
数据分析与数据挖掘 - 05统计概率
一 统计学基础运算
1 方差的计算
在统计学中为了观察数据的离散程度,我们需要用到标准差,方差等计算。我们现在拥有以下两组数据,代表着两组同学们的成绩,现在我们要研究哪一组同学的成绩更稳定一些。方差是中学就学过的知识,可能有的同学忘记了 ,一起来回顾下。
A组 = [50,60,40,30,70,50] B组 = [40,30,40,40,100]
为了便于理解,我们可以先使用平均数来看,它们的平均数都是50,无法比较出他们的离散程度的差异。针对这样的情况,我们可以先把分数减去平均分进行平方运算后,再取平均值。
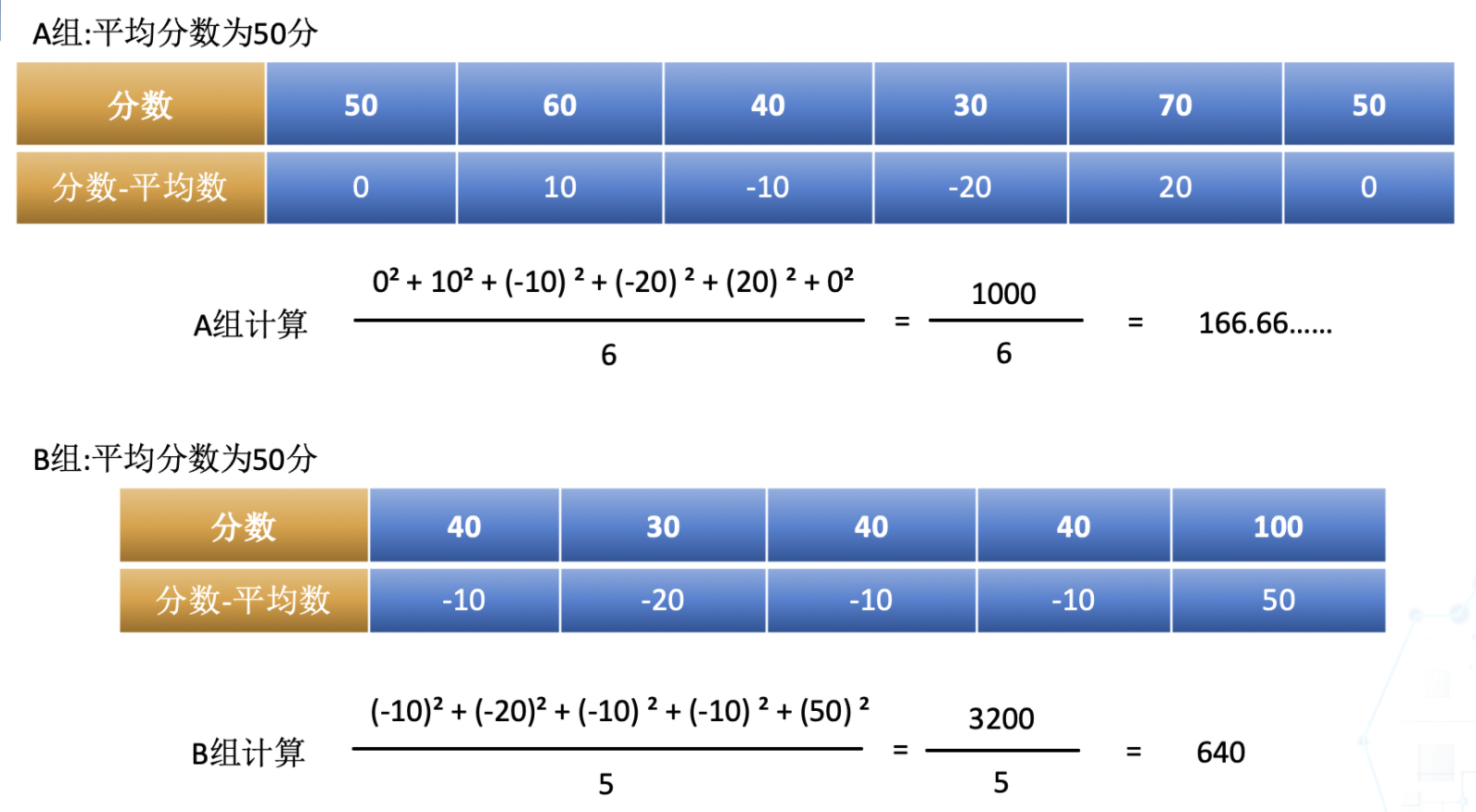
想上面这样就是方差的计算方式,就是数组中的每一个数减去平均值,然后再分别计算它们的平方值,最后再取平均数的运算就叫方差。方差很适合用来研究数据的离散程度,但是会存在两个问题:
- 有时数值会变得特别大
- 运算的结果变成了原来的平方
为了解决上面的问题,我们会把最后的结果开方,就像这样:
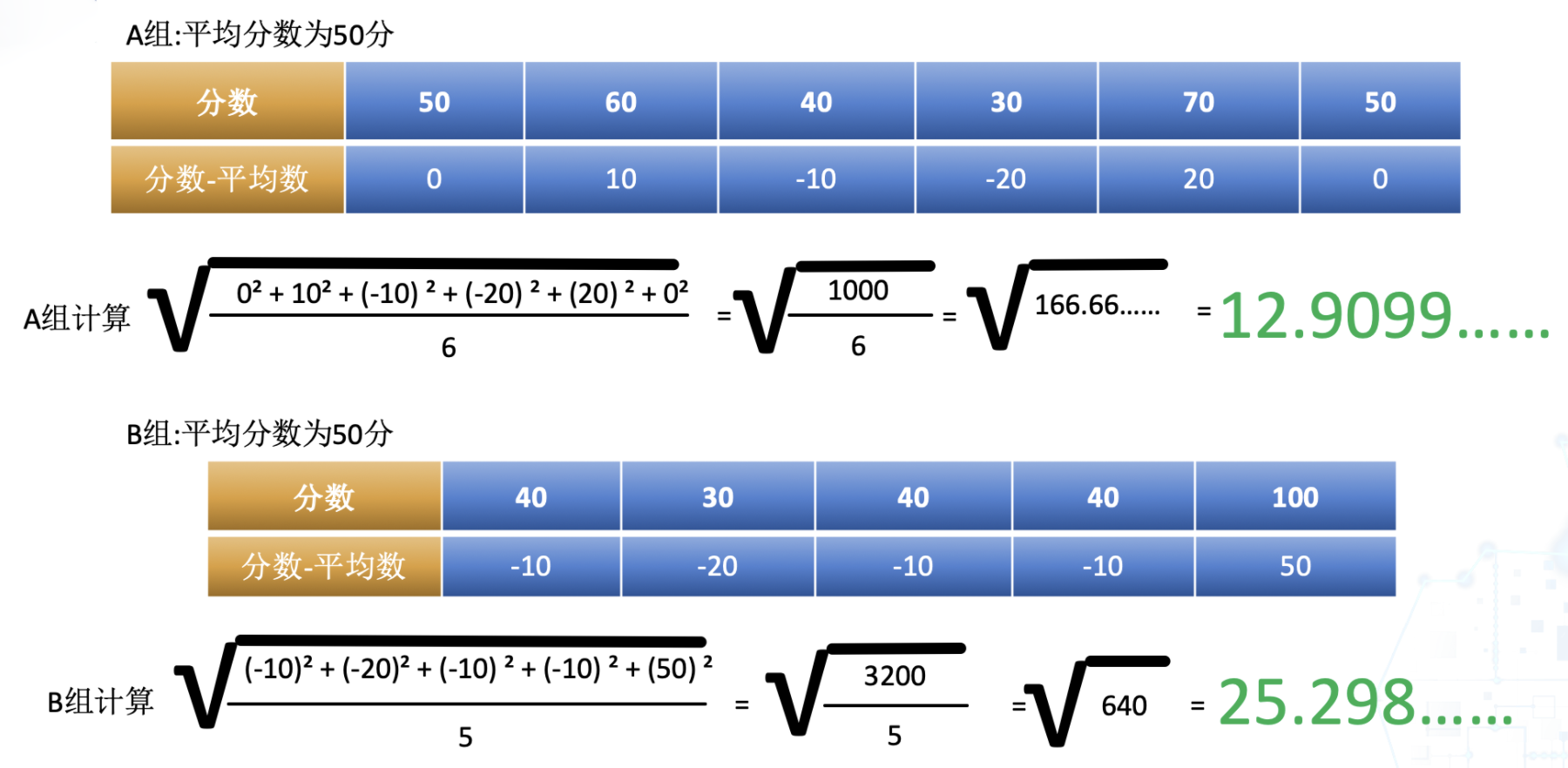
在方差的结果上,开一个根号,运算出来的结果就叫做标准差了。通过标准差的计算后,我们一下就能够看出来,标准差越小的,证明其成绩越稳定。
2 使用numpy计算标准差和方差
import numpy as np
# 创建一个二维数组
arr = np.array([[3, 7, 25, 8, 15, 20],
[4, 5, 6, 9, 14, 21]])
# 计算方差
print(arr.var())
print(np.var(arr))
# 计算标准差
print(arr.std())
print(np.std(arr))
# 计算轴0方向方差
print(arr.var(axis=0))
print(np.var(arr, axis=0))
# 计算轴1方向方差
print(arr.var(axis=1))
print(np.var(arr, axis=1))
# 计算轴0方向标准差
print(arr.std(axis=0))
print(np.std(arr, axis=0))
# 计算轴1方向标准差
print(arr.std(axis=1))
print(np.std(arr, axis=1))
二 二项式定理
1 二项式系数
二项式定理非常重要,是理解和应用概率分布的前提,这都是中学学过的,我们一起来回顾一下。
2ab这一项可以用排列组合的知识来理解,从(a+b)(a+b)分别选出a和b的可能性,那么一共有两种情况:
- 从第一个(a+b)中选出a,从第二个(a+b)选出b
- 从第二个(a+b)中选出a,从第一个(a+b)中选出b
所以ab左边的系数就是2,这个2就是二项式系数,同理:

