光电设计大赛-基于树莓派4B的YOLOv5-Lite目标检测的移植与部署
📚 使用须知
- 本博客内容仅供学习参考
- 建议理解思路后独立实现
- 欢迎交流讨论
前言
本文为树莓派4B项目——YOLOv5-Lite目标检测,本次项目采用树莓派4B(Cortex-A72)作为核心 CPU 进行部署。该篇博客算是深度学习理论的初步实战,选择的网络模型为 YOLOv5 模型的变种 YOLOv5-Lite 模型。YOLOv5-Lite 与 YOLOv5 相比虽然牺牲了部分网络模型精度,但是缺极大的提升了模型的推理速度,该模型属性将更适合实战部署使用。
一、YOLOv5-Lite概述
1.1 YOLOv5概述
YOLOv5 网络模型算是 YOLO 系列迭代后特别经典的一代网络模型,作者为:Glenn Jocher。部分学者可能认为YOlOv5的创新性不足,其是否称得上 YOLOv5 而议论纷纷。作者认为 YOLOv5 可以算是对 YOLO 系列之前的一次集大成者的总结和突破,其属于非常优秀经典的网络模型框架,各种网络结构和 trick 是非常值得借鉴的!
代码地址:ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
Ultralytics YOLOv5🚀是由Ultralytics开发的一款前沿、最先进的(SOTA)计算机视觉模型。基于PyTorch框架,YOLOv5以其易用性、速度和准确性著称。它融合了大量研发的见解和最佳实践,使其成为广泛视觉人工智能任务的热门选择,包括物体检测、图像分割和图像分类。
Yolov5 官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。作者仅以 Yolov5s 的网络结构为对象进行讲解,其他版本的读者朋友可以参考其他博客!
Yolov5s 网络是 Yolov5 系列中深度最小,特征图的宽度最小的网络。后面的3种都是在此基础上不断加深,不断加宽。Yolov5s 的网络结构图如下(源于江大白大佬的结构图):
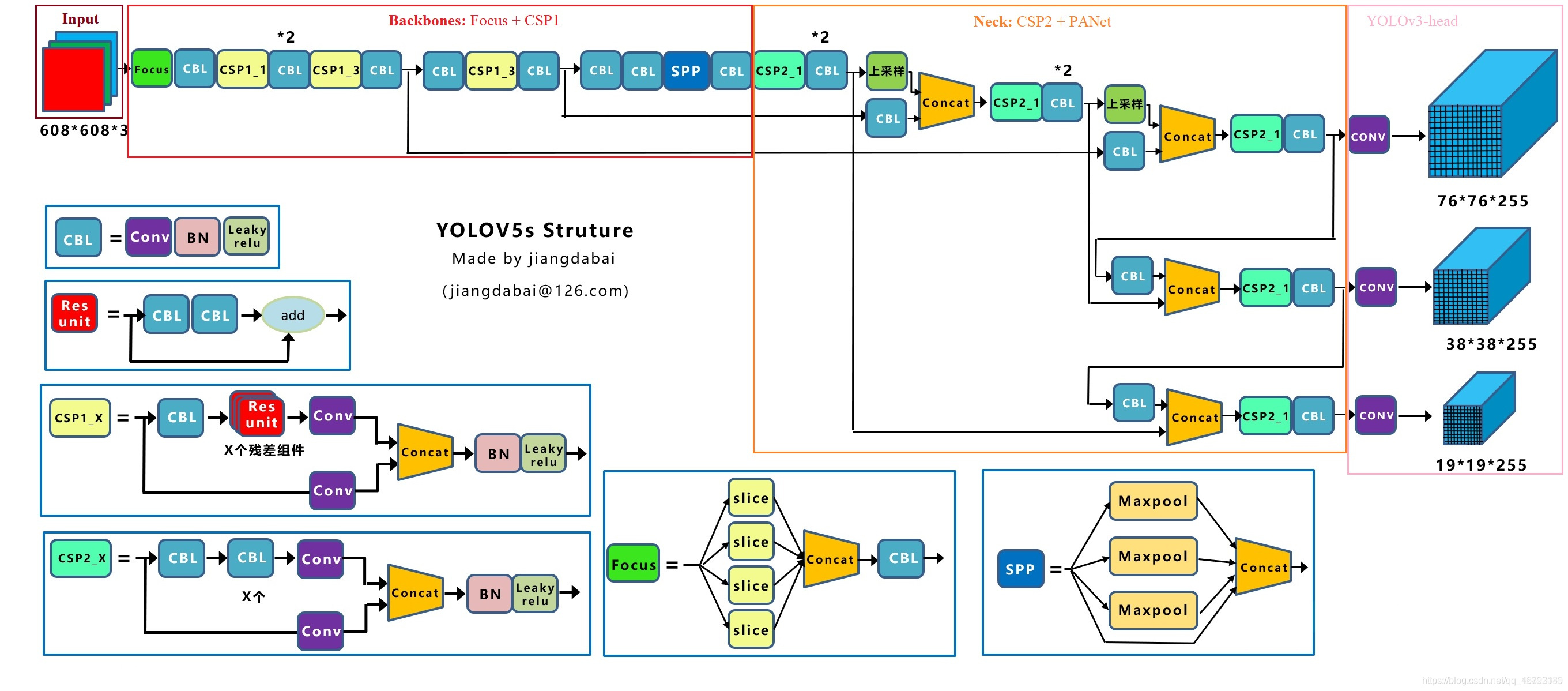
上图即 Yolov5s 的网络结构图,YOLOv5s网络从功能上可划分为四个部分:输入端(Input)、骨干网络(Backbone)、颈部网络(Neck)和预测头(Head)。
🔍 关键模块详解
1. C3模块(Cross Stage Partial Network)
这是YOLOv5的核心组件,用于替代标准卷积。其设计目的是解决梯度信息重复导致的推理计算量大的问题。
工作原理:它将输入特征图拆分为两部分,一部分经过多个Bottleneck残差块进行深度特征提取,另一部分直接通过一个卷积层。最后将两部分特征拼接(Concat),再融合。
作用:这种方式在保证特征提取能力的同时,显著减少了参数量和计算量,提升了效率。在原版YOLOv5中,这个模块被称为BottleneckCSP。
2. SPP/SPPF模块(空间金字塔池化)
该模块位于骨干网络末端,用于增加网络的感受野,使其能够更好地理解图像的上下文信息。
工作原理:它并行使用多个不同尺寸(如5×5,9×9,13×13)的最大池化层(MaxPool),再将所有池化结果与原始特征拼接,最后通过卷积融合。
新版改进:在YOLOv5 v6.x及之后的版本中,SPP被更高效的SPPF(快速空间金字塔池化)取代。SPPF通过串联多个5×5的MaxPool来实现与SPP相同的感受野效果,但计算速度更快。
3. 颈部网络:FPN+PAN结构
这是YOLOv5s实现多尺度目标检测的关键。
FPN(自上而下):将深层的高级语义特征(包含“是什么”的信息)向上传递,增强浅层特征的语义。
PAN(自下而上):将浅层的精确定位特征(包含“在哪里”的信息)向下传递,增强深层特征的定位能力。
协同作用:这种双向的特征融合路径(见上方结构图“颈部网络”部分),使模型在各个尺度上都能同时获得丰富的语义信息和精确的位置信息,从而显著提升了对不同大小目标的检测能力。
4. 预测头(Head)与输出
颈部网络最终输出三个不同尺度的特征图(P3, P4, P5),分别用于检测小、中、大目标。这些特征图会输入到相同的预测头,每个位置会预测:
边界框:包含中心坐标、宽高,使用GIOU Loss作为损失函数进行优化。
置信度:表示框内包含目标的概率。
类别概率:使用Sigmoid函数输出每个类别的概率。
⚙️ 模型缩放原理:深度与宽度
YOLOv5系列(s, m, l, x)共享完全相同的架构,性能差异仅由两个超参数控制:
| 模型版本 | 深度系数 (depth_multiple) | 宽度系数 (width_multiple) | 参数量(约) | 特点 |
|---|---|---|---|---|
| YOLOv5s | 0.33 | 0.50 | 7.2 MB | 最快,最轻量,适合移动端或实时场景。 |
| YOLOv5m | 0.67 | 0.75 | 21.2 MB | 速度与精度平衡。 |
| YOLOv5l | 1.00 | 1.00 | 46.5 MB | 精度更高。 |
| YOLOv5x | 1.33 | 1.25 | 86.7 MB | 最精确,但参数量最大,速度最慢。 |
深度系数:主要控制C3模块中Bottleneck残差块的堆叠次数。例如,YOLOv5s的C3模块中堆叠数仅为默认值(YOLOv5l)的33%。
宽度系数:控制卷积层的通道数(即卷积核数量)。例如,YOLOv5s的卷积通道数仅为默认值的一半。
💡 架构演进:从v5.x到v6.x
YOLOv5仍在持续迭代,v6.x版本对网络结构进行了一些关键优化:
Focus层被替换:早期版本的Focus层(一种切片操作)被一个6×6大小、步长为2的卷积层(Conv)取代,目的是便于将模型导出到其他框架。
SPPF取代SPP:如上所述,使用了更高效的快速空间金字塔池化。
主干网络C3层重复次数减少:从9次减少到6次,以减少计算量。
可考虑到实际情况,部署的本地机器通常并没有 PC 端那么计算能力强劲。这时候为了整体目标检测系统的稳定运行,往往需要牺牲掉网络模型的精度以换取足够快的检测速度。因此,轻量化部署的网络模型结构就此孕育而生!
1.2 YOLOv5-Lite详解
Yolov5-Lite 网络模型作为轻量化部署网络的代表作之一,深受算法部署工程师的偏爱(作者为中国ppogg大佬)!
