【项目】手写数字识别的Qt实现
【项目】手写数字识别的Qt实现
![]()
(logo由豆包生成)
工作流整理
- 利用Pytorch训练手写数字识别模型
- 将模型转化为onnx格式,便于OpenCV调用
- Qt界面开发
- 基本功能测试:包含手写板、检测与清除按钮、预测与置信度输出
- 完整界面化:菜单,多元功能
- 创新功能
- 多模态交互:语音/手势辅助、压感支持
- 模型优化与部署创新:轻量化模型、模型切换、加速推理
- 实时交互反馈:逐笔画检测、置信度可视化、错误纠正闭环
- 数据增强与用户参与
- 界面设计与功能扩展
- 跨平台与隐私保护
- 扩展性与生态集成
- 个性化与用户体验
简单的Pytorch训练
根据【知乎】基于 pytorch 搭建简单网络实现 MNIST 手写数字识别这一指引先简单做一个训练模型
先导入torch相关库
import torchvision.datasets
import torch
from torch.utils import data
from torchvision import transforms
from torch import nn
本项目基于MNIST项目实现,先导入MNIST
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.MNIST(
root = './data', train = True, transform = trans, download = True
)
mnist_test = torchvision.datasets.MNIST(
root = './data', train = False, transform = trans, download = True
)
torch有提供比较方便的接口
batch_size = 64
train_loader = data.DataLoader(mnist_train, batch_size = batch_size)
test_loader = data.DataLoader(mnist_test, batch_size = batch_size)
接着构建一个简单的网络
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, X):
X = self.flatten(X)
logits = self.linear_relu_stack(X)
return logits
这是指引上的写法,事实上并不是很好,等下面把训练写完再细讲
损失函数选择交叉熵损失,优化方式选择随机梯度下降
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr = 1e-3)
然后就是训练和检测函数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(0), y.to(0)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f'loss : {loss : >7f} [{current : >5d} / {size : >5d}]')
def test(dataloader, model):
size = len(dataloader.dataset)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(0), y.to(0)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
print(f'Test Error:\n Accuracy : {100 * correct : >0.1f}%, Avg loss: {test_loss : >8f} \n')
主要过程如下
epochs = 50
for t in range(epochs):
print(f'Epoch {t + 1}\n----------------')
train(train_loader, model, loss_fn, optimizer)
test(test_loader, model)
print('Completed.')
这个时候回到一开始的网络设置,先讲一下主要接口
-
nn.Linear是个线性变换,如下
\[y = Wx + b \] -
nn.ReLU是个激活函数
\[ReLU(x) = \max(0, x) \]
前两层网络的工作是做特征提取和特征激活
最后一步是把特征映射到对应的数字,最后这一层的工作和前面是不一样的,只会考虑线性的评分,而不能用ReLU再一次激活
从数学的角度来看,线性映射出是个结果之后,如果再进行ReLU,那么负值就会被截掉,而交叉熵损失又需要用到softmax函数,这个时候softmax的数值会失真,因而训练效果不会很好
就目前的网络而言,修改方案就是直接去掉最后一个nn.ReLU()
给出最后一次的结果
Epoch 50
----------------
loss : 0.226819 [ 0 / 60000]
loss : 0.261751 [ 6400 / 60000]
loss : 0.190327 [12800 / 60000]
loss : 0.333068 [19200 / 60000]
loss : 0.221980 [25600 / 60000]
loss : 0.304426 [32000 / 60000]
loss : 0.190971 [38400 / 60000]
loss : 0.370367 [44800 / 60000]
loss : 0.297724 [51200 / 60000]
loss : 0.401518 [57600 / 60000]
Test Error:
Accuracy : 92.1%, Avg loss: 0.004319
Completed.
先写个可视化结果看看模型效果
import matplotlib.pyplot as plt
model.eval()
my_test_loader = data.DataLoader(
mnist_test,
batch_size = 64,
shuffle = True
)
X, y = next(iter(my_test_loader))
X, y = X.to(0), y.to(0)
with torch.no_grad():
pred = model(X)
pred_label = pred.argmax(1)
plt.figure(figsize = (10, 10))
for i in range(9):
plt.subplot(3, 3, i + 1)
plt.imshow(X[i].cpu().squeeze(), cmap = 'gray')
plt.title(f'true = {y[i].item()}, pred = {pred_label[i].item()}')
plt.axis('off')
plt.show()

然后就是把模型保存下来
torch.save(model.state_dict(), 'model.pth')
print('Save Pytorch Model State to model.pth')
转化为ONNX格式
不同格式的模型其实都存储着相似的东西,无非就是一些基础信息和权重以及偏置的张量
用onnx接口直接转化就好了
device = 'cpu'
model = NeuralNetwork().to(device)
state_dict = torch.load('model.pth', map_location = device)
model.load_state_dict(state_dict)
model.eval()
dummy_input = torch.randn(1, 1, 28, 28, device = device)
torch.onnx.export(
model,
dummy_input,
'mnist.onnx',
export_params = True,
opset_version = 11,
dynamo = False,
do_constant_folding = True,
input_names = ['input'],
output_names = ['logits'],
dynamic_axes = {
'input' : {0 : 'batch_size'},
'logits' : {0 : 'batch_size'}
}
)
print('Successfully exported.')
