
数据分析八:互联网征信中的信用评分模型(刷卡行为分析)
用户刷卡行为数据分析:
互联网征信中的信用评分模型案例之一,分析用户刷卡行为数据,构建变量并预测结果。
1. 背景介绍
(1)个人信用贷款:结婚/家具/读书/旅行;
(2)现有的网络信贷产品:芝麻信用/微粒贷/考拉信用分;
(3)网络借贷:
(4)信用评估:用户申请-信用评估(前后信用数据)-获得批准;
(5)网络征信的重要性:减少坏账率;
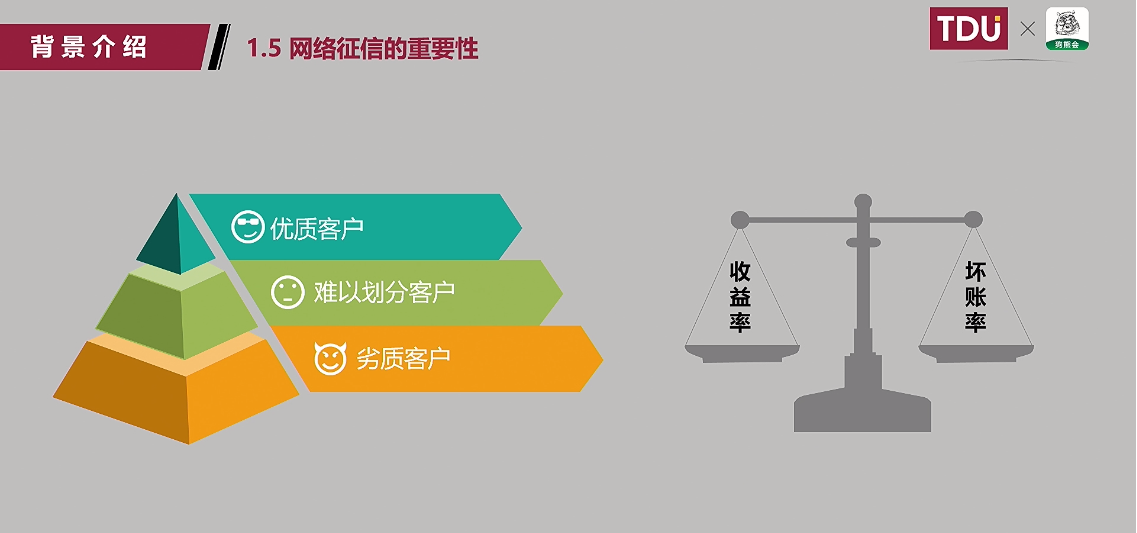
难以划分的客户——谁能够有能力划分;
(6)国际征信机构:
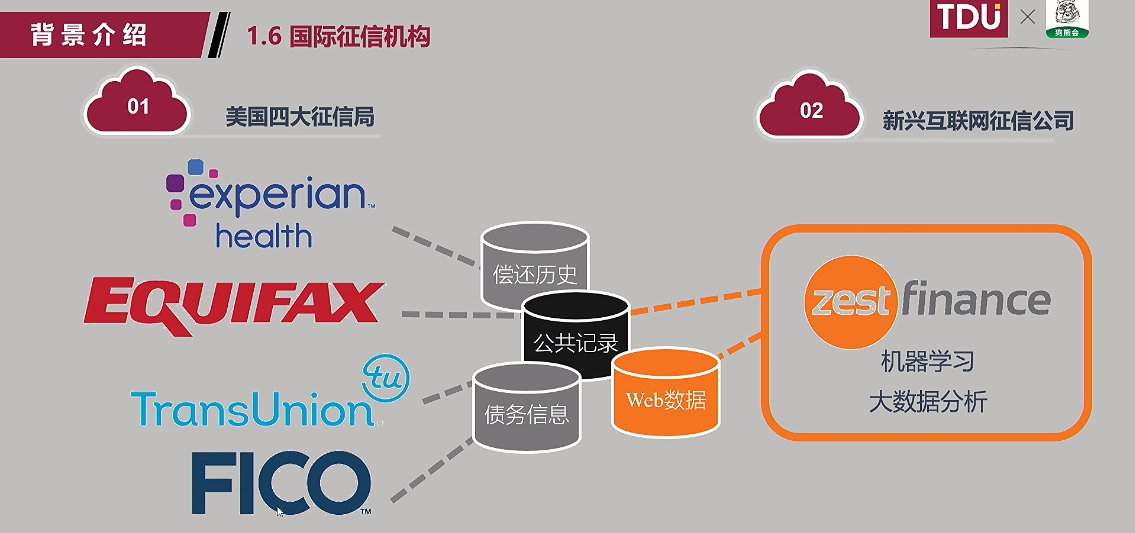
(7)首批准个人征信牌照持有公司:

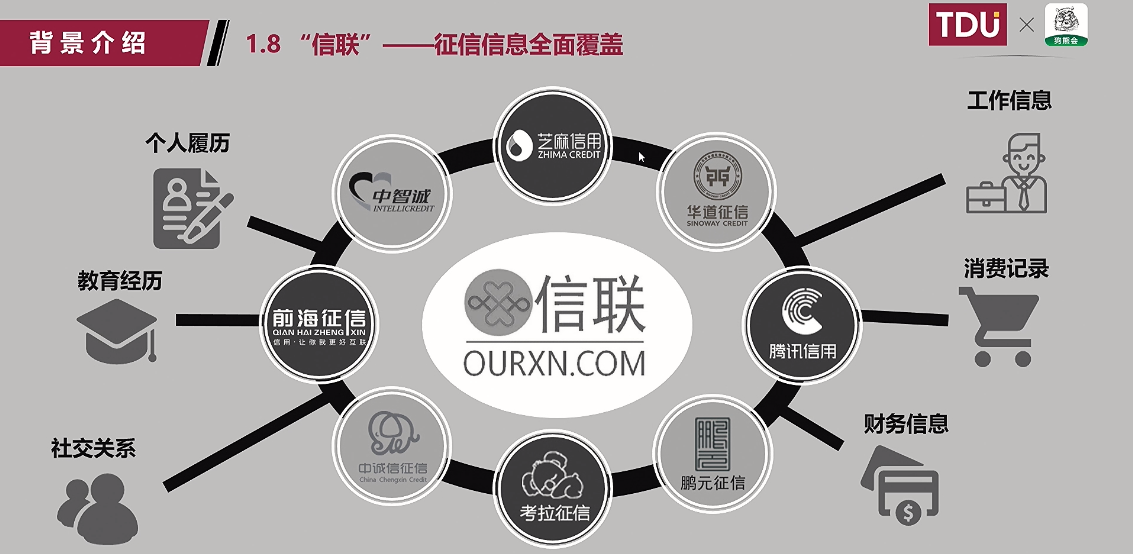
(8)”信联“——征信信息全面覆盖:
(9)征信得分的得出:

(10)征信的本质:对于每个用户给出非违约概率的判断;(一般是0-1之间