我们从上边的两个例子中可以看到,无论是第一个例子中的从两个括号中选出一个b,还是后边的从3个括号中选出一个b(这里我们把b作为研究对象,其实无论是谁都是一样的)都是组合的问题,所以结合我们中学学过的知识二项系数可以总结为如下公式:

在统计学中,对于二项分布来说,二项系数是必不可少的知识,关于二项分布我们后边会讲到。
2 用Python获得二项系数
首先需要声明一个函数,函数接收两个参数,一个是n,一个是k,返回值为其二项系数的值。
import itertools
import numpy as np
# 等待排列的数组
arr = [1, 2, 3, 4, 5]
# 排列的实现P
print(list(itertools.permutations(arr, 3)))
# 组合的实现C
print(list(itertools.combinations(arr, 3)))
# 获取二项系数的函数
# 支持两个参数,第一个是n,第二个是k
def get_binomial_coefficient(n, k):
return len(list(itertools.combinations(np.arange(n), k)))
print(get_binomial_coefficient(3, 1))
使用二项式系数就可以展开(a+b)^n,所以有二项式定理,如下:

三 独立实验与重复实验
寺庙在中国已经遍布大江南北了,一天小王和小李二人出游,爬山后,偶遇一寺庙,寺庙中有一个大师,善占卜。于是二人决定请大师帮忙占卜一次。大师见二人结伴而来,便问二人是占卜独卦,还是连卦呢?二人不解,何为独卦,何为连卦?于是大师解答到:独卦为第一人占卜后,将卦签放回签桶中后,再进行第二次占卜。连卦为第一人占卜后,已抽出的卦签不放回签桶中,直接进行第二次占卜。
假设签筒中,只有5根签,其中2根是上签,而其他3根是下签。小王先抽签,小王抽签的行为记为S,小李抽签的行为记为T。在独卦的占卜规则下,S的结果并不影响T的结果。也就是说不管小王是否抽中上签,小李抽中上签的概率都是2/5。而在连卦的占卜规则下,S的结果对T的结果产生影响。因为小王抽完签之后,并不把签放回桶中。如果小王抽中上签,那么小李抽中上签的概率就是1/4,如果小王没有抽中上签,那么小李抽中上签的概率就是2/4。在独卦的占卜规则下,两次抽签行为S与T的。它们的结果互不影响,我们在统计学中称S与T是独立试验。
当S与T相互独立时,S中发生事件A和T中发生的事件B的概率P可以表示为:
P(A∩B) = P(A) * P(B)
显然,在独卦的占卜规则下,小王和小李都抽中上签的概率是4/25。
现在有这样一个场景,掷骰子的游戏,仍然是小王和小李一起玩,每人拿3颗骰子。游戏规则是三颗骰子每个掷一次,最后谁的点数大谁赢。这里不管他们掷骰子多少次,每一次的结果对于其他次的结果都不会产生影响,所以他们都是相互独立的实验。
对于这样反复的独立试验,我们称其为重复试验或者叫独立重复试验。现在我们把掷3次骰子,每一次掷骰子时,其中2颗骰子都出现1的情况画图如下(X代表其他数字):