接下来讲解一些参数的含义
dummy_input = (batch, channel, height, width)
这是用于统一格式的
export_params = True
这是用于将权重和偏置写入ONNX,否则只导出结构无法进行推理
offset_version = 11
dynamo = False
推理时要用到OpenCV DNN,而其最高的稳定支持版本就是11
把dynamo关掉也是为了给OpenCV稳定接口,不产生一些无法利用的数据
input_names = ['input'],
output_names = ['logits'],
dynamic_axes = {
'input' : {0 : 'batch_size'},
'logits' : {0 : 'batch_size'}
}
这块区域用来告诉ONNX第0维是动态维,不固定为1,便于后续多目标推理
简单Qt页面开发
界面设计
为了简单测试功能,我设计了下面这个布局
_________ [button(predict)]
| |[line edit(predict)]
|DrawBoard|[line edit(confidence)]
_________ [button(clear)]
这时候我初步接触了基于对象继承的个性化组件设计
DrawBoard在Qt组件中并不存在,但是可以自主设计一个
首先在ui上面放一个QWidget占位,让DrawBoard基于QWidget进行设计,然后QWidget就可以直接提升为DrawBoard了
DrawBoard设计
首先给出接口
#pragma once
#include <QWidget>
#include <QImage>
#include <QPoint>
class DrawBoard : public QWidget {
Q_OBJECT
private:
QImage canvas;
QPoint lastPos;
public:
explicit DrawBoard(QWidget *parent = nullptr);
void clear();
std::vector<float> getNormalizedSize() const;
void paintEvent(QPaintEvent *) override;
void mousePressEvent(QMouseEvent *) override;
void mouseMoveEvent(QMouseEvent *) override;
};
主要的原理就是记录鼠标的移动,通过上一次位置和当下的位置连接画出来
初始化阶段产生一个mnist长宽放大十倍的画布,背景设置为黑色
DrawBoard::DrawBoard(QWidget *parent)
: QWidget(parent),
canvas(280, 280, QImage::Format_Grayscale8) {
canvas.fill(Qt::black);
setFixedSize(280, 280);
}
清空就是把背景变为全黑
void DrawBoard::clear() {
canvas.fill(Qt::black);
update();
}
由于画布大小与mnist训练出的模型格式不同,需要变成目标格式并把数值压平
std::vector<float> DrawBoard::getNormalizedSize() const {
QImage small = canvas.scaled(28, 28, Qt::IgnoreAspectRatio, Qt::SmoothTransformation);
std::vector<float> data(28 * 28);
for (int y = 0; y < 28; y++) {
for (int x = 0; x < 28; x++) {
int gray = qGray(small.pixel(x, y));
data[y * 28 + x] = gray / 255.f;
}
}
return data;
}
然后是正常的显示函数
void DrawBoard::paintEvent(QPaintEvent *) {
QPainter p(this);
p.drawImage(0, 0, canvas);
}
接下来处理鼠标行为
规定只有在鼠标左键按下时触发位置设置
void DrawBoard::paintEvent(QPaintEvent *) {
QPainter p(this);
p.drawImage(0, 0, canvas);
}
接着是鼠标移动的逻辑
void DrawBoard::mouseMoveEvent(QMouseEvent *e) {
if (!(e->buttons() & Qt::LeftButton)) return;
QPainter p(&canvas);
p.setPen(QPen(Qt::white, 15, Qt::SolidLine, Qt::RoundCap));
p.drawLine(lastPos, e->pos());
lastPos = e->pos();
update();
}
e->buttons()相对于e->button的区别是,它是个状态判别函数,即现在的鼠标左键是按下的时候就可以继续,而非必须“按下”左键才能继续
鼠标移动时,就把上一个点位和当下的点位连起来
按钮行为
clear的按钮操作很简单
void MainWindow::on_btnClear_clicked() {
ui->editPred->clear();
ui->editConf->clear();
ui->Board->clear();
}
然后是predict按钮,这涉及了OpenCV相关的接口
首先初始化的时候加载模型
cv::dnn::Net net; // 位于MainWindow.h
MainWindow::MainWindow(QWidget *parent)
: QMainWindow(parent)
, ui(new Ui::MainWindow)
{
ui->setupUi(this);
net = cv::dnn::readNetFromONNX("mnist.onnx");
connect(ui->btnPred, &QPushButton::clicked, this, &MainWindow::on_btnPred_clicked);
connect(ui->btnClear, &QPushButton::clicked, this, &MainWindow::on_btnClear_clicked);
}
由于ONNX导出的是logits,因此需要自己再写一个softmax函数
cv::Mat softmax(const cv::Mat& logits) {
CV_Assert(logits.rows == 1);
cv::Mat probs;
logits.copyTo(probs);
double maxVal;
cv::minMaxLoc(probs, nullptr, &maxVal); // 定位最大值
probs -= maxVal; // 减去最大值稳定数值
cv::exp(probs, probs); // exp(src, tar)
double sum = cv::sum(probs)[0];
probs /= sum;
return probs;
}
接着直接用ONNX的数据就可以推理了
void MainWindow::on_btnPred_clicked() {
auto data = ui->Board->getNormalizedSize();
cv::Mat input(1, 28 * 28, CV_32F, data.data());
cv::Mat blob = input.reshape(1, {1, 1, 28, 28}); // 格式转换
net.setInput(blob);
cv::Mat out = net.forward(); // 前向传播得到输出
cv::Mat prob = softmax(out);
cv::Point classId;
double conf;
cv::minMaxLoc(prob, nullptr, &conf, nullptr, &classId);
ui->editPred->setText(QString::fromStdString("Number: ") + QString::number(classId.x));
ui->editConf->setText(QString::fromStdString("Confidence: ") + QString::number(conf, 'f', 4));
}
效果如下
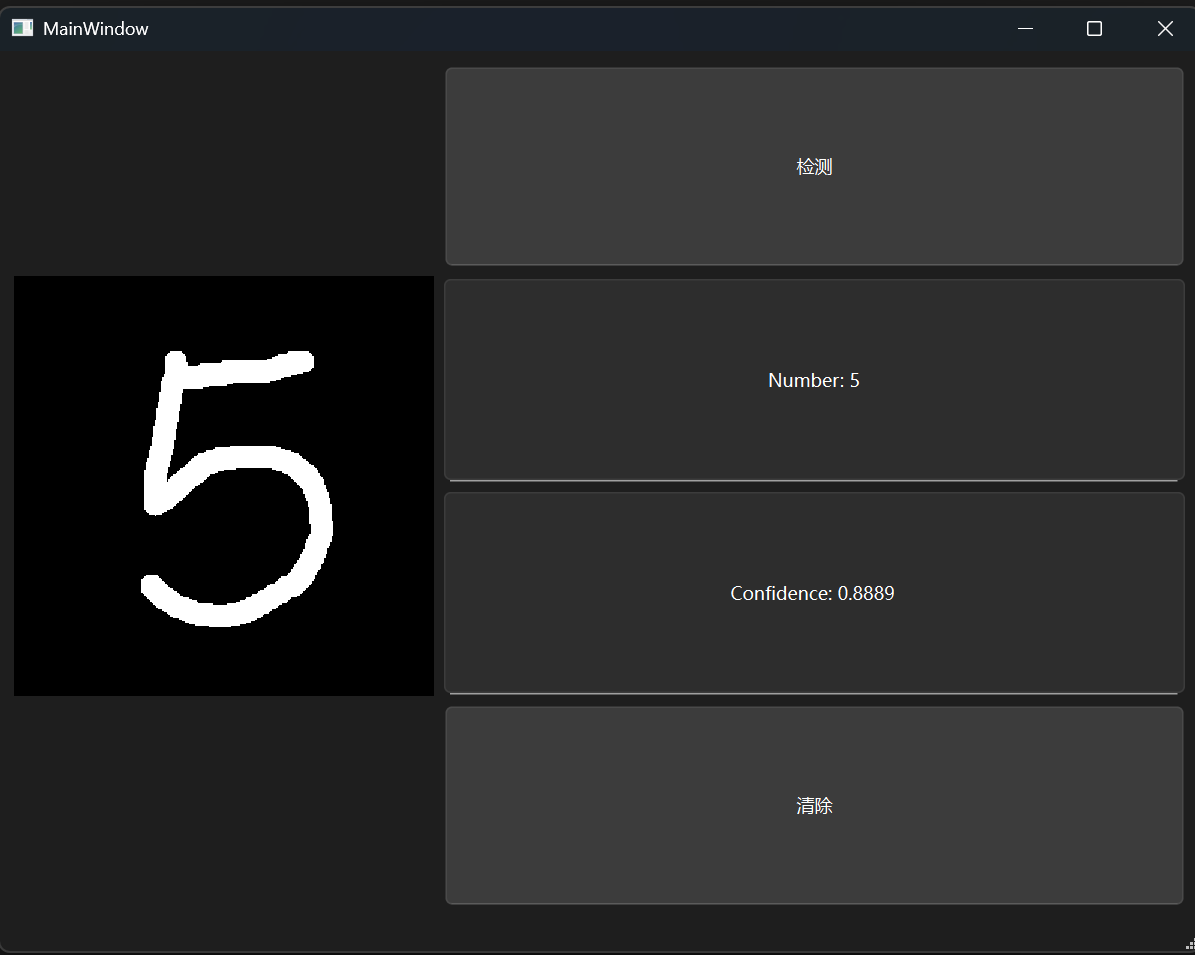
识别模型探索
其实目前用mlp练出来的模型在使用的过程中不太理想,所以我想多跑几个类型的模型看看效果
但是又不能每个网络都单独写一个完整的代码,所以我考虑做一个体系化的lab
于是我设计了一个LAB,项目结构如下:
MNIST_Lab
├─data
│ └─MNIST
├─engine
├─experiments
├─models
├─onnx
├─pth