,为了方便判定用户,于是用几百几百的方式来判定,如芝麻信用的评分);
(11)小贷用户互联网征信VS数据:用户自填数据(可能存在数据造假)/用户行为数据(数据可信度更高)/跨平台数据整合;
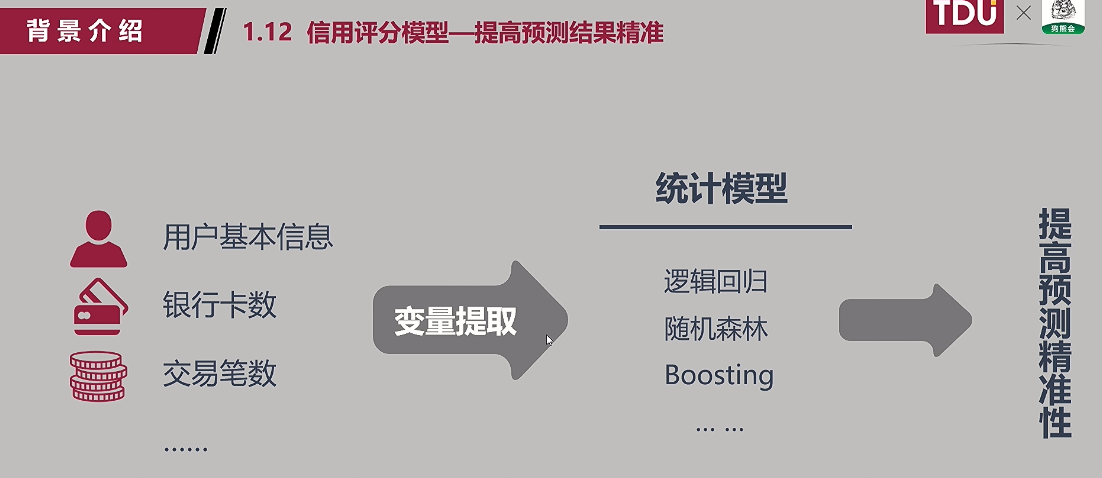
(12)信用评分模型——提高预测精准度;
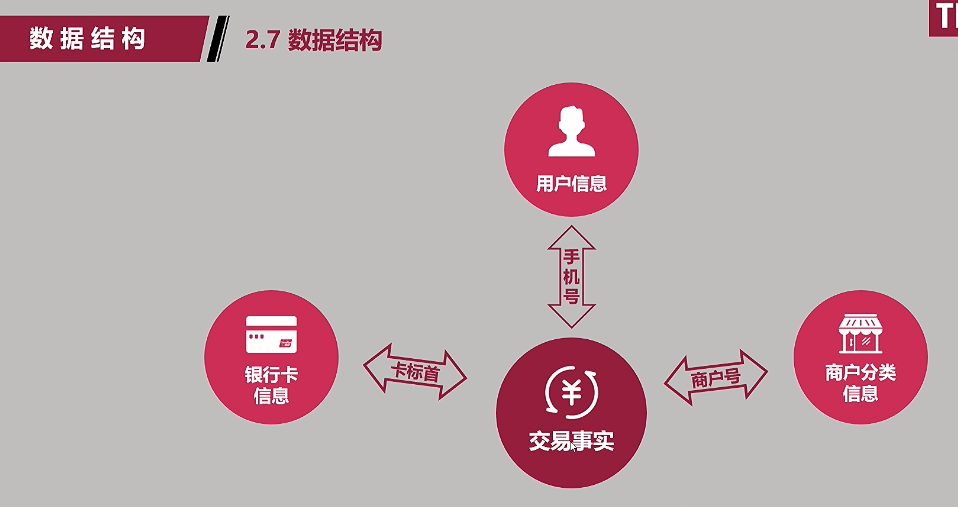
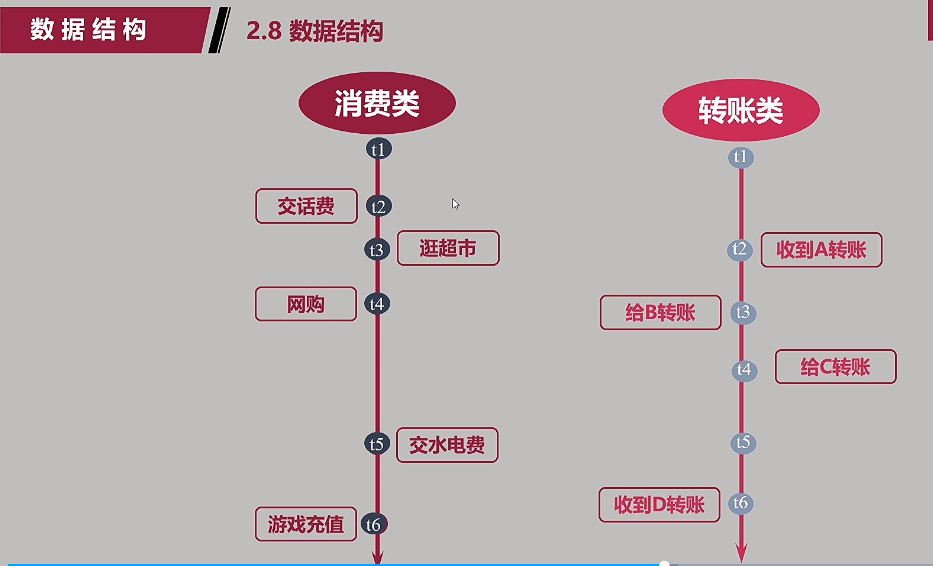
