HBase 和 Phoenix 的结构
HBase 结构



可以看到 HBase 集群由 Master、Region Server、ZooKeeper、HDFS 组成
Master
- 协调管理多个 Region Server,侦测各 Region Server 之间的状态,平衡 Region Server 之间的负载,负责分配 Region 给 Region Server,在 Region Split 后,负责新 Region 的分配,在 Region Server 停机后,负责失效 Region Server 上的 Region 迁移
- 负责表的创建、修改、删除等
- 维护 .META. 表和 -ROOT- 表的信息
- 管理对 Table 的 CRUD 操作
- 允许多个 Master 共存
Region Server
- 管理多个 Region
- 管理 BlockCache
- 管理 WAL(HLog)
- 响应客户端的读写请求
Region
- 每张表都由 Region 组成
- 每个 Region 管理一段按 RowKey 排序的数据,记录 StartKey/EndKey 以快速定位
- 每个 Region 又由多个 Store 组成,每个 Store 对应表中的一个 Column Family
- Store 包括 MemStore 和 StoreFile,一个 StoreFile 又包含一个或多个 HFile
- MemStore 在内存, HFile 在 HDFS
- 数据先写入 MemStore,达到阀值后 flush 到 HDFS 的 HFile,这样一张表就会存在很多个小的 HFile,需要手动或者自动做 Compact 操作进行合并,不然会影响数据读取的性能,而当合并后的文件太大时,又会进行 Region 的拆分,拆分后可以将部分 Region 分配给其他 Region Server 管理
- 数据的改动只会在做 Compact 的时候才真正执行,之前只会做个标记 (HDFS 是不允许改文件内容的)
- Compact 包括 Minor Compact 和 Major Compact,Minor 只合并不删数据,Major 会删数据
BlockCache
BlockCache 是读缓存,将数据预读到内存 (引用局部性:下一条指令或数据很大概率就在附近)
WAL (Write Ahead Log)
HDFS 上的文件,所有写操作都会先记到这个文件后,才会将数据写入数据表,目的是系统崩溃后可以从 WAL 恢复数据
ZooKeeper
- 作为集群节点间的协调器,可以使用 HBase 自带的 ZooKeeper,也可以使用系统的 ZooKeeper
- 作为 Master 的 HA 解决方案,通过 ZooKeeper 保证至少有一个 Master 处于运行状态
- 负责 Region 和 Region Server 的注册
- Java 程序读写 HBase 不是连接 Master,而是连接 ZooKeeper,从 ZooKeeper 中取出相应的 Region Server 信息,然后直接和 Region Server 通信
-ROOT- 表和 .META. 表
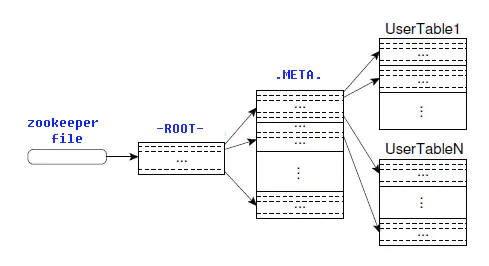
- -ROOT- 和 .META. 也是 HBase 表
- 用户表所有 Region 的元数据被存储在 .META. 表中
- 随着 Region 的增多 .META. 表的数据也会增大,.META. 表的 Region 也会分裂
- .META. 表所有 Region 的元数据保存在 -ROOT- 表中,-ROOT- 表只有一个Region
- ZooKeeper 记录 -ROOT- 表的位置信息
- 客户端首先访问 ZooKeeper 获得 -ROOT- 表位置,然后访问 -ROOT- 表获得 .META. 表位置,最后根据 .META. 表中的信息确定用户数据存放的 Region 位置
- 可以看到客户端不需要和 Master 交互,而是通过 ZooKeeper 直接和 Region 交互
- 为了加快访问速度,.META. 表的 Region 全部保存在内存中,客户端会将查询过的位置信息缓存起来,因此,当客户端第一次进行数据查询的时候,响应会比较慢
High Availability 机制
WAL 保障数据高可用
- HBase中的 HLog 机制是 WAL 的一种实现,而 WAL 是事务机制中常见的一致性的实现方式
- 每个 Region Server 中都会有一个 HLog 的实例,Region Server 会将更新操作 (如 Put,Delete) 先记录到 WAL (也就是 HLog) 中,然后将其写入到 Store 的 MemStore,最终 MemStore 会将数据写入到持久化的 HFile 中
- 这样就保证了 HBase 的写的可靠性,如果没有 WAL,当 Region Server 宕掉的时候,MemStore 还没有写入到 HFile,或者 StoreFile 还没有保存,数据就会丢失
Master 容错
- ZooKeeper 会重新选择一个新的 Master
- 无 Master 过程中,数据读取仍照常进行,但是 Region 的切分、负载均衡等无法进行
Region Server 容错
- 定时向 ZooKeeper 汇报心跳
- 如果一段时间内未出现心跳,Master 将该 Region Server 上的 Region 重新分配到其他 Region Server
- 失效服务器上 WAL 日志由主服务器进行分割并派送给新的 Region Server
ZooKeeper 容错
- ZooKeeper 是一个可靠的服务,一般配置 3 或 5 个 ZooKeeper 实例
Phoenix

- 支持 SQL
- 支持二级索引
- 支持撒盐
- 支持 JDBC
- 没有一个单独的 Phoenix 组件,而是把 Phoenix 嵌入到了 HBase
- Phoenix 元数据存在 HBase 表 SYSTEM.TABLE
- 提供 Phoenix Query Server 给不是 Java 的程序通过 HTTP 的方式查询

 浙公网安备 33010602011771号
浙公网安备 33010602011771号