└─utils
这个文件结构附加地让我对python的路径设置有了更深的认识:python对于“当前”路径的判定取决于,当前“运行”的路径
比如说,我再experiments下有个train.py访问了'../data',如果我在MNIST_Lab下运行:
python experiments/train.py
那这时候data的位置在MNIST_Lab的父文件夹
而如果我在MNIST_Lab/experiments下运行:
python train.py
这时候data的位置就在MNIST_Lab下了
所以我需要先定下一个规则:我只会在MNIST_Lab/experiments文件夹下运行文件
先把一些与模型无关的组件定义好:
models(工具)
在models下定义模型,放一个注册表registry.py方便后续访问
from .mlp import MLP
from .cnn import SimpleCNN
from .lenet5 import LeNet5
MODEL_REGISTRY = {
"mlp" : MLP,
"cnn" : SimpleCNN,
"lenet5" : LeNet5
}
def get_model(name : str):
if name not in MODEL_REGISTRY:
raise ValueError(f'Unknown model: {name}')
return MODEL_REGISTRY[name]()
为了统一字符串格式,我规定字符表名和模型对应名称.py都是全小写,而类可以有大写
这里还有一个小细节,返回模型返回的是模型实例T()而非T本身
engine
这里放的是训练和测试的组件
# engine/train.py
import torch
def train_epoch(dataloader, model, loss_fn, optimizer, device):
model.train()
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# engine/evaluate.py
import torch
def evaluate(dataloader, model, loss_fn, device):
model.eval()
correct, loss_sum = 0, 0.0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss_sum += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).sum().item()
return {
"accuracy": correct / len(dataloader.dataset),
"loss": loss_sum / len(dataloader)
}
为了开包即用,我尽量对大多数变量做了参数化,后面在主程序就可以放心调用了
在evaluate.py中我犯了点错误,lost这个平均值不小心多除了一次,导致lost看起来很夸张,代码审计还是得注意一点……
utils
这是一个通用零件库,我这里放了保存模型和导出ONNX的代码
依旧记住我的原则:只在experiments/下运行
# utils/save_pth.py
from pathlib import Path
import torch
# 在experiments/ 下运行
PTH_DIR = Path('../pth')
PTH_DIR.mkdir(exist_ok = True)
def save_pth(model, name: str):
path = PTH_DIR / f'{name}.pth'
torch.save(model.state_dict(), path)
return path
导出ONNX的部分与先前的大差不差,要注意的是dynamo要关掉才能保证适用OpenCV,而且动态维度其实是暂时没有必要性的,因为目前的手写识别只会接受一个样本
# utils/export_onnx.py
from pathlib import Path
import torch
ONNX_DIR = Path("../onnx")
ONNX_DIR.mkdir(exist_ok=True)
def export_onnx(
model,
name: str,
input_shape=(1, 1, 28, 28),
opset=11
):
model.eval()
dummy = torch.randn(*input_shape)
path = ONNX_DIR / f"{name}.onnx"
torch.onnx.export(
model,
dummy,
path,
dynamo = False,
opset_version=opset,
input_names=["input"],
output_names=["logits"],
)
return path
experiments
在这里就是主要的运行代码,对于路径处理先有一个加入工作目录
import sys
sys.path.append('../')
完整代码中尽量解耦不同的组件,留出可以修改的部分
# experiments/train.py
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision import transforms
import sys
sys.path.append(r'../')
from models.registry import get_model
from engine.train import train_epoch
from engine.evaluate import evaluate
device = 'cpu'
# 在MNIST_LAB下运行
transform = transforms.ToTensor()
train_ds = MNIST('../data', train = True, download = True, transform = transform)
test_ds = MNIST('../data', train = False, download = True, transform = transform)
train_loader = DataLoader(train_ds, batch_size = 64, shuffle = True)
test_loader = DataLoader(test_ds, batch_size = 64)
modelType = 'mlp'
model = get_model(modelType).to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr = 0.0049)
for epoch in range(50):
train_epoch(train_loader, model, loss_fn, optimizer, device)
metrics = evaluate(test_loader, model, loss_fn, device)
print(epoch + 1, metrics)
from utils.save_pth import save_pth
from utils.export_onnx import export_onnx
outputName = "mlp"
save_pth(model, outputName)
export_onnx(model, outputName)
models(模型)
当下的工作任务是横向对比不同的模型,所以我先控制下变量:
- loss:交叉熵损失
- optimizer:SGD
- lr:0.0049【宇宙终极答案,其实是因为MNIST不需要太小的学习率】
- epochs:50
接着不同的模型就是定义不同的结构,都是继承于nn.Module的
MLP:
MLP的构造前面已经介绍过了,这里再细究一下
MLP的全称是Multilayer Perceptron,多层感知机
其在MNIST的过程是把数据压平,然后通过全连接层和非线性函数进行复合构造网络
全连接层是线性的,非线性函数用来引入非线性的性质
目前用ReLU()是因为更通用,后续可以修改
CNN(简单):
CNN的观念是局部特征常常比整体特征更有意义
于是CNN引入了三件事:
- 局部连接(卷积核)
- 权重共享
- 逐步扩大感受野(即处理的范围)
先给出代码:
# models/cnn.py
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 32, 3, 1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, 1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 5 * 5, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.features(x)
return self.classifier(x)
在我的代码结构中,抽象出来就是:
self.features = nn.Sequential(
Conv -> ReLU -> Pool
Conv -> ReLU -> Pool
)
self.classifier = nn.Sequential(
Flatten -> Linear -> ReLU -> Linear
)
第一层Conv2d参数是Conv2d(1, 32, 3, 1),有32个滤波器,可以认为是一个3×3的滑动窗口在28×28的图像上计算,这可以用来观察一些局部结构,如4的弯折,8的弧度
接着是ReLU()非线性处理
最后是MaxPool2d()对于每个2×2区域取最大值
第二层就不是个局部特征观察了,而是前一层抽象出了个概要图,做同样的操作提取出更抽象的特征
关于参数的计算也需要细究一下:
- 3×3的滑动窗口,下标从0开始,所以输出是(N, 32, 26 = 28-3+1, 26)
- 提取2×2区域,输出为(N, 32, 13=26/2, 13)
- 再是3×3滑动窗口,输出为(N, 32, 11 = 13-3+1, 11)
- 卷积给了64个输出通道,最后输出为(N, 64, 5=11/2, 5)
所以在classifier中才是Linear(64 * 5 * 5, 128)
classifier在提取完数据之后再做了一个小的MLP,用于分类任务
LeNet-5:
LeNet-5是一种更加完全版本的CNN
# models/lenet5.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet5(nn.Module):
def __init__(self, num_classes = 10):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size = 5)
self.conv2 = nn.Conv2d(6, 16, kernel_size = 5)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, num_classes)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.avg_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.avg_pool2d(x, 2)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
相比于CNN有以下的不同点:
- 卷积核从3×3变成5×5
- 从最大池化变为平均池化,更强调整体效应
- 通道数较少
其实这个网络比较久远,所以一些思维跟现今的模型设计有些不同
结果展示
-
MLP:
50 {'accuracy': 0.9652, 'loss': 0.11397983232041477} -
CNN:
50 {'accuracy': 0.9882, 'loss': 0.03712443070957781} -
LeNet5:
50 {'accuracy': 0.9812, 'loss': 0.05748969653345479}
手写板算法优化
getNormalized算法优化
其实测试率不理想除了模型问题外,还有我的getNormalizedSize函数的实现问题
在当前的实现中,我粗暴地将280×280的画布缩放到28×28,一方面直接缩放可能导致信息畸变,另一方面,如果用户没有居中书写,那么结果也会大相径庭
所以接下来考虑将QImage转化为cv::Mat来处理
处理的主线就是让图片尽量符合MNIST的数字格式
首先将画布的QImage深拷贝下来
cv::Mat img(canvas.height(), canvas.width(), CV_8UC1,
const_cast<uchar*>(canvas.bits()),
canvas.bytesPerLine());
img = img.clone();
然后进行二值化,用来适应MNIST风格
cv::threshold(img, img, 10, 255, cv::THRESH_BINARY);
再通过找到所有白色的点位来确定整个数字的位置,用一个bbox把数字框起来,这样如果用户输入不居中也能正常识别了
std::vector<cv::Point> points;
cv::findNonZero(img, points);
cv::Rect bbox = cv::boundingRect(points);
cv::Mat digit = img(bbox);
接下来就把img缩放到20×20,因为事实上28×28还包含了背景留白,MNIST的数字本身占到约20×20
下一步回到28×28
cv::resize(digit, resized, cv::Size(20, 20), 0, 0, cv::INTER_AREA);
cv::Mat padded = cv::Mat::zeros(28, 28, CV_32F);
接着转化成float再归一化
cv::Mat resized_f;
resized.convertTo(resized_f, CV_32F, 1. / 255.);
resized_f.copyTo(padded(cv::Rect(4, 4, 20, 20))); // 居中拷贝
计算之前进行轻微的高斯模糊也可以模仿MNIST的风格
cv::GaussianBlur(padded, padded, cv::Size(3, 3), 0.5);
最后就是拉平计算,下面是完整代码
std::vector<float> DrawBoard::getNormalizedSize() const {
// 用cv::Mat处理数据
cv::Mat img(canvas.height(), canvas.width(), CV_8UC1,
const_cast<uchar*>(canvas.bits()),
canvas.bytesPerLine());
// 防止浅拷贝
img = img.clone();
// 二值化
cv::threshold(img, img, 10, 255, cv::THRESH_BINARY);
// 查看前景区域
std::vector<cv::Point> points;
cv::findNonZero(img, points);
if (points.empty()) return std::vector<float>(28 * 28, 0.f);
cv::Rect bbox = cv::boundingRect(points);
cv::Mat digit = img(bbox);
// 缩放到 20×20
cv::Mat resized;
cv::resize(digit, resized, cv::Size(20, 20), 0, 0, cv::INTER_AREA);
// 居中填充到 28×28
cv::Mat padded = cv::Mat::zeros(28, 28, CV_32F);
cv::Mat resized_f;
resized.convertTo(resized_f, CV_32F, 1. / 255.);
resized_f.copyTo(padded(cv::Rect(4, 4, 20, 20)));
// 高斯模糊:模仿MNIST
cv::GaussianBlur(padded, padded, cv::Size(3, 3), 0.5);
std::vector<float> data(28 * 28);
for (int y = 0; y < 28; y++) {
for (int x = 0; x < 28; x++) {
data[y * 28 + x] = padded.at<float>(y, x);
}
}
return data;
}
做完之后看看十个数码的效果

显示resize后结果
我一开始没有注意到手写板转化算法的问题其实是因为我下意识地将这个过程当作黑盒了
但其实这个处理后的结果是可以可视化的
用一个QLabel放在指定的位置,可以输出位图,这样就不需要新增对象类型了,代码如下:
cv::Mat mat28(28, 28, CV_32F, data.data());
cv::Mat mat28_copy = mat28.clone();
cv::Mat img8u;
mat28_copy.convertTo(img8u, CV_8UC1, 255.);
QImage img(img8u.data, 28, 28, img8u.step,
QImage::Format_Grayscale8);
QPixmap pix = QPixmap::fromImage(img)
.scaled(ui->labelPix->size(),
Qt::KeepAspectRatio,
Qt::FastTransformation);
ui->labelPix->setPixmap(pix);
原本的策略也可以照着写,现在就可以清晰看出两种算法的差异所在了
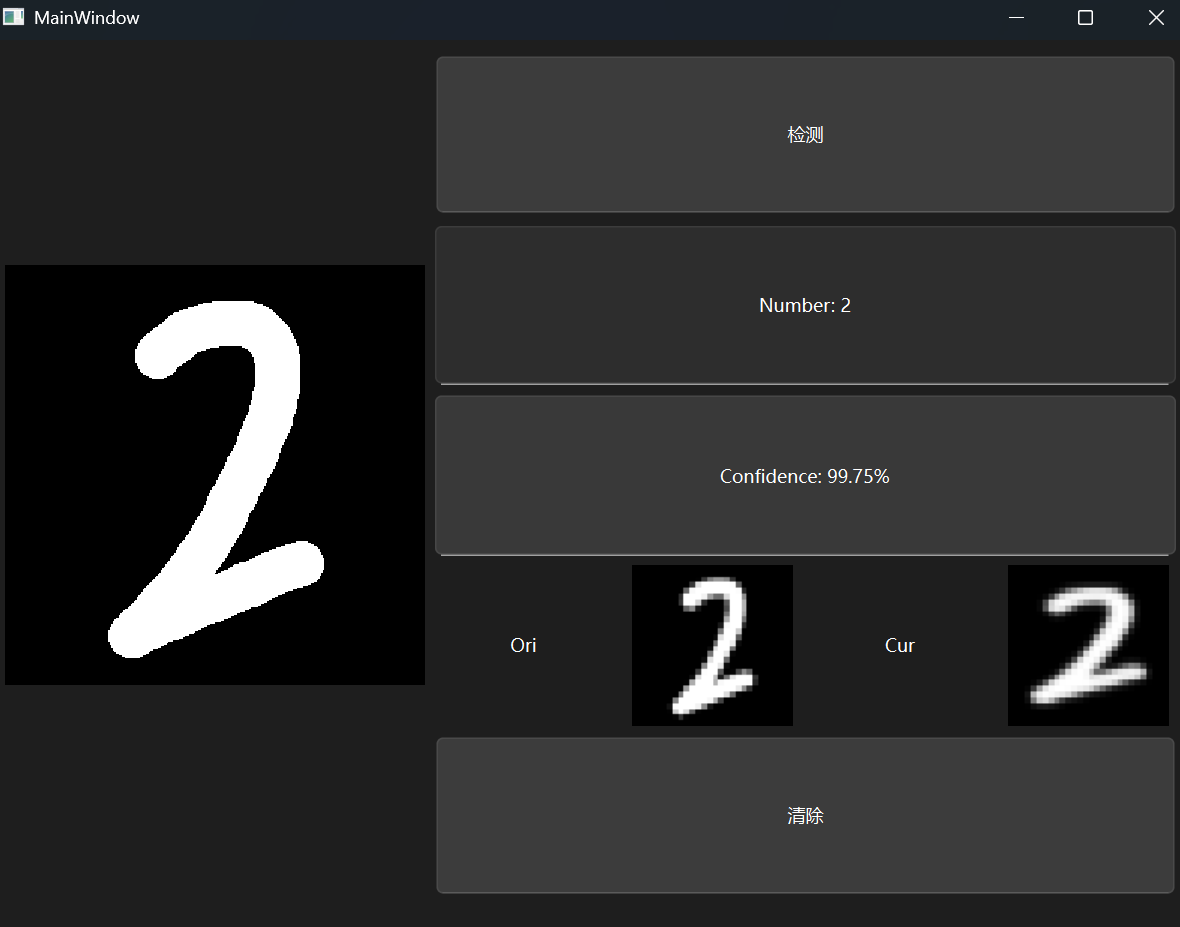
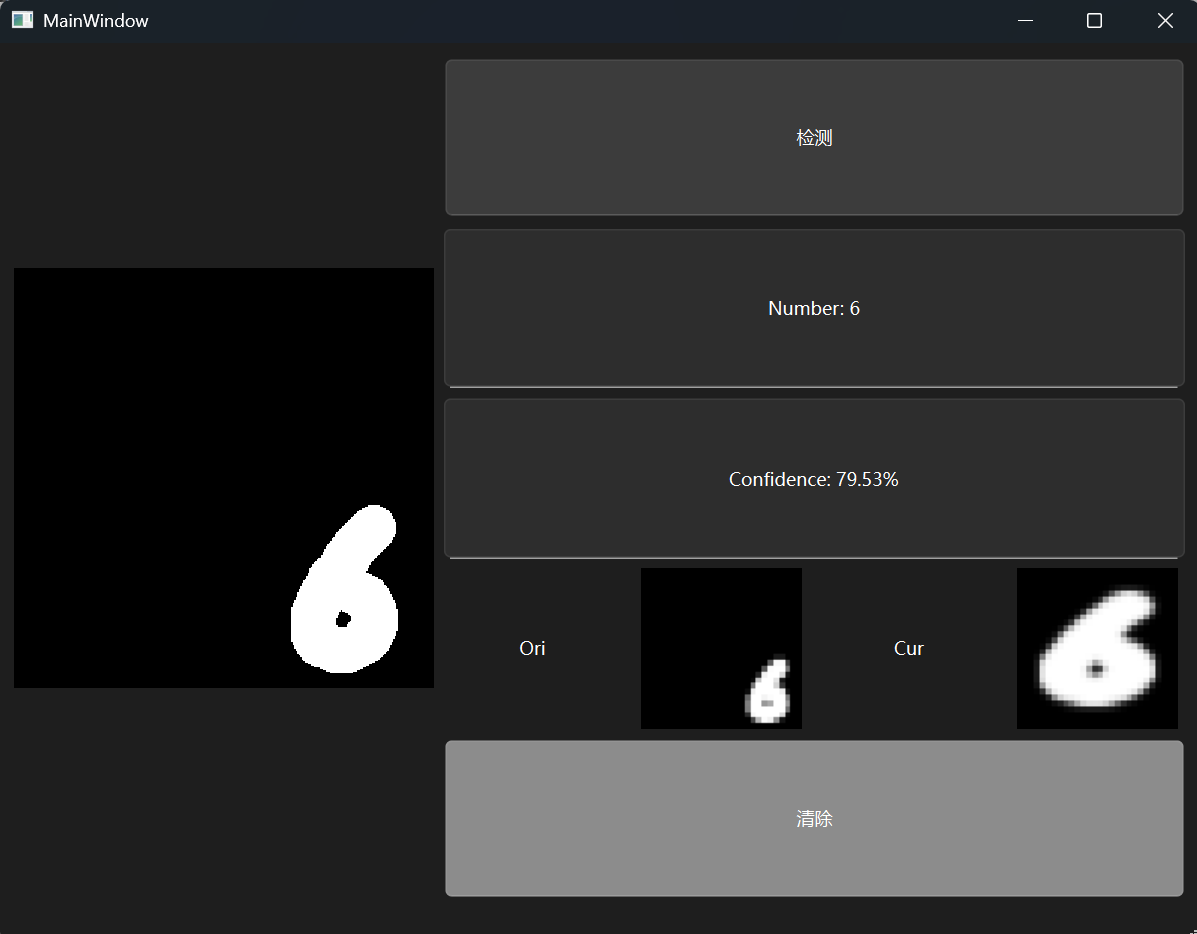