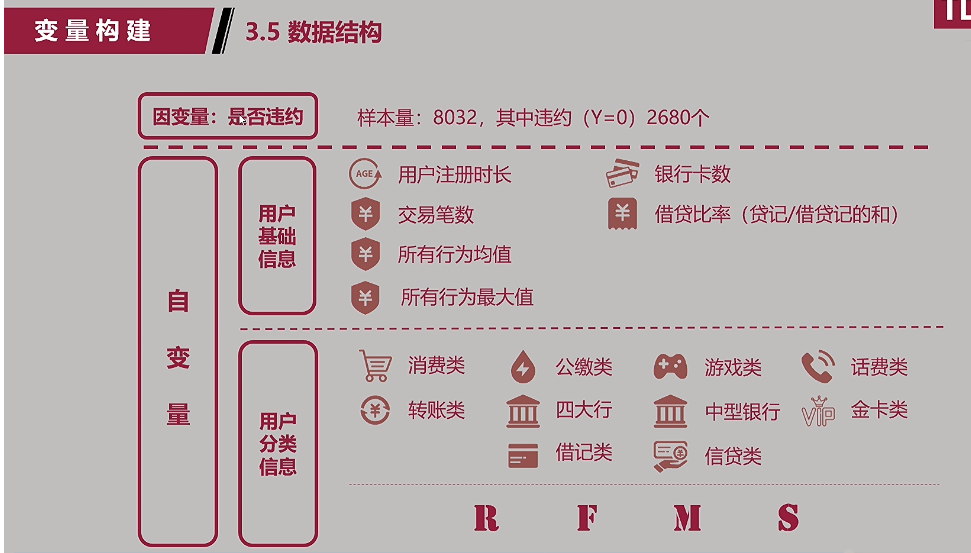
2. 数据结构:
(1)行业背景—刷卡数据;
(2)建模难点:成千上万条行为记录;行为随时间变化,且发生的时间点不规律;行为分为不同类型,公缴,游戏点卡,还款,话费,日常消费等;
如何构建这样的模型:
a. 用户信息:如身份证信息(姓名/性别/出生日期/住址);银行卡信息:普卡/金卡/白金卡(哪家银行的哪类型卡);
