
python 实现主成份分析
from sklearn.datasets import load_iris
import numpy as np
from numpy import linalg
def pca(X,k):
#去中心化
X = X-X.mean(axis = 0)
#每一行代表特征,每一列代表样本
X_cov = np.cov(X.T,ddof = 0)
#特征值,和特征向量
eigenvalues,eigenvectors = linalg.eig(X_cov)
#前k个最大的特征向量
klarge_index = eigenvalues.argsort()[-k:][::-1]
k_eigenvectors = eigenvectors[klarge_index]
return np.dot(X,k_eigenvectors.T)
iris = load_iris()
X = iris.data
k =2
X_pca = pca(X,k)
#查看各特征值的贡献率
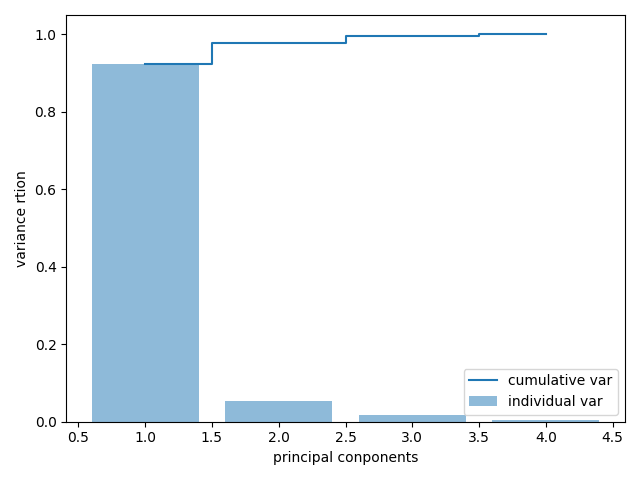
from sklearn.datasets import load_iris import numpy as np from numpy import linalg import matplotlib.pyplot as plt iris = load_iris() X = iris.data X = X-X.mean(axis = 0) #每一行代表特征,每一列代表样本 X_cov = np.cov(X.T,ddof = 0) #特征值,和特征向量 eigenvalues,eigenvectors = linalg.eig(X_cov) total =sum(eigenvalues) var_exp = [ (i/total) for i in sorted(eigenvalues,reverse = True)] cum_var_exp =np.cumsum(var_exp) plt.bar(range(1,5),var_exp,alpha=0.5,align = 'center',label = 'individual var') plt.step(range(1,5),cum_var_exp,where = 'mid',label = 'cumulative var') plt.ylabel('variance rtion') plt.xlabel('principal conponents') plt.legend(loc = 'best') plt.show()
#运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号