上面这个算法其实依旧有问题,最明显的问题是数字1在经过这个操作之后,白色会布满屏幕导致结果失真
下面是更加贴合数据集的做法:
std::vector<float> DrawBoard::getNormalizedSize() const {
/** 省略 **/
// === 4. 等比例缩放,使最长边 = 20 ===
int w = digit.cols;
int h = digit.rows;
int new_w, new_h;
if (w > h) {
new_w = 20;
new_h = static_cast<int>(h * 20.0 / w);
} else {
new_h = 20;
new_w = static_cast<int>(w * 20.0 / h);
}
/** 省略 **/
}
主要区别在于缩放时的数据,应当采用等比缩放,固定一个更长边是20,另外一边等比变化
其实还要加上一步质心对齐才更贴合原数据集,但是视觉效果反而没那么好,所以就不用了
UI思维强化
在做计算器的项目时我就发现只有一个mainwindow.ui的话,stacked widget里面的不同页面变量可能会冲突,而且检查起来会比较困难
针对这个问题,其实是要适当地将一些常用的或较大型的组件当作一个完整的ui来做,有.ui/.h/.cpp全套工具链,这样在调试和组装的时候才更加容易
其中涉及了“提升为”功能。我把此前做的功能做成一个单独的debug widget,接着在main window里面采用stacked widget,其中一页就可以放进一整个widget,然后提升为debug widget。这样组件化设计会方便后面的开发
在此基础上,main window加上一个导航栏,用户体验就会更好一些
拓展功能1:逐笔画识别
在这里多了一个Qt必要技能:自己写signals和slots
我的设计思路就是当笔画移动时,传出信号,接收到信号后实时预测
可以发现这个功能用到connect函数即可,这时候问题就在于如何写signals和slots
重点:代码中要标明signals和slots才能被识别,例如:
signals:
void func1();
private slots:
void func2();
我一开始没注意到这个问题,报错没看懂,弄了好久才明白
信号函数简单,只要在笔画移动的最后给出就行了
void DrawBoard::mouseMoveEvent(QMouseEvent *e) {
/** 省略 **/
emit mouseMoved(lastPos, e->pos());
}
emit关键字其实是Qt的一个有语义但无功能的语法宏,它建议在发射信号的时候给出标识
信号槽函数的逻辑和先前的检测逻辑一致:
connect(ui->Board, &DrawBoard::mouseMoved, this, &RealtimeWidget::on_mouse_moved);
由于是个动态的过程,因而可以考察过程中softmax数组发生了什么变化,因而可以做一个柱状图跟踪过程
这里用到了QChartView类,这不在Qt的默认组件里面,首先要在CMakeLists.txt里面加上
find_package(Qt6 REQUIRED COMPONENTS Charts)
然后就写一个ChartWidget类,接收一个cv::Mat(其实是一个数组),显示高度关系
ChartWidget::ChartWidget(QWidget *parent)
: QWidget(parent),
ui(new Ui::ChartWidget)
{
ui->setupUi(this);
chart = new QChart();
chart->setTitle("Digit Probability");
series = new QBarSeries();
set = new QBarSet("probability");
// 初始化10个柱子
for (int i = 0; i < 10; i++)
*set << 0;
series->append(set);
chart->addSeries(series);
// X轴
axisX = new QBarCategoryAxis();
QStringList categories;
for (int i = 0; i < 10; i++)
categories << QString::number(i);
axisX->append(categories);
chart->addAxis(axisX, Qt::AlignBottom);
series->attachAxis(axisX);
// Y轴
QValueAxis *axisY = new QValueAxis();
axisY->setRange(0, 1);
axisY->setTitleText("Probability");
chart->addAxis(axisY, Qt::AlignLeft);
series->attachAxis(axisY);
ui->chartView->setChart(chart);
ui->chartView->setRenderHint(QPainter::Antialiasing);
}
每次读入一次都更新一次,把每个柱子移动走再填上新数据就行了
void ChartWidget::updateProb(const cv::Mat &prob) {
if (prob.empty())
return;
set->remove(0, set->count());
for (int i = 0; i < prob.cols; i++) {
float p = prob.at<float>(0, i);
*set << p;
}
}
其实还有一个每次读入都sort一遍的版本,但是默认的视觉不太好看
void ChartWidget::updateSortedProb(const cv::Mat &prob) {
QVector<digitProb> data;
for (int i = 0; i < prob.cols; i++) {
data.push_back({i, prob.at<float>(0, i)});
}
std::sort(data.begin(), data.end(), [](const digitProb &x, const digitProb &y) {
return x.prob > y.prob;
});
set->remove(0, set->count());
QStringList categories;
for (auto dat : data) {
*set << dat.prob;
categories << QString::number(dat.digit);
}
axisX->clear();
axisX->append(categories);
}
其中digitProb结构体是为了方便保留数字信息
struct digitProb {
int digit;
float prob;
};

拓展功能2:客制化界面
模型选择
这个好说,就是把Combo Box的内容映射到模型的路径
DrawBoard::DrawBoard(QWidget *parent, int width, int height) : QWidget(parent) {
/** 省略 **/
model = {
{"MLP", "mlp.onnx"},
{"SimpleCNN", "cnn.onnx"},
{"LeNet-5", "lenet5.onnx"},
{"ResNet", "resnet.onnx"}
};
net = cv::dnn::readNetFromONNX("models/resnet.onnx");
}
DrawBoard自己给出一个修改模型的接口
void DrawBoard::setModel(QString modelName) {
std::string path = "models/" + model[modelName].toStdString();
net = cv::dnn::readNetFromONNX(path);
}
本来我是想把model放进source文件的,但是这样做似乎build时间太长了,所以就干脆放在release文件夹里面
画笔大小
这个也不难,Qt自带一个QSlider,使用这个就好了
想要带刻度的话,就在tickPosition选择TicksBelow就行
画笔与背景颜色
这个功能会引起一系列的连锁反应
首先对于DrawBoard类,要加上penColor和backgroundColor的成员变量
值得注意的是颜色变量应该用QColor,我一开始直接用Qt::black对应的Qt::GlobalColor导致可用的颜色选项并不多,用QColor也可以让Qt::GlobalColor顺利赋值
其次要加上penColor和backgroundColor的setter
由于画布颜色和画笔颜色的界面高度一致,所以我单独设计了一个colorChoiceWidget类
这个类里面包含了一个标识“画笔颜色/画布颜色”的label和一个Combo Box
Combo Box的选项可以是[Icon text],然后暗含颜色数据