我们先来看一下第一次掷骰子的情况前两颗骰子为1,第三颗骰子为其他数字的概率分别为1/6、1/6、5/6,因为每一次的试验都是相互独立的,所以发生的概率为1/6×1/6×5/6。三次掷骰子,每一次有两颗骰子是1的情况的种类为3种,由于3种情况是互斥的(不可能同时发生),所以概率应该为3次的概率相加。也就是:3×(1/6)²×5/6。A事件和B事件相互排斥时,公式可以表示为:
P(A∪B)=P(A)+P(B)
根据以上试验结果,可得重复试验的概率公式为:

重复试验对于下一章我们要学习的二项分布的理解非常有帮助,所以一定要理解。如果不是特别的理解,你可以现在把上边掷骰子的情况修改成为4颗骰子掷6次,每一次出现两个1的情况画图重新按照咱们上边的思路梳理一下,相信你就已经能够掌握了。
练习题:
现在有5道4选1的问题。A同学对这5道题目完全不会,但在乱答的情况下,能够答对一半以上的概率是多少,用代码实现一下。
import itertools
import numpy as np
"""
题目解析:答对一半以上的情况分别为3题,4题和5题
不用考虑其顺序,答对任意题目都可以,所以这是一个组合的问题
"""
# 声明一个函数来求组合问题
def get_binomial_coefficient(n, k):
return len(list(itertools.combinations(np.arange(n), k)))
# 每题答对的概率
P_true = 1 / 4
# 每题答错的概率
P_false = 3 / 4
# 求答对0到5题的组合情况
# 答对0题的组合情况
zero = get_binomial_coefficient(5, 0)
# 答对1题的组合情况
one = get_binomial_coefficient(5, 1)
# 答对2题的组合情况
two = get_binomial_coefficient(5, 2)
# 答对3题的组合情况
three = get_binomial_coefficient(5, 3)
# 答对4题的组合情况
four = get_binomial_coefficient(5, 4)
# 答对5题的组合情况
five = get_binomial_coefficient(5, 5)
# # # 答对一半以上的概率(答对3题、4题、5题)
last = three * pow(P_true, 3) * pow(P_false, 2) + four * pow(P_true, 4) * pow(P_false, 1) + five * pow(P_true, 5) * pow(
P_false, 0)
print(last)
学霸的世界:有一两个不太确定的,蒙一下吧,考完了很没信心,感觉考得不怎么样,结果是除了蒙的,其他的都对了,数学140分。
