.net集成kafka使用小记
安装nuget包
Confluent.Kafka

创建主题
有三种方式,一种是在kafka-manager UI界面上创建,一种是在kafka-tool软件上创建,一种是通过代码创建。
- kafka-manager:
在kafka-manager界面上创建Cluster,并在该Cluster下创建Topic。
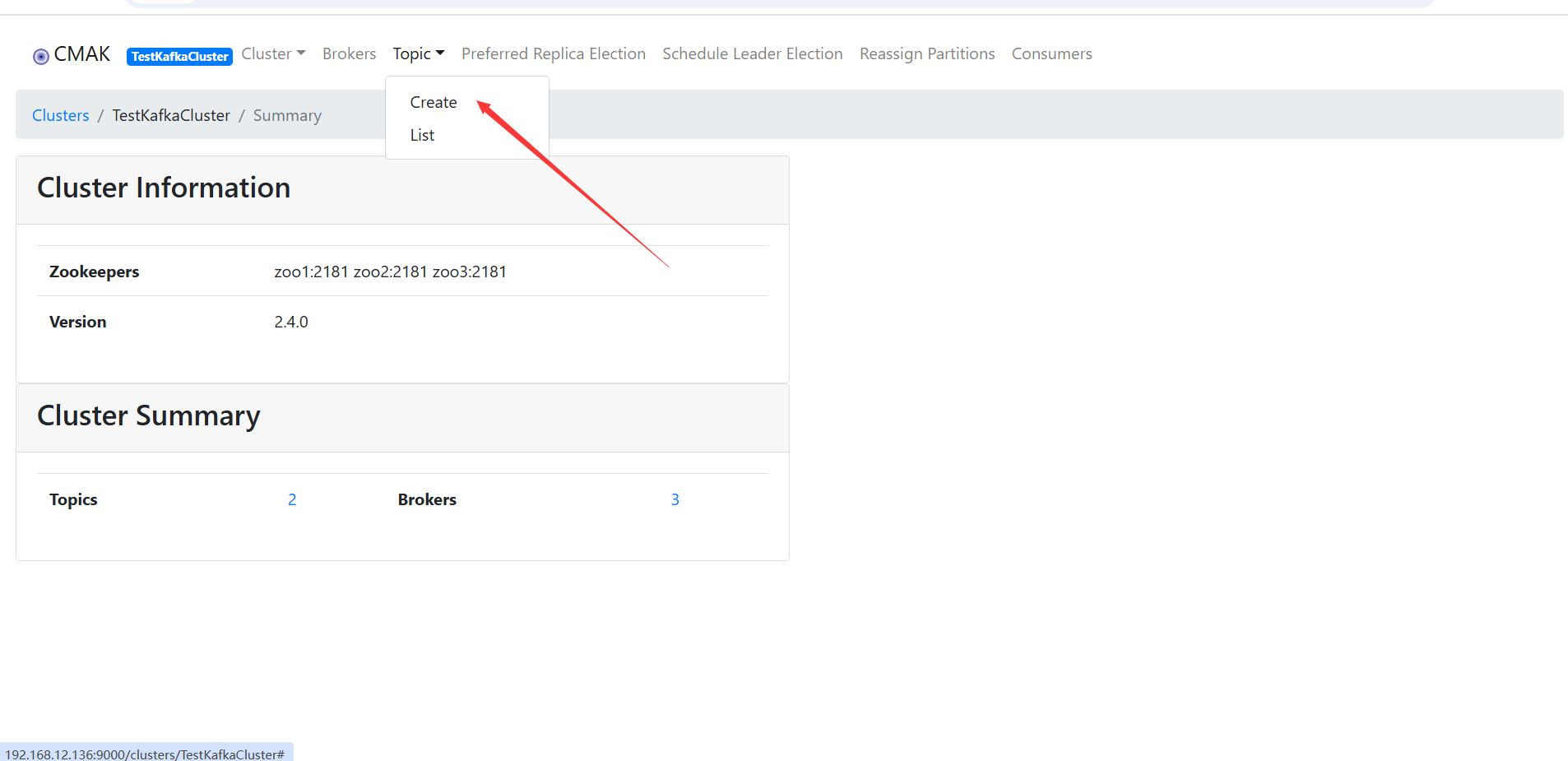
输入Topic和Partitions值,点击Create按钮。这里创建主题test,test包含3个分区。

- kafka-tool
鼠标右键Topics文件夹,点击“Create Topic”选项。
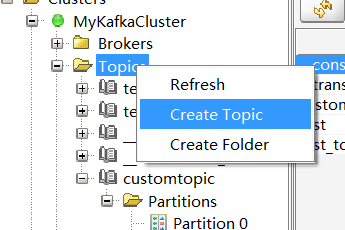
弹框张输入对应的主题名称、分区数量(可选,默认1)、副本因子(可选,默认1)即可,然后点击底部的Add按钮。


- 程序实现
Console.WriteLine("请输入待创建的Topic名称");
string topicName = Console.ReadLine();
await ConfluentKafka.CreateKafkaTopic(brokerList, topicName, 3, 1);
public static async Task CreateKafkaTopic(string bootstrapServers, string topicName, int numPartitions = 3, short replicationFactor = 1)
{
using (var adminClient = new AdminClientBuilder(new AdminClientConfig
{
BootstrapServers = bootstrapServers
}).Build())
{
try
{
// 创建主题配置
var newTopic = new TopicSpecification
{
Name = topicName,
NumPartitions = numPartitions,
ReplicationFactor = replicationFactor,
Configs = new Dictionary<string, string>
{
// 可添加其他主题配置参数
{ "cleanup.policy", "delete" },//当消息超过保留时间或大小,Kafka会物理删除旧数据。
{ "retention.ms", "7200000" } //消息在分区中保留的最大时间(毫秒)。保留2小时
}
};
// 创建主题
await adminClient.CreateTopicsAsync(new List<TopicSpecification> { newTopic });
Console.WriteLine($"成功创建主题: {topicName}");
}
catch (CreateTopicsException e)
{
// 处理主题已存在或其他错误
if (e.Results[0].Error.Code == ErrorCode.TopicAlreadyExists)
{
Console.WriteLine($"主题 {topicName} 已存在");
}
else
{
Console.WriteLine($"创建主题失败: {e.Results[0].Error.Reason}");
}
}
catch (Exception e)
{
Console.WriteLine($"发生错误: {e.Message}");
}
}
}

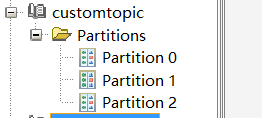
创建分区(扩容)
基于已有主题创建分区,只能扩容,不能和现有分区数量一致或更少。下面用代码来实现。
Console.WriteLine("请输入需要扩充后的分区数量");
string partitionCount = Console.ReadLine();
await ConfluentKafka.CreatePartitionsForExistingTopicAsync(brokerList, "customtopic", Convert.ToInt32(partitionCount));
/// <summary>
/// 创建分区
/// </summary>
/// <param name="bootstrapServers">集群地址</param>
/// <param name="topicName">主题名称</param>
/// <param name="targetPartitionCount">扩充后的分区数量</param>
/// <returns></returns>
public static async Task CreatePartitionsForExistingTopicAsync(string bootstrapServers, string topicName, int targetPartitionCount)
{
using (var adminClient = new AdminClientBuilder(new AdminClientConfig
{
BootstrapServers = bootstrapServers
}).Build())
{
try
{
// 创建分区
var partitionsSpecification = new PartitionsSpecification
{
Topic = topicName, //目标主题
