PA2.2-运行时环境和基础设施
📚 使用须知
- 本博客内容仅供学习参考
- 建议理解思路后独立实现
- 欢迎交流讨论
程序,运行时环境与AM
通过批处理模式运行NEMU
我们知道, 大部分同学很可能会这么想: 反正我不阅读Makefile, 老师助教也不知道, 总觉得不看也无所谓.
所以在这里我们加一道必做题: 我们之前启动NEMU的时候, 每次都需要手动键入c才能运行客户程序. 但如果不是为了使用NEMU中的sdb, 我们其实可以节省c的键入. NEMU中实现了一个批处理模式, 可以在启动NEMU之后直接运行客户程序. 请你阅读NEMU的代码并合适地修改Makefile, 使得通过AM的Makefile可以默认启动批处理模式的NEMU.
从我们熟悉的开始
在上一个任务我们要不断地填充指令,然后完成am-kernels/tests/cpu-tests/tests/*.c的测试任务
我们要测试就要在am-kernels/tests/cpu-tests键入命令make ARCH=$ISA-nemu ALL=dummy run
RTFSC,这条命令是如何打开我们实现的NEMU,并且真的运行了test/dummy.c
来看看其下的am-kernels/tests/cpu-tests/Makefile
有点蒙,看不懂?还记得讲义交给我们的方法吗?

重点关注他的输出顺序和我们源代码的组织顺序,我们会发现,原来当我们键入make run
Makefile中会查看run所需的依赖文件,然后在Makefile中不断寻找
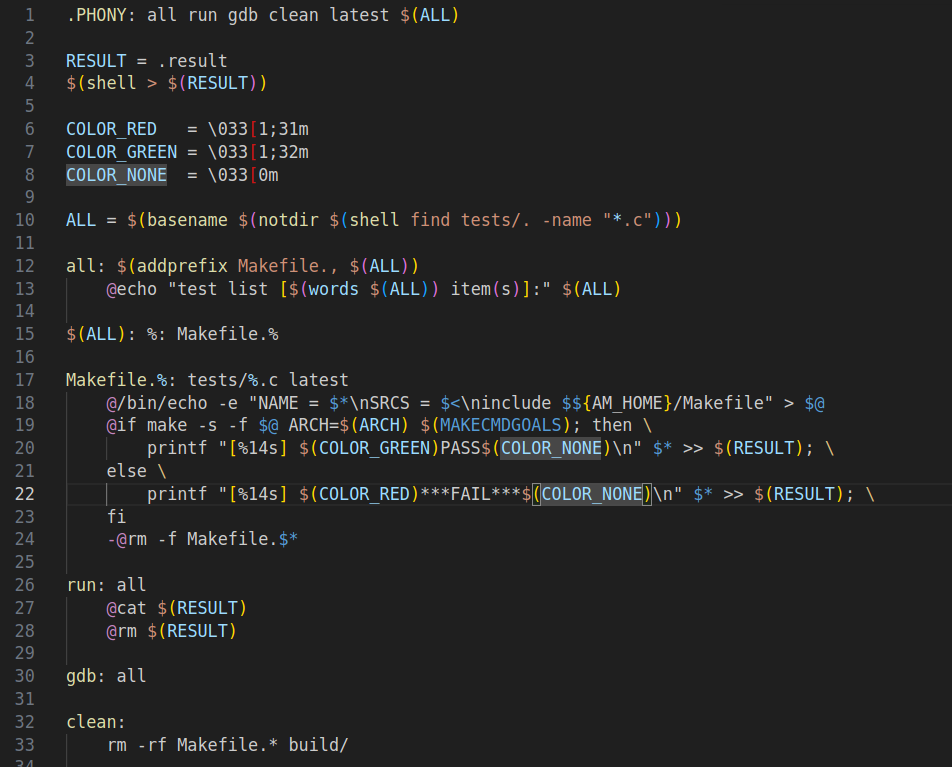
这里run:all,即run依赖的文件(标签)是all
然后去实现all,又发现all依赖着Makefile.xxx(xxx是我们传入.c文件名,有没传入的话就默认是/test/*.c)
然后又发现Makefile.xxx依赖着test/xxx.c和latest
...