学渣的世界:好多不会的,我感觉选这个就应该对,毕竟蒙对的经验很丰富,感觉考得还可以,结果是会的马虎做错了,蒙的就对了一个,数学89分,啪啪打脸。
根据概率结果可知,乱答看似概率还不错,但实际运算出来后概率低的可怜,所以每次乱答后,实际得分总比想象中的得分低。
四 ∑符号及其意义
在以前,我们表示a1到a5的和会这样写:S5 = a1 + a2 + a3 + a4 + a5。同理,如果我们要表示a1到a10的和会这样写:S10 = a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8 + a9 + a10。如果我们要表示a1到a1000的和我们会这样写S1000 = a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8 + …… + a1000。但是中间的……总给人一种不好的感觉,就像我们在学习二项定理时的表达方式,总感觉特别的冗长。为了解决这个问题,我们就引入了Σ(读西格玛)符号,也可以叫做求和符号。像上边的表示a1到a1000的和我们可以这样表达:
Σ(读西格玛)符号在数学中非常的常见,在以后的学习中,你也几乎可以在任意一个算法模型中见到这个符号,所以它的特点也一定要掌握。
Σ可以使用分配率,我们一起来看一个例子:

下面我们一起来学习一下几个关于Σ的计算公式,记住它们,以后你的计算将会非常的方便。
公式一及其证明过程如下:
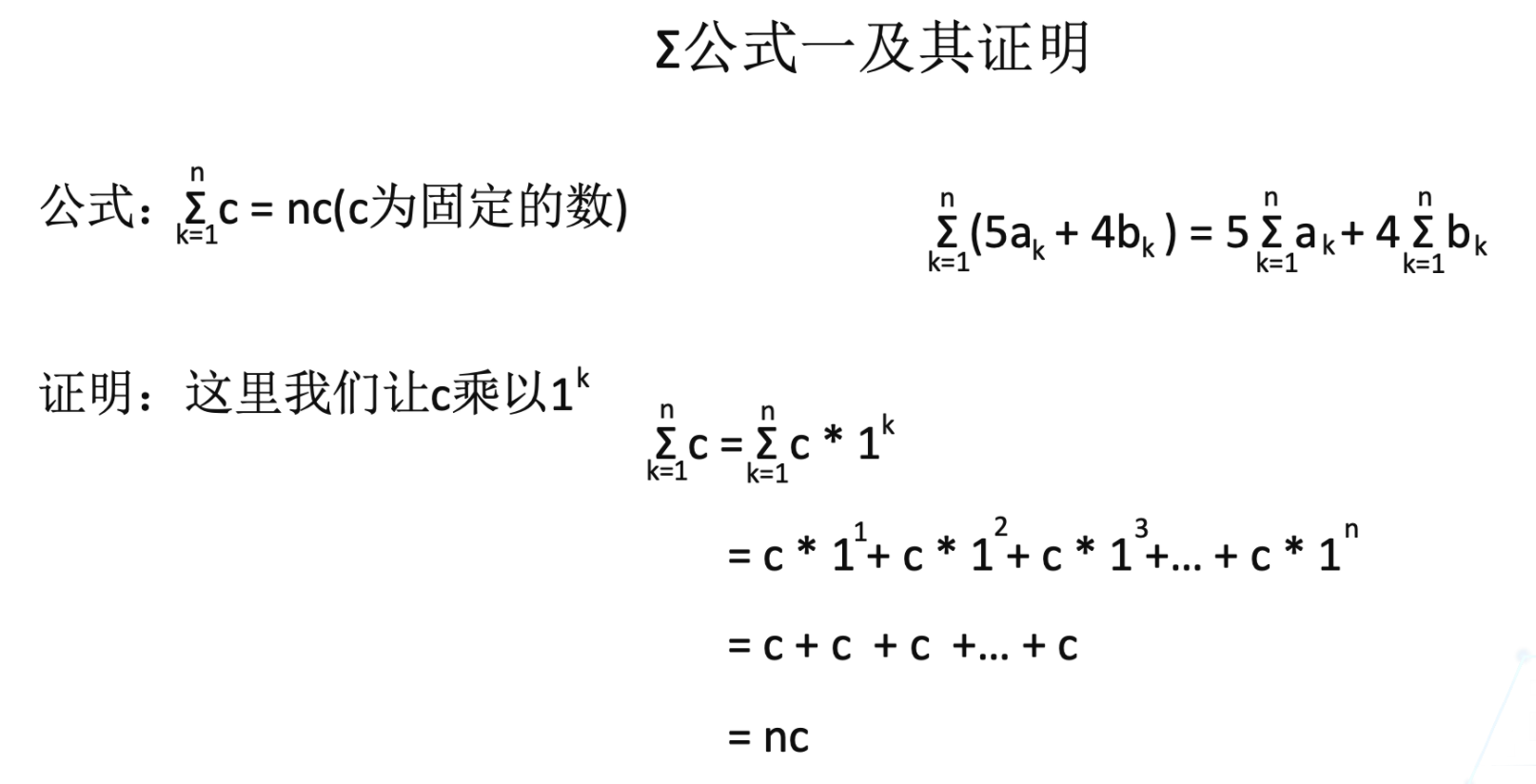
公式二及其证明过程如下:

Σ的计算公式我们暂时先学习这两个,其他的公式后边用到的时候我们再来结合着场景进行学习。
五 随机变量
终于到了随机变量,随机变量后边就是概率分布的知识了,随机变量在人工智能领域中的应用非常的普遍。首先说一下随机变量的分类,随机变量分为离散型随机变量和连续型随机变量。离散型随机变量的基本定义就是在实数范围内取值并不连续,或者说他的取值不是一个区间,而是一些固定的值。连续型随机变量则相反,它的取值是一个区间,在实数范围内是连续的。
还是举个例子比较形象,请看下面的示例:
离散型随机变量:一次掷20个硬币,k个硬币正面朝上,k是随机变量,k的取值只能是自然数0,1,2,…,20,而不能取小数3.5、无理数√20,因而k是离散型随机变量。
连续型随机变量:公共汽车每15分钟一班,某人在站台等车时间x是个随机变量,x的取值范围是[0,15),它是一个区间,从理论上说在这个区间内可取任一实数3.5、√20等,因而称这随机变量是连续型随机变量。
六 伯努利分布
伯努利分布也被称为“零一分布”或“两点分布”。从名字上,我们就能够看出来,伯努利分布中事件的发生就两种情况。伯努利分布指的是一次随机试验,结果只有两种。生活中这样的场景很多,抛硬币是其中一个,我们抛一次硬币,其结果只有正面或反面。或某一个事件的成功和失败,病情的康复或未康复等等。
我们用字母x来表示随机变量的取值,并且它的概率计算公式为:
P(x=1) = p,P(x=0) = 1-p
当x=1时,它的概率为p,当x-0时,它的概率为1-p,我们就称随机变量x服从伯努利分布。
练习:
甲和乙,两个人用一个均匀的硬币来赌博,均匀的意思就是不存在作弊行为,硬币抛出正面和反面的概率各占一半。硬币抛出正面时,甲输给乙一块钱,抛出反面时,乙输给甲一块钱。我们来用Python实现这一过程和输赢的总金额呈现的分布情况。
分析:
我们用数字1来表示抛得的结果为正面,用数字-1来表示抛得的结果为反面。为了呈现出概率分布的情况,我们需要有足够多的人来参与这个游戏,并且让他们两两一组来进行对决。
# 导入 matplotlib库,用来画图,关于画图我们后边会有专门的章节进行讲解
import matplotlib.pyplot as plt
# 导入numpy
import numpy as np
n_person = 200
n_times = 500
t = np.arange(n_times)
# 创建包含1和-1两种类型元素的随机数组来表示输赢
# *2 -1 是为了随机出1 和-1,(n_person, n_times)表示生成一个200*500的二维数组
steps = 2 * np.random.random_integers(0, 1, (n_person, n_times)) - 1
# 计算每一组的输赢总额
amount = np.cumsum(steps, axis=1)
# 计算平方
sd_amount = amount ** 2
# 计算所有参加赌博的组的平均值
average_amount = np.sqrt(sd_amount.mean(axis=0))
print(average_amount)
# 画出数据,用绿色表示,并画出平方根的曲线,用红色表示
plt.plot(t, average_amount, 'g.', t, np.sqrt(t), 'r')
plt.show()
七 二项分布
离散型随机变量最常见的分布就是二项分布,我们还是以掷骰子为例子来开始这一章节的知识讲解。比如我们拥有一个骰子,那么每掷一次骰子的取值可能性为1、2、3、4、5、6,这些取值每一次的可能性都为六分之一,因为每一次掷骰子的行为都是独立的,第一次的结果并不影响第二次的任何行为和结果,这也叫概率的独立性。
总结一下,它一共有两个特点:
- 每一次事件的概率都大于等于0,如果我们用P来表示概率,用X来表示事件,其数学表示就是P(X)>=0
- 所有事件的概率的总和为1,也就是说骰子一共有6个面,我们每投掷一次骰子,一定会获得1、2、3、4、5、6数字其中的一个,其数学表示就是∑P(Xi)=1
现在有两个人A和B在进行某种对决,瓶子里有两个红球,一个白球,从里面随机抽取,抽到红球A获胜,抽到白球B获胜,抽完球再放进去。显然,A获胜的概率为2/3,在这种情况下,A能赢的次数就是一个随机变量了,而这个随机变量是如何分布的呢?
