通俗易懂理解——浮点与定点的计算机表示及互转
https://zhuanlan.zhihu.com/p/63897066
在神经网络当中,为了尽快落地就需要考虑到数据存储以及速度问题,这时候将浮点数转为定点数就是一种比较常规的做法,也就是涉及到Binary neural networks和quantization,这部分有待下一篇继续补充,现在就要搞定浮点与定点的计算机表示及互转。看了挺多网上内容,智商有限没有完全明白,不过最后还是找到了两篇写得比较清晰的,特此结合起来解决当前问题。
篇章1
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
无论是单精度还是双精度在存储中都分为三个部分:
- 符号位(Sign) : 0代表正,1代表为负
- 指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
- 尾数部分(Mantissa):尾数部分
其中float的存储方式如下图所示: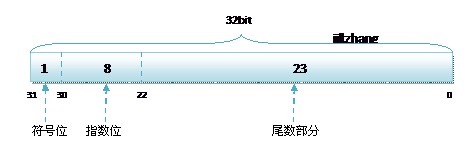
而双精度的存储方式为:
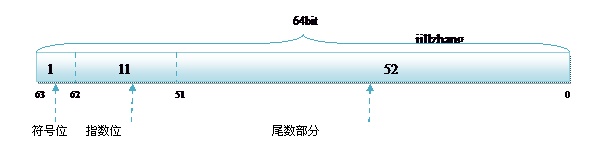
R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25* ;而120.5可以表示为:1.205*
,这些小学的知识就不用多说了吧。
而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01。
在此插播二进制小数与十进制进行互换的做法:
1、十进制转为二进制:十进制0.125转二进制为0.001。就是将小数部分不断乘以2,每次取整数部分,直到为1。

2、二进制转为十进制:二进制0.001转为十进制为0.125。将各个位乘以2的负次方,最后将得到的结果相加,0*1/2+0*1/4+1*1/8得十进制的0.125

120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.0001* ,1110110.1可以表示为1.1101101*
,任何一个数都的科学计数法表示都为1.xxx*
,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。
首先看下8.25,用二进制的科学计数法表示为:1.0001*
按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130(尚未理解这个127的意义,数值就是 -1) ,位数部分为,故8.25的存储方式如下图所示:
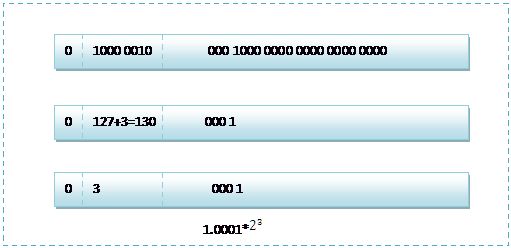
而单精度浮点数120.5的存储方式如下图所示:
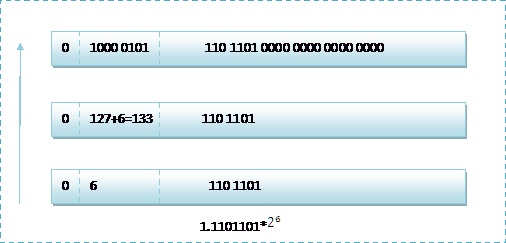
那么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存数据:0100001011101101000000000000,首先我们现将该数据分段,0 10000 0101 110 1101 0000 0000 0000 0000,在内存中的存储就为下图所示:

根据我们的计算方式,可以计算出,这样一组数据表示为:1.1101101*2**6=120.5
而双精度浮点数的存储和单精度的存储大同小异,不同的是指数部分和尾数部分的位数。所以这里不再详细的介绍双精度的存储方式了,只将120.5的最后存储方式图给出,大家可以仔细想想为何是这样子的