Yolov5-Lite地址:GitHub - ppogg/YOLOv5-Lite
Yolov5-Lite 算法的模型结构如图下。该算法去除了 Focus 结构层,减小了模型体量,使模型变得更为轻便;同时,去除了 4 次 slice 操作,减少了对计算机芯片缓存的占用,降低了计算机的处理负担。与 Yolov5 算法相比,Yolov5-Lite 算法能避免反复使用 C3 Layer 模块。C3 Layer 模块会占用计算机很多运行空间,从而降低计算机的处理速度。这种方式能使 Yolov5-Lite 算法模型的精度控制在可靠范围内,从而使其更易部署。
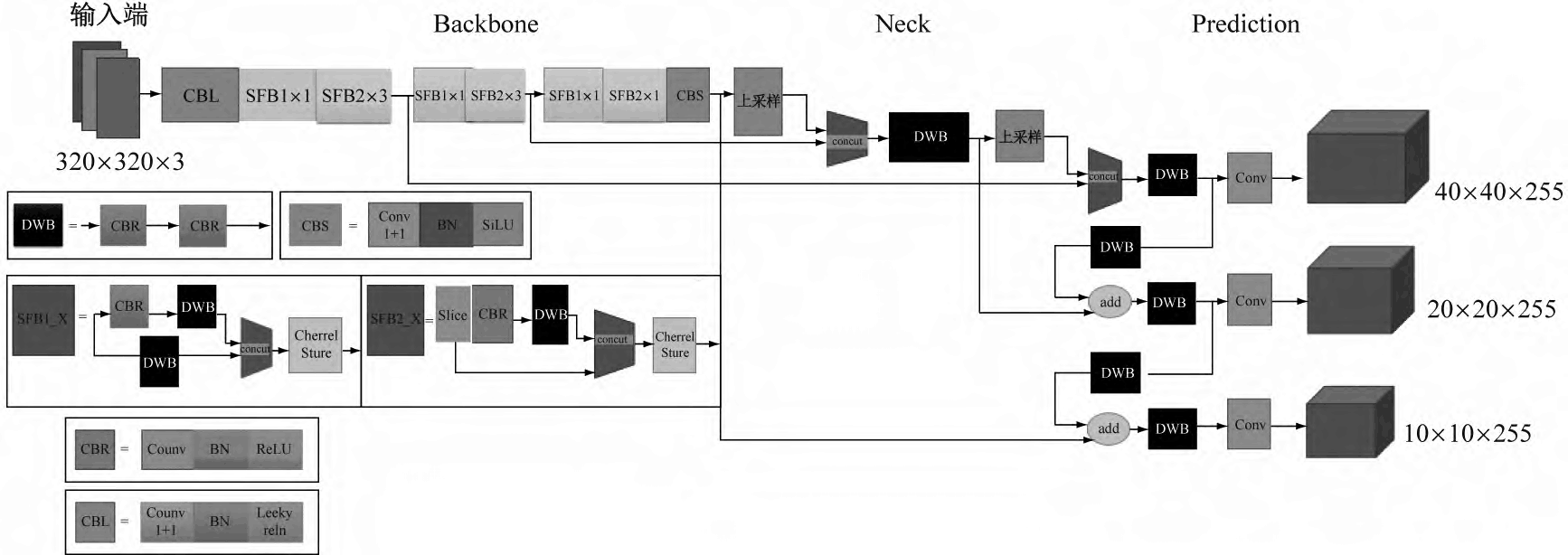
在图像识别领域,主干网络结构(Backbone)和检测头(Head)中往往有一段中间层,即特征增强融合网络层(Neck),可更精准地提取融合特征。Yolov5-Lite 算法也采用 FPN+PAN 结构,但其对输出端(Head)进行了通道剪枝,改进了 YOLOv4 算法和 YOLOv5 算法中的 FPN+PAN 的结构,具体表现在以下2个方面:
(1) 与 YOLOv5 算法不同,Yolov5-Lite 算法自身各结构的通道数量相同,即模型特征增强网络通道网格数也是20×20×96,这样可优化对内存的访问和使用,提高模型的运行效率;
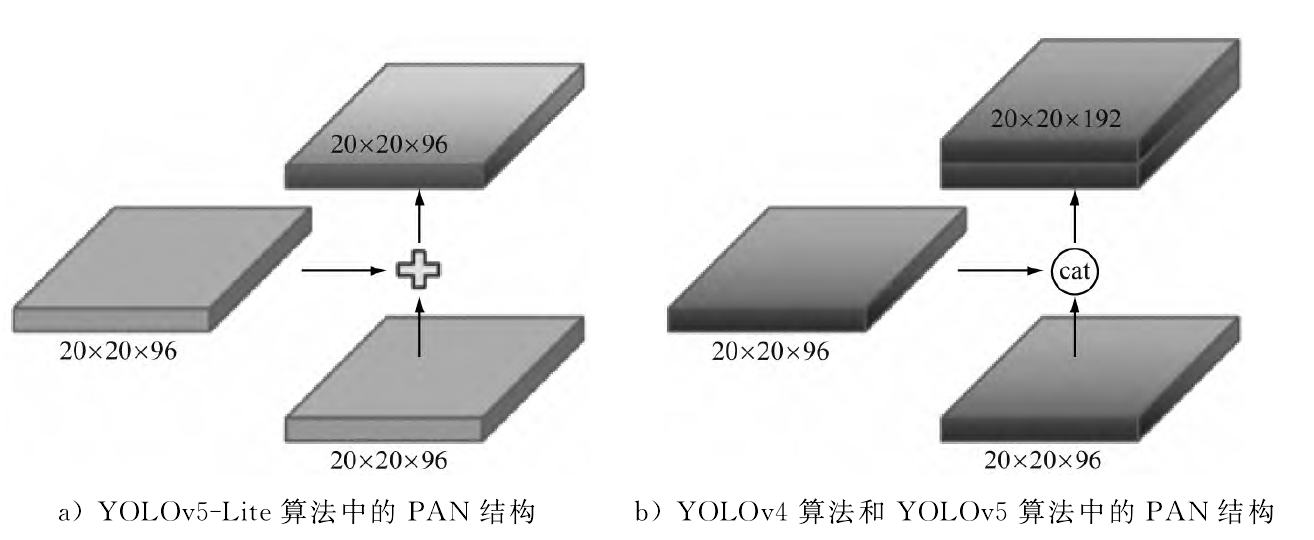
(2) Yolov5-Lite 算法采用 PANet 结构,将 YOLOv5 算法的通道连接(cat)操作改进为叠加操作,这样可进一步优化对内存的使用,加快处理速度。如下图为 Yolov5-Lite 算法与 YOLOv4 和 YOLOv5 算法中的 PAN 结构对比:
总结:
Yolov5-Lite 网络模型源于 YOLOv5 模型,随处可以可见 YOLOv5 网络模型的影子。但是,出于移植部署的目的性,Yolov5-Lite 网络将工作重心放在如何进行快速推理,如何轻量化网络模型大小!
Yolov5-Lite 网络模型不仅通过直接改变网络模型的结构,偏向多使用计算量小的网络模型结构去提取和融合目标特征,同时侧重运用计算机的运行机制:通过降低计算机内存的存储和读取去变相提高网络推理速度!!!
作者这里仅对 Yolov5-Lite 做初步概述,详情读者朋友可以参考学术论文!
二、YOLOv5-Lite训练
2.1 数据集制作
常规的神经网络模型训练是需要收集到大量语义丰富的数据集进行训练的。但是考虑实际工程下可能仅需要对已知场地且固定实物进行目标检测追踪等任务,这个时候我们可以采取偷懒的下方作者使用的方法!
1、作者使用树莓派4B的 Camera 直接在捕获需要识别目标物的图片信息(捕获期间转动待识别的目标物体);
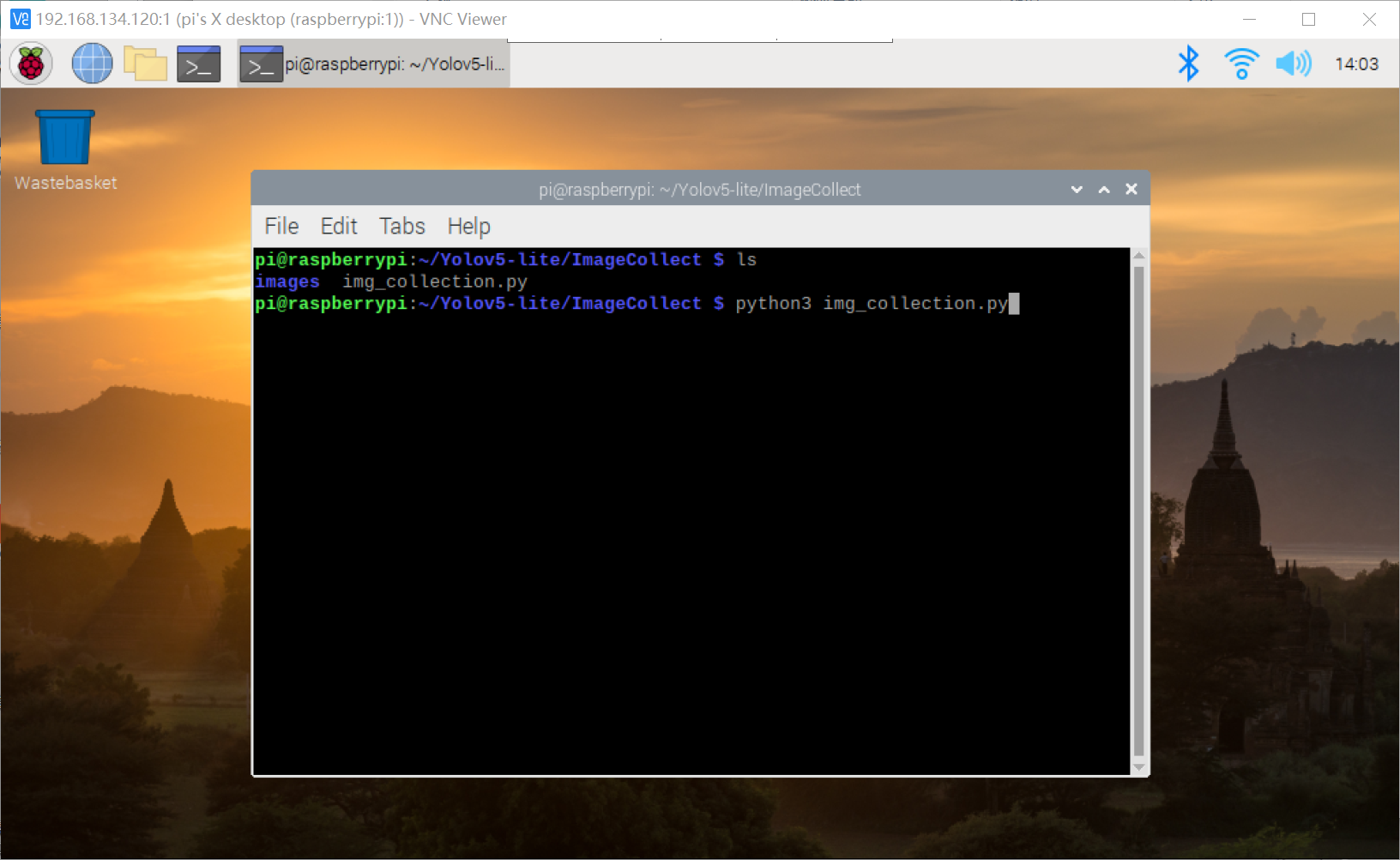
树莓派4B的 Camera 定时捕获照片的python代码如下
点击查看代码
import cv2
from threading import Thread
import uuid
import os
import time
count = 0
def image_collect(cap):
global count
while True:
success, img = cap.read()
if success:
file_name = str(uuid.uuid4())+'.jpg'
cv2.imwrite(os.path.join('images',file_name),img)
count = count+1
print("save %d %s"%(count,file_name))
time.sleep(0.4)
if __name__ == "__main__":
os.makedirs("images",exist_ok=True)
# 打开摄像头
cap = cv2.VideoCapture(0)
m_thread = Thread(target=image_collect, args=([cap]),daemon=True)
while True:
# 读取一帧图像
success, img = cap.read()
if not success:
continue
cv2.imshow("video",img)
key = cv2.waitKey(1) & 0xFF
# 按键 "q" 退出
if key == ord('c'):
m_thread.start()
continue
elif key == ord('q'):
break
cap.release()
按动 “c” 开始采集待识别目标图像,按动 “q” 退出摄像头 Camera 的图片采集;
2、将捕获到的待识别目标物照片传输到PC端,利用 Labelme 软件进行标注;

标注了 3 类目标:drug,prime,glue;读者朋友可以根据自己实际情况标注自己需要的数据集!由于我们标注的数据的标签 label 默认是 JSON 格式的不能被 YOLO 系列的神经网络模型直接进行利用训练。
3、使用 JSON 转 txt 的 YOLO 格式 label 的python代码进行转换:
`dic_lab.py`:
dic_labels= {'drug':0,
'glue':1,
'prime':2,
'path_json':'labels',
'ratio':0.9}
lablemetoyolo.py
import os
import json
import random
import base64
import shutil
import argparse
from pathlib import Path
from glob import glob
from dic_lab import dic_labels
def generate_labels(dic_labs):
path_input_json = dic_labels['path_json']
ratio = dic_labs['ratio']
for index, labelme_annotation_path in enumerate(glob(f'{path_input_json}/*.json')):
# 读取文件名
image_id = os.path.basename(labelme_annotation_path).rstrip('.json')
# 计算是train 还是 valid
train_or_valid = 'train' if random.random() < ratio else 'valid'
# 读取labelme格式的json文件
labelme_annotation_file = open(labelme_annotation_path, 'r')