假设对局3次,A能赢的次数为x,则x的值有可能是0、1、2、3中的一个,关于其分别出现的概率,我们可以用反复试验的概率来进行求解(这其实就是3重伯努利试验)。
概率计算结果如下:

将x的概率分布整理成表,并替换成二项系数如下图:
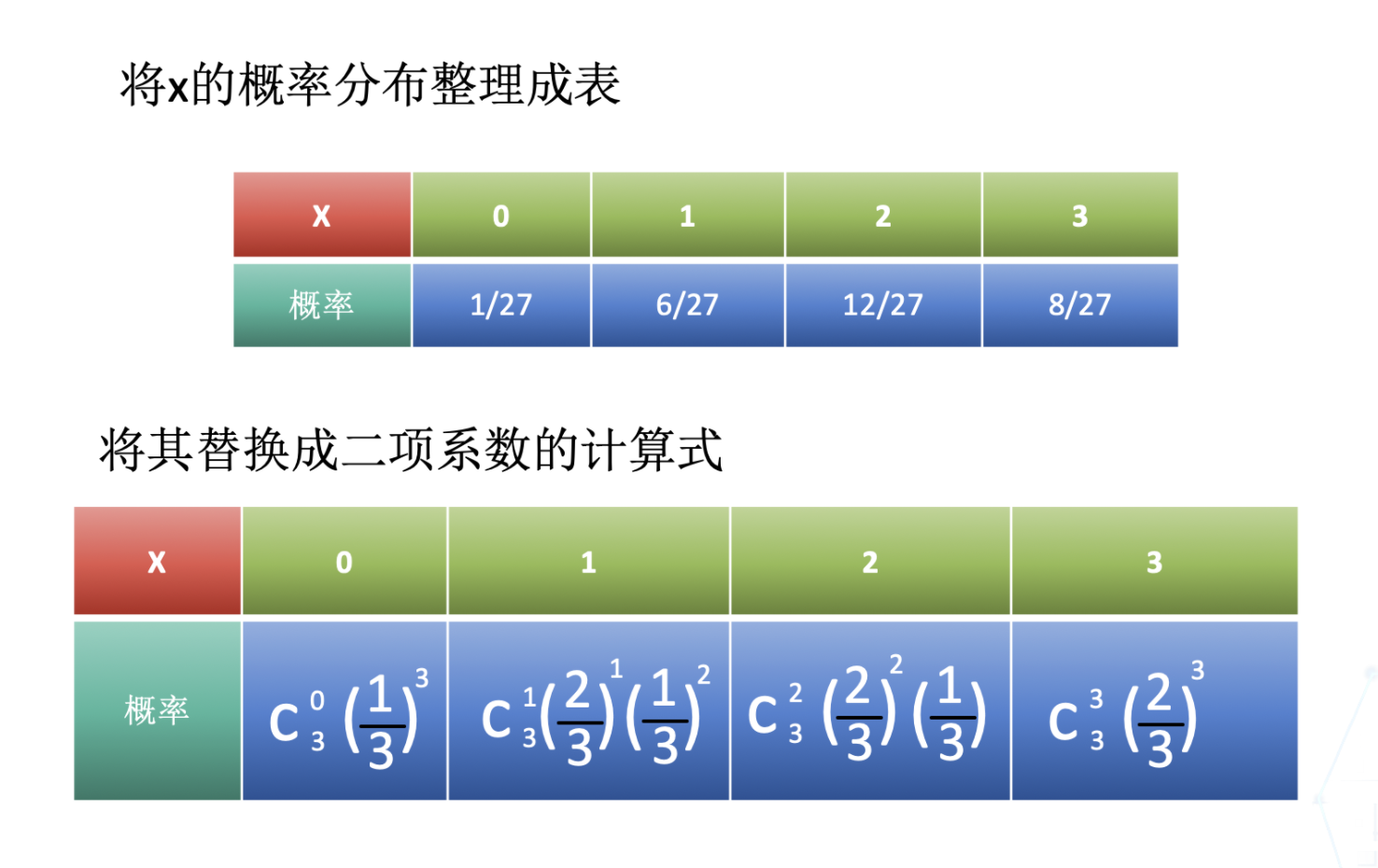
这就是二项分布的典型例子啦。一般来说,成功概率为p的试验,独立重复n次后的成功次数为X的概率分布,被称为关于发生概率为p、次数为n的二项分布。
这中情况下,X=k(k=0、1、2、…、n)的概率为n次重复中有k次成功(一次成功概率为p),整理后的公式如下:
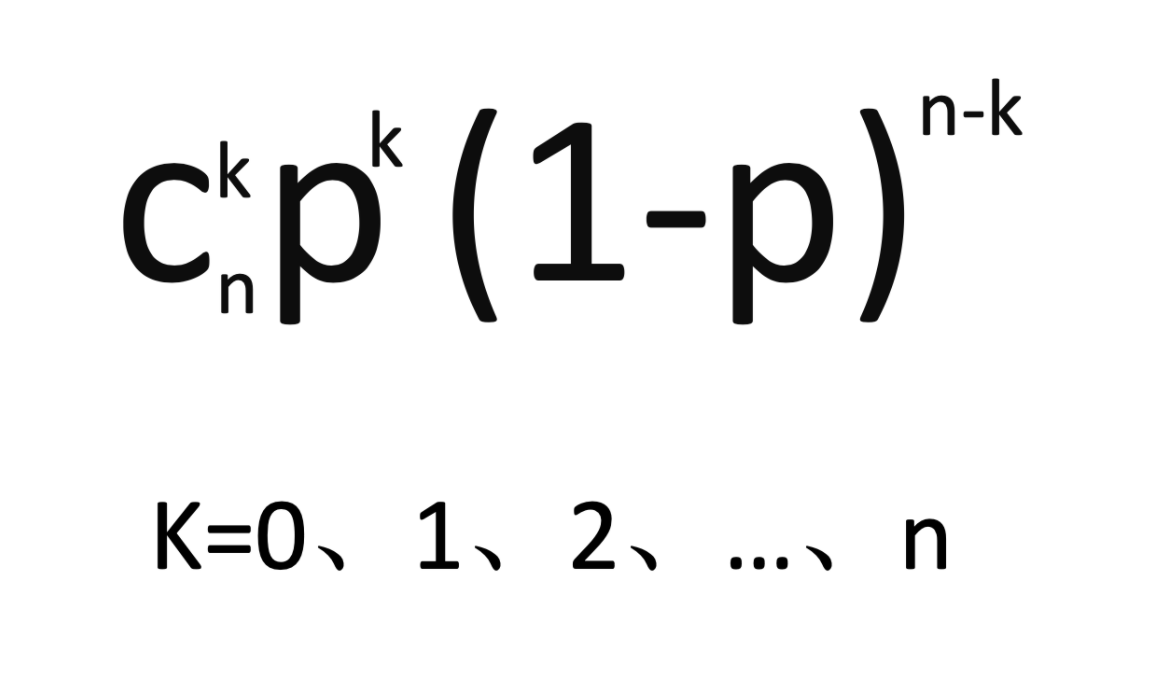
那么二项分布又与伯努利分布是什么样的关系呢?看着好像感觉有一些相似的地方,这种结果为成功或失败,胜或负等,结果是二选一的试验,被称为伯努利试验。在伯努利试验中,已知其中一个结果发生的概率(多数取成功的概率)时,此伯努利试验重复n次(也叫n重伯努利试验)时,其事件发生的次数(成功次数)遵循二项分布。如果二项分布中的试验次数变成了1次,那么这就叫做伯努利试验了,其随机变量是服从二项分布的。所以伯努利分布是二项分布在n=1时的特例,这就是它们的关系了。
最后总结一下二项分布,如下图:

八 条件概率
现在假设我们有两个事件,事件A和事件B。当事件B发生时,事件A发生的概率,这就是条件概率的理解。条件概率公式是:
P(A|B) = P(A∩B)÷P(B)
**
这个公式看似有点抽象,但如果我们把它变形为** P(B) * P(A|B) = P(A∩B),**就很好理解,P(B)表示事件B发生的概率,确定了事件B发生的概率再乘以P(A|B)自然就是事件A和事件B同时发生的概率。P(A|B)就是事件B发生时事件A发生的概率,P(A∩B)指的是事件A和事件B同时发生的概率。
同理,可得:
P(B|A) = P(A∩B)÷P(A)
**
把两个公式变形:
P(A∩B) = P(B) * P(A|B)
** P(A∩B) = P(A) * P(B|A) **
即可推导出:
P(A|B) = P(B|A) * P(A) / P(B)
**
这就是简单贝叶斯公式和它的推导过程,贝叶斯定理在人工智能领域可是非常重要的知识点,未来你会学到很多贝叶斯模型的,比如高斯贝叶斯、多项式贝叶斯、伯努利贝叶斯等等的分类器。
练习:
现在假设一天之中,我饿了的概率是10%,我饿了并且在吃饭的概率是50%,我吃饭的概率是40%
问:我吃饭的时候饿了的概率。
把我饿了看作事件A,则P(A) = 10%,把我吃饭的概率看作事件B,则P(B) = 40%,已知P(B|A) = 50%,则P(A|B) = P(B|A) * P(A) / P(B) = 0.5 * 0.1 / 0.4 = 12.5%
九 全概率
全概率可是概率论中非常重要的知识点,也关系着后边我们对贝叶斯定理进行深入的推导。那么什么又是全概率呢?
