
学习Sci. Adv. 关于AMP_generator文章-复现
- 环境配置:在Anaconda Prompt中创建虚拟环境“AMPdesign”,python=3.9。本人新手,根据大佬帖子安装pytorch:“ https://zhuanlan.zhihu.com/p/1897261918172987396 ”,本次安装的是2.5.1版本,conda途径安装,安装代码:
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=11.8 -c pytorch -c nvidia
![image]()

- pycharm中打开项目,配置刚刚新建的虚拟环境:文件→设置→项目→Python解释器→添加解释器→添加本地解释器→Conda环境:使用现有环境→选择AMPdesign
![image]()

- 先阅读README,再开始代码复现
3.1 首先运行train_AMP_GPT.py文件。这个文件有几个小错误需要改,按照要求改就好了,比如文件名不统一,np.Inf需改为np.inf等。训练中的状态: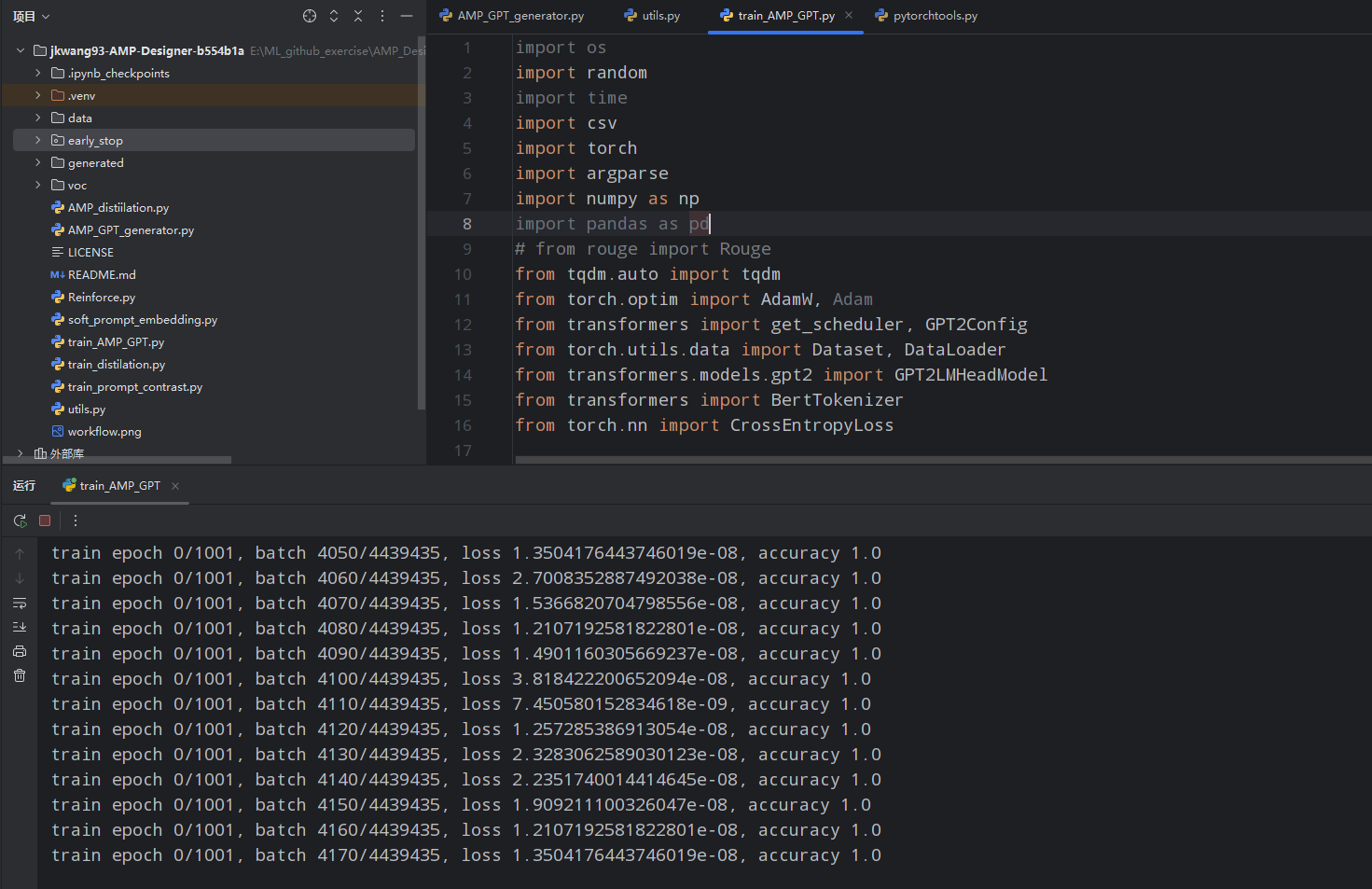
本地太慢确实不适合跑完整的训练,修改参数epoch=2,batch_size=4, warmup_steps=10进行测试。
3.2
本地先测试。首先将data/prompt_data里面的两个带标签数据集合并,并加上3个表头:comment_text,id,label。
第二至关重要。修改测试参数,将batch_size调为8,epoch调为1,--log_step调为10.不然本地跑不动,会显存报错。
第三,把Save model checkpoint注释掉。不然硬盘存储真的扛不动!!!
注释完后貌似有格式问题,新代码如下:

第四,把17行的from pytorchtools import EarlyStopping修改为from early_stop.pytorchtools import EarlyStopping。
还有一些细节的改动,可以直接debug。训练结果:
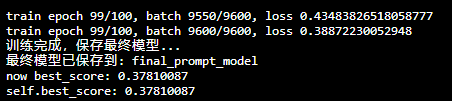
但是好像没有验证集?看不出来有没有过拟合。这样的话最好把带标签的数据给划分一下。
3.3
这一步我们根据步骤先把模型蒸馏一下。
持续更新中...
欢迎指正交流,共同学习进步。邮箱:z1437143688@126.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号