labelme_annotation = json.load(labelme_annotation_file)
# yolo 格式的 lables
yolo_annotation_path = os.path.join(train_or_valid, 'labels',image_id + '.txt')
yolo_annotation_file = open(yolo_annotation_path, 'w')
# yolo 格式的图像保存
yolo_image = base64.decodebytes(labelme_annotation['imageData'].encode())
yolo_image_path = os.path.join(train_or_valid, 'images', image_id + '.jpg')
yolo_image_file = open(yolo_image_path, 'wb')
yolo_image_file.write(yolo_image)
yolo_image_file.close()
# 获取位置信息
for shape in labelme_annotation['shapes']:
if shape['shape_type'] != 'rectangle':
print(
f'Invalid type `{shape["shape_type"]}` in annotation `annotation_path`')
continue
points = shape['points']
scale_width = 1.0 / labelme_annotation['imageWidth']
scale_height = 1.0 / labelme_annotation['imageHeight']
width = (points[1][0] - points[0][0]) * scale_width
height = (points[1][1] - points[0][1]) * scale_height
x = ((points[1][0] + points[0][0]) / 2) * scale_width
y = ((points[1][1] + points[0][1]) / 2) * scale_height
object_class = dic_labels[shape['label']]
yolo_annotation_file.write(f'{object_class} {x} {y} {width} {height}\n')
yolo_annotation_file.close()
print("creat lab %d : %s"%(index,image_id))
if __name__ == "__main__":
os.makedirs(os.path.join("train",'images'),exist_ok=True)
os.makedirs(os.path.join("train",'labels'),exist_ok=True)
os.makedirs(os.path.join("valid",'images'),exist_ok=True)
os.makedirs(os.path.join("valid",'labels'),exist_ok=True)
generate_labels(dic_labels)
我们需要根据自己的需要自定义字典 dic_lab,字典中的 ratio = 0.9 的作用是将数据集拆分成训练集和验证集 9:1。读者朋友可以根据自己的实际情况去修改字典的标签内容,成功执行 lablemetoyolo.py 代码后效果如下:
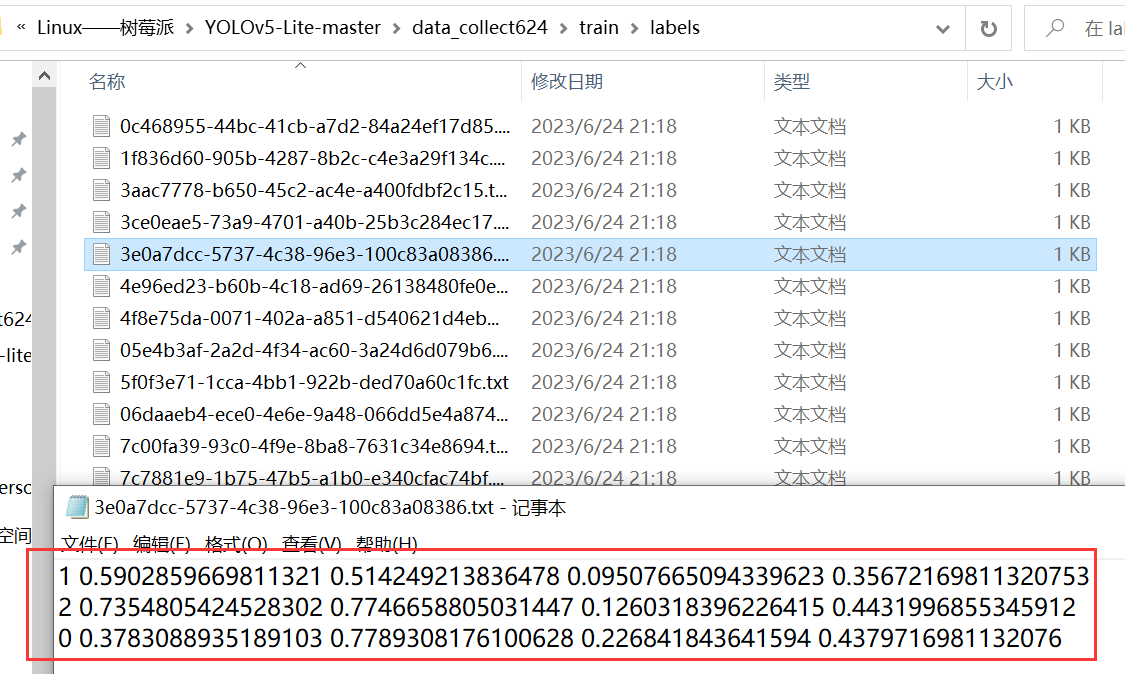
labels文件夹下的标签成功转换了 YOLO 系列可以使用的 label 标签,到此时就已经成功准备好我们需要的训练集了!
特别说明:该方法仅适用于上述作者所说的场景下,实际情况下,建议大家还是使用合格的数据集进行训练(即目标与背景语义丰富的数据集),使得训练出来的神经网络具有良好的泛化性与鲁棒性,否则训练出来的网络很容易过拟合!
2.2 YOLOv5-Lite训练
Yolov5-Lite 训练就是常规的神经网络模型训练,我们从 GitHub 上下载 Yolov5-Lite 的源代码,训练平台为:PyCharm 2022.3 x64,GPU:RTX3060 6G,CPU:AMD Ryzen 7 4800U 1.8GHZ。
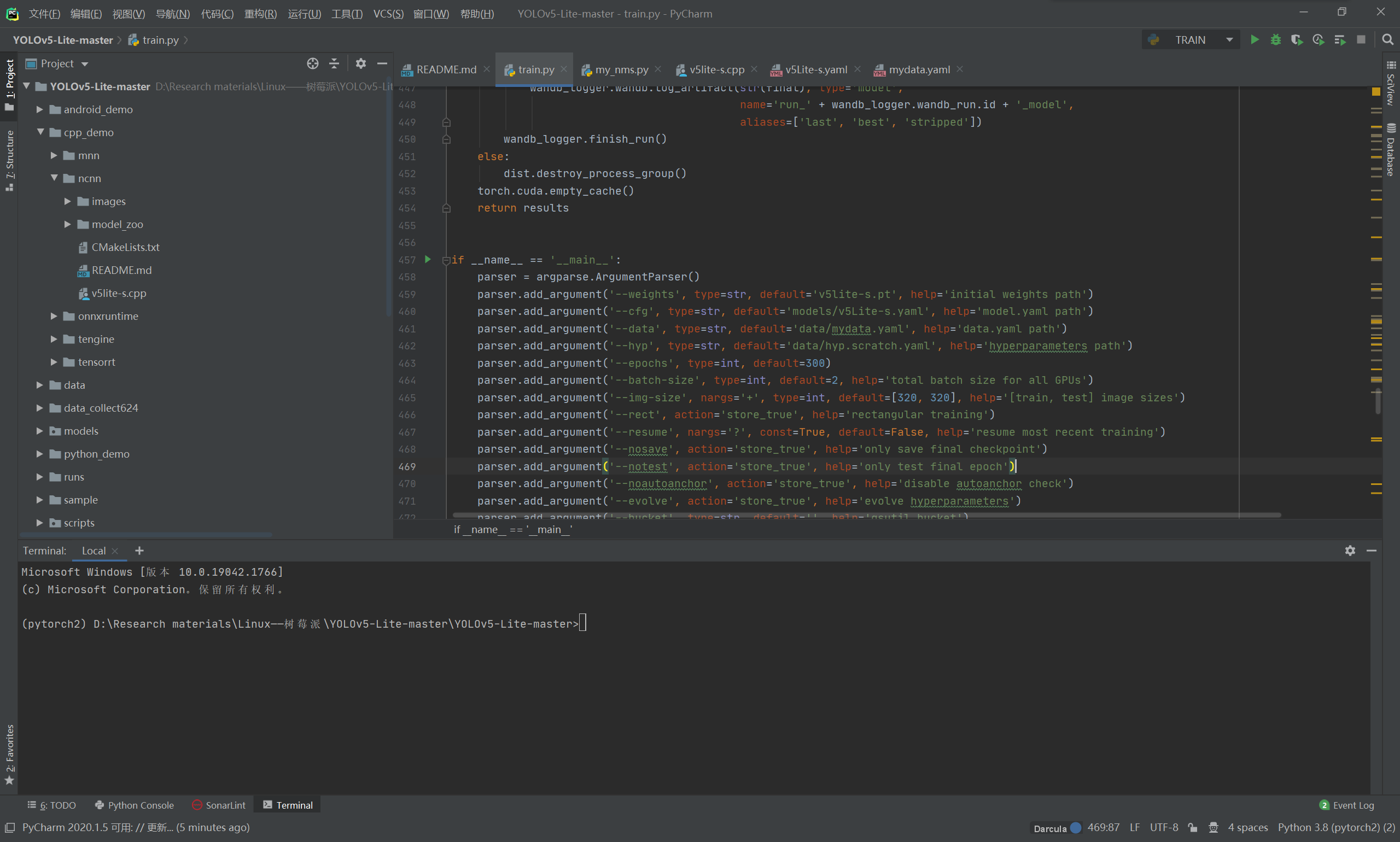
在 Yolov5-Lite 的目录下找到 train.py (训练文件)的 main 函数入口,进行如下配置:
我们设置如下几个核心配置:
--weights v5lite-s.pt
--cfg models/v5Lite-s.yaml
--data data/mydata.yaml
--img-size 320
--batch-size 16
--data data/mydata.yaml
--device 0/cpu (可以不使用CUDA训练)
一定要将数据集存放的地址位置搞正确!!!

Yolov5-Lite 网络模型的训练可以不一定必须使用 CUDA 进行加速,但是 pytorch 架构等依赖库一定需要满足,模型训练依赖要求如下:
点击查看代码
# base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.8.0
torchvision>=0.9.0
tqdm>=4.41.0
# logging -------------------------------------
tensorboard>=2.4.1
# wandb
# plotting ------------------------------------
seaborn>=0.11.0
pandas
# export --------------------------------------
# coremltools>=4.1
# onnx>=1.9.1
# scikit-learn==0.19.2 # for coreml quantization
# extras --------------------------------------
thop # FLOPS computation
pycocotools>=2.0 # COCO mAP
将训练环境与数据集都搞定之后,就可以点击运行按钮进行 Yolov5-Lite 的模型训练了!