b. 商户分类信息:刷卡在哪里刷的(公缴类/消费类/游戏类/话费类)(住宿:香格里拉,速八等)
c. 交易事实:刷卡名称,交易时间,交易金额等;
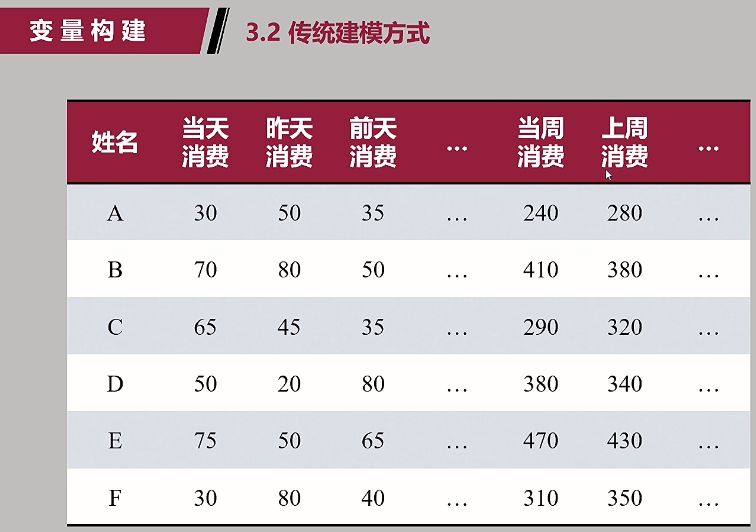
(3)传统建模方式:成千上万的变量;
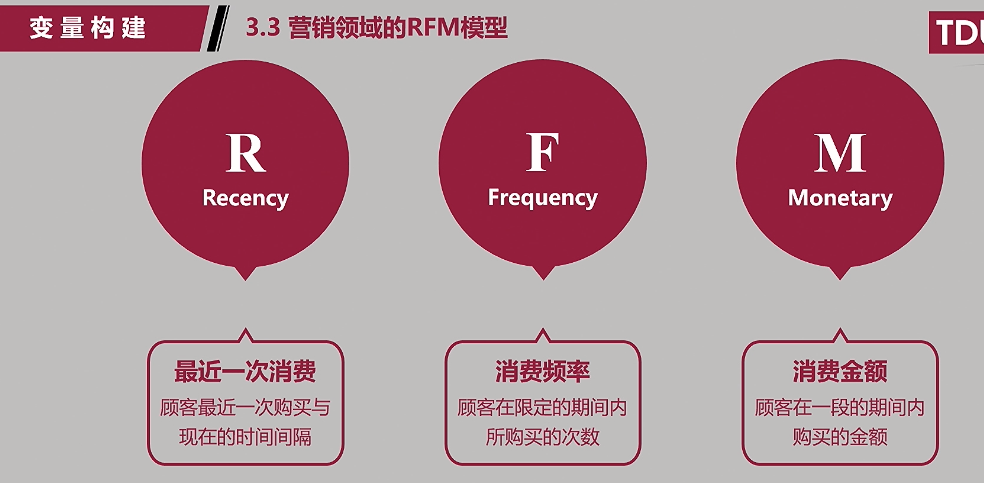
(4)营销领域的RFM模型:客户终身价值的模型;
2/8定律:80%的利润来于20%的客户;