IncreaseTo = targetPartitionCount //目标分区总数
};
await adminClient.CreatePartitionsAsync(new List<PartitionsSpecification> { partitionsSpecification });
Console.WriteLine($"主题 {topicName} 分区数已调整为 {targetPartitionCount}");
}
catch (CreatePartitionsException ex)
{
if (ex.Results[0].Error.Code == ErrorCode.InvalidPartitions)
{
Console.WriteLine($"错误:目标分区数 {targetPartitionCount} 必须大于当前分区数");
}
Console.WriteLine($"操作失败:{ex.Results[0].Error.Reason}");
throw;
}
catch (Exception ex)
{
Console.WriteLine($"操作失败:{ex.Message}");
throw;
}
}
}
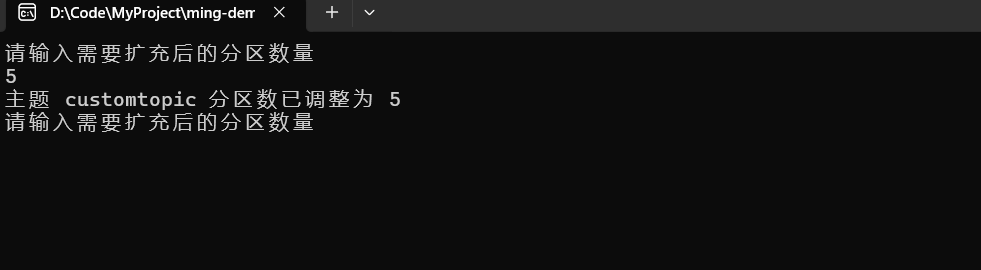
旧分区数量为3
调整后的分区数量为5
生产者发送消息到Kafka集群主题
创建了一个简单的 Kafka 生产者,它会从控制台持续读取用户输入的消息,然后将这些消息异步发送到 Kafka 集群的 "test" 主题中。
using KafkaServer;
while (1 == 1)
{
Console.WriteLine("请输入发送到Kafka的内容");
string message = Console.ReadLine();
string brokerList = "192.168.12.136:9092,192.168.12.137:9093,192.168.12.138:9094";
await ConfluentKafka.Produce(brokerList, "test", message);
}
public class ConfluentKafka
{
public static async Task Produce(string brokerlist, string topicname, string content)
{
ProducerConfig config = new ProducerConfig()
{
BootstrapServers = brokerlist,
Acks = Acks.All,
EnableIdempotence = true,
MessageSendMaxRetries = 3,
//LingerMs = 10
};
using (var producer = new ProducerBuilder<string, string>(config).Build())
{
Console.WriteLine("\n-----------------------------------------");
Console.WriteLine($"Producer {producer.Name} producing on topic {topicname}");
Console.WriteLine("-------------------------------------------");
try
{
var deliveryReport = await producer.ProduceAsync(topicname, new Message<string, string>
{
Key = new Random().Next(1, 10).ToString(),
Value = content
});
Console.WriteLine($"delivered to:{deliveryReport.TopicPartitionOffset}");
}
catch (ProduceException<string, string> ex)
{
Console.WriteLine($"failed to delivery message: {ex.Message} [{ex.Error.Code}]");
}
}
}
}

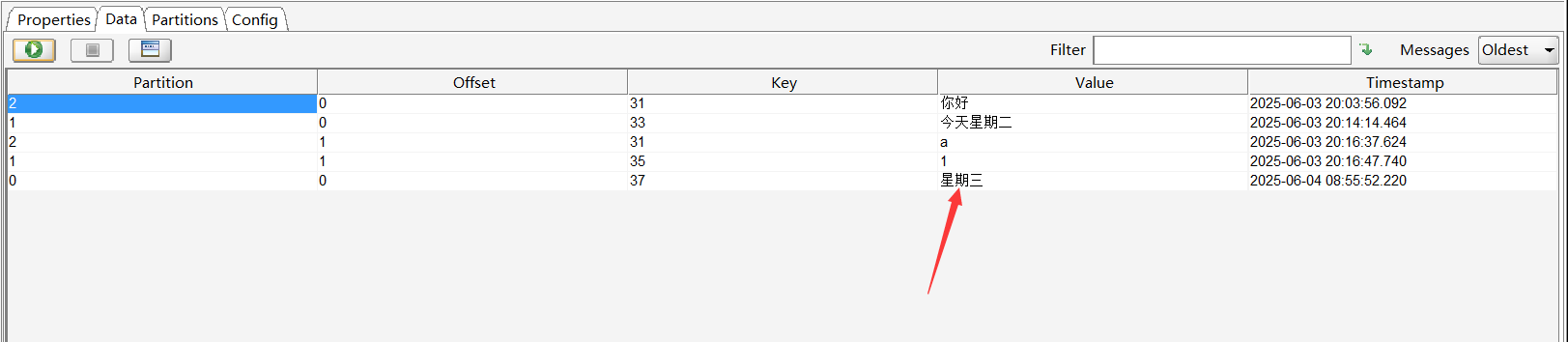
可以看到0分区已经收到值,打开kafka tool工具,选择对应Cluster下的Topic,点击右边区域的Data选项,点击绿色运行按钮,可以看到有1条结果,Value值就是程序发送的内容,默认情况下显示的是密文。

若要查看明文,需要切换到Properties选项,找到Content Types选项,将Value的值由Byte Array切换到String,然后点击Update按钮。

重新切换到Data选项,就能看到明文的内容了。
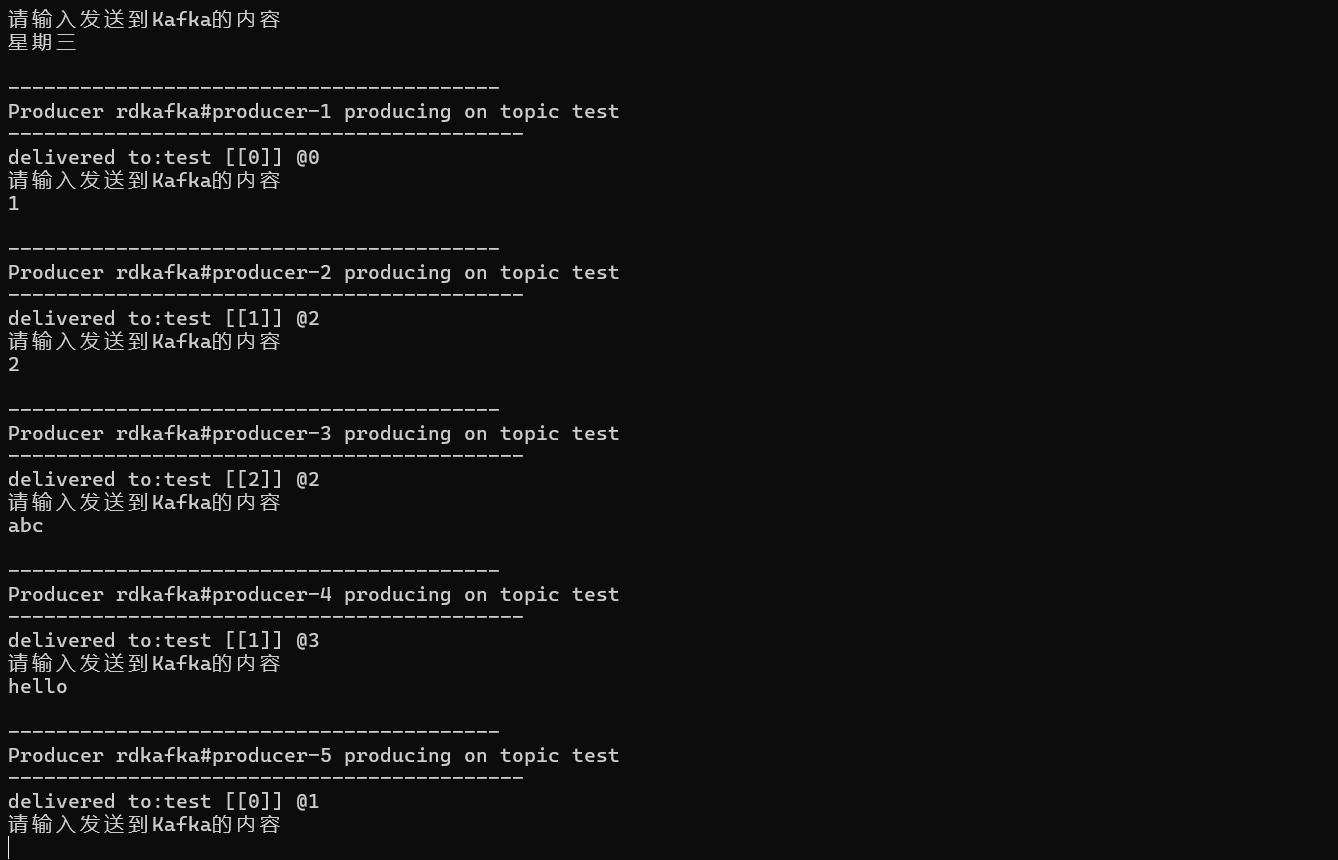
多发送些数据

基于Key的分区策略
如果一个主题内包含多个分区,生产者在发送消息时会根据Key来决定消息的分区。
- 如指定了Key,Kafka会通过哈希取模算法将不同Key的消息均匀分配到各个分区,避免数据倾斜。
- 如果不指定Key,消息会被随机分配到某个分区。
我们知道在Kafka中,同一个分区的内的消息是有序的,但是不同分区之间的消息顺序是无序的,若需要某些消息按顺序处理,可以将这些消息设置相同的Key,确保它们进入同一个分区。
// 生成1到100之间的随机数(范围扩大以增加随机性)
