
python数据分析(三)
数据分析处理库(Pandas)
pandas是数据处理及分析的,底层计算由Numpy来完成,将复杂的操作封装起来,使其用起来十分高效、简洁。
import pandas as pd
数据预处理
df = pd.read_csv('../data/Titanic-dataset-master/df.csv')
df.head ()
df.tail()
df.info()
df是Pandas工具包中最常见的基础结构
df.index //索引
df.columns //列名
df.values //值
df.dtypes //列结构
df=df.set_index('Name')
df.head()
age=df['Age']
age['Braund, Mr. Owen Harris']
df[['Age','Fare']][:5]
//iloc():用位置找数据
df.iloc[0]
df.iloc[0:5]
df.iloc[0:5,1:3]
//loc():用标签找数据
df.loc['Braund, Mr. Owen Harris'] //取某一人数据
df.loc['Braund, Mr. Owen Harris','Fare'] //某一人某个指标数据
df.loc['Braund, Mr. Owen Harris':'Owen Harris',:] //某批数据
df.loc['Braund, Mr. Owen Harris','Fare'] = 100 //修改某个数据
//bool类型作为索引
df[df['Fare'] > 40][:5] //Fare列大于40的行筛选出来
df.loc[df['Sex'] == 'male','Age'].mean() //计算所有男性年龄的平均值
data={'country':['China','America','India'],'population':[14,3,12]}
df_data = pd.DataFrame(data) //创建df数据集结构
//显示及设置最大行及列
pd.get_option('display.max_rows')
pd.set_option('display.max_rows',6)
pd.get_option('display.max_columns')
pd.set_option('display.max_columns',6)
//series是DataFrame中数据中单独取某列数据
data = [10,11,12]
index=['a','b','c']
s = pd.Series(data=data,index=index)
s.loc['b']
s1.replace(to_replace = 100,value=101,inplace=True) //将100替换为101,inplace为True确实替换,False为仅仅打印的
//更改series的索引
s1.index=['a','b','d']
s1.rename(index = {'a':'A'},inplace = True)
//增加数据
data=[100]
index=['h']
s2=pd.Series(data=data,index=index)
s3=s1.append(s2)
s3['j']=500
//删除数据
del s1['A']
s1.drop(['b','d'],inplace = True)
数据分析
df = pd.DataFrame([[1,2,3],[4,5,6]],index=['a','b'],columns = ['A','B','C'])
df.sum(axis=0/1) //默认对每列/行计算
df.mean() //均值
df.median() //中位数
df.max() //最大
df.min() //最小
df.describe()
df.cov() //协方差
df.corr() //相关系数
df['sex'].vaule_counts(ascending = True) //该列所有属性个数(从小到大)
df['Age'].value_counts(ascending = True,bins = 5) //指定划分为几组

group_names=['Yonth','Old']
pd.value_counts(bins_res,labels=group_names) //标签分类计数,分版本0.24.2版本目前没有
df.pivot_table(index='Sex',columns='Pclass',values='Fare',aggfunc='max/count') //各个船舱最大票价/人数
//成年与未成年人幸存的概率
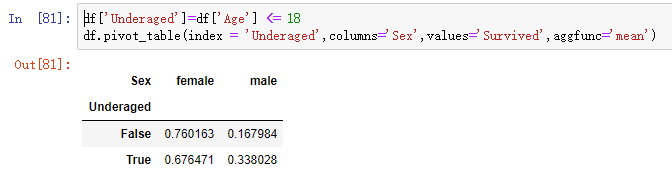
//groupby操作
df.groupby('key').sum() //分组求和
df.groupby('key').aggregate(np.mean) //分组求均值
df.groupby('Sex')['Age'].mean() //分组求均值
df.groupby('Sex')['Age'].count() //分组计数
df.groupby('Sex')['Age'].describe() //分组信息描述
df.groupby('Sex')['Age'].agg([np.sum,np.mean,np.std]) //自定义信息
//merge合并函数

Data.sort_values(by=['group','data'],ascending=[False,True],inplace=True)
data=pd.DataFrame({'k1':['one']*3+['two']*4,'k2':[3,2,1,3,3,4,4]}) //创建数据集
data.drop_duplicates() //去除重复行
data.drop_duplicates(subset='k1') //以某一行去除重复行
Df.assign(ration=df['data1']/df['data2']) //增加数据
Df.isnull() //判断函数所有的确实情况
Df.isnull().any(axis=1) //是否存在缺失
Df.fillna(5) //数值填充
//apply自定义函数
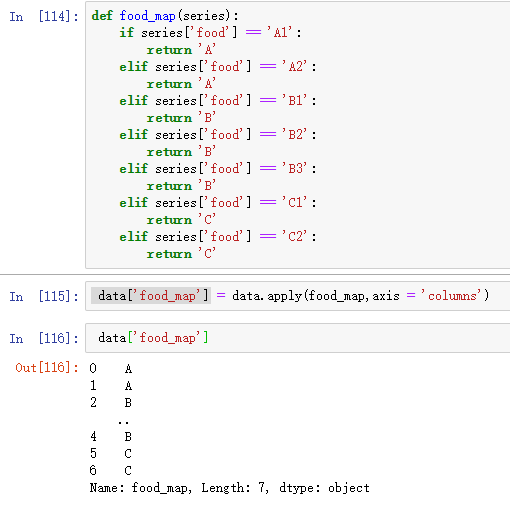
//时间操作
ts=pd.Timestamp('2017-11-24') //转为时间戳
Ts.month //取月
Ts.day //日
Ts+pd.timedelta('5 days') //加5天
Pd.to_datetime(s) //转为日期
Ts.dt.hour/weekday //转为小时周
Pd.Series(pd.date_range(start='2017-11-24',periods=10,freq='12H')) //获得一连串数据
df = pd.read_csv('../data/Titanic-dataset-master/df.csv',index_col=0,parse_dates=True) //将时间特征作为索引
Data['2013']
Data['2012-01':'2012-03']
Data[(data.index.hour > 8) & data.index.hour < 12] //时间序列作为索引
Data.resample('D'/'3D'/'M').mean().head() //以天/3天/月为周期进行采样计算均值
//大数据处理技巧
对数据结构分析及内存占用情况
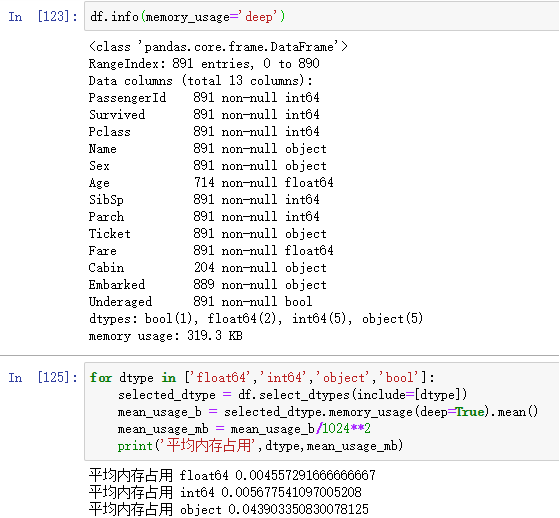
//查看类型转换前后的内存占用情况


 浙公网安备 33010602011771号
浙公网安备 33010602011771号