
目录
- AAAI 2021
- https://arxiv.org/pdf/1911.10244.pdf
- a seq of high-level objectives
- synthesis of compact automata, human-interpretable
- enrich the state space, discover structure
1 Introduction
- hard to solve: sparse, non-Markovian, long-term sequential
- ours: DeepSynth, infer unknown sequential dependencies, high-level objectives
- automata: interpretable
- off-the-shelf unsupervised image segmentation
4 Background on Automata Synthesis
- the algorithm used for automatic inference of unknown high-level sequential structures as automata
- input: a trace sequence. output: N-state automaton
- briefly: 1 to N, search, smallest conforming to...
- sliding window of \(w\) (hyperparam), only unique segments are processed, reduced the size (000 012 222 222 234 444 ...)
- hyperparam \(l\): length of negative examples. too small: accpets all. too long: NP hard
- fail: add to
5 DeepSynth
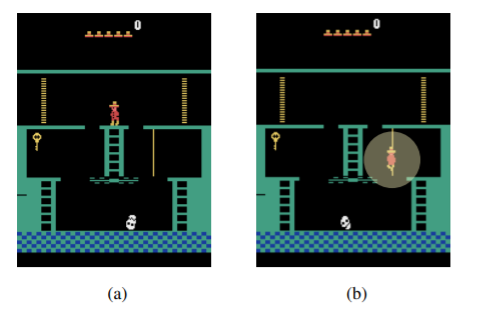
- other Atari: avoid, collect, no particular order. Montezuma's Revenge: long, complex sequence
- actually not a seq, shortcut!
![image]()
- actually not a seq, shortcut!
- the input image is segmented into enough objects whose correlation can guide the agent
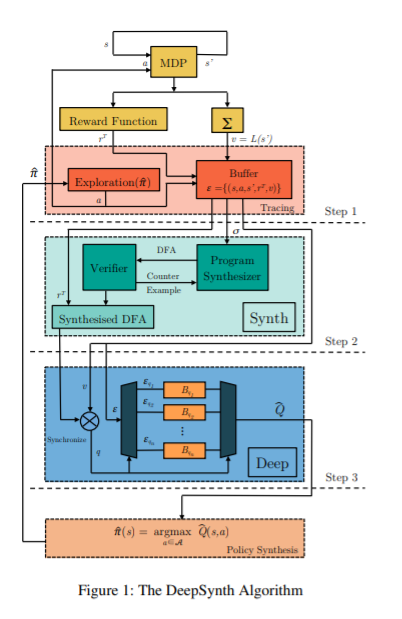
Step 1
- intrinsic reward \(r^T=\hat r +\mu r^i\), depends on the inferred automaton
- stack of four \(84*84*4\)
- transition tuple: additional \(L(s')\) to detect collision. empty or multiple: √
Step 2
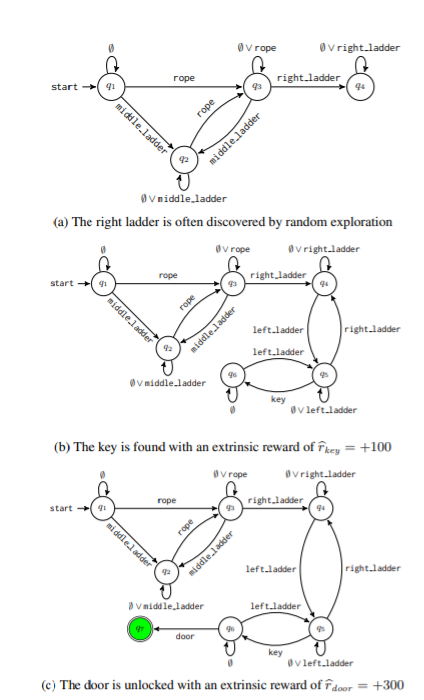
- an automaton comforms to the labels in the trace, label: a symbol of the alphabet
![image]()
Step 3
- new label, expand, reward
- much less than extrinsic reward
- invariant optimal policy and its proof
- product MDP, incorporate 2 MDPs (DFA is a trivial MDP)
- non-Markovianity is resloved where the DFA represents the history
- multiple NNs for multiple states
- interconnected (through Q-learning, "backwards")
- don't share weights, buffers, \(\epsilon\) for \(\epsilon-\)greedy
Appendix
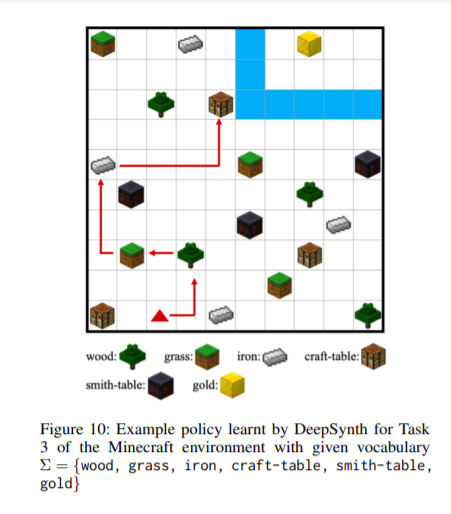
Discussion and Comments
- strong prior: "the state space of the DFA": what's the overlapping object?
- not general
- maybe a pioneer to this field.