int randomNumber = new Random().Next(1, 101);
// 根据随机数对3取模的结果决定使用哪个Key
string key;
switch (randomNumber % 3)
{
case 0:
key = "AAA";
break;
case 1:
key = "AAB";
break;
case 2:
key = "AAC";
break;
default:
key = "AAA"; // 理论上不会执行到这里
break;
}
var deliveryReport = await producer.ProduceAsync(topicname, new Message<string, string>
{
Key = key,
Value = content
});

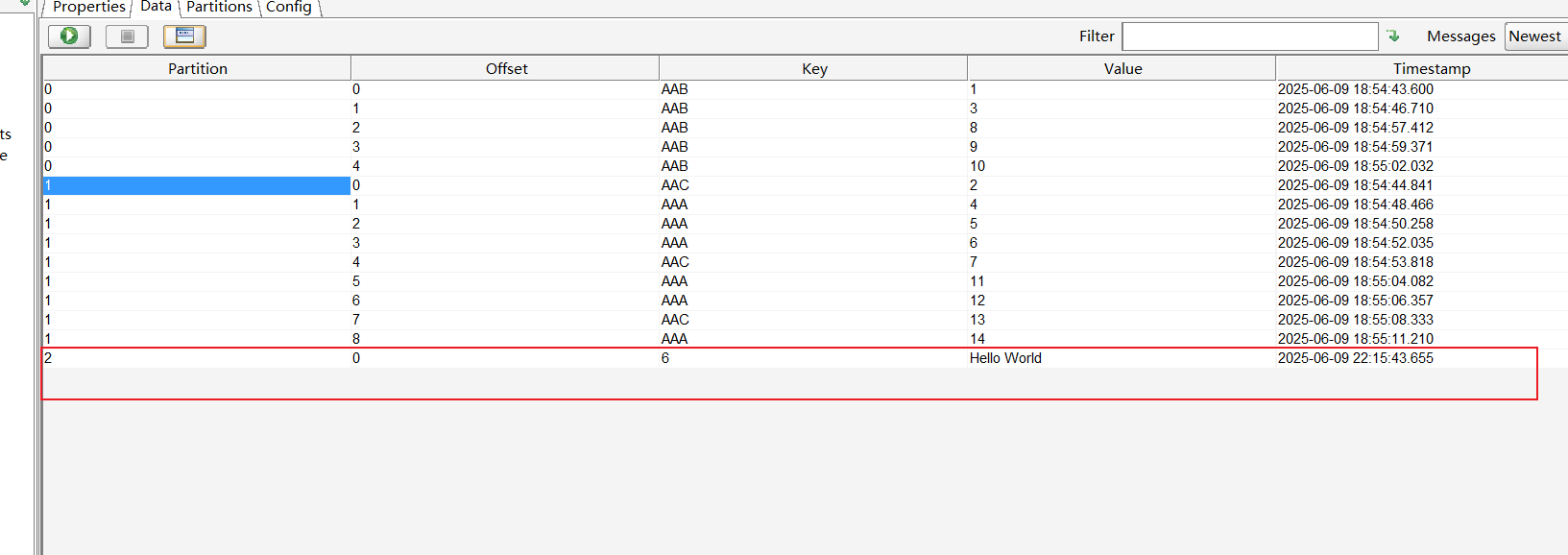
可以看到相同的Key是进入同一个分区的,这里出现AAA和AAC共用一个分区是由于 Murmur2 哈希算法导致的,虽然 AAA 和 AAC 是不同的 Key,但它们的 哈希值对 3 取模的结果恰好相同,因此被分配到同一个分区。这并不违反 "相同的 Key 进入同一个分区" 的原则,但不同的 Key 确实可能被分配到相同分区。
向指定分区发送消息
固定向分区2发送消息。
var deliveryReport = await producer.ProduceAsync(new TopicPartition(topicname,2), new Message<string, string>
{
Key = new Random().Next(1, 10).ToString(),
Value = content
});
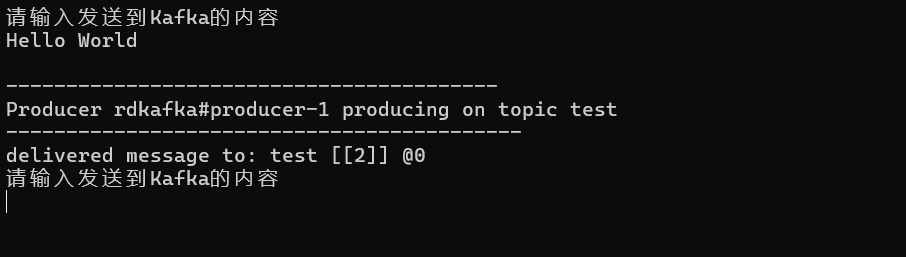
基于Key值动态指定分区发送消息
根据Key的内容动态决定发送给哪个分区,例如假设发送日志消息,日志来源有多个渠道,PC端、App端、微信小程序端,此时根据Key的值动态决定将日志的消息发送到哪个分区。
using (var producer = new ProducerBuilder<string, string>(config)
.SetPartitioner(topicname,(topic,partitionCount, keyData, keyIsNull) =>
{
if (!keyIsNull && keyData.Length > 0)
{
var key = Encoding.UTF8.GetString(keyData);
if (key.StartsWith("app"))
return 0;
if (key.StartsWith("weichat"))
return 1;
if (key.StartsWith("pc"))
return 2;
}
//key为空时默认分区为2
return new Partition(2);
}).Build())
{
Console.WriteLine("\n-----------------------------------------");
Console.WriteLine($"Producer {producer.Name} producing on topic {topicname}");
Console.WriteLine("-------------------------------------------");
try
{
var deliveryReport = await producer.ProduceAsync(topicname, new Message<string, string>
{
Key = "applog",
Value = content
});
Console.WriteLine($"delivered message to: {deliveryReport.TopicPartitionOffset}");
}
catch (ProduceException<string, string> ex)
{
Console.WriteLine($"failed to delivery message: {ex.Message} [{ex.Error.Code}]");
}
}
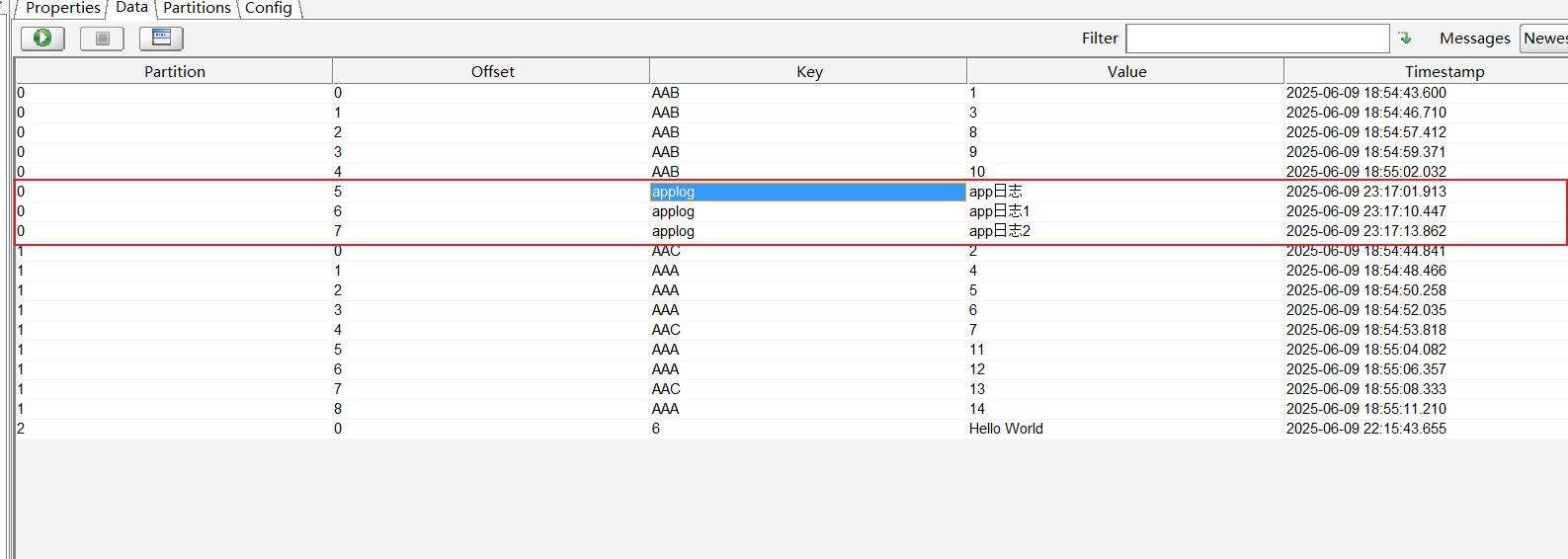
事务操作(批量发送)
public class KafkaTransaction
{
public static void TransactionSend()
{
string brokerList = "192.168.12.136:9092,192.168.12.137:9093,192.168.12.138:9094";
string topicName = "test";
string transactionalId = Guid.NewGuid().ToString("N");
ProducerConfig config = new ProducerConfig
{
//kafka集群地址
BootstrapServers = brokerList,
//启用幂等性
EnableIdempotence = true,
//所有ISR副本确认
Acks = Acks.All,
//事务Id
TransactionalId = transactionalId
};
using IProducer<string, string> producer = new ProducerBuilder<string, string>(config).Build();
try
{
