体的二进制本地代码呢?答案是在CLR运行时的Just-In-Time编译过程中。这个从泛型IL代码特化到本地代码的过程我们可以用步骤B来表示,其情况比步骤A更加有趣:以array<T>为例,在JIT编译之前,CLR将判断T的类型(空穴来风:根据的是一个名为MethodDesc的内部隐含方法字段-_-b,可类比元数据),当T为值类型时,假使存在着2种值类型特化版本array<int>和array<double>,JIT将分别为其编译2个不同版本的本地代码;而当T为引用类型时,无论是array<String^>也好,array<Thread^>、array<Int32^>也罢,JIT均只生成一份本地代码(可以简单地理解为array<Object^>),该特化代码版本为所有兼容的引用类型参数所共享(注意,此处应该结合类型参数的基类-接口约束体会,JIT编译是运行时类型校验的关键屏障之一;如果引用类型参数不符合约束,首先编译器就会报错,即使采用动态代码emit来逃避静态编译,也逃不过JIT这一关,JIT最终将会发现类型参数不兼容并抛出异常中断程序执行)。
最后再说说在跨Assembly引用过程中JIT对值类型特化的一些主要指导思想。举个例子,存在两个Assembly,AX和AY,其中AX被AY所引用,假设array<T>是在AX中定义的,同时在AX中存在着array<float>和array<bool>两种特化形式,并且在执行过程中已经被特化过了,而在后继的执行流中AY又引用了两种array的特化版本,array<float>和array<char>,此时,JIT将直接重用为AX生成的array<float>本地代码,而仅需额外再帮AY编译特化一份array<char>即可。CLR特有的托管对象模型能够保证这一代码共享过程不会发生任何问题。
由上可以看出,.net CLR对托管泛型采用了一种延迟特化的混合策略:即,在尽可能多地保证Code Sharing的同时进行增量的JIT Code Specialization,这里的Code Sharing包括泛型的IL代码和运行时可以重用的本地二进制特化代码,而本地二进制特化代码重用的准则则为:对于所用兼容的(即符合约束的)引用类型参数,一概重用同一份专用特化代码;对于值类型参数,则具体情况具体分析,尽可能地复用执行路径中已经特化过的本地代码,而只重新即时编译那些新碰到的值类型特化版本。
2. 对值类型Boxing/Unboxing的抑制
明确了托管泛型的底层特化机制,我们便可以来看看值类型特化的泛型中是不是需要装箱/拆箱及其中个原因了。所谓装箱(Boxing),就是在托管堆中对堆栈中的值类型变量进行对象封装,生成一份值类型变量的对象引用副本,无论是显式的还是隐式的;而拆箱这一概念则比较容易混淆,准确来说,它应该指的是这么一种行为:首先在堆栈中隐式地分配一个临时值变量,然后再把对象引用副本中的值Copy回这个临时值变量。严格说来unboxing的重要性不及boxing,因为其时空开销远比boxing小,而且很容易进行编译优化(比方说寄存器优化),但不管怎么说,我还是比较赞同这样一种观点:“严格辨别unboxing操作的主要标准,在于是不是隐式分配了临时堆栈变量”,因为bit-wise copy始终是一个共性的存在,而不管是从托管堆到堆栈还是从堆栈到堆栈。考察bit-wise拷贝对性能的影响不是本文重点。
先考察不用泛型的情况,用普通集合类ArrayList来组装一个10000个int的数组,每一个int都必须进行boxing,然后以Object^的reference handle形式逐个地存储进ArrayList,说得形象点(当然不那么严谨,为便于想象),我们可以将ArrayList的对象模型类比成“Object对象的指针数组”,其中的每一个元素都是一个指向Int32对象的指针(Int32继承自ValueType,而后者又继承自Object);可以看到,在组装这个ArrayList时,将10000个int中的每个int都boxing成Int32对象的开销是相当显著的,而在读写这些数组元素时,每一次访问都要经历两次间接引用,一次是对ArrayList^的引用,而另一次则是对ArrayList中Object^的引用,这显然降低了效率。
接下来再看看.net 2.0中采用了泛型技术的集合类是如何工作的。仍以array<T>为例,考察语句:array<int>^ t=gcnew array<int>(10000),在运行时,当JIT发现T为一个整型值类型时,它将把array的构造行为特化编译成为在托管堆中以字节连续的形式分配10000*4个字节的形式(以某种对象封装的形式),其对象模型可以简单地类比为一个托管堆中的int数组,而不是一个Int32指针数组及其许许多多的Int32对象;在组装这个array<int>数组时,我们仅需简单地将多个int拷贝进托管堆中的某连续地址即可,全然无需进行boxing;而当我们在访问其中的int时,也只需要进行一次对array<int>^的间接引用即可,从而保证了值类型集合类的处理效率。而另一方面,考察一下array<Int32^>^ t=gcnew array<Int32^>(10000),嗯…撇开ArrayList长度的动态性不谈,实际上我们可以发现,JIT对array<Int32^>在对象模型上的编译处理与ArrayList是基本相似的,说白了,都是Object^的数组(或队列,本质是相同的),无非静态数据结构和动态数据结构的区别而已。由上述组装、引用的过程可见,泛型对值类型boxing/unboxing的抑制作用是显著的,值得一提的是,这种抑制作用不仅体现在集合类的处理当中,也体现在泛型方法的参数、返回值传递等方面,大家可以慢慢体会。一言以蔽之,这全部归功与.net CLR对值类型/引用类型的区别对待、及其托管泛型本身所具备的延迟(即时)特化机制。至于性能方面量化的profiling,大家可以看看博客堂Sunmast的Blog[4],这里就不重复了。
3. 总结与体会
总结是我写此文的主要目的,最后顺带铺开来再谈点自己的体会。兼备Code Specialization和Code Sharing的优点、具备小工作集、代码简洁是采用托管泛型机制最容易看到的好处,可是它的核心特色在哪里? 而我们又能从它身上看到点什么深层次的东西? 这是我一直都在思考的问题。首先,它不仅能够充分利用C#/C++/CLI等编译器所提供的静态类型检查和编译优化功能,而且还使得运行时的强类型约束及代码优化成为可能,这一过程是在JIT特化时实现的,它体现了CLR最本质的两个设计思想:运行时托管和无处不在的强类型;其次,从它身上我们也可以看到CLR追求实效性的核心设计—实现理念,从类型系统的本质上说,CLR是一个聪明的混血儿,它通过添加值类型这种Shortcut,从而在整体继承纯面向对象类型系统的同时,尽最大可能保证处理的高效。而另一方面,我们也可以大胆地加以推断,为了实现托管泛型中的Code Sharing和运行时类型约束,CLR 2.0对IL、JIT、乃至是托管对象模型都进行了不小的改进,这些改动也许无法实现向下兼容,幸好这一切都无关紧要,反正CLR 1.0/1.1不支持泛型。但不管怎么说,因小及大,是运行时环境本身赋予了托管泛型强大的活力,而这种程度的技术张力仅靠单一的语言或编译器(不禁再次联想起C# 2.0中的functional programming、yield和partial)是无法做到的。
4. 主要参考文献
1. Professional .NET 2.0 Generics, Tod Golding, Wrox, 2005
2. Essential .NET vol.1: The Common Language Runtime, Don Box, Pearson Edu., 2003
3. Shared Source CLI Essentials, David Stutz, O'Reilly, 2003
4. Sunmast's Blog, http://blog.joycode.com/sunmast/archive/2005/12/16/csharp_generic_misleading.aspx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号