直到全部的依赖文件都准备好了
还可以发现,其实我们真正执行的make run 还包括abstract-machine/Makefile下的run
/bin/echo -e "NAME = dummy\nSRCS = tests/dummy.c\ninclude ${AM_HOME}/Makefile" > Makefile.dummy
这是一个bash命令,我们相当于在abstract-machine/Makefile中多定义了NAME = dummy,SRCS = tests/dummy.c,然后开始执行abstract-machine/Makefile
这个时候我们再看abstract-machine/Makefile,就会发现原来找不到NAME和SRCS这两个变量 是通过这种方式'传'到abstract-machine/Makefile中的!
那么abstract-machine/Makefile中的run呢?
//abstract-machine/Makefile
-include $(AM_HOME)/scripts/$(ARCH).mk
//abstract-machine/scripts/riscv32-nemu.mk
include $(AM_HOME)/scripts/isa/riscv.mk
include $(AM_HOME)/scripts/platform/nemu.mk
在abstract-machine/scripts/platform/nemu.mk中
//abstract-machine/scripts/platform/nemu.mk
run: image
$(MAKE) -C $(NEMU_HOME) ISA=$(ISA) run ARGS="$(NEMUFLAGS)" IMG=$(IMAGE).bin
可以看到这里的$(NEMU_HOME),-C 选项后面跟着一个目录路径,表示在执行 make 命令之前,先切换到指定的目录路径下,然后再执行 make 命令。
来看看NEMU中的Makefile
//nemu/scripts/native.mk
NEMU_EXEC := $(BINARY) $(ARGS) $(IMG)
run: run-env
$(call git_commit, "run NEMU")
$(NEMU_EXEC)
我们再来看看NEMU中的源码
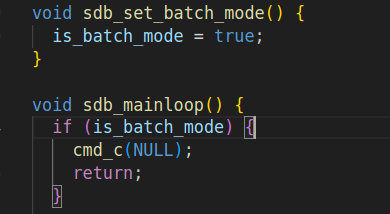
is_batch_mode? 批处理模式?
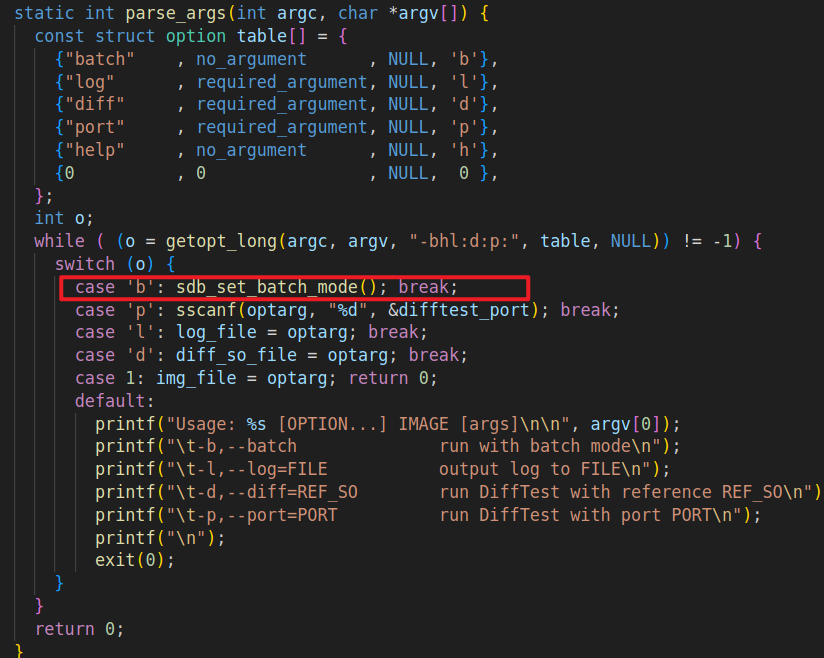
所以我们只要在运行NEMU时传入参数b即可
小小总结
所以我们能够看到abstract-machine还真就全心全意在做一件事情:提供运行时的环境

目前为止,我看到了abstract-machine能够将我们再linux中写的c代码转为我们NEMU中以riscv32为架构的可执行代码,并调用我们再NEMU中实现的TRM(图灵机)(我们再NEMU中实现了简易调试器sdb和图灵机TRM),完成了在NEMU上运行代码!
实现常用的库函数
实现字符串处理函数
根据需要实现abstract-machine/klib/src/string.c中列出的字符串处理函数, 让cpu-tests中的测试用例string可以成功运行. 关于这些库函数的具体行为, 请务必RTFM.