(5)RMFS模型:s:standard deviation

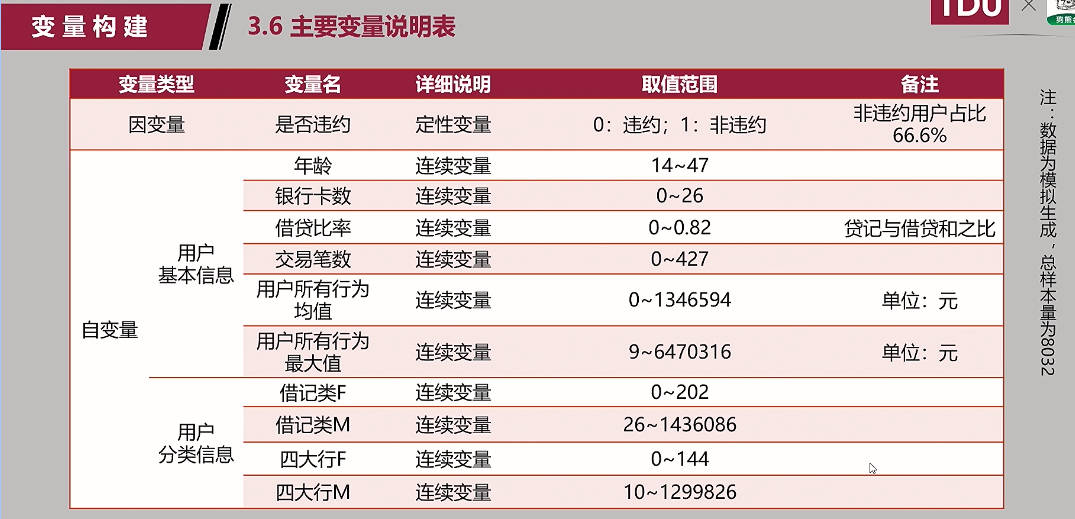
3. 变量构建(怎么算):很重要
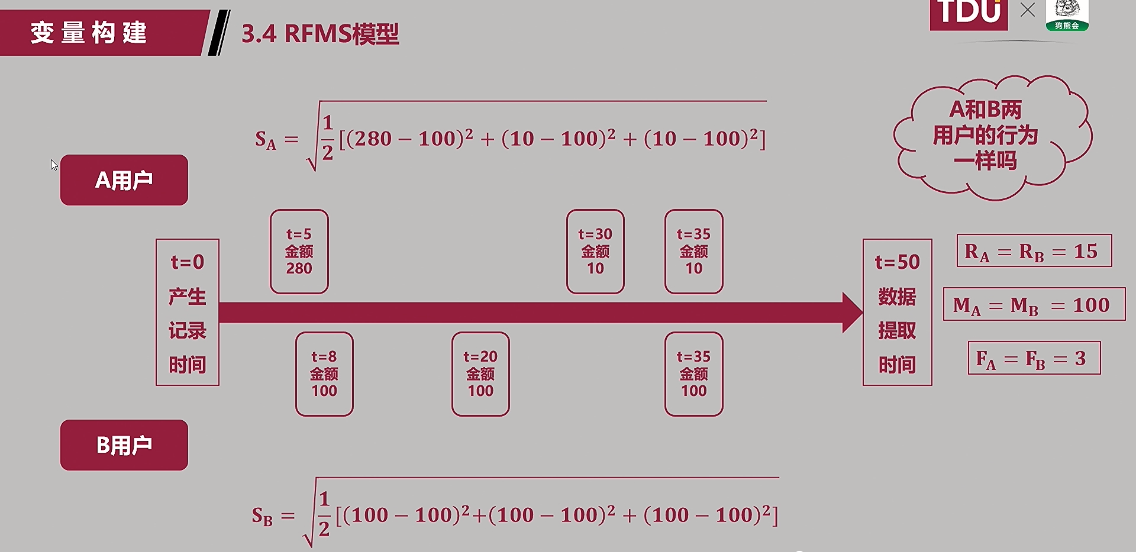
所有行为最大值:越小越好;
借贷比率:使用信用卡刷卡该值会大一些,使用储蓄卡该值会小一些;
(7)
- 模型结果:
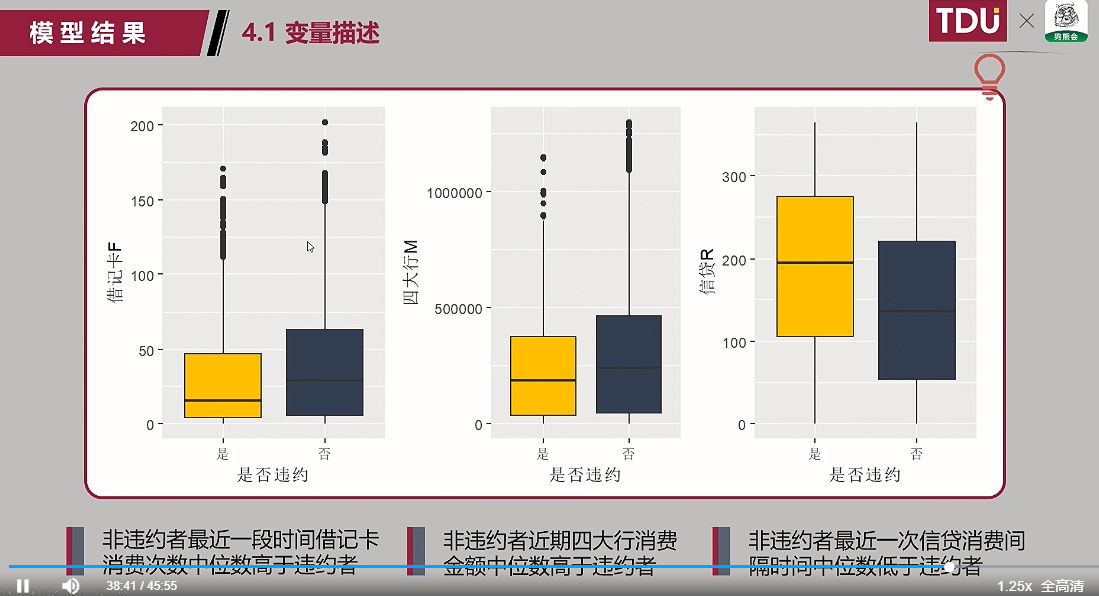