初始化函数如下
QIcon makeColorIcon(const QColor& color) {
QPixmap pix(16, 16);
pix.fill(Qt::transparent);
QPainter p(&pix);
p.setBrush(color);
p.setPen(Qt::black);
p.drawRect(0, 0, 15, 15);
return QIcon(pix);
}
void initColorCombo(QComboBox* box) {
box->addItem(makeColorIcon(Qt::black), "Black", QColor(Qt::black));
box->addItem(makeColorIcon(QColor(255,107,107)), "Red", QColor(255,107,107));
box->addItem(makeColorIcon(QColor(77,163,255)), "Blue", QColor(77,163,255));
box->addItem(makeColorIcon(QColor(76,217,100)), "Green", QColor(76,217,100));
box->addItem(makeColorIcon(Qt::white), "White", QColor(Qt::white));
}
这样接下来又会有一个小问题,就是colorChoiceWidget这个类内部的信息不能公开外泄,所以颜色改变时需要自主发出signal,所以要自己写一个colorChanged信号
colorChoiceWidget::colorChoiceWidget(QWidget *parent)
: QWidget(parent)
, ui(new Ui::colorChoiceWidget) {
ui->setupUi(this);
initColorCombo(ui->comboBox);
setAttribute(Qt::WA_StyledBackground, true); // 保证能够被渲染
connect(ui->comboBox, &QComboBox::currentIndexChanged, this, [this](int index) {
QColor color = ui->comboBox->itemData(index).value<QColor>();
emit colorChanged(color);
});
}
这样的话槽函数的参数就能用到了(回收前文伏笔)
connect(ui->colorBackground, &colorChoiceWidget::colorChanged, this, [this](const QColor& color) {
ui->Board->setBackgroundColor(color);
ui->editConf->clear();
ui->editPred->clear();
ui->Board->clear();
ui->labelPix->clear();
});
橡皮擦
有笔当然就有橡皮擦配对,这里解锁了按钮的另一个功能
将按钮设置为checkable,可以让按钮在两种状态之间切换,在这里就是可以切换橡皮和画笔模式
ui->btnEraser->setCheckable(true);
ui->btnEraser->setIconSize(QSize(22, 22));
ui->btnEraser->setFixedHeight(36);
ui->btnEraser->setIcon(QIcon(":/icons/pencil.svg"));
ui->btnEraser->setText("画笔");
connect(ui->btnEraser, &QPushButton::toggled, this, [this](bool checked) {
if (checked) {
ui->btnEraser->setIcon(QIcon(":/icons/eraser.svg"));
ui->btnEraser->setText("橡皮");
ui->Board->toEraser();
} else {
ui->btnEraser->setIcon(QIcon(":/icons/pencil.svg"));
ui->btnEraser->setText("画笔");
ui->Board->fromEraser();
}
});
关于toEraser和fromEraser的实现,这里用了一个枚举类来实现
enum DrawMode {
PEN,
ERASER
} mode;
这两个函数只要让DrawMode改变就行,然后画画的时候根据mode去决定用penColor还是backgroundColor
最后是画笔/画布颜色改变带来的predict方式改变
原先的白画笔黑画布模式理应能兼容新方式,所以就只设计好新方式即可
这里由于只有两种颜色,那直接把画笔对应颜色改成白色,画布对应颜色改成黑色,这样就不用考虑颜色相对亮度的问题了
std::vector<float> DrawBoard::getNormalizedSize() const {
// === 1. 将 QImage 转为 cv::Mat ===
QImage binary(canvas.width(), canvas.height(), QImage::Format_Grayscale8);
for (int y = 0; y < canvas.height(); ++y) {
const QRgb* src = reinterpret_cast<const QRgb*>(canvas.scanLine(y));
uchar* dst = binary.scanLine(y);
for (int x = 0; x < canvas.width(); ++x) {
QColor c(src[x]);
dst[x] = (c == penColor) ? 255 : 0;
}
}
cv::Mat img(binary.height(),
binary.width(),
CV_8UC1,
binary.bits(),
binary.bytesPerLine());
img = img.clone();
/*** 省略 ***/
}

拓展功能3:表达式识别
首先用yolov5训练了一个数字和加减乘除的目标检测模型,导出为onnx格式
接着在Qt C++实现一个YOLO_Detector类,构造函数如下
YOLO_Detector::YOLO_Detector(const std::string& model_path,
int input_height,
int input_width,
float conf_threshold,
float nms_threshold) {
net = cv::dnn::readNetFromONNX(model_path);
this->input_height = input_height;
this->input_width = input_width;
this->conf_threshold = conf_threshold;
this->nms_threshold = nms_threshold;
net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
num_ops = {
{0, "0"}, {1, "1"}, {2, "2"}, {3, "3"}, {4, "4"},
{5, "5"}, {6, "6"}, {7, "7"}, {8, "8"}, {9, "9"},
{10, "/"}, {11, "="}, {12, "-"}, {13, "*"}, {14, "+"}
};
}
其中需要注意opencv dnn中模型的输入需要与图片的输入完全一致,模型本身没有调整大小的能力
先给出主要pipeline的代码(除去大多数防御性编程)
std::vector<Detection> YOLO_Detector::detect(const cv::Mat& image) {
std::vector<Detection> result;
float scale = 1.0f;
int top = 0;
int left = 0;
cv::Mat blob = preprocess(image, scale, top, left);
std::vector<cv::Mat> outputs = infer(blob);
std::vector<int> class_ids;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
decode(outputs[0], class_ids, confidences, boxes);
std::vector<int> indices = applyNMS(boxes, confidences);
for (int idx : indices) {
if (idx < 0 || idx >= static_cast<int>(boxes.size())) {
continue;
}