先从一个故事开始讲解一下,拿上班的道路选择举例说明吧。
我每天上班一共有4条路可以选择,我们现在把这4条路编成号码,分别是1号路到4号路。我每天会选择不同的路进行上班,来碰一下自己运气。现在我每天选择1号路上班的概率是20%,2号路的概率是30%,3号路的概率是10%,4号路的概率是40%。但是北京的路很糟糕,尤其是上班的高峰期,每一条路都有可能拥堵。现在1号路堵的概率为30%,2号路堵的概率是40%,3号路堵的概率是50%,4号路堵的概率是25%。一旦发生拥堵的情况我一定会迟到,现在来求一下我上班不迟到的概率。
这道题目首先要理解的就是如果我想要上班不迟到,那么路上就不能遇到拥堵的情况,也就是我们现在要把拥堵的概率,转换成为不拥堵的概率。那么对应的把拥堵的概率换算成不拥堵的概率就是1号路不堵的概率为70%,2号路不堵的概率是60%,3号路不堵的概率是50%,4号路堵的不概率是75%。换算完成后,下一步就是计算出我选择了其中一条路,并且这条路没有发生拥堵的概率。
首先我选择1号路的概率是20%,也就是0.2,并且1号路不拥堵的概率为70%,就是0.7,那么这件事情发生的概率就是0.20.7,结果等于0.14。这里有两个事件,事件A是我选择了1号路,事件B是1号路不拥堵,那么可以用P(AB)来进行概率的表示。也就是P(AB)=0.14,当我选择了1号路,并且一号路不拥堵的概率是0.14。我选择2号路的概率是0.3,2号路不拥堵的概率是0.6,这个时候我把事件A当做是2号路不拥堵,事件B当做是我选择了2号路,那么就可以写成P(AB)=0.18。那么现在我们来看一下我选择了3号路,并且3号路不堵的概率吧,就是0.10.5 = 0.05。同理,我选择了4号路,并且4号路不堵的概率是0.4*0.75 = 0.3。那么最终我上班不迟到的概率就是0.14+0.18+0.05+0.3=0.67。
以上就是全概率的计算过程。我们来总结一下全概率公式。这里我们把上班不迟到的这件事情叫做事件A,它可以表示为P(A)。选择上班路线的事件叫做事件B,那么4条路的选择概率分别可以表示为P(B1)=0.2、P(B2)=0.3、P(B3)=0.1、P(B4)=0.4。那么分别对应着4条路,并且选择后它们不堵的概率可以表示为P(A|B1)=0.7、P(A|B2)=0.6、P(A|B3)=0.5、P(A|B4)=0.75。
也就是说,我上班不迟到的全概率的计算方法就是
P(A)=P(A|B1)P(B1)+P(A|B2)P(B21)+P(A|B3)P(B3)+P(A|B4)P(B4)
**
以上只有4种情况的发生,那么针对于n中情况的全概率公式,我们可以这样写P(A)=P(A|B1)P(B1) + P(A|B2)P(B2) + ... + P(A|Bn)P(Bn),进一步简化公式,用求和符号Σ(西格玛)来进行表示就是:
以上这就是全概率公式和他的推导过程。
十 贝叶斯定理
上面的章节我们分别学习了简单贝叶斯公式和全概率公式,现在我们把全概率公式A和B做一个互换,可得:
把现在的P(B)带入到简单贝叶斯公式中,并替换P(B),可得:
这个最终的公式就叫做贝叶斯定理,下面我们用一个经典的题目来练习一下。
有一种疾病,发病率为千分之一。目前的基因检测技术,只要发病了就一定能够检测到。但如果没有发病的话,其误诊的概率为百分之五。这里我们用阳性代表生病了,这是医院里的检测报告的术语。现在一个人的化验结果呈阳性(结果代表它得病了),求这个人真实患病的概率。
这道题目的解题思路是,首先我们要列出已知条件:
- 第一个已知条件是这种疾病的发病率为千分之一,那么用可以用P(病)=0.001来表示。
- 第二个已知条件是只要发病了就一定能够检测到,那么也就是P(阳性|病)=1,也就是生病了那么其检测结果就是阳性,因为阳性代表着生病。
- 第三个条件是误诊率为百分之五,也就是P(阳性|健康)=0.05。
梳理清楚了三个条件,那么问题是其化验结果呈阳性,其真实的患病概率是多少,其实求的就是P(病|阳性)的值是多少?
- 根据简单贝叶斯公式来进行计算一下,也就是P(病|阳性)=P(阳性|病)P(病)/P(阳性)。
- 进一步的把P(阳性)换算成全概率公式P(阳性)=P(病)P(阳性|病)+P(健康)P(阳性|健康)。
- 最终得到P(病|阳性)=P(阳性|病)P(病)/(P(病)P(阳性|病)+P(健康)P(阳性|健康))
P(病|阳性) = 1 * 0.001 / (0.001 * 1 + 0.999 * 0.05) = 0.0196 = 1.96%
这一章到这里就结束了,最后留一个小题目:垃圾邮件筛选
判断邮件标题中包含"购买商品,不是广告",这样一个邮件是垃圾邮件吗?
我们通过分词技术已经把"购买商品,不是广告"切分为4个单词,分别是购买、商品、不是、广告。
在已知的数据样本中,共有36封邮件。其中的24封邮件为正常邮件,12封邮件为垃圾邮件。其中正常邮件包含"购买"这个词的有2封,包含"商品"的邮件有4封,包含"不是"的邮件有4封,包含"广告"的邮件有5封。
在垃圾邮件中包含"购买"这个词的有5封,包含"商品"的邮件有3封,包含"不是"的邮件有3封,包含"广告"的邮件有3封。注:一封邮件标题可以包含一个或多个关键词。
问题:判断一封新来的邮件,标题是"购买商品,不是广告",是正常邮件还是垃圾邮件。
思路提示:求的就是P("购买商品,不是广告")P("正常")的概率大还是P("购买商品,不是广告")P("垃圾")的概率大,谁的概率大结果就是谁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号