//初始化事务,并指定超时时间
producer.InitTransactions(TimeSpan.FromSeconds(30));
//开始事务
producer.BeginTransaction();
//批量发送消息
for (int i = 100; i < 110; i++)
{
string content = i.ToString();
producer.Produce(topicName, new Message<string, string> { Key = content, Value = content });
}
//提交事务,并指定超时时间
producer.CommitTransaction(TimeSpan.FromSeconds(15));
}
catch (Exception ex)
{
//回滚事务,并指定超时时间
producer.AbortTransaction(TimeSpan.FromSeconds(10));
Console.WriteLine(ex.Message);
}
Console.WriteLine($"done:{transactionalId}");
}
}

ProducerConfig参数配置解析
- BootstrapServers:指定了 Kafka 代理服务器的列表。这里具体指定的是Kafka集群的地址,用于连接集群。
- Acks:决定了生产者在发送消息后需要等待多少个副本确认收到消息才认为发送成功,有3个配置选项。
- Acks.All:生产者会等待所有副本确认收到消息后才认为消息发送成功。
可靠性:可靠性高,只要ISR中至少有一个副本存活,就能保证消息不丢失。
性能:性能最低,因为需要等待所有副本确认,延迟最高。
适用场景:适用于对消息可靠性要求极高,且能接受低吞吐量的场景,如金融交易记录。
- Acks.None:生产者不等待任何确认,消息发送后立即认为发送成功。
性能:性能最高,没有等待确认的开销,吞吐量最大。
可靠性:可靠性最低,消息可能因网络问题或 broker 崩溃而丢失,且生产者不会知道。
适用场景:适用于对可靠性要求极低,且需要极高吞吐量的场景,如实时指标收集(允许少量数据丢失)。
- Acks.Leader:生产者只需要等待 leader 副本确认收到消息即可认为发送成功。
性能:性能中等。减少了等待 follower 副本的时间,延迟较低。
可靠性:可靠性中等。如果 leader 副本在确认后但 follower 副本同步前崩溃,消息可能丢失。
适用场景:适用于对可靠性有一定要求,但更注重性能的场景,如日志收集。
| 配置 | 可靠性 | 性能 | 幂等性支持 | 适用场景 |
|---|---|---|---|---|
| Acks.All | 最高(不丢失消息) | 最低(高延迟) | 支持 | 金融交易、关键业务数据 |
| Acks.Leader | 中等(leader 确认后可能丢失) | 中等 | 支持 | 日志收集、普通业务数据 |
| Acks.None | 最低(可能大量丢失) | 最高(低延迟) | 不支持 | 实时指标、允许少量丢失的监控数据 |
- EnableIdempotence:是否开启幂等性,开启则可避免因重试造成的消息重复问题。默认值为false,若设置值为true,则该配置与Acks = Acks.All固定搭配使用,这是因为幂等性生产者需要确保所有副本都成功接收消息,才能避免重试导致的重复。若Acks属性设置其它值,同时又配置此参数开启幂等性,Kafka 会自动将 Acks 强制设为 All。
注意:当 EnableIdempotence = true 时,Kafka 会强制将 Retries 设为 int.MaxValue,确保消息最终发送成功。
为什么开启后可以避免消息重复:因为生产者会为每条消息分配一个唯一的 ID,broke会对已经接收的消息进行缓存,从而拒绝重复的消息。
ProducerConfig config = new ProducerConfig()
{
Acks = Acks.All,(隐式强制)
Retries = int.MaxValue,(隐式强制)
EnableIdempotence = true
};
- MessageSendMaxRetries:设置消息发送失败后的最大重试次数。
- LingerMs:指定生产者在发送批次前等待的最大毫秒数。默认为0ms(立即发送),通过设置此参数可以实现批量发送提高吞吐量,减少网络开销。值越大,延迟越高,但吞吐量也越高。
| LingerMs | 延迟 | 吞吐量 | 适用场景 |
|---|---|---|---|
| 0ms | 最低(实时) | 最低 | 实时系统(如高频交易) |
| 10-100ms | 中等 | 中等 | 大多数业务系统(默认 5ms) |
| 100ms+ | 高 | 最高 | 批量处理系统(如日志聚合) |
- TransactionalId:事务Id,每个生产者的TransactionalId必须唯一,设置此参数后将启用Kafka生产者的事务功能。
适用场景:单主题多分区且要求有原子性(例如金融系统中同一账户的收支记录必须同时成功)、多主题多分区且要求有原子性(例如电商订单提交时,同时更新订单主题、库存主题、用户积分主题)
TransactionalId = Guid.NewGuid().ToString();
跨分区:在一个事务中向同一主题的多个分区发送消息。
// 向同一主题的不同分区发送消息(跨分区)
producer.BeginTransaction();
// 向分区 0 发送
producer.Produce(
topic: "sameTopic",