const cv::Rect& box = boxes[idx];
float x1 = (static_cast<float>(box.x) - static_cast<float>(left)) / scale;
float y1 = (static_cast<float>(box.y) - static_cast<float>(top)) / scale;
float x2 = (static_cast<float>(box.x + box.width) - static_cast<float>(left)) / scale;
float y2 = (static_cast<float>(box.y + box.height) - static_cast<float>(top)) / scale;
cv::Rect mapped_box(static_cast<int>(std::round(x1)),
static_cast<int>(std::round(y1)),
static_cast<int>(std::round(x2 - x1)),
static_cast<int>(std::round(y2 - y1)));
int xx1 = std::max(0, mapped_box.x);
int yy1 = std::max(0, mapped_box.y);
int xx2 = std::min(image.cols, mapped_box.x + mapped_box.width);
int yy2 = std::min(image.rows, mapped_box.y + mapped_box.height);
int ww = xx2 - xx1;
int hh = yy2 - yy1;
Detection det;
det.class_id = class_ids[idx];
det.confidence = confidences[idx];
det.box = cv::Rect(xx1, yy1, ww, hh);
result.push_back(det);
}
return result;
}
首先做一个preprocess,先letterbox后做blobFromImage
接着对于blob做一个forward()操作,再去解码输出
然后通过NMS过滤重复的框体
最后坐标运算从letterbox空间回到原图空间,构造成映射框封装成Detection的vector
preprocess
cv::Mat YOLO_Detector::preprocess(const cv::Mat& image,
float& scale,
int& top,
int& left) {
cv::Mat padded = letterbox(image, scale, top, left);
if (padded.empty()) {
return cv::Mat();
}
return cv::dnn::blobFromImage(padded,
1.0 / 255.0,
cv::Size(input_width, input_height),
cv::Scalar(),
true,
false);
}
先做letterbox是为了防止暴力伸缩导致识别难度提升
cv::Mat YOLO_Detector::letterbox(const cv::Mat& image,
float& scale,
int& top,
int& left) {
if (image.empty()) {
scale = 1.0f;
top = 0;
left = 0;
return cv::Mat();
}
int src_width = image.cols;
int src_height = image.rows;
scale = std::min(static_cast<float>(input_width) / static_cast<float>(src_width),
static_cast<float>(input_height) / static_cast<float>(src_height));
int resized_width = static_cast<int>(std::round(src_width * scale));
int resized_height = static_cast<int>(std::round(src_height * scale));
cv::Mat resized;
cv::resize(image, resized, cv::Size(resized_width, resized_height));
int pad_width = input_width - resized_width;
int pad_height = input_height - resized_height;
left = pad_width / 2;
top = pad_height / 2;
int right = pad_width - left;
int bottom = pad_height - top;
cv::Mat padded;
cv::copyMakeBorder(resized,
padded,
top,
bottom,
left,
right,
cv::BORDER_CONSTANT,
cv::Scalar(114, 114, 114));
return padded;
}
infer与decode
infer就是做了一个前向推理
std::vector<cv::Mat> YOLO_Detector::infer(const cv::Mat& blob) {
net.setInput(blob);
std::vector<cv::Mat> outputs;
net.forward(outputs, net.getUnconnectedOutLayersNames());
return outputs;
}
YOLOv5给出的候选框结构如下
[cx, cy, w, h, obj, cls1, cls2, ..., clsN]
分别为中心点x、y,宽、高,objectness,后续类别分数
下面的代码就是根据这些内容进行判定,同时用一个经验的判别方式过滤无效框
void YOLO_Detector::decode(const cv::Mat& output,
std::vector<int>& class_ids,
std::vector<float>& confidences,
std::vector<cv::Rect>& boxes) {
class_ids.clear();
confidences.clear();
boxes.clear();
if (output.empty()) {
std::cout << "decode: output is empty" << std::endl;
return;
}
if (output.dims != 3) {
std::cout << "decode: unsupported dims = " << output.dims << std::endl;
return;
}
int rows = output.size[1];
int dimensions = output.size[2];
float* data = reinterpret_cast<float*>(output.data);
for (int i = 0; i < std::min(rows, 5); i++) {
data += dimensions;
}
data = reinterpret_cast<float*>(output.data);
int kept_with_obj = 0;
int kept_no_obj = 0;
for (int i = 0; i < rows; i++) {
float cx = data[0];
float cy = data[1];
float w = data[2];
float h = data[3];
// 无效框过滤
if (w <= 1.0f || h <= 1.0f) {
data += dimensions;
continue;
}
// objectness
float obj = data[4];
// 关键过滤(非常重要)
if (obj < 0.25f) {
data += dimensions;
continue;
}
int num_classes = dimensions - 5;
cv::Mat scores(1, num_classes, CV_32FC1, data + 5);
cv::Point class_id_point;
double max_class_score;
cv::minMaxLoc(scores, nullptr, &max_class_score, nullptr, &class_id_point);
float conf = obj * static_cast<float>(max_class_score);
if (conf > conf_threshold) {
int box_left = static_cast<int>(std::round(cx - w / 2.0f));