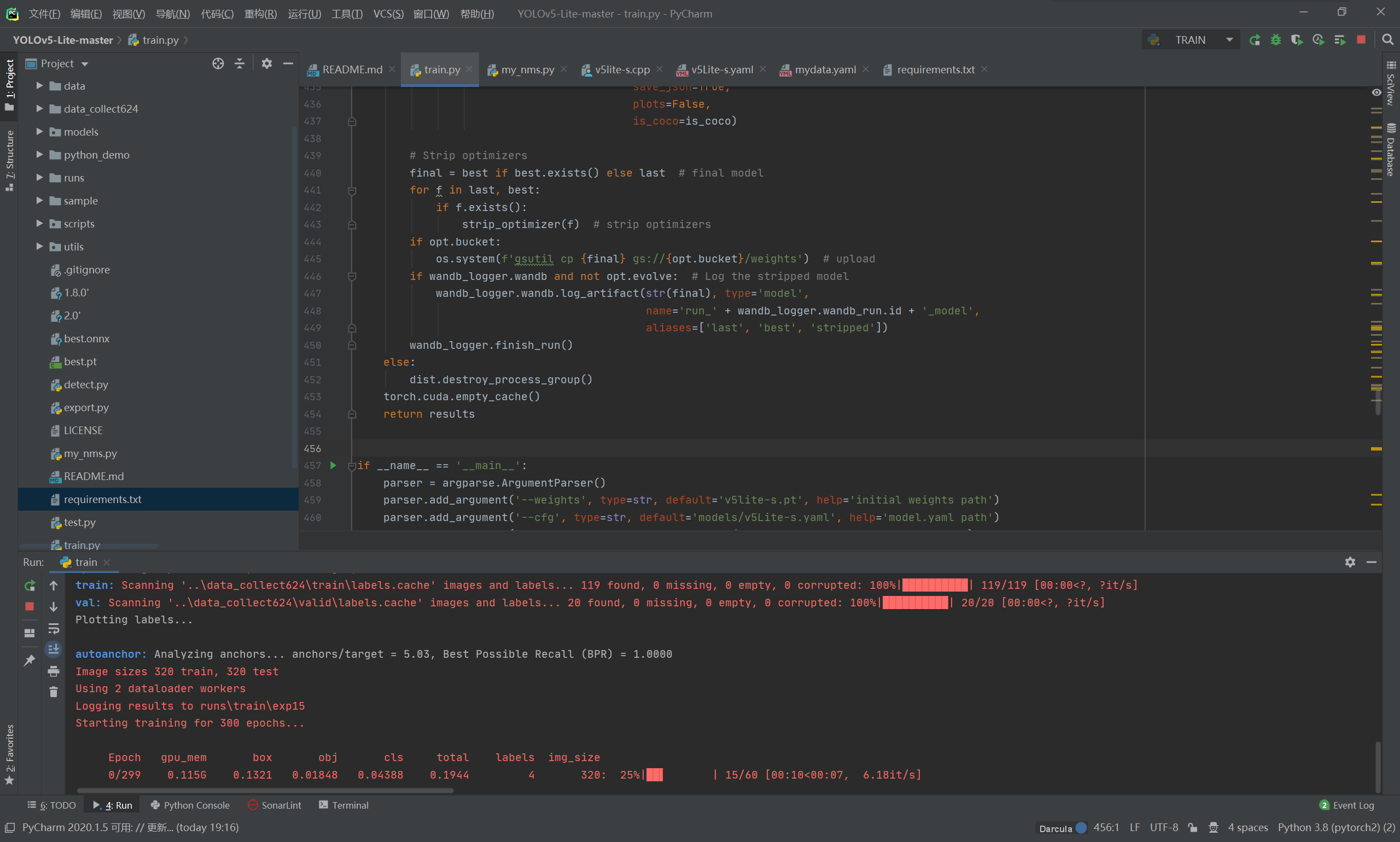
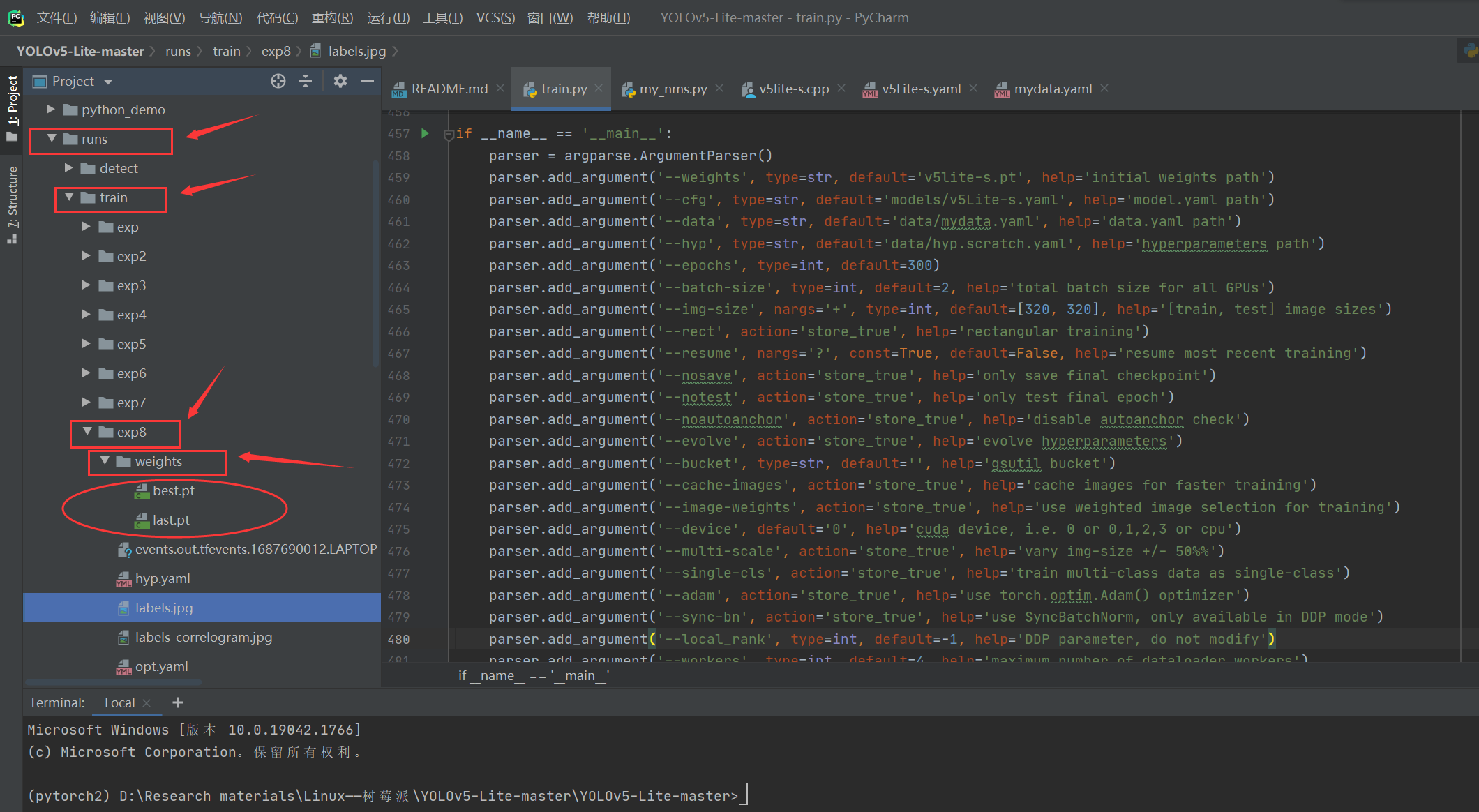
训练成功之后,将会在当前目录下的 run 文件下的 trian 文件下找到 expx (x代表数字),expx 则存放了第 x 次训练时候的各种数据内容,包括:历史最优权重best_weight,当前权重last_weight,训练结果result等等;
三、树莓派4B部署YOLOv5-Lite
3.1 ONNX概述
Open Neural Network Exchange(ONNX)是一个开放的生态系统,它使人工智能开发人员在推进项目时选择合适的工具,不用被框架或者生态系统所束缚。ONNX支持不同框架之间的互操作性,简化从研究到生产之间的道路。ONNX支持许多框架(TensorFlow, Pytorch, Keras, MxNet, MATLAB等等),这些框架中的模型都可以导出或者转换为标准ONNX格式。模型采用ONNX格式后,就可在各种平台和设备上运行

开发者根据深度学习框架优劣选择某个框架,但是这些框架适应不同的开发阶段,由于必须进行转换,从而导致了研究和生产之间的重大延迟。ONNX格式一个通用的IR,能够使得开发人员在开发或者部署的任何阶段选择最适合他们项目的框架。ONNX通过提供计算图的通用表示,帮助开发人员为他们的任务选择合适的框架。
ONNX可视化:ONNX 模型可以通过 netron 进行可视化。
ONNX 顾名思义就是开放的神经网络模型转换,利用它可以轻松将模型更换框架,从而适配亦或是部署在各类设备上。
3.2 ONNX模型转换和移植
如今的开源 YOLO 系列神经网络模型的目录下作者都会预留 export.py 文件将该神经网络模型进行转换到 ONNX 模型,方便大家实际情况下部署使用!