message: new Message<string, string> { Key = "key1", Value = "value1" },
partition: 0
);
// 向分区 1 发送
producer.Produce(
topic: "sameTopic",
message: new Message<string, string> { Key = "key2", Value = "value2" },
partition: 1
);
producer.CommitTransaction();
跨主题:在一个事务中向多个不同主题发送消息。
producer.Produce(topic1, new Message<string, string> { Key = "key1", Value = "value1" });
producer.Produce(topic2, new Message<string, string> { Key = "key2", Value = "value2" });
注意:当设置该值后,以下属性也需要配置,否则可能会出错:
EnableIdempotence = true;//启用生产者的幂等性,确保重试时不会重复发送消息。
Acks = Acks.All; //确保所有副本都确认收到消息后才认为发送成功(当 EnableIdempotence = true 时,Kafka 会自动将 acks 设置为 all,不可修改。)
- BatchNumMessages:控制生产者在单个批次中可以包含的最大消息数量,当生产者积累的消息数量达到该值时,会将这些消息打包成一个批次发送出去,以提高吞吐量和效率。
默认值:10000(不同版本可能会有些差异)。
值越大:可以减少网络请求次数,提高吞吐量,但会增加消息在本地的缓存时间(即延迟)。
值越小:消息会更快地发送,但可能增加网络开销。
注意:如果该属性与LingerMs属性搭配使用,即使消息数量未达到BatchNumMessages设定的值,但如果等待时间超过了LingerMs值,也会发送批次。
- AllowAutoCreateTopics:是否允许自动创建主题。默认为false,若将其设为 true,当生产者尝试向一个不存在的主题发送消息时,Kafka 会自动创建该主题。(生产环境谨慎使用)
AllowAutoCreateTopics = true
- MessageTimeoutMs:生产者等待消息确认的最长时间。一旦超过这个时间,生产者就会认为消息发送失败,进而可能触发重试机制。默认值为300000毫秒,即5分钟。具体设置多少应结合网络状况和业务需求来合理调整超时时间。
//5秒
MessageTimeoutMs = 5000
消费者消费Kafka所有分区消息
public static void RunConsume()
{
string brokerList = "192.168.12.136:9092,192.168.12.137:9093,192.168.12.138:9094";
var config = new ConsumerConfig
{
GroupId = "testgroup",
BootstrapServers = brokerList,
AutoOffsetReset = AutoOffsetReset.Earliest,
//禁用自动提交
EnableAutoCommit = false
};
using (var consumer = new ConsumerBuilder<string, string>(config).Build())
{
//订阅主题
consumer.Subscribe("test");
try
{
while (true)
{
ConsumeResult<string, string> consumeResult = consumer.Consume();
// 处理分区末尾标记
if (consumeResult.IsPartitionEOF)
{
Console.WriteLine($"Reached end of TopicPartition: {consumeResult.TopicPartition}");
continue; // 跳过本次循环,继续等待新消息
}
try
{
Console.WriteLine($"Consumed message: Partition='{consumeResult.Partition }', Offset='{consumeResult.Offset}', Key='{consumeResult.Message.Key}', Value='{consumeResult.Message.Value}', TopicPartitionOffset='{consumeResult.TopicPartitionOffset}'.");
//手动提交偏移量
consumer.Commit(consumeResult);
}
catch (KafkaException e)
{
Console.WriteLine($"Commit error:{e.Error.Reason}");
}
}
}
catch(OperationCanceledException e)
{
Console.WriteLine("消费已停止");
}
finally
{
consumer.Close();
}
}
}
发送一些数据到Topic下。
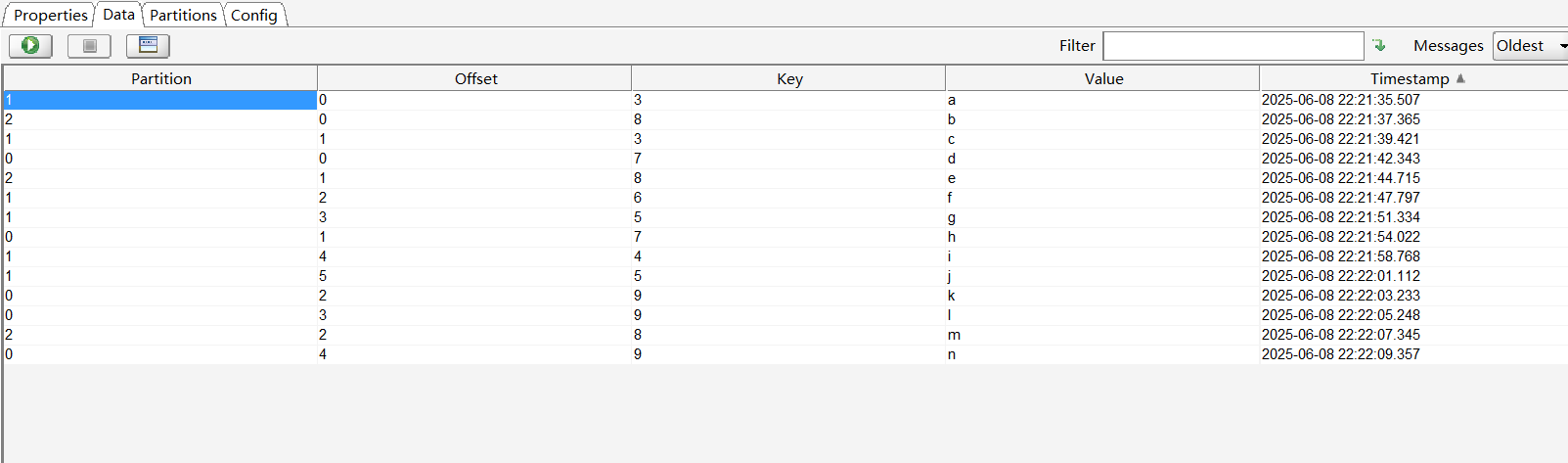
消费者通过指定topic接收消息。

注意:
- 由于设置了consumer.Commit(consumeResult); 因此已经手动提交偏移量到Kafka了,所以当你再次重新运行程序时,在groupId不变的前提下,消费者组会从上次提交的偏移量继续消费。如果之前已经消费完所有消息,那么再次启动时就不会有新消息可消费。
- 可以看到消费者读取的顺序和kafka中存储的消息顺序是不同的,这是因为该主题有多个分区,Kafka保证同一个分区下的消息是有序的,不同分区之间的消息没有全局顺序。
consumeResult.IsPartitionEOF:当消费者读取到分区的末尾(即当前没有新消息可消费)时,Kafka 会返回一个特殊的 ConsumeResult,其 IsPartitionEOF 属性为 true。此时:
- 消息内容为空:consumeResult.Message为 null。
- 偏移量信息有效:consumeResult.TopicPartitionOffset 表示分区的末尾位置。
加上此判断可以避免空指针异常和资源浪费。
消费者手动消费分区下指定偏移量消息
public static void RunConsume()
{
string brokerList = "192.168.12.136:9092,192.168.12.137:9093,192.168.12.138:9094";
var config = new ConsumerConfig
{
GroupId = "testgroup",
BootstrapServers = brokerList,
AutoOffsetReset = AutoOffsetReset.Earliest,
//禁用自动提交
EnableAutoCommit = false
};
using (var consumer = new ConsumerBuilder<string, string>(config).Build())
{
//手动指定分区偏移量(创建一个指向分区1的偏移量为3的位置,这样消费者就从偏移量3开始读取消息)
var topicPartitionOffset = new TopicPartitionOffset(new TopicPartition("test", 1), new Offset(3));
//手动分配分区并设置偏移量
consumer.Assign(topicPartitionOffset);
try
{
while (true)
{
ConsumeResult<string, string> consumeResult = consumer.Consume();
// 处理分区末尾标记
if (consumeResult.IsPartitionEOF)
{
Console.WriteLine($"Reached end of TopicPartition: {consumeResult.TopicPartition}");
continue; // 跳过本次循环,继续等待新消息
}
try
{
Console.WriteLine($"Consumed message: Partition='{consumeResult.Partition}', Offset='{consumeResult.Offset}', Key='{consumeResult.Message.Key}', Value='{consumeResult.Message.Value}', TopicPartitionOffset='{consumeResult.TopicPartitionOffset}'.");
//手动提交偏移量
consumer.Commit(consumeResult);
}
catch (KafkaException e)
{
Console.WriteLine($"Commit error:{e.Error.Reason}");
}
}
}
catch (OperationCanceledException e)
{
Console.WriteLine("消费已停止");
}
finally
{
consumer.Close();
}
}
}
这里程序中固定写死从分区1偏移量位置3的位置开始读取该分区中后面偏移量>=3的消息,另外,手动分配分区后,Kafka 不会使用消费者组的偏移量管理,因此,重启程序后,新的消费者实例没有之前的偏移量记录,会按照你手动指定的偏移量(或 AutoOffsetReset 策略)重新开始消费。


获取分区当前的水位线
在手动分配偏移量前,建议先通过 QueryWatermarkOffsets 获取分区的水位线范围,确保指定的偏移量在有效范围内,而不是像前面那样写死固定值。
var partitions = consumer.QueryWatermarkOffsets(new TopicPartition("test", 1), TimeSpan.FromSeconds(10));
该方法用于查询指定分区的低水位线(Low Watermark)和高水位线(High Watermark)。
返回值 partitions 包含两个关键属性:
- Low:分区中当前可消费的最小偏移量。
- High:分区中当前可消费的最大偏移量(下一条未消费消息的偏移量)。
通过水位线可以知道分区当前的可消费区间,避免手动分配无效的偏移。
//查询指定分区的低水位线(Low Watermark)和高水位线(High Watermark)。
var partitions = consumer.QueryWatermarkOffsets(new TopicPartition("test", 1), TimeSpan.FromSeconds(10));
