
【MOOC】Requests库
一、安装Requests库
cmd命令行 --- pip install requests
二、Requests库7个主要方法

1、requests.request(method , url , **kwargs)
method :请求方法 ‘GET’、’HEAD’、’POST’、’PUT’、’PATCH’、’delete’、’OPTIONS’
**kwargs :控制访问参数,可选项【13个】
(1) params :字典或字节序列,作为参数增加到url中,把参数提交到服务器,服务器根据参数筛选资源返回【‘GET’】
(2) data :字典、字节序列或文件对象,作为Request的内容【‘POST’、’PUT’】
(3) json :JSON格式数据,作为Request的内容【‘POST’、’PUT’】
(4) headers :字典,HTTP定制头【‘POST’、’PUT’】模拟浏览器
(5) cookies :字典或CookieJar【‘POST’、’PUT’】
(6) auth :元组,支持HTTP认证功能
(7) files :字典,传输文件
(8) timeout :设定超时时间,秒
(9) proxies :字典,设定访问代理服务器,可以增加登录认证,防止爬虫逆追踪
(10) allow_redirects :True/False,默认True,重定向开关
(11) stream :True/False,默认True,获取内容是否立即下载
(12) verify :True/False,默认True,认证SSL证书开关
(13) cert :本地SSL证书路径
2、requests.get(url,params=None,**kwargs)
Request对象 :向服务器请求资源
Response对象 :返回包含服务器资源

3、requests.head(url , **kwargs) 获取头部信息,资源概要
4、requests.post (url ,data=None , json=None , **kwargs) 附加新数据
5、requests.put (url , data=None , **kwargs) 覆盖原url资源的内容
6、requests.patch (url , data=None , **kwargs) 局部修改
7、requests.post (url ,**kwargs) 删除请求
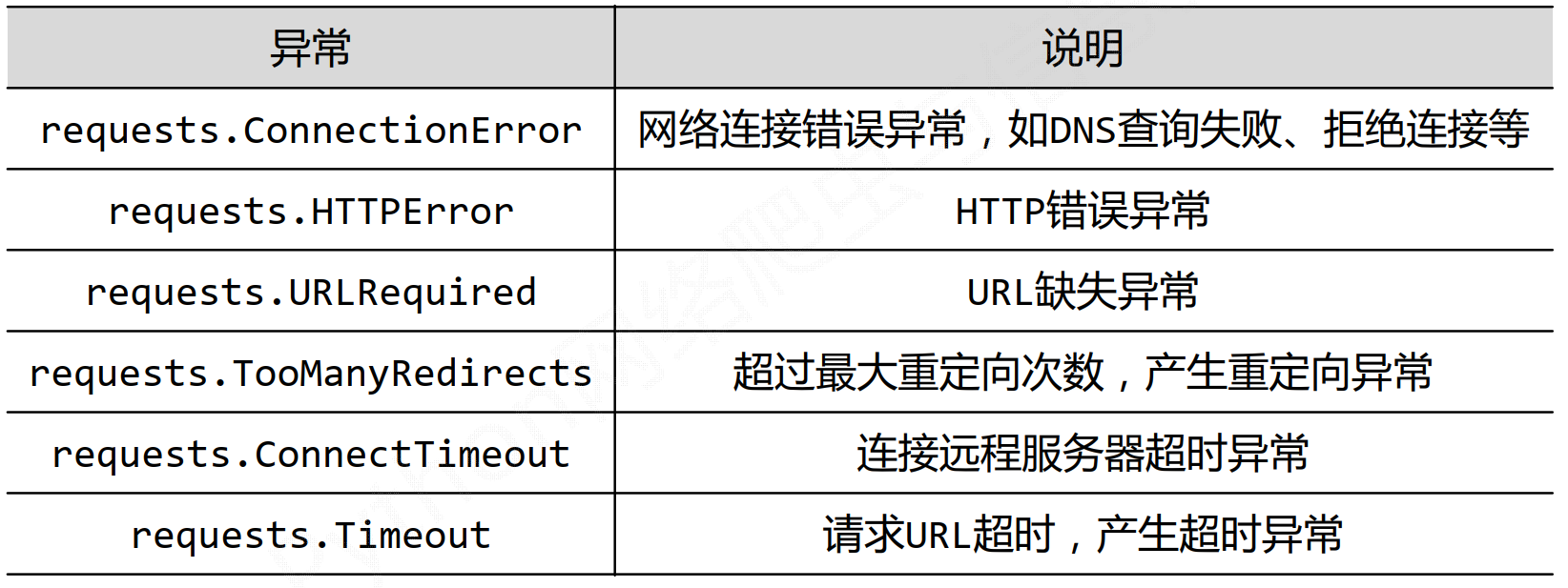
三、requests库异常处理
四、爬取网页通用框架
可抛出异常,使网页爬取更有效
import requests
def getHTMLText(url):
try:
r = requests.get(url , timeout=30)
r.raise_for_status() #如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__ == '__main__':
url="http://www.baidu.com"
print(getHTMLText(url))
五、实例
1、京东商品页面爬取
import requests
url = "https://item.jd.com/10606162030.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败!")
2、亚马逊商品页面爬取
亚马逊会以来源审查方式拦截不友好的User-Agent(爬虫)
查看headers内的User-Agent为 'python-requests/2.22.0'会被拦截
需要将User-Agent改为'Mozilla/5.0',浏览器的标准headers,模拟浏览器向服务器发起请求
import requests
url = "https://www.amazon.cn/dp/B07FTXBNVL?ref_=Oct_DLandingS_D_5d3c58a2_62&smid=A3CQWPW49OI3BQ"
try:
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败!")
3、百度/360搜索关键词提交
## 百度关键词接口 https://www.baidu.com/s?wd=keyword
import requests
keyword = 'python'
try:
kv = {'wd':keyword}
r = requests.get('http://www.baidu.com/s',params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print('爬取失败')
##360关键词接口 https://www.so.com/s?q
import requests
keyword = 'python'
url = 'http://www.so.com/s'
try:
kv = {'q':keyword}
r = requests.get(url,params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print('爬取失败')
4、网络图片的爬取与存储
#网络图片的爬取与存储
import requests
import os
url = 'http://image.biaobaiju.com/uploads/20190728/18/1564309609-PTqdhHcgYt.jpeg'
root = 'C://pic//' ##存储到C盘下的pic文件中
path =root + url.split('/')[-1] #提取url最后一个‘/’后面的字符作为存储图片的名字
try:
if not os.path.exists(root): ##判断根目录是否存在,若不存在,建立目录
os.mkdir(root)
if not os.path.exists(path): ##判断文件是否存在,若不存在,则根据url获取
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content) ##r.content 返回内容的二进制形式
f.close()
print('文件保存成功!')
else:
print('文件已经存在!')
except:
print('爬取失败!')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号