NLP历程从规则到统计
NLP历程从规则到统计
机器智能的设想最早是是由计算机科学之父阿兰\(\cdot\)图灵(Alan Turing)在1950年<
基于规则
20世纪60年代,科学家认为理解自然语言的基础是做好两件事:语句分析和语义分析。对于我们从小学习英语,要学习语法规则(Grammer Rules)、词性(Part of Speech)和构词法(Morphologic)等。这种语言规则是学习好英语的方法,并且这些语法规则可以用计算机的算法描述,就坚定基于规则的自然语言处理的信心。
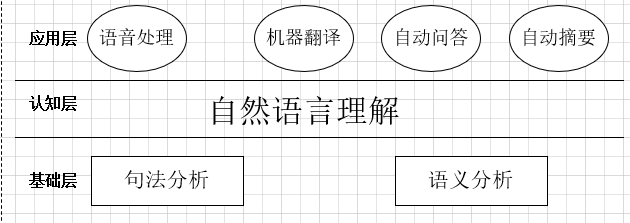
句法分析:将句子分为主语、动词短语(谓语)和结尾符号三部分。之后对每一部分接着进一步分析得到文法分析树(Syntactic Parse Tree,也简称为Prase Tree)。
如对句子徐志摩喜欢林徽因。进行语法分析,构建的语法分析树。
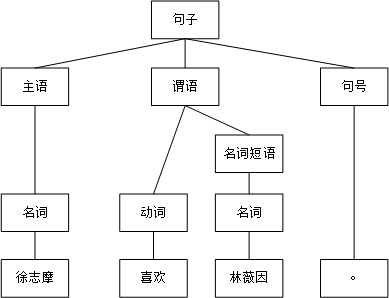
构建语法树的语法分析规则也被称为重写规则(Rewrite Rules)。构建的文法分析器构建语法树的方法的对于简答句子可以实现,然而对于复杂的语句这种方法并不适用。存在两个缺点:(1)要实现真实的语句的语法规则,语法规则数量需要很多,覆盖20%的真实语句就可能需要几万条规则实现,并且语言句子随着时间的会不断增加,所以需要出现新的句子需要添加新的规则。(2)自然语言的语法和高级程序语言的语法规则不同。自然语言的文法规则是复杂的上下文有关文法(Context Dependent Grammer),而程序语言是便于计算机解码的上下文无关文法(Context Independent Grammer).
语义的处理相比于文法分析面临更大的问题。自然语言中的词的多义很难用规则描述,而是严重依赖上下文,或者有些是常识。
‘The pen is in the box.’和‘The box is in the pen.’这两句话中的pen含义不同,分别是钢笔\围栏的意思。
基于规则的句法分析(包括文法分析和语义分析)存在的问题。
基于统计
弗里德里克\(\cdot\) 贾里尼克和IBM华生实验室使用基于统计的方法解决语音识别的问题,将与新识别率从70%提升到了90%。2005年随着基于Google基于统计的方法翻译系统全面超过基于规则方法的SysTran翻译系统之后,基于统计方法替代了基于规则的方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号