long lowOffset = partitions.Low; // 例如:0
long highOffset = partitions.High; // 例如:10(表示下一条消息偏移量为10,当前最大已提交偏移量为9)
Console.WriteLine($"partitions lowOffset: {lowOffset},highOffset: {highOffset}");
//手动指定分区偏移量,从分区起始位置开始消费
var topicPartitionOffset = new TopicPartitionOffset(new TopicPartition("test", 1), lowOffset);
//手动分配分区并设置偏移量
consumer.Assign(topicPartitionOffset);
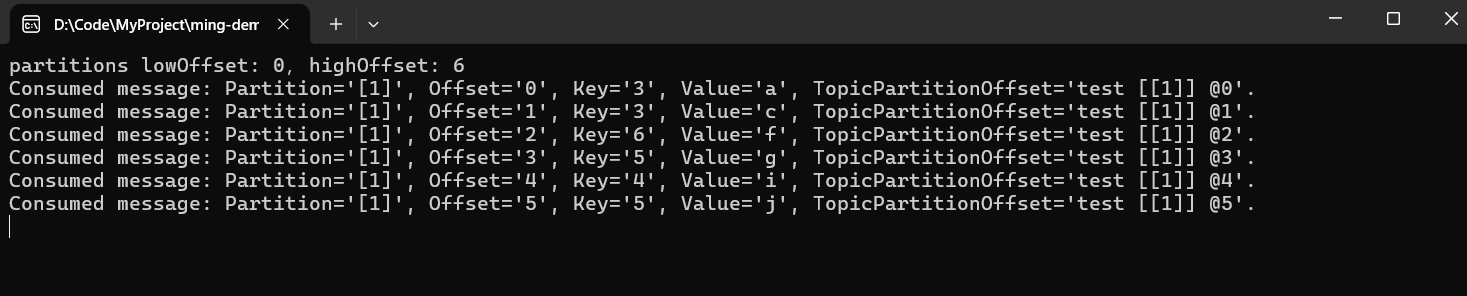
可以看到1分区下水位线最低位0,最高为6,6就代表下一条消息的偏移量,当前已提交的偏移量最大为5,如下图所示。
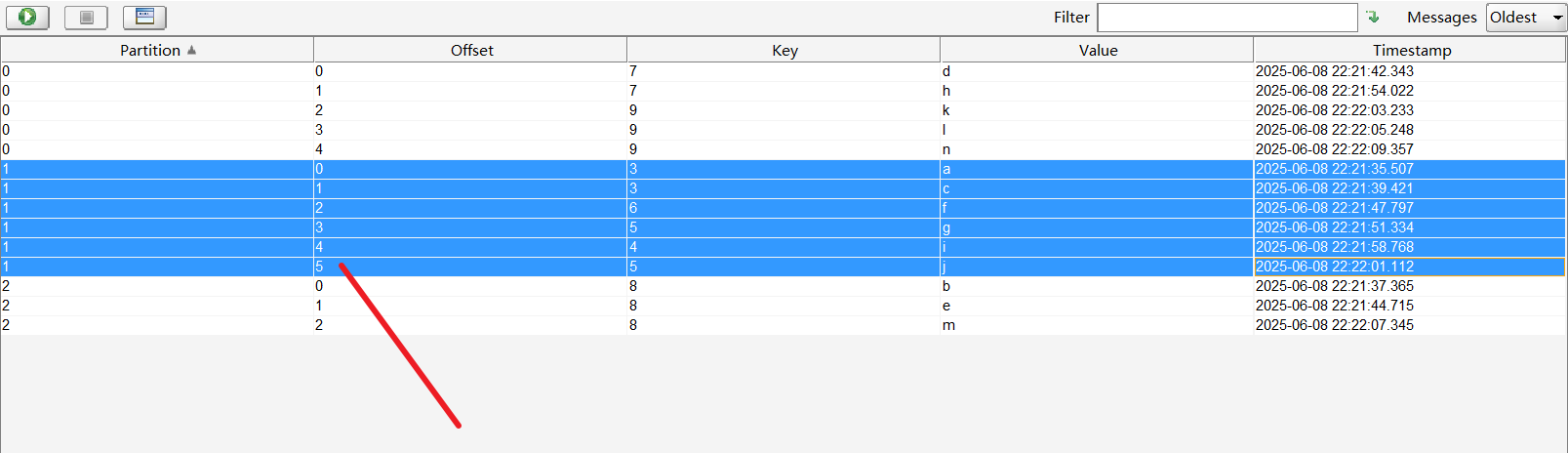
消费者重置所有分区的偏移量
public static void RunConsume()
{
string brokerList = "192.168.12.136:9092,192.168.12.137:9093,192.168.12.138:9094";
var config = new ConsumerConfig
{
GroupId = "testgroup",
BootstrapServers = brokerList,
AutoOffsetReset = AutoOffsetReset.Earliest,
//禁用自动提交
EnableAutoCommit = false
};
using (var consumer = new ConsumerBuilder<string, string>(config).Build())
{
using var adminClient = new AdminClientBuilder(new AdminClientConfig
{
BootstrapServers = config.BootstrapServers
}).Build();
var metadata = adminClient.GetMetadata("test", TimeSpan.FromSeconds(10));
var partitions = new List<TopicPartition>();
foreach (var partition in metadata.Topics[0].Partitions)
{
partitions.Add(new TopicPartition("test",partition.PartitionId));
}
consumer.Assign(partitions);
foreach(var partition in partitions)
{
var watermarkOffsets = consumer.QueryWatermarkOffsets(partition,TimeSpan.FromSeconds(10));
consumer.Seek(new TopicPartitionOffset(partition, watermarkOffsets.Low));
}
try
{
while (true)
{
ConsumeResult<string, string> consumeResult = consumer.Consume();
// 处理分区末尾标记
if (consumeResult.IsPartitionEOF)
{
Console.WriteLine($"Reached end of TopicPartition: {consumeResult.TopicPartition}");
continue; // 跳过本次循环,继续等待新消息
}
try
{
Console.WriteLine($"Consumed message: Partition='{consumeResult.Partition}', Offset='{consumeResult.Offset}', Key='{consumeResult.Message.Key}', Value='{consumeResult.Message.Value}', TopicPartitionOffset='{consumeResult.TopicPartitionOffset}'.");
//手动提交偏移量
consumer.Commit(consumeResult);
}
catch (KafkaException e)
{
Console.WriteLine($"Commit error:{e.Error.Reason}");
}
}
}
catch (OperationCanceledException e)
{
Console.WriteLine("消费已停止");
}
finally
{
consumer.Close();
}
}
}
ConsumerConfig参数配置解析
- EnableAutoCommit:是否启用自动提交偏移量,默认值为true。
当值为true时,Kafka 消费者会定期自动提交已消费消息的Offset。
当值设置为false时,则Kafka不会自动提交偏移量,这个时候必须在后面设置Commit,如果不设置Commit,每次消费者重启后,都会从AutoOffsetReset(Earliest 或 Latest)指定的位置重新开始消费,进而可能导致重复消费,因为Kafka不知道消费了哪些消息。