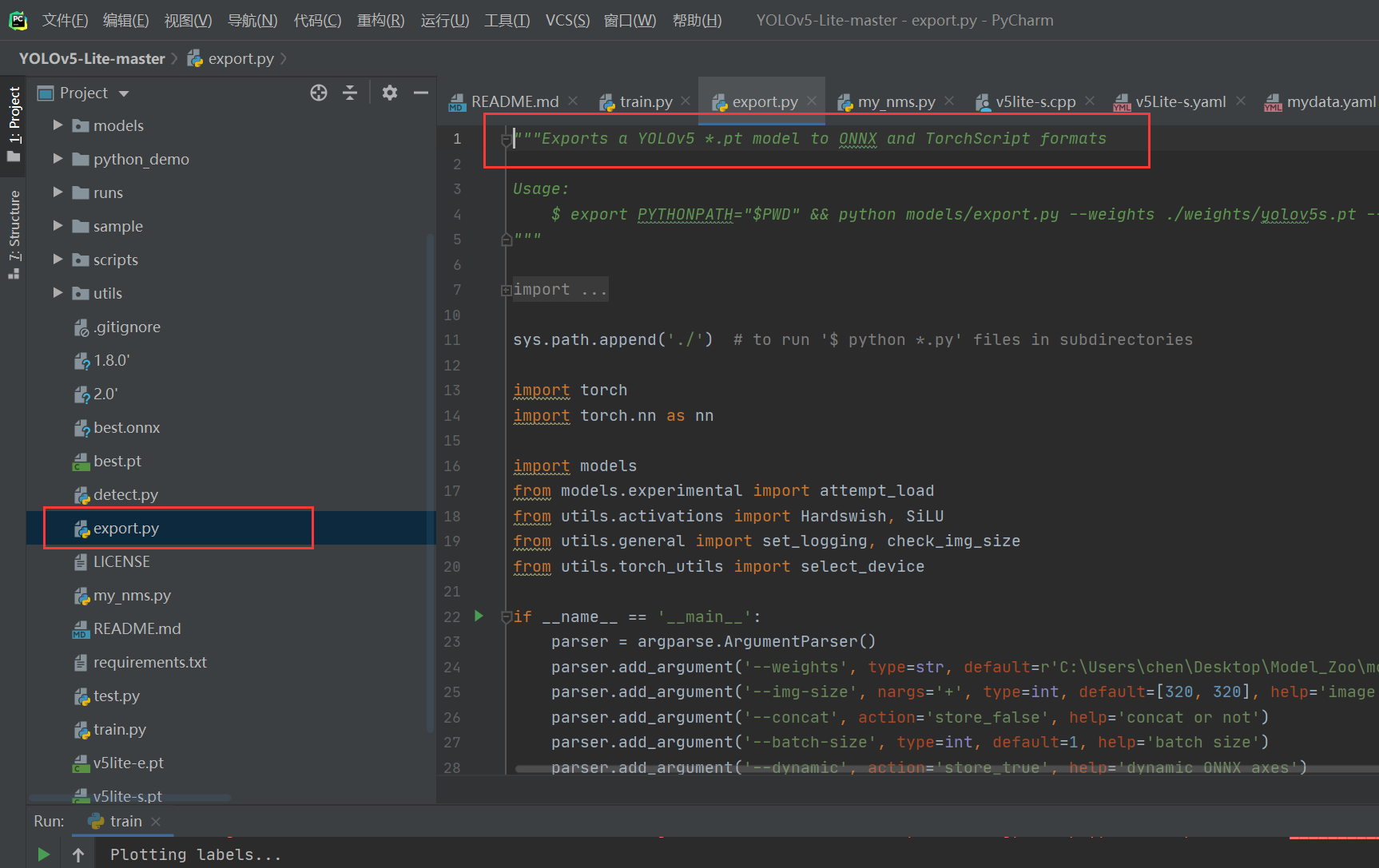
将我们训练好的最优训练权重 weights 存放到 YOLOv5-Lite 主目录下,之后运行如下代码:
python export.py --weights best.pt
运行该指令后将会通过 best.pt 文件,生成 best.onnx 的 ONNX 模型的权重文件;
同时为了成功运行 ONNX 格式的 YOLOv5-Lite 网络模型,需要在树莓派4B中安装 onnxruntim ,当然值得注意的是 onnxruntim 的安装需要依赖的 Numpy版本1.21 以上。
pip install onnx (tab补全安装包)
将转换成 ONNX 格式的权重文件导入到树莓派4B中,并于目标检测程序保持同一目录下:
到此 ONNX 模型的转换与移植工作就可以完成了!
四、YOLOv5-Lite目标检测
YOLOv5-Lite 的目标检测前向推理程序是很简单的,可以直接借鉴如下提供的代码:
点击查看代码
import cv2
import numpy as np
import onnxruntime as ort
import time
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
def _make_grid( nx, ny):
xv, yv = np.meshgrid(np.arange(ny), np.arange(nx))
return np.stack((xv, yv), 2).reshape((-1, 2)).astype(np.float32)
def cal_outputs(outs,nl,na,model_w,model_h,anchor_grid,stride):
row_ind = 0
grid = [np.zeros(1)] * nl
for i in range(nl):
h, w = int(model_w/ stride[i]), int(model_h / stride[i])
length = int(na * h * w)
if grid[i].shape[2:4] != (h, w):
grid[i] = _make_grid(w, h)
outs[row_ind:row_ind + length, 0:2] = (outs[row_ind:row_ind + length, 0:2] * 2. - 0.5 + np.tile(
grid[i], (na, 1))) * int(stride[i])
outs[row_ind:row_ind + length, 2:4] = (outs[row_ind:row_ind + length, 2:4] * 2) ** 2 * np.repeat(
anchor_grid[i], h * w, axis=0)
row_ind += length
return outs
def post_process_opencv(outputs,model_h,model_w,img_h,img_w,thred_nms,thred_cond):
conf = outputs[:,4].tolist()
c_x = outputs[:,0]/model_w*img_w
c_y = outputs[:,1]/model_h*img_h
w = outputs[:,2]/model_w*img_w
h = outputs[:,3]/model_h*img_h
p_cls = outputs[:,5:]
if len(p_cls.shape)==1:
p_cls = np.expand_dims(p_cls,1)
cls_id = np.argmax(p_cls,axis=1)
p_x1 = np.expand_dims(c_x-w/2,-1)
p_y1 = np.expand_dims(c_y-h/2,-1)
p_x2 = np.expand_dims(c_x+w/2,-1)
p_y2 = np.expand_dims(c_y+h/2,-1)
areas = np.concatenate((p_x1,p_y1,p_x2,p_y2),axis=-1)
areas = areas.tolist()
ids = cv2.dnn.NMSBoxes(areas,conf,thred_cond,thred_nms)
if len(ids)>0:
return np.array(areas)[ids],np.array(conf)[ids],cls_id[ids]
else:
return [],[],[]
def infer_img(img0,net,model_h,model_w,nl,na,stride,anchor_grid,thred_nms=0.4,thred_cond=0.5):
# 图像预处理
img = cv2.resize(img0, [model_w,model_h], interpolation=cv2.INTER_AREA)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32) / 255.0
blob = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
# 模型推理
outs = net.run(None, {net.get_inputs()[0].name: blob})[0].squeeze(axis=0)
# 输出坐标矫正
outs = cal_outputs(outs,nl,na,model_w,model_h,anchor_grid,stride)
# 检测框计算
img_h,img_w,_ = np.shape(img0)
boxes,confs,ids = post_process_opencv(outs,model_h,model_w,img_h,img_w,thred_nms,thred_cond)
return boxes,confs,ids
if __name__ == "__main__":
# 模型加载
model_pb_path = "best.onnx"
so = ort.SessionOptions()
net = ort.InferenceSession(model_pb_path, so)
# 标签字典
dic_labels= {0:'drug',
1:'glue',
2:'prime'}
# 模型参数
model_h = 320
model_w = 320
nl = 3
na = 3
stride=[8.,16.,32.]
anchors = [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]]
anchor_grid = np.asarray(anchors, dtype=np.float32).reshape(nl, -1, 2)
video = 0
cap = cv2.VideoCapture(video)
flag_det = False
while True:
success, img0 = cap.read()
if success:
if flag_det:
t1 = time.time()
det_boxes,scores,ids = infer_img(img0,net,model_h,model_w,nl,na,stride,anchor_grid,thred_nms=0.4,thred_cond=0.5)
t2 = time.time()
for box,score,id in zip(det_boxes,scores,ids):
label = '%s:%.2f'%(dic_labels[id],score)
plot_one_box(box.astype(np.int16), img0, color=(255,0,0), label=label, line_thickness=None)
str_FPS = "FPS: %.2f"%(1./(t2-t1))
cv2.putText(img0,str_FPS,(50,50),cv2.FONT_HERSHEY_COMPLEX,1,(0,255,0),3)
cv2.imshow("video",img0)
key=cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key & 0xFF == ord('s'):
flag_det = not flag_det
print(flag_det)
cap.release()
就该目标检测算法简单给大家讲解一下
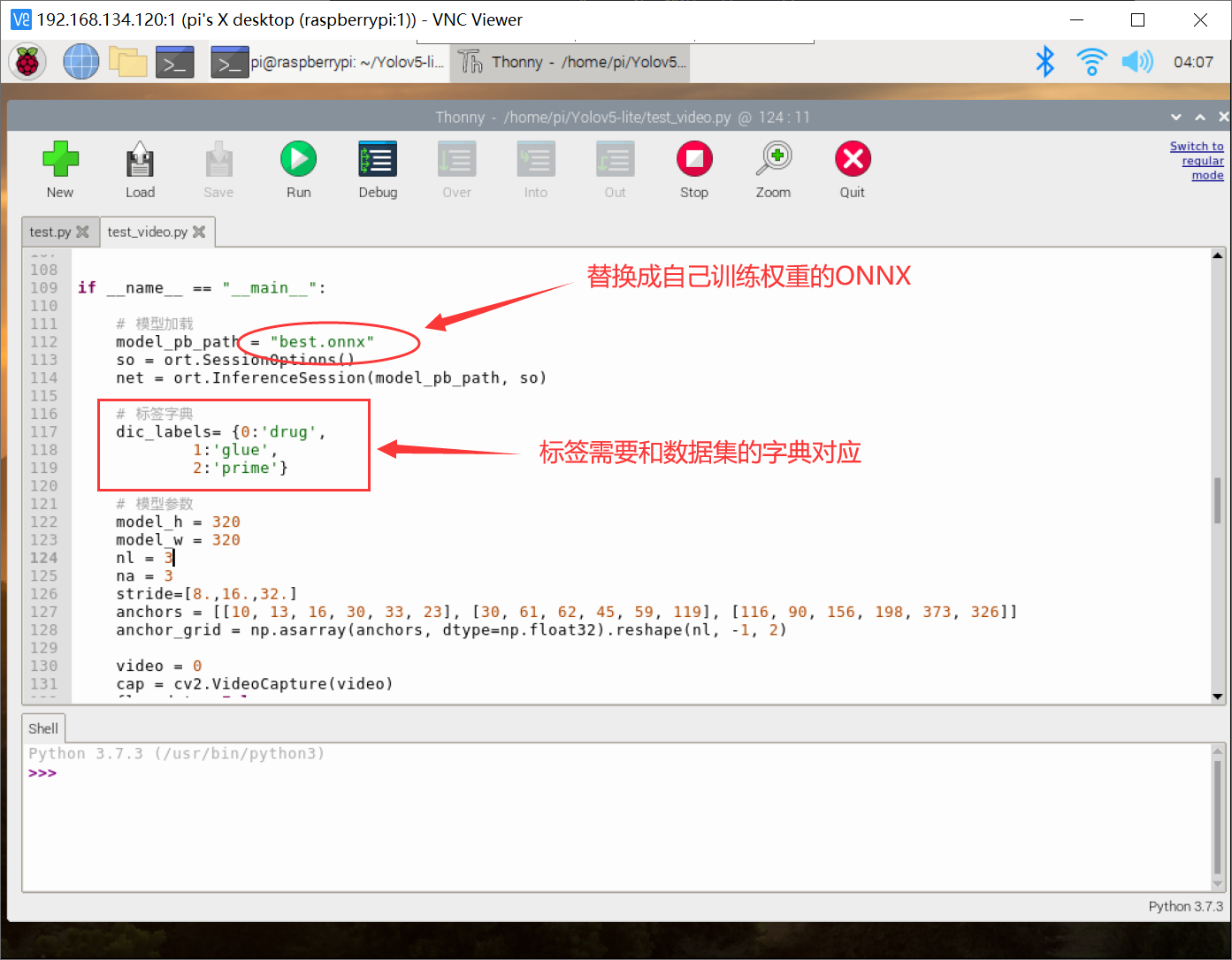
上方的 model_pb_path 和 dic_labels 是需要根据自己实际情况去改一下的,其余基本保持不变即可!