点击查看代码
#include <klib.h>
#include <klib-macros.h>
#include <stdint.h>
#if !defined(__ISA_NATIVE__) || defined(__NATIVE_USE_KLIB__)
size_t strlen(const char *s) {
const char *p = s;
while (*p != '\0') {
p++;
}
return p - s;
}
char *strcpy(char *dst, const char *src) {
char *d = dst;
while ((*d++ = *src++) != '\0') {
// nothing
}
return dst;
}
char *strncpy(char *dst, const char *src, size_t n) {
char *d = dst;
while (n > 0 && *src != '\0') {
*d++ = *src++;
n--;
}
while (n > 0) {
*d++ = '\0';
n--;
}
return dst;
}
char *strcat(char *dst, const char *src) {
char *d = dst;
// 找到dst的结尾
while (*d != '\0') {
d++;
}
// 复制src到dst结尾
while ((*d++ = *src++) != '\0') {
// nothing
}
return dst;
}
int strcmp(const char *s1, const char *s2) {
while (*s1 && *s1 == *s2) {
s1++;
s2++;
}
return *(unsigned char *)s1 - *(unsigned char *)s2;
}
int strncmp(const char *s1, const char *s2, size_t n) {
if (n == 0) return 0;
while (n > 1 && *s1 && *s1 == *s2) {
s1++;
s2++;
n--;
}
return *(unsigned char *)s1 - *(unsigned char *)s2;
}
void *memset(void *s, int c, size_t n) {
unsigned char *p = (unsigned char *)s;
unsigned char value = (unsigned char)c;
// 简单循环设置每个字节
for (size_t i = 0; i < n; i++) {
p[i] = value;
}
return s;
}
void *memmove(void *dst, const void *src, size_t n) {
unsigned char *d = (unsigned char *)dst;
const unsigned char *s = (const unsigned char *)src;
// 如果目标地址在源地址之前,或者不重叠,从前往后复制
if (d < s || d >= s + n) {
for (size_t i = 0; i < n; i++) {
d[i] = s[i];
}
}
// 如果目标地址在源地址之后且有重叠,从后往前复制
else {
for (size_t i = n; i > 0; i--) {
d[i - 1] = s[i - 1];
}
}
return dst;
}
void *memcpy(void *out, const void *in, size_t n) {
unsigned char *dst = (unsigned char *)out;
const unsigned char *src = (const unsigned char *)in;
// memcpy不处理重叠,直接复制
for (size_t i = 0; i < n; i++) {
dst[i] = src[i];
}
return out;
}
int memcmp(const void *s1, const void *s2, size_t n) {
const unsigned char *p1 = (const unsigned char *)s1;
const unsigned char *p2 = (const unsigned char *)s2;
for (size_t i = 0; i < n; i++) {
if (p1[i] != p2[i]) {
return p1[i] - p2[i];
}
}
return 0;
}
#endif
函数说明
- strcmp
int strcmp(const char *s1, const char *s2)
逐字符比较两个字符串
当字符不同或到达字符串结尾时停止
返回值:
<0 如果 s1 < s2
0 如果 s1 == s2
>0 如果 s1 > s2
- strncmp
int strncmp(const char *s1, const char *s2, size_t n)
比较两个字符串的前n个字符
如果n为0,直接返回0
比较过程中遇到'\0'也会停止
- memcmp
int memcmp(const void *s1, const void *s2, size_t n)
比较两个内存区域的前n个字节
按字节比较,不关心字符串的'\0'结束符
返回第一个不同字节的差值
- memset
void *memset(void *s, int c, size_t n)
将内存区域的前n个字节设置为值c
注意:c被转换为unsigned char类型
返回原始指针s
- 其他函数的要点:
memmove:处理内存重叠的情况,根据源地址和目标地址的相对位置决定复制方向
memcpy:不处理内存重叠,直接复制
strncpy:可能不会以'\0'结尾,如果源字符串长度小于n,会用'\0'填充剩余部分
所有函数都使用unsigned char类型进行指针操作,避免符号扩展问题
这些实现是标准库函数的基本版本,为了清晰易懂没有进行性能优化(如字对齐操作等)。在实际使用时,可以根据目标平台的特点进行优化。
实现sprintf
实现abstract-machine/klib/src/stdio.c中的sprintf(), 具体行为可以参考man 3 printf. 目前你只需要实现%s和%d就能通过hello-str的测试了, 其它功能(包括位宽, 精度等)可以在将来需要的时候再自行实现.