consumer.Commit(consumeResult);
- GroupId:消费者组Id,作用如下所示
消费者组表示:用于标识一组消费者属于同一个消费者组。同一个消费者组内的消费者会协作消费一个或多个主题的消息,Kafka会确保每条消息只会被组内的一个消费者消费(负载均衡)。
分区分配:Kafka 会根据 ****GroupId ****将主题的分区(Partitions)分配给组内的不同消费者,确保每个分区只能被组内的一个消费者消费。
- 例如:如果 Topic 有 3 个分区(Partition 0、1、2),而消费者组有 2 个消费者,Kafka 可能会分配:
- 消费者1:Partition 0 和 1
- 消费者2:Partition 2
- 这样可以实现消息的并行处理,提高吞吐量。
偏移量管理:Kafka 会为每个 GroupId 存储消费的偏移量(Offset),记录消费者组已经消费到了哪个位置。
- 如果 EnableAutoCommit 设为 true,Kafka 会定期自动提交偏移量;如果设为 false,则需要手动调用 consumer.Commit(consumeResult) 提交。
- 如果消费者重启,它会从上次提交的 Offset 继续消费,避免重复消费或丢失消息。
消费者再平衡:当消费者组内的消费者数量发生变化时,Kafka会触发再平衡,重新分配分区给存活的消费者。
- AutoOffsetReset:决定了当消费者首次启动或找不到已提交的偏移量(Offset)时,从何处开始消费消息。总共有3个值,分别为Latest、Earliest、Error。其中默认值是Latest。
- Latest:从最新的消息开始消费,即消费启动后新产生的消息,不处理主题已有的历史数据。(适用于实时监控、日志采集)。
- Earliest:从主题的最早消息开始消费,即从分区的起始位置开始,包含所有历史数据。(适用于数据同步)
- Error:如果找不到已提交的偏移量(如首次启动或偏移量已过期),直接抛出NoOffsetForPartitionException异常,终止消费进程。(适用于金融系统等不允许自动重置偏移量的场景)
- BootstrapServers:指定了 Kafka 代理服务器的列表。这里具体指定的是Kafka集群的地址,用于连接集群。
消费者相关的回调配置
using (var consumer = new ConsumerBuilder<Ignore, string>(config)
.SetErrorHandler((_, error) =>
{
if (error.IsFatal)
{
Console.WriteLine($"Fatal error: {error.Reason}");
// 可选择退出应用或重启消费者
}
else
{
Console.WriteLine($"Transient error: {error.Reason}");
// 无需终止消费,Kafka 会自动重试
}
})
.SetPartitionsAssignedHandler((c, partitions) =>
{
Console.WriteLine($"Assigned partitions: {string.Join(", ", partitions)}");
// 可自定义分区消费策略
})
.SetPartitionsRevokedHandler((c, partitions) =>
{
Console.WriteLine($"Revoking partitions: {string.Join(", ", partitions)}");
c.Commit(partitions); // 手动提交偏移量
})
.Build())
- SetErrorHandler:错误处理回调,捕获 Kafka 消费者在运行过程中发生的错误(如 Broker 连接失败、网络临时中断、消息反序列化失败等)。
参数:
- Error对象包含错误码和详细原因。
适用场景:适用于记录错误日志、监控报警等场景。
- SetPartitionsAssignedHandler:分区分配回调,当消费者成功分配到新分区时触发(如首次启动或 Rebalance 后)
参数:
- List
:分配给当前消费者的分区列表。
// 自定义起始 Offset(例如从分区开始位置消费)
var offsetsToSeek = partitions.Select(p =>
new TopicPartitionOffset(p, Offset.Beginning)).ToList();
c.Assign(offsetsToSeek);
或者
// 自定义起始 Offset(从 Offset=100 开始)
var offsets = partitions.Select(p => new TopicPartitionOffset(p, new Offset(100)));
c.Assign(offsets);
适用场景:
- 自定义分区消费起点(如跳过历史数据,从某个时间点开始)。
- 记录分配的分区信息,用于监控或调试。
- SetPartitionsRevokedHandler:分区回收回调,当消费者的分区被重新分配或关闭时触发(如 Rebalance 前或消费者主动退出)。
参数:
- List
:包含即将被回收的分区及其当前消费位置。
适用场景:
- 手动提交偏移量:确保在分区被回收前提交最后处理的 Offset。
- 释放分区相关资源(如关闭文件句柄、数据库连接)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号