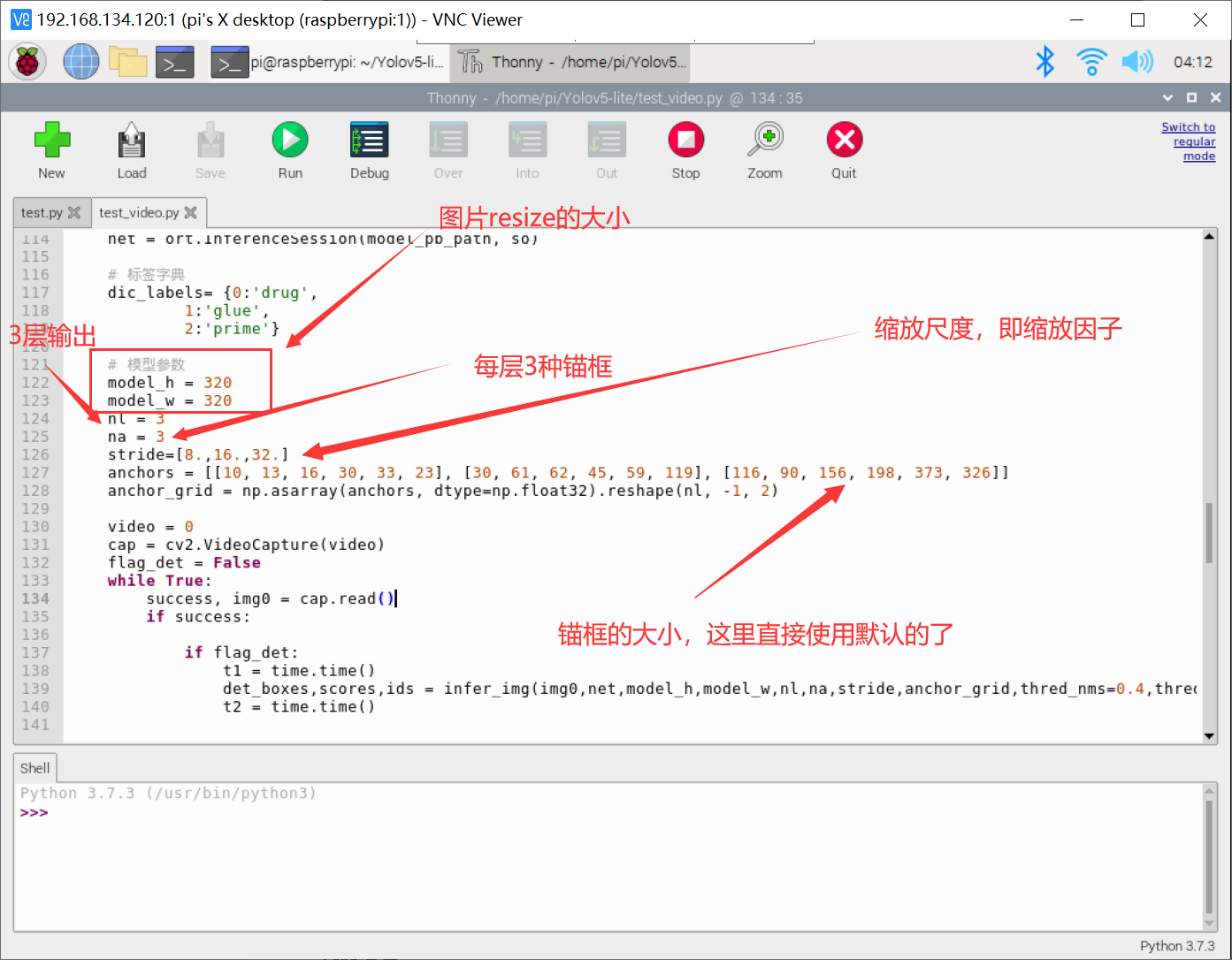
上述基本除了 anchor 锚框这个数据,其余都是不需要改动的,这里 anchor 直接使用了默认值。如果大家想在目标检测的时候可以更好地框选出自己地识别目标,可以用 K-means 聚类算法去自适应 anchor 的大小,从小聚类出符合自己数据类型的 anchor ,这样目标检测的时候可能效果更好!
一切准备就绪,直接运行咱们的 test_video.py 程序进行目标检测:
python3 test_video.py
按键 “s” 开启目标检测功能,按键 “q” 退出当前目标检测程序!
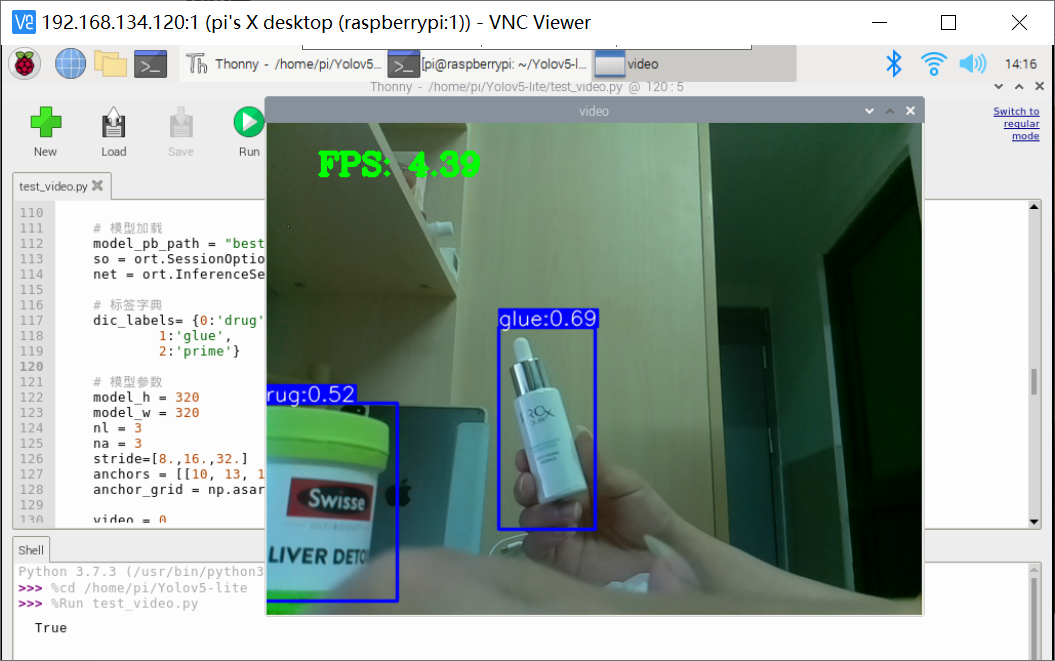
本次仅使用了 ONNX 模型下直接跑 YOLOv5-Lite 的网络模型,目前该状态下的FPS仅维持在5左右,效果其实比直接跑 YOLOv5 网络模型已经好很多了(YOLOv5的FPS在0.3FPS左右)。但是距离可以与控制结合感觉还是差了点。
五、"迷宫寻宝"光电智能小车
引言
1、综合运用光电传感、计算机视觉、路径规划技术完成了光电智能寻宝小车。
2、使用OpenCV技术处理图像,通过边缘检测、轮廓提取、透视变换完成宝藏图识别。
3、使用YOLOv5-Lite算法,通过网络模型训练实现了四种宝物的判别。
4、依据宝物对称规则,判断宝藏真伪后进行“剪枝”操作,排除宝藏点并根据广度优先算法规划最短路径。
5、“记忆”功能,即小车可记忆到达过的宝藏点;中断重启后可直接前往未到达过的宝藏点。
本光电智能小车采用树莓派4B单板计算机作为主控设备,搭载各外设有摄像头模块、八路灰度传感器循迹模块、超声波测距模块和直流电机驱动模块。小车使用摄像头搭配OpenCV技术实现了宝藏图的识别;并采用YOLOv5技术进行真、伪宝物判断;运用广度优先算法实现了最短路径规划;使用灰度传感器和超声波测距实现了自动循迹驾驶。小车完成了“迷宫寻宝”全部功能。
作品实现方案
整体实现流程
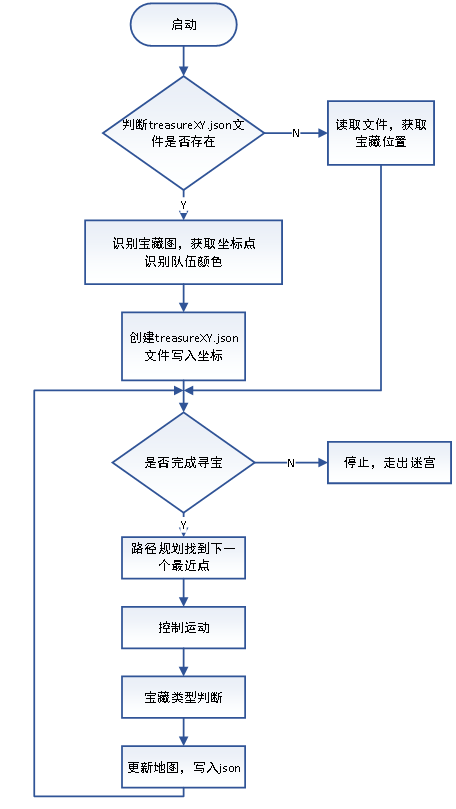
首先小车启动后会判断treasureXY.json文件是否存在,若文件存在则小车会直接从文件中读取宝藏位置;若文件不存在,即小车第一次启动,还未进行宝藏提的识别,则小车会首先进行宝藏图的识别,进而获取宝藏位置,并将该位置信息写入treasureXY.json文件。
该文件中存放的是宝藏在迷宫图中的位置信息、队伍颜色信息和已经判别的真宝藏个数信息,并且该文件中存放的宝藏位置会随着小车每次到达宝藏点进行判别真伪后更新,直到小车走出迷宫。
该json文件存在的意义在于,小车具备了“记忆“功能(持久化存储),即在迷宫中正常寻宝过程中会记录下已经到达过的宝藏点,若中途与对方相撞导致循迹不能正常进行,或发生其他形式的中断,本小车可重启后直接前往还未到达过的宝藏点,将已经识别过的宝藏点排除,进而很大程度上减少了走出迷宫的时间,提高了整个寻宝过程的可靠性。
判别队伍颜色是通过识别宝藏图上的红/蓝色方块,该部分是和宝藏图识别同时进行。考虑到迷宫图的对称特性,上下颠倒不会产生影响,我们将左下角有色方块作为判别依据,通过对图像覆盖红/蓝色掩膜,进行颜色突出,让小车知道己方是红队或是蓝队。
接着小车会自动规划路径,并自动巡航驾驶,到达最近的宝藏点进行宝物判断。判断完成后,小车会依据宝物位置双色交错对称规则进行宝藏点的排除,这样的优势在于小车无需将8个宝藏点全部遍历,而只需最多前往6个宝藏点即可找到己方的三个真宝藏。最终走出迷宫。
宝藏图识别模块
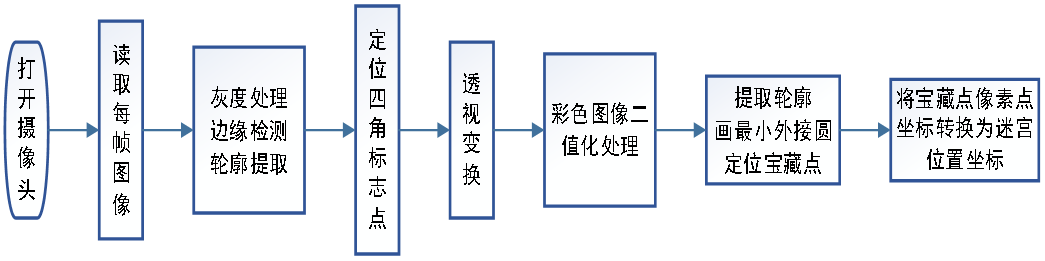
宝藏图识别功能采用OpenCV(计算机视觉)技术实现,其整体流程如图所示。
之后对提取到的轮廓进行遍历,画其最小外接矩形,并限制长、宽范围使其接近正方形,目的是定位四个角落的标志点。
对四个标志点进行透视变换可将原本倾斜的图像投影到一个平面,目的是消除拍照过程中由于人为操作所造成的图像倾斜。
将得到的平面彩色图像二值化处理,即转换为黑白图像,这样做的目的是消除由于光照不均匀所产生的噪声,并且二值化操作简化了图像,使其更易于处理。
将此黑白图像进行特征点轮廓提取,遍历每一个轮廓,画其最小外接圆,这样就可定位图中宝藏点的像素点位置,进行相应的坐标变换,即可得到宝藏在迷宫图中的位置。
该过程也会同时通过图像左下角红/蓝色方块识别队伍颜色信息。如下图所示。
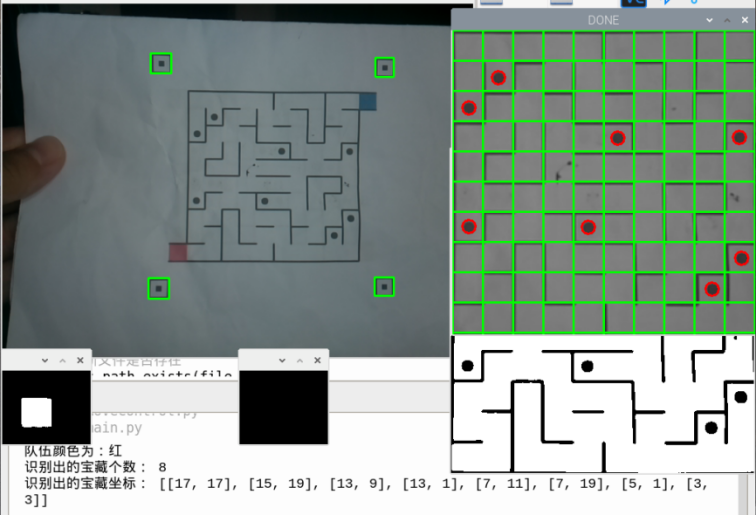
从图中可以看到,该识图装置正确识别了8个宝藏的位置信息,并且由于左下角为红色方块,因此识别队伍颜色为红。原图像为彩色图像,在经过灰度处理和透视变换后的平面图象中标出网格线,宝藏位置即可轻易获取。
真伪宝藏判别模块
真伪宝藏判别功能采用YOLOv5技术。但由于YOLOv5对算力的依赖较大,故采用YOLOv5-Lite版本。YOLOv5-Lite相比于YOLOv5虽然牺牲了部分网络模型精度,但是却极大的提升了模型的推理速度,该模型属性将更适合树莓派部署使用。
以下是本次YOLOv5网络模型部署使用的部分代码。
def cal_outputs(outs,nl,na,model_w,model_h,anchor_grid,stride):
row_ind = 0
grid = [np.zeros(1)] * nl
for i in range(nl):
h, w = int(model_w/ stride[i]), int(model_h / stride[i])
length = int(na * h * w)
if grid[i].shape[2:4] != (h, w):
grid[i] = _make_grid(w, h)
outs[row_ind:row_ind + length, 0:2] = (outs[row_ind:row_ind + length, 0:2] * 2. - 0.5 + np.tile(
grid[i], (na, 1))) * int(stride[i])
outs[row_ind:row_ind + length, 2:4] = (outs[row_ind:row_ind + length, 2:4] * 2) ** 2 * np.repeat(
anchor_grid[i], h * w, axis=0)
row_ind += length
return outs
这段代码是YOLO算法的一部分,用于计算模型的输出。定义变量grid为一个长度nl的列表,用存储每个尺度下的网格信息。通过循环对每个尺度进行处理。过程为:首先将输出的前两列(表示预测框的中心坐标)进行归一化处理,然后加上网格信息和偏移量,再乘步长,得到相对于原图的坐标。然后将输出的后两列(表示预测框的宽度和高度)进行归一化处理,然后进行平方和乘法操作,得到绝对值尺度。通过更新row_ind记录输出索引。最后返回处理后的输出。
def infer_img(img0,net,model_h,model_w,nl,na,stride,anchor_grid,thred_nms=0.4,thred_cond=0.5):
# 图像预处理
img = cv2.resize(img0, tuple([model_w,model_h]), interpolation=cv2.INTER_AREA)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32) / 255.0