下面我就这个基础知识点来解决一个我们的一个疑惑,请看下面一段程序,注意观察输出结果
float f = 2.2f;
double d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
f = 2.25f;
d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
可能输出的结果让大家疑惑不解,单精度的2.2转换为双精度后,精确到小数点后13位后变为了2.2000000476837,而单精度的2.25转换为双精度后,变为了2.2500000000000,为何2.2在转换后的数值更改了而2.25却没有更改呢?很奇怪吧?其实通过上面关于两种存储结果的介绍,我们已经大概能找到答案。首先我们看看2.25的单精度存储方式,很简单 0 1000 0001 001 0000 0000 0000 0000 0000,而2.25的双精度表示为:0 100 0000 0001 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,这样2.25在进行强制转换的时候,数值是不会变的,而我们再看看2.2呢,2.2用科学计数法表示应该为:将十进制的小数转换为二进制的小数的方法为将小数*2,取整数部分,所以0.282=0.4,所以二进制小数第一位为0.4的整数部分0,0.4×2=0.8,第二位为0,0.8*2=1.6,第三位为1,0.6×2 = 1.2,第四位为1,0.2*2=0.4,第五位为0,这样永远也不可能乘到=1.0,得到的二进制是一个无限循环的排列 00110011001100110011... ,对于单精度数据来说,尾数只能表示24bit的精度,所以2.2的float存储为:

但是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。
篇章2
1. 这篇博客将要讨论什么?
说来惭愧,作为计算机科班出身的人,计算机基础知识掌握并不扎实,这里的基础指的是计算机体系结构中的内容,诸如数据的表示和处理,如float的表示和运算等。看《CSAPP》方知人家老外把这个东西当成重中之重,大量详细的原理介绍,并配套大量例题。当初本科学的时候,很简单的了解了下概念而已,所以应该直接将《CSAPP》当做教材来用,里面习题全做,这样CS出来的基本知识将掌握的很扎实。
学艺不精的后果就在于:学而不思则罔。圣人太厉害了,总结得很到位。比如最近项目中涉及到浮点和定点的转换,自己就有点蒙,边看边实验,还算理解了,作文以记之。
一直以来,程序中接触的数据类型都是int整型,char字符型,float单精度浮点型,double双精度浮点型。看到浮点和定点一直不知道如何划分这个概念的范畴。以为浮点就是float表示小数,定点就是int可表示整数而已。经过学习明白了显然是错误的。应该是这样划分的:
浮点:小数点非固定的数,可表示数据范围较广,整数,小数都可表示。包含float,double;
定点:小数点固定,可表示整数,小数。int本质是小数点位于末尾的32位定点数而已;
有了这个认识,后面的讨论就可以开始了。
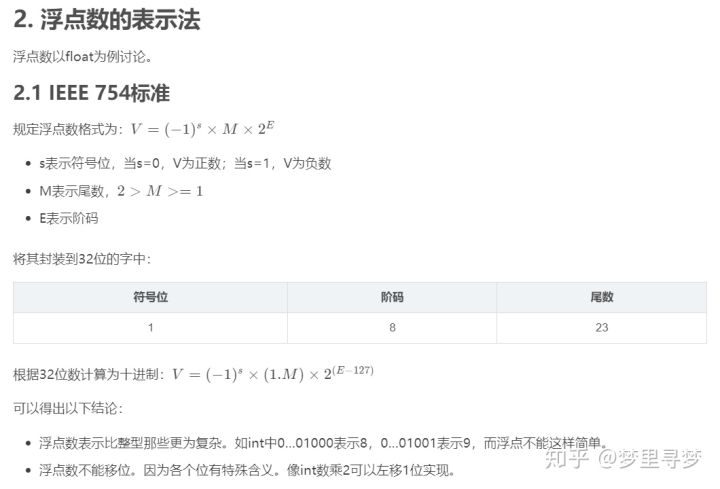
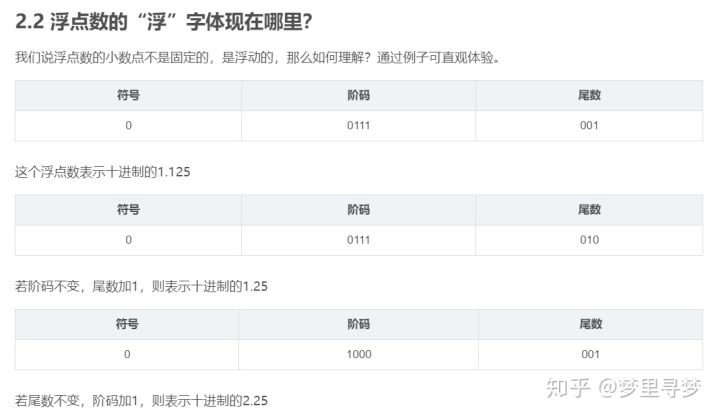
3. 定点数的表示法
对于计算机来说,浮点定点的概念是看不见的,因为它只能看到:0…00001110,至于它表示多少,是逻辑层面的设置。你如果让它是int那就按照int表示法对每个位赋予意义,如果你让它是float就按照float表示法赋予意义。
对于00011100 表示的定点数:
- 如果我们设定小数点是位于最后一位的,即00011100. 则其表示28
- 若设定小数点位于后三位的,即00011.100 则其表示3.50
- 若设定小数点位于后四位的,即0001.1100 则其表示1.75
可以看到:
- 小数位数越多,表示的精度越高。若小数点后有n位,则其表示的最大精度为1/(2^n)(这里相当于将二进制切换到十进制来看精度。);
- 整数位数越多,可表示的最大值越大。
以8位为例,最高位为符号位:
- 若整数位占4位,小数位占3位,则其最大精度为0.125,最大值为15.875
- 若整数位占5位,小数位占2位,则其最大精度为0.250,最大值为31.750
- 若整数位占6位,小数位占1位,则其最大精度为0.500,最大值为63.500
- 若整数位占7位,小数位占0位,则其最大精度为1.000,最大值为127
4. 浮点数 & 定点数
4.1 为何要把浮点数转换为定点数呢?
这来源于项目中神经网络的需求,网络中大量的参数,如果全部用F32表示,一是占用空间大,二是读取效率不高。
如果我们可以将某些浮点数转换为定点数表示,在接受精度损失的前提下,每次就可以读取多个进行运行,可显著提高运算效率。
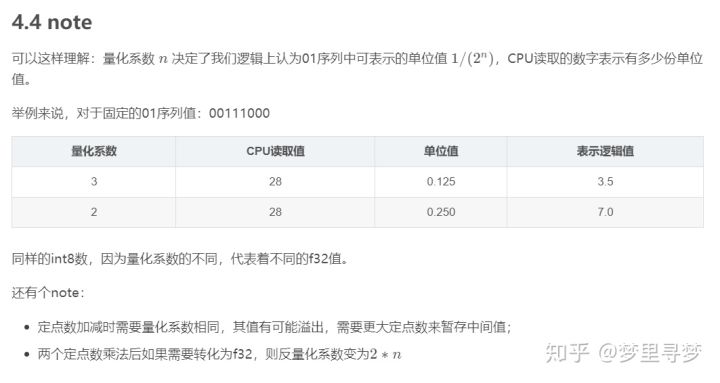
举例来说,我们用8位定点数,1个符号位,4个整数位,3个小数位,则其可表示范围是-16.00~15.875,最大精度0.125。
有几个浮点数:0.145,1.231,2.364,7.512,每个需要32bit表示。
如果我们将每个量化成一个8位定点数,比如通过某种方法得到:1,10,19,60
此时每个数需要8bit表示。那么读一个浮点数,可以同时读4个定点数,且计算效率可以提高。当然这样做是有风险的:
- 损失精度,比如再将上述定点数转化为浮点数:0.125,1.250, 2.375,7.500;
- 定点数表示范围有限,加法有可能会溢出,需要拿int16或int32来暂存中间结果;

5. 总结
可以看到:
- 浮点数和定点数的转换是一种映射。将较为密集的数据空间(F32)映射到较为稀疏的空间(int8);
- 定点数的小数点实际中是没有的,这只是我们逻辑上的一种设定。01序列是一样的,CPU读取都是相同的,因为我们逻辑上小数点的不同位置,我们认为它代表的值是不同的;
大神博客1:https://www.cnblogs.com/jillzhang/archive/2007/06/24/793901.html
大神博客2:https://blog.csdn.net/niaolianjiulin/article/details/82764511

 浙公网安备 33010602011771号
浙公网安备 33010602011771号