点击查看代码
#include <am.h>
#include <klib.h>
#include <klib-macros.h>
#include <stdarg.h>
#if !defined(__ISA_NATIVE__) || defined(__NATIVE_USE_KLIB__)
// 辅助函数:将整数转换为字符串
static char* itoa(int value, char* str, int base) {
char* ptr = str;
char* ptr1 = str;
char tmp_char;
int tmp_value;
// 处理负数(仅限于十进制)
if (base == 10 && value < 0) {
*ptr++ = '-';
value = -value;
ptr1++;
}
// 生成数字字符串(逆序)
do {
tmp_value = value;
value /= base;
*ptr++ = "0123456789abcdef"[tmp_value - value * base];
} while (value);
*ptr-- = '\0';
// 反转字符串
while (ptr1 < ptr) {
tmp_char = *ptr;
*ptr-- = *ptr1;
*ptr1++ = tmp_char;
}
return str;
}
// 辅助函数:将无符号整数转换为字符串
static char* utoa(unsigned int value, char* str, int base) {
char* ptr = str;
char* ptr1 = str;
char tmp_char;
unsigned int tmp_value;
// 生成数字字符串(逆序)
do {
tmp_value = value;
value /= base;
*ptr++ = "0123456789abcdef"[tmp_value - value * base];
} while (value);
*ptr-- = '\0';
// 反转字符串
while (ptr1 < ptr) {
tmp_char = *ptr;
*ptr-- = *ptr1;
*ptr1++ = tmp_char;
}
return str;
}
// 辅助函数:输出一个字符到缓冲区
static void output_char(char** out, char c) {
*(*out)++ = c;
}
// 核心格式化函数
static int format_string(char* out, const char* fmt, va_list ap) {
char* original_out = out;
char buffer[32]; // 用于数字转换的临时缓冲区
while (*fmt) {
if (*fmt == '%') {
fmt++; // 跳过 '%'
switch (*fmt) {
case 'd': // 有符号十进制整数
case 'i': {
int num = va_arg(ap, int);
itoa(num, buffer, 10);
char* p = buffer;
while (*p) {
output_char(&out, *p++);
}
break;
}
case 'u': { // 无符号十进制整数
unsigned int num = va_arg(ap, unsigned int);
utoa(num, buffer, 10);
char* p = buffer;
while (*p) {
output_char(&out, *p++);
}
break;
}
case 'x': // 十六进制整数(小写)
case 'X': { // 十六进制整数(大写)
unsigned int num = va_arg(ap, unsigned int);
utoa(num, buffer, 16);
// 如果是大写,转换为大写
if (*fmt == 'X') {
char* p = buffer;
while (*p) {
if (*p >= 'a' && *p <= 'f') {
*p = *p - 'a' + 'A';
}
p++;
}
}
char* p = buffer;
while (*p) {
output_char(&out, *p++);
}
break;
}
case 'c': { // 字符
char c = (char)va_arg(ap, int);
output_char(&out, c);
break;
}
case 's': { // 字符串
char* str = va_arg(ap, char*);
if (str == NULL) {
str = "(null)";
}
while (*str) {
output_char(&out, *str++);
}
break;
}
case 'p': { // 指针
void* ptr = va_arg(ap, void*);
unsigned int addr = (unsigned int)(uintptr_t)ptr;
output_char(&out, '0');
output_char(&out, 'x');
utoa(addr, buffer, 16);
char* p = buffer;
while (*p) {
output_char(&out, *p++);
}
break;
}
case '%': { // 百分号
output_char(&out, '%');
break;
}
default: {
// 不支持的格式,直接输出字符
output_char(&out, '%');
output_char(&out, *fmt);
break;
}
}
} else {
// 普通字符,直接输出
output_char(&out, *fmt);
}
fmt++;
}
// 添加字符串结束符
*out = '\0';
// 返回写入的字符数(不包括结尾的'\0')
return out - original_out;
}
int vsprintf(char *out, const char *fmt, va_list ap) {
return format_string(out, fmt, ap);
}
int sprintf(char *out, const char *fmt, ...) {
va_list ap;
va_start(ap, fmt);
int result = vsprintf(out, fmt, ap);
va_end(ap);
return result;