blob = np.expand_dims(np.transpose(img, (2, 0, 1)), axis=0)
# 模型推理
outs = net.run(None, {net.get_inputs()[0].name: blob})[0].squeeze(axis=0)
# 输出坐标矫正
outs = cal_outputs(outs,nl,na,model_w,model_h,anchor_grid,stride)
# 检测框计算
img_h,img_w,_ = np.shape(img0)
boxes,confs,ids = post_process_opencv(outs,model_h,model_w,img_h,img_w,thred_nms,thred_cond)
return boxes,confs,ids
这段代码是YOLO模型的推理函数,下面是对代码的解释:
1.图像预处理。首先,将输入图像img0的尺寸调整为模型所需的大小。然后将图像的颜色空间从BGR转换为RGB。接下来,将图像转换为浮点型,并将像素值归一化到0-1的范围内。最后,将图像的维度顺序从(H,W,C)转换为(C,H,W),并添加一个额外的维度作为批次维度。
2.模型推理。将预处理后的图像输入到YOLO模型中进行推理。
3.输出坐标校正。将模型的输出通过cal_outputs函数进行坐标校正。cal_outputs函数根据模型的输出(outs),网格数量(nl和na),模型的宽度,高度和步长来矫正输出的边界框。
4.检测狂计算。获取原始图像的高度(img_h)和宽度img_w。将矫正后的模型输出outs、模型的高度(model_h)、模型的宽度(model_w)、原始图像的高度(img_h)、原始图像的宽度(img_w)、非极大值抑制的阈值(thred_nms)和条件阈值(thred_cond)作为参数,传递给post_process_opencv函数。post_process_opencv函数根据这些参数计算检测框的位置(boxes)、置信度(confs)和类别标签(ids)。
5返回结果。将计算得到的检测框位置、置信度和类别标签作为函数的返回值。
检测宝藏类型的过程为。首先打开树莓派摄像头捕获待识别物体的图像信息。然后加载预先训练的ONNX模型文件。通过infer_img函数对图像进行推理,将识别结果(置信度和类别ID)输出。
最短路径规划模块
小车根据广度优先搜索进行路径规划,并根据对称规则,进行剪枝操作,以达到减少目标点的效果。
最终小车最多需要遍历六个宝藏点,最少仅需遍历三个点。
将地图分为左下、右下、左上、右上四个部分,小车先以起点为出发点,在左下象限寻找最近的宝藏,若为己方真宝藏,则直接剪枝掉本象限另外一个宝藏和中心对称的象限的对应宝藏,并以本点为起始点,规划最短路径到右下象限宝藏点,以此类推,直至走完地图。
该模块实现首先需要将给定的宝藏图初始化,转化成二维数组形式,其中0代表道路可走,1代表墙不可走。
广度优先搜索的思想:使用队列来存取数组中每一个元素。首先将起点压入队列,遍历其周围四个节点,检视其是否已被访问以及是否能走,然后将能走的节点加入队列,并记录加入节点的前节点坐标。
重复以上步骤,直至走到终点,这样就得到了一组从起点到终点的坐标列表。得到坐标列表后,还需将其转化为路径方向和旋转反向才能被小车识别,小车才能按照既定路线行驶。
方法是:用路径坐标的列表,后项减前项,就可得到每一段的位移向量,该向量信息包含了小车从起点到终点的路径信息,即小车每走一段路是需要向上、向下、向左还是向右。但由于小车行驶速度的不均匀性,只通过路径信息小车是不知道需要在何时去执行上述路径操作。
这就需要将路径信息进一步转化成旋转方向,即小车每到一次路口是选择直行、左转还是右转。该旋转方向的获取是通过将上述得到的路径方向向量,后向减前向,这样就得到了一组包含了每个路口旋转方向的向量信息。通过这个旋转方向向量,小车就知道到达路口后该如何行驶,就能走出从起点到终点的最短路径。
如下图所示,是一个可视化的二维迷宫图。图中标出了从起点到达第一个宝藏点的最短路径。

依据上述最短路径分析,输出坐标列表、路径方向和旋转方向如下所示。
坐标列表: [[19, 1], [19, 2], [19, 3], [18, 3], [17, 3], [17, 2], [17, 1], [16, 1], [15, 1], [15, 2], [15, 3], [14, 3], [13, 3], [13, 4], [13, 5], [12, 5], [11, 5], [11, 4], [11, 3], [11, 2], [11, 1], [12, 1], [13, 1]]
路径方向: [1, 1, 0, 0, 3, 3, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 3, 3, 3, 3, 2, 2]
旋转方向: [3, 3, 1, 1, 3, 1, 3, 3, 3]
其中在路径方向中,0代表向上;1代表向右;2代表向下;3代表向左。在旋转方向种,0代表直行;1代表右转;3代表左转。
下图是走完全部迷宫后的可视化路线图。

中断重启模块
考虑到小车在地图中寻迹可能与对方车辆发生碰撞,导致小车无法顺利跑完剩余地图。
特加入中断重启模块,原理大致为:小车每一次寻得宝藏后,更新地图信息的同时,把地图信息持久化存储于json文件中。若小车发生中断,重启后无需重新识别地图,通过读取json中未到达的坐标点,重新进行路径规划,直接前往未识别过的宝藏点,对于已经识别过的宝藏点不会再次去判断。
小车启动后后首先判断该json文件是否存在。若不存在,则表明小车还未获取宝藏点位置,需要识别宝藏图,获取宝藏位置信息后写入json文件然后启动。若该文件存在,则小车会直接读取该文件信息,进行循迹,无需再次识别地图。以下是该模块功能实现代码展示。
若json文件不存在:
else:
treasure_list, TC = findTreasureXY()
if TC == 0:
teamColor = 2
else:
teamColor = TC
json_list = {"matrix":treasure_list, "TC":teamColor, "count":0}
json_str = json.dumps(json_list)
#将宝藏坐标;队伍颜色;已找到宝藏个数存入json文件
with open("matrix.json", "w") as file:
file.write(json_str)
#接着执行路径规划,宝藏判别等操作
TD = FindNearestTreasure.TreasureDetector(0)
TD.classifyXY(treasure_list)
......
若json文件存在:
if os.path.exists(file_path):
# 直接从文件种加载数据
with open("matrix.json", "r") as file:
JSdata = json.load(file)
#接着执行路径规划,宝藏判别等操作
TD = FindNearestTreasure.TreasureDetector(0)
TD.classifyXY(treasure_list)
......