(1)变量描述:
(2)BIC选模型结果——》BIC选模型系数图:
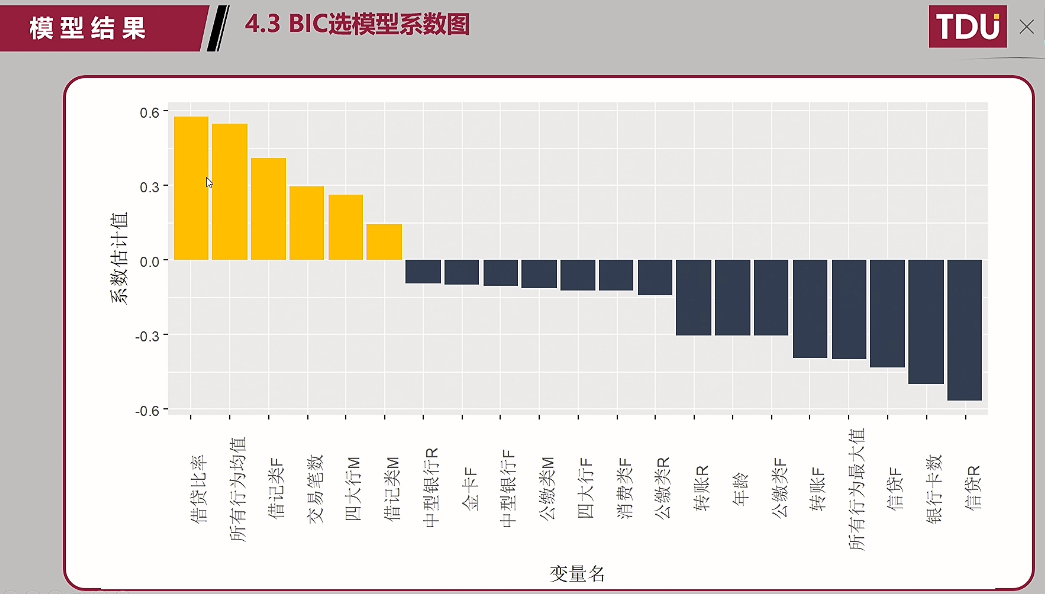
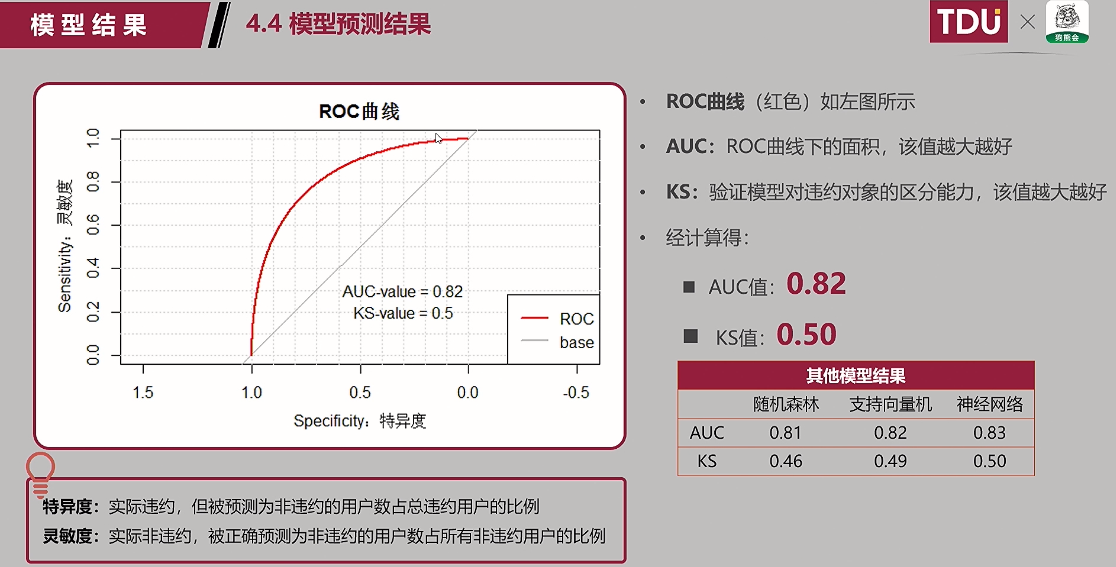
推荐使用逻辑回归的值——能清晰的看到哪些变量比较重要,且能够知道变量重要的什么程度;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号