}
int snprintf(char *out, size_t n, const char *fmt, ...) {
if (n == 0) {
return 0;
}
va_list ap;
va_start(ap, fmt);
int result = vsnprintf(out, n, fmt, ap);
va_end(ap);
return result;
}
int vsnprintf(char *out, size_t n, const char *fmt, va_list ap) {
if (n == 0) {
return 0;
}
char* original_out = out;
char buffer[32]; // 用于数字转换的临时缓冲区
while (*fmt && n > 1) { // n>1 保留一个字符给'\0'
if (*fmt == '%') {
fmt++; // 跳过 '%'
switch (*fmt) {
case 'd': // 有符号十进制整数
case 'i': {
int num = va_arg(ap, int);
itoa(num, buffer, 10);
char* p = buffer;
while (*p && n > 1) {
*out++ = *p++;
n--;
}
break;
}
case 'u': { // 无符号十进制整数
unsigned int num = va_arg(ap, unsigned int);
utoa(num, buffer, 10);
char* p = buffer;
while (*p && n > 1) {
*out++ = *p++;
n--;
}
break;
}
case 'x': // 十六进制整数(小写)
case 'X': { // 十六进制整数(大写)
unsigned int num = va_arg(ap, unsigned int);
utoa(num, buffer, 16);
// 如果是大写,转换为大写
if (*fmt == 'X') {
char* p = buffer;
while (*p) {
if (*p >= 'a' && *p <= 'f') {
*p = *p - 'a' + 'A';
}
p++;
}
}
char* p = buffer;
while (*p && n > 1) {
*out++ = *p++;
n--;
}
break;
}
case 'c': { // 字符
char c = (char)va_arg(ap, int);
if (n > 1) {
*out++ = c;
n--;
}
break;
}
case 's': { // 字符串
char* str = va_arg(ap, char*);
if (str == NULL) {
str = "(null)";
}
while (*str && n > 1) {
*out++ = *str++;
n--;
}
break;
}
case 'p': { // 指针
void* ptr = va_arg(ap, void*);
unsigned int addr = (unsigned int)(uintptr_t)ptr;
if (n > 3) { // 需要 "0x" + 至少一个数字 + '\0'
*out++ = '0';
*out++ = 'x';
n -= 2;
}
utoa(addr, buffer, 16);
char* p = buffer;
while (*p && n > 1) {
*out++ = *p++;
n--;
}
break;
}
case '%': { // 百分号
if (n > 1) {
*out++ = '%';
n--;
}
break;
}
default: {
// 不支持的格式,直接输出字符
if (n > 2) { // 需要两个字符:'%' + 格式字符
*out++ = '%';
*out++ = *fmt;
n -= 2;
}
break;
}
}
} else {
// 普通字符,直接输出
*out++ = *fmt;
n--;
}
fmt++;
}
// 添加字符串结束符
*out = '\0';
// 返回本应写入的字符数(不包括结尾的'\0')
// 这里简化处理,返回实际写入的字符数
return out - original_out;
}
int printf(const char *fmt, ...) {
// 简单实现:输出到标准输出(假设有一个putch函数)
char buffer[256]; // 限制最大输出长度
va_list ap;
va_start(ap, fmt);
int len = vsnprintf(buffer, sizeof(buffer), fmt, ap);
va_end(ap);
// 假设有 putch 函数输出字符
char* p = buffer;
while (*p) {
putch(*p++);
}
return len;
}
#endif
函数说明
- sprintf
int sprintf(char *out, const char *fmt, ...)
将格式化的字符串写入 out 缓冲区
支持格式:
%d 或 %i:有符号十进制整数
%u:无符号十进制整数
%x:十六进制整数(小写)
%X:十六进制整数(大写)
%c:字符
%s:字符串
%p:指针地址(十六进制)
%%:百分号字符
返回写入的字符数(不包括结尾的\0)
- snprintf
int snprintf(char *out, size_t n, const char *fmt, ...)
安全的 sprintf 版本
n 指定缓冲区大小,防止缓冲区溢出
最多写入 n-1 个字符,最后一个字符总是\0
-
vsprintf和vsnprintf可变参数列表版本,由
sprintf和snprintf调用 -
辅助函数
itoa:将整数转换为字符串(支持十进制)utoa:将无符号整数转换为字符串(支持十进制和十六进制)format_string:核心格式化逻辑 -
printf简单实现,使用
putch输出字符到标准输出假设
putch函数已经实现(需要根据具体平台实现)
注意事项:
这个实现是简化版本,不支持宽度、精度、对齐等高级格式化选项
不支持浮点数格式化(%f, %g 等)
对于不支持的格式字符,会原样输出 % 和该字符
snprintf 和 vsnprintf 会确保不会发生缓冲区溢出
如果需要更完整的实现,可以添加对宽度、精度、左对齐等格式选项的支持

 浙公网安备 33010602011771号
浙公网安备 33010602011771号