灰度传感器循迹模块
该灰度传感器的主要结构为具有八对稳定的光电对管,如图是一个光电对管的简易示意图。
发光二极管发出一束光,被检测面反射后,照射到光电三极管种。
光电三极管是一个对光线敏感的器件,进光量越多,经过他的电流也就越大。
当一束光照射到检测面后,一部分被检测面吸收,一部分反射到光电三极管中,于是产生了电流值。
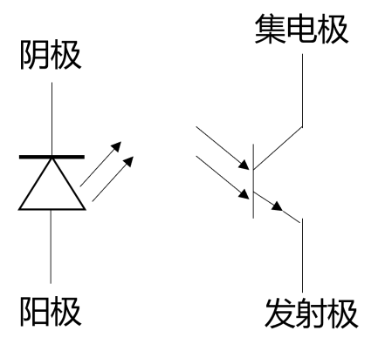
检测面的灰度越深对于光的吸收越强,而反射的光线也会越弱,能被三极管捕捉的光线也就越少了。
于是可得出结论:不同的检测面灰度,会产生不同的电流值。
光电三极管中的电流信号利用欧姆定律被转化为一个电压信号,电压信号经ADC(数模转换器)捕获后转化为数字信号,这样就完成了灰度值—电流信号—电压信号—数字信号的转变。
考虑到迷宫车道地面为白色,车道的中线粘贴约2cm宽的黑色胶带作为循迹线,当使用灰度传感器循迹时,处于黑色线上方的光电对管由于黑线对光的吸收,则光电三极管接收不到光线,进而不能产生电流信号,也不会产生相应的电压信号,那么此输出端会向芯片输出一个低电平。
而其他不在黑线之上的光电对管,由于白色不会吸收光线,光电三极管接收光线强,产生相应的电流信号,转化为电压信号,则在此输出端会向芯片输出一个高电平。
此传感器为八路灰度传感器,具有八对光电对管,通过并行输出方式,将八路传感器状态输出给小车的主控芯片,芯片即可依据八路信号高低电平的变化情况,判断黑色循迹线相对于小车中线的位置,进而驱动电机控制小车运动状态。
该传感器的测量使用高度对检测的灵敏度和稳定性都有影响。
当检测距离较近时,测量灵敏度越高但不稳定;检测高度越高,灰度检测越稳定,但是如果距离太远,由于传感器灵敏度降低,易出现传感器判别不清的情况。
因此在实际使用中,将此传感器置于距离地面2cm左右能做到即稳定又灵敏。
电机驱动模块
该模块用到了四个直流电机,左侧两个电机并联,右侧两个电机并联,连接方式如图所示。
该直流电机内部结构主要包含有转子、定子即环状永磁体。其工作原理是基于洛伦兹力和电磁感应的相互作用。
当电流通过转子是,在环状永磁体产生的磁场中,根据右手定则,电流方向和磁场方向之间会产生一个力的方向。
根据洛伦兹定律,这个力会使转子开始旋转。同时,转子旋转时,由于转子中导线在磁场中移动,会产生一个感应电动势,即电磁感应现象。这个感应电动势会产生一个电流,这个电流又会产生一个磁场,与原有的磁场相互作用,进一步增强了力矩,是电机的转速增加。
直流电机的转速与电压和负载有关。电压越高,电机的转速越快。本模块中电机带动小车的运动状态主要分为以下7种:直行、后退、左转、右转、向左微调、向右微调和掉头。
不同的运动状态主要区别在于施加到小车左右两侧电机的电压不同。
例如:若要小车直行,则需在左右两侧同时施加相同的正向电压;若要后退则施加反向电压。若要左转则在左侧电机施加反向电压,右侧电机施加正向电压。右转同理。小车在正常直行过程中有时会稍微偏离轨道,需要进行微调,此时将左右两侧电机施加不同大小的电压,即具有一定的电压差,电压大的一侧电机转速快,电压小的一侧电机转速慢,就可实现微调。掉头的实现与转弯相同,只需增大转弯时间即可。
该模块引入了PID控制理论。通过P(比例)、I(积分)和D(微分)三个参数对系统进行闭环处理。使系统维持稳定输出。
本次任务中使用了位置式PID算法。即通过八路灰度传感器实时读取小车体与黑涩循迹线的位置偏差,通过该偏差值赋予左右电机不同速度进行巡线驾驶。PID的引入,使得本小车速度得到了极大提升。
具体代码实现如下
位置式PID读取偏差:
# 获取当前位置偏差
# -7 --> 7
# 全检测不到-8;全检测到是0
def readTrackData():
Start_Poi = 0
End_Poi = 0
for i in range(8):
if Start_Poi == 0:
if GPIO.input(Tracking[i]) == 0:
Start_Poi = i * 2 + 1
else:
if GPIO.input(Tracking[i]) != 0:
End_Poi = (i - 1) * 2 + 1
break
if Start_Poi != 0 and End_Poi == 0:
End_Poi = 15
return int((Start_Poi + End_Poi) / 2 - 8)
小车左转状态:
def turnLeft():
car.Car_Spin_Left(125, 140)
time.sleep(0.2)
while 1:
car.Car_Spin_Left(125, 140)
time.sleep(0.007)
Tracking_1Value = GPIO.input(Tracking[1])
Tracking_2Value = GPIO.input(Tracking[2])
Tracking_3Value = GPIO.input(Tracking[3])
Tracking_4Value = GPIO.input(Tracking[4])
if Tracking_1Value == 1 and (Tracking_2Value == 0 or Tracking_3Value == 0) and Tracking_4Value == 1:
break
小车右转状态:
def turnRight():
car.Car_Spin_Right(130, 135)
time.sleep(0.2)
while 1:
car.Car_Spin_Right(130, 135)
time.sleep(0.007)
Tracking_3Value = GPIO.input(Tracking[3])
Tracking_4Value = GPIO.input(Tracking[4])
Tracking_5Value = GPIO.input(Tracking[5])
Tracking_6Value = GPIO.input(Tracking[6])
if Tracking_3Value == 1 and (Tracking_4Value == 0 or Tracking_5Value == 0) and Tracking_6Value == 1:
break
超声波测距模块
块使用了HCSR04超声波测距传感器,其具有四个接线端分别为VCC、TRIG、ECHO和GND,其中TRIG为触发脉冲信号输入端,ECHO为回响信号输出端。
该模块工作原理为:首先在TRIG端输入一个大于10us的高电平脉冲作为触发信号,模块接收触发信号后会将ECHO端拉高并发射超声波,直至声波被障碍物反射后被该模块接收器接收并将ECHO端拉低,这样就在ECHO端输出一个与距离等比的高电平脉冲信号。主控设备在接受ECHO回响信号后根据脉宽时间计算距离,以下是距离计算公式:
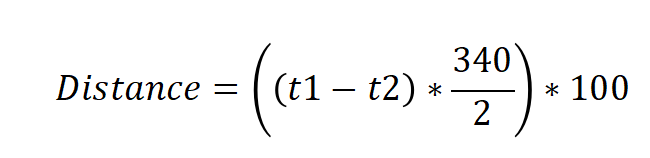
其中t1为起始时间,t2为结束时间,距离单位为厘米。以下为程序实现代码。
def Distance():
GPIO.output(TrigPin,GPIO.LOW)
time.sleep(0.000002)
GPIO.output(TrigPin,GPIO.HIGH)
time.sleep(0.000015)
GPIO.output(TrigPin,GPIO.LOW)
t3 = time.time()
while not GPIO.input(EchoPin):
t4 = time.time()
if (t4 - t3) > 0.03 :
return -1
t1 = time.time()
while GPIO.input(EchoPin):
t5 = time.time()
if(t5 - t1) > 0.03 :
return -1
t2 = time.time()
time.sleep(0.01)
return ((t2 - t1)* 340 / 2) * 100
作品设计建构说明
以下是本作品的实物展示。

本作品实际机械机构中各各组成部件介绍:1.防撞扩展支架。2.摄像头。3.USB接口的LED补光灯板。4.HCSR04超声波测距模块。5.灰度传感器模块。6.摄像头固定云台。7.4.3寸显示屏。8.树莓派4B主控板。9.启动按键及小车扩展板。10.12.6V锂电池组。11.防滑轮胎。
如图所示小车最前方安装了防撞扩展支架,用于撞倒宝藏和当与对方车辆相撞时保护己方车辆。
摄像头倾斜向下,用于宝藏识别和地图识别,其后置有LED补光灯板,用于提供光照,以免由于光照不足导致识别不准确。
超声波测距传感器在摄像头下方,用于在行驶过程中测量小车与宝藏的距离,以便于在宝藏前停下。
小车前端底部装有灰度循迹传感器,用于循迹黑线控制小车行驶。
摄像头云台用于固定摄像头,以面由于碰撞导致摄像头滑落。
树莓派数控板安装在小车上方,通过40根排线与小车扩展盘相连,控制小车运行。
最后方为12V锂电池组,用于给小车供电。
小车扩展版作为最基础结构,用于固定连接各各组件。
下图是小车扩展版底部电机排布情况。

如图所示,小车共四个直流电机,用于驱动小车运动。
左侧两个电机并联,右侧两个电机并联。
通过施加不同的电压,左右两侧电机转速不同,达到差速的目的,进而来驱动小车直行、转弯和掉头等运动状态。
作品达到的效果
本作品综合运用图象识别,路径规划,光电传感,计算机视觉等技术完成了“迷宫寻宝”光电智能小车全部功能。
1.小车附带车载的识图装置(即小车前方摄像头)用于识别宝藏图。
宝藏图的识别是通过OpenCV(计算机视觉)技术,通过定位四个角落标志点,进行透视变换,之后对图像二值化处理,识别图中轮廓,提取图中宝藏点坐标。
整个过程十分迅速,只需不到一分钟左右时间就能识别出全部宝藏位置信息。同时在识别地图过程中。根据宝藏图左下角的有色方块,就可识别队伍颜色。
2.小车在识别完地图后,可通过一键式操作启动,完成迷宫寻宝。
小车依据宝藏位置分布规则,即:宝藏及伪宝藏的位置按宝藏图随即摆放、双色交错对称,迷宫的上下左右四个象限区域内各放置一个红色和一个蓝色宝藏,小车会率先前往所在象限中最近一点进行宝物识别,若该宝藏为己方真宝藏,则表明该象限另一宝藏必为对方宝藏,并且与当前宝藏对称分布的宝藏也必为对方宝藏。
据此本小车会直接前往下一个象限内最近一宝藏点进行判别,自动排除本象限内另一宝藏点和对称宝藏点。
这样做的目的是本小车可通过最短的路径来找到八个宝藏中己方的三个真宝藏,而无需全部遍历,很大程度缩短了寻宝时间。
作品的创新点和优势
本作品的的创新点和优势主要在于:
1.使用OpenCV(计算机视觉)技术使小车具备了视觉处理功能;
2.在路径规划中小车利用广度优先算法计算最短路径,使小车每次前往的宝藏点都是距离当前最近的一点。
并且小车会自动实时根据已经判别的宝藏类型和宝藏位置分布来更新地图,使该小车最少只需到达三个宝藏点最多到达留个宝藏点就能找到三个己方真宝藏,缩短了寻宝时间,这是本小车优势之一。
3.小车具备“记忆”性功能,即小车可记忆已经到达的宝藏点,并实时更新存储信息,这样小车在正常行驶过程中若与对方车辆发生碰撞或发生其它形式的中断导致不能正常循迹,小车可中断重启后直接前往还未到达过的宝藏点,之前已经到达过的宝藏点会在小车“记忆”存储中直接排除,进而很大程度上减少了走出迷宫的时间,提高了整个寻宝过程的可靠性。这也是本小车最大优势之处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号