
Pytorch实战学习(四):加载数据集
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
Dataset & Dataloader
1、Dataset & Dataloader作用
※Dataset—加载数据集,用索引的方式取数
※DataLoader—Mini-Batch
通过获得DataSet的索引以及数据集大小,来自动得生成小批量训练集
DataLoader先对数据集进行Shuffle,再将数据集按照Batch_Size的长度划分为小的Batch,并按照Iterations进行加载,以方便通过循环对每个Batch进行操作
Shuffle=True:随机打乱顺序
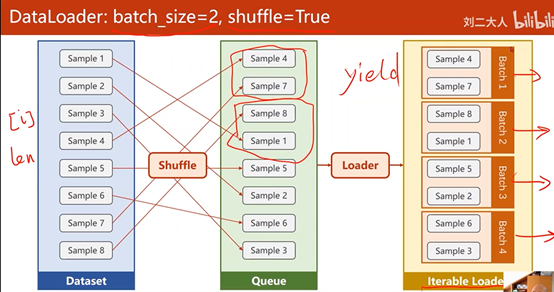
2、Mini-Batch:
利用Mini-Batch均衡训练性能和时间
在外层循环中,每一层是一个epoch(训练周期),在内层循环中,每一次是一个Mini-Batch(Batch的迭代)
for epoch in range(training_epochs): for i in range(total_batch):
3、相关术语
※Epoch:所有样本都参与了一次训练
※Batch-size:进行一次训练(前馈、反馈、更新)的样本数
※Iteration:有多少个Batch,每次
Epoch = Batch-size * Iteration

4、代码部分
在构造数据集时,两种对数据加载到内存中的处理方式如下:
①加载所有数据到dataset,每次使用getitem()读索引,适用于数据量小的情况
②只对dataset进行初始化,仅存文件名到列表,每次使用时再通过索引到内存中去读取,适用于数据量大(图像、语音…)的情况
import torch import numpy as np ## Dataset为抽象类,不能被实例化,只能被其他子类继承 from torch.utils.data import Dataset ## 实例化DataLoader,用于加载数据 from torch.utils.data import DataLoader ## Prepare Data class DiabetesDataset(Dataset): def __init__(self, filepath): xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32) ## 获取数据集长度 self.len = xy.shape[0] self.x_data = torch.from_numpy(xy[:, :-1]) self.y_data = torch.from_numpy(xy[:, [-1]]) ## 索引:下标操作 def __getitem__(self, index): return self.x_data[index], self.y_data[index] ## 返回数据量 def __len__(self): return self.len dataset = DiabetesDataset('diabetes.csv.gz') ##num_workers多线程 train_loader = DataLoader(dataset = dataset, batch_size = 32, shuffle = True, num_workers = 0) ##Design Model ##构造类,继承torch.nn.Module类 class Model(torch.nn.Module): ## 构造函数,初始化对象 def __init__(self): ##super调用父类 super(Model, self).__init__() ##构造三层神经网络 self.linear1 = torch.nn.Linear(8, 6) self.linear2 = torch.nn.Linear(6, 4) self.linear3 = torch.nn.Linear(4, 1) ##激活函数,进行非线性变换 self.sigmoid = torch.nn.Sigmoid() ## 构造函数,前馈运算 def forward(self, x): x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) return x model = Model() ##Construct Loss and Optimizer ##损失函数,传入y和y_pred,size_average--是否取平均 criterion = torch.nn.BCELoss(size_average = True) ##优化器,model.parameters()找出模型所有的参数,Lr--学习率 optimizer = torch.optim.SGD(model.parameters(), lr=0.01) ## Training cycle ## windows环境下DataLoader的num_workers设置为多线程,需要将主程序(对数据操作的程序)封装到函数中 if __name__ =='__main__': for epoch in range(100): #enumerate:可获得当前迭代的次数 for i, data in enumerate(train_loader, 0): ## 准备数据 inputs, lables = data ##前向传播 y_pred = model(inputs) loss = criterion(y_pred, lables) print(epoch, i, loss.item()) ##梯度归零 optimizer.zero_grad() ##反向传播 loss.backward() ##更新 optimizer.step()
!!两个问题!!
①DataLoader的参数num_workers设置 >0
在windows中利用多线程读取,需要将主程序(对数据操作的程序)封装到函数中
## Training cycle ## windows环境下DataLoader的num_workers设置为多线程,需要将主程序(对数据操作的程序)封装到函数中 if __name__ =='__main__': for epoch in range(100): #enumerate:可获得当前迭代的次数 for i, data in enumerate(train_loader, 0):
但是运行还是报错,只能把num_workers = 0
②运行结果:损失不会一直下降,改小了学习率也不行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号