技术的极限(11): 有趣的编程
上一篇:技术的极限(10): 考虑技术的伸缩性
下一篇:技术的极限(12): 探索编译器
目录:
** 0x01 达夫设备
** 0x02 switch+goto
** 0x03 硬件加速
** 0x04 O(1)大数据传输
** 0x05 C语言的异常跳转
** 0x06 非欧几里得引擎
** 0x07 为什么现代软件开发令人伤心
** 0x08 设计/内容/商业的交集=付费社区
** 0x09 高阶初学者的系统设计介绍
** 0x0A 概率统计可视化教程
** 0x0B Flash已死,Flash不死
** 0x0C 最快的大数乘法算法
** 0x0D 深度SVG动画生成
** 0x0E why GNU grep is fast
0x01 达夫设备
https://www.cnblogs.com/lihuidashen/p/13253337.html
void send( int * to, int * from, int count){
int n = (count + 7 ) / 8 ;
switch (count % 8 ) {
case 0 : do { * to ++ = * from ++ ;
case 7 : * to ++ = * from ++ ;
case 6 : * to ++ = * from ++ ;
case 5 : * to ++ = * from ++ ;
case 4 : * to ++ = * from ++ ;
case 3 : * to ++ = * from ++ ;
case 2 : * to ++ = * from ++ ;
case 1 : * to ++ = * from ++ ;
} while ( -- n > 0 );
}
}
混合switch-case和do-while循环,我从来没用过这种写法,有点两种不同齿轮混合的味道。
0x02 switch+goto
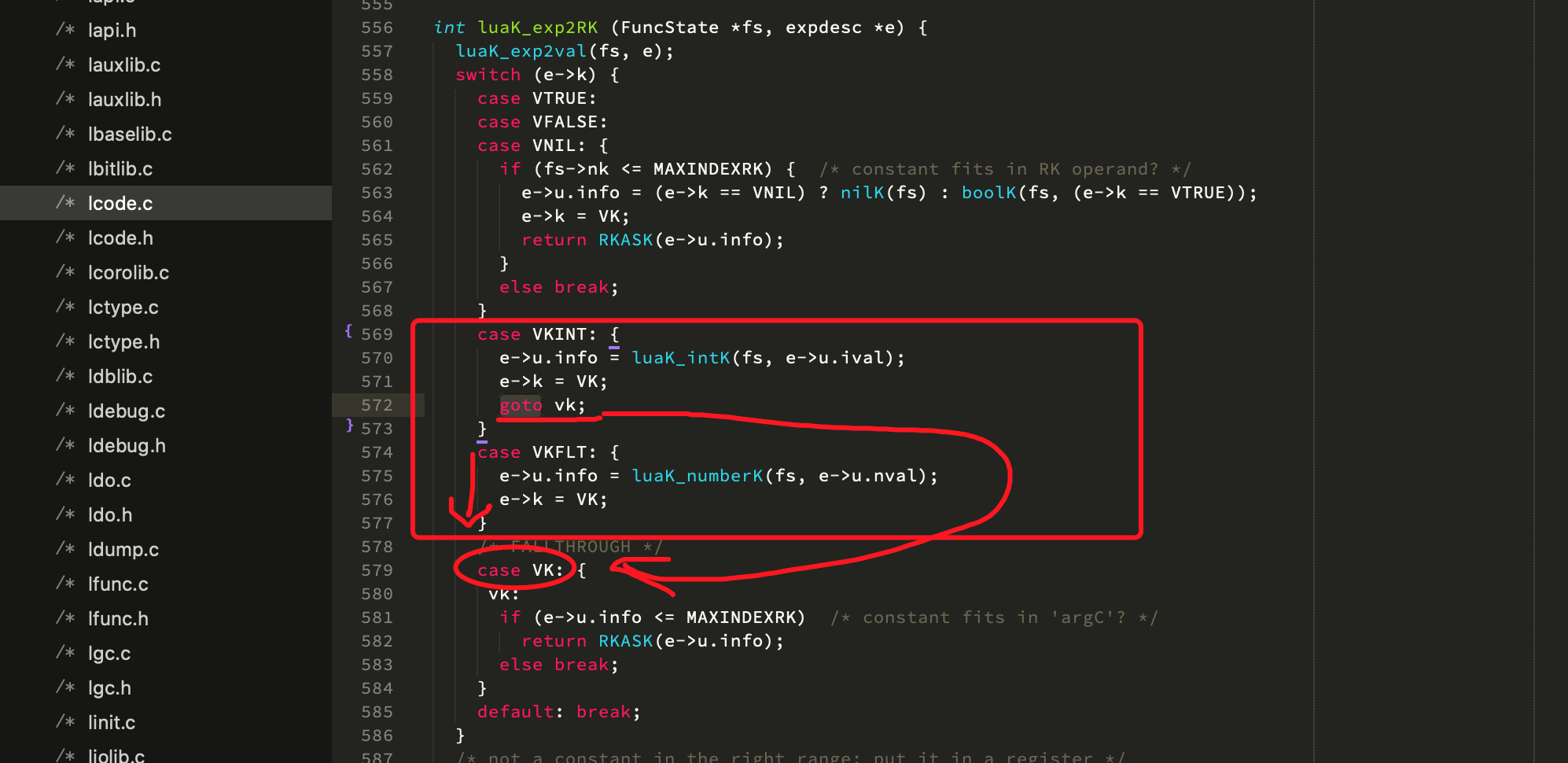
parser代码里常见到这种路径:switch-case里多个case分支的代码有重复部分,常见的把重复的部分作为一个独立的case,例如这里的VK 这个case,那么VKINT和VKFLT只是预处理部分和VK不同,就会用switch-case来做成两个case处理不同的部分,再goto到VK这个case。 只是switch-case本来就可以上一个case直接FALLTHROUGH到下一个case,因此VKFLT里面就不需要goto,但是VKINT里需要加个goto,否则会走 VKINT+VKFLT+VK 三处代码的合并逻辑,就不对了。
0x03 硬件加速
软件写多了,会发现很多物理世界的做法能解决很多看上去麻烦的问题。上周去了一家芯片设计小公司看,我们很多算法,他们可以把一些固定参数,固定流水的算法,直接设计进固化的芯片里。减少了用通用CPU指令写算法的时间消耗,非常高性能。当然,这是非通用芯片,都是定制用的。这个让我脑洞大开,我们被通用CPU限制了很多脑洞。整个算法就是一个指令输入数据,异步等待数据返回即可,算法代码变成了IO代码。硬件加速大概是这样:芯片定制 > FPGA > GPU > CPU,每一级都有数量级的性能差异,通用性则反过来。这就是那些做AI芯片是在干什么,所谓AI芯片,就是把深度神经网络的算法,把某些底层的算法控制流,直接设计到芯片的逻辑们控制流里去。
0x04 O(1)大数据传输
https://www.cnblogs.com/AllenMaster/p/13237362.html
Azure Data Box
Azure直接寄硬盘盒给客户,客户把需要上传到Azure的数据直接写硬盘,再把硬盘寄回给Azure,后者帮你直接把硬盘数据导入云存储。
涨见识了,这么做最“高效传输”。
0x05 C语言的异常跳转

这个是c里面setjmp和longjmp模拟异常跳转的代码,非常规控制流。不过和上面的那个“达夫设备”代码还是不一样。
0x06 非欧几里得引擎
github: https://github.com/HackerPoet/NonEuclidean