int box_top = static_cast<int>(std::round(cy - h / 2.0f));
int box_width = static_cast<int>(std::round(w));
int box_height = static_cast<int>(std::round(h));
boxes.emplace_back(box_left, box_top, box_width, box_height);
confidences.push_back(conf);
class_ids.push_back(class_id_point.x);
}
data += dimensions;
}
}
NMS
std::vector<int> YOLO_Detector::applyNMS(const std::vector<cv::Rect>& boxes,
const std::vector<float>& confidences) {
std::vector<int> indices;
if (boxes.empty() || confidences.empty()) {
return indices;
}
cv::dnn::NMSBoxes(boxes,
confidences,
conf_threshold,
nms_threshold,
indices);
return indices;
}
可以直接用dnn的接口做NMS(Non-Maximum Suppression,非极大值抑制),这可以保留分数最高的框,最大限度地防止重叠
表达式识别
最终目的是生成表达式,主要的思路是按照bbox的x坐标中心排序,在此基础上加上大量过滤措施
std::string YOLO_Detector::generateExpression(const cv::Mat& image) {
std::vector<Detection> detections = detect(image);
if (detections.empty()) {
return "";
}
const float expr_conf_threshold = 0.50f;
std::vector<Detection> valid;
valid.reserve(detections.size());
for (const auto& d : detections) {
if (d.confidence < expr_conf_threshold) {
continue;
}
if (d.box.width < 5 || d.box.height < 5) {
continue;
}
if (d.box.x >= image.cols || d.box.y >= image.rows) {
continue;
}
if (num_ops.find(d.class_id) == num_ops.end()) {
continue;
}
valid.push_back(d);
}
if (valid.empty()) {
return "";
}
// 只按 x 中心排序
std::sort(valid.begin(), valid.end(), [](const Detection& a, const Detection& b) {
int ax = a.box.x + a.box.width / 2;
int bx = b.box.x + b.box.width / 2;
return ax < bx;
});
// 用平均宽度估计“同一个字符重复框”的 x 阈值
float mean_width = 0.0f;
for (const auto& d : valid) {
mean_width += static_cast<float>(d.box.width);
}
mean_width /= static_cast<float>(valid.size());
int x_threshold = std::max(10, static_cast<int>(std::round(mean_width * 0.45f)));
std::vector<Detection> filtered;
filtered.reserve(valid.size());
for (const auto& det : valid) {
if (filtered.empty()) {
filtered.push_back(det);
continue;
}
Detection& last = filtered.back();
int x = det.box.x + det.box.width / 2;
int last_x = last.box.x + last.box.width / 2;
bool same_char = std::abs(x - last_x) < x_threshold;
if (same_char) {
if (det.confidence > last.confidence) {
last = det;
}
} else {
filtered.push_back(det);
}
}
// 再按 x 中心稳定排序一次
std::sort(filtered.begin(), filtered.end(), [](const Detection& a, const Detection& b) {
int ax = a.box.x + a.box.width / 2;
int bx = b.box.x + b.box.width / 2;
return ax < bx;
});
std::string result;
result.reserve(filtered.size());
for (const auto& det : filtered) {
result += num_ops[det.class_id];
}
return result;
}
到这之后,计算的环节就可以交给之前写出来的ExpressionValidator类了

附加内容
qss美化
一开始我意识到了如果不自己控制的话,深色模式和正常模式的ui不一样
我希望做一个统一的ui,在不同的环境下也能够有相同的视觉效果,从而学到了qss
其实qss是css的子集,所以按照css的思路去写就行了,只要不去写一些复杂的逻辑代码
其中涉及到了几种应用:
- 同一种类渲染
/* ===== LineEdit Bold Version ===== */
QLineEdit {
background-color: #1E2230;
border: 2px solid #3C4C7A;
border-radius: 14px;
padding: 8px 14px;
color: #EAF0FF;
font-size: 15px;
}
/* hover */
QLineEdit:hover {
border: 2px solid #6C8CFF;
}
/* focus 强调 */
QLineEdit:focus {
border: 2px solid #8F6BFF;
background-color: #24293A;
selection-background-color: #7F4DFF;
}
- 单一对象渲染
/* ===== 主按钮 ===== */
QPushButton#btnPred {
background: qlineargradient(
x1:0, y1:0, x2:1, y2:1,
stop:0 #5A6BFF,
stop:1 #7F4DFF
);
border: none;
border-radius: 18px;
padding: 12px 20px;
color: white;
font-weight: 500;
}
QPushButton#btnPred:hover {
background: qlineargradient(
x1:0, y1:0, x2:1, y2:1,
stop:0 #6D7DFF,
stop:1 #9A6BFF
);
}
QPushButton#btnPred:pressed {
background: #4C56CC;
}
- 类中成员
/* ComboBox 本体 */
colorChoiceWidget QComboBox {
background: transparent;
border: 1px solid #cfcdc4;
color: #e6eef7;
font-size: 14px;
padding-left: 6px;
padding-right: 24px; /* 给箭头留空间 */
}
colorChoiceWidget QComboBox::hover {
border: 1px solid #ffe23d;
}
除此之外,一些icon也可以用矢量图替换,比如Combo Box的箭头
colorChoiceWidget QComboBox::down-arrow {
image: url(:/icons/arrow_down.svg);
width: 20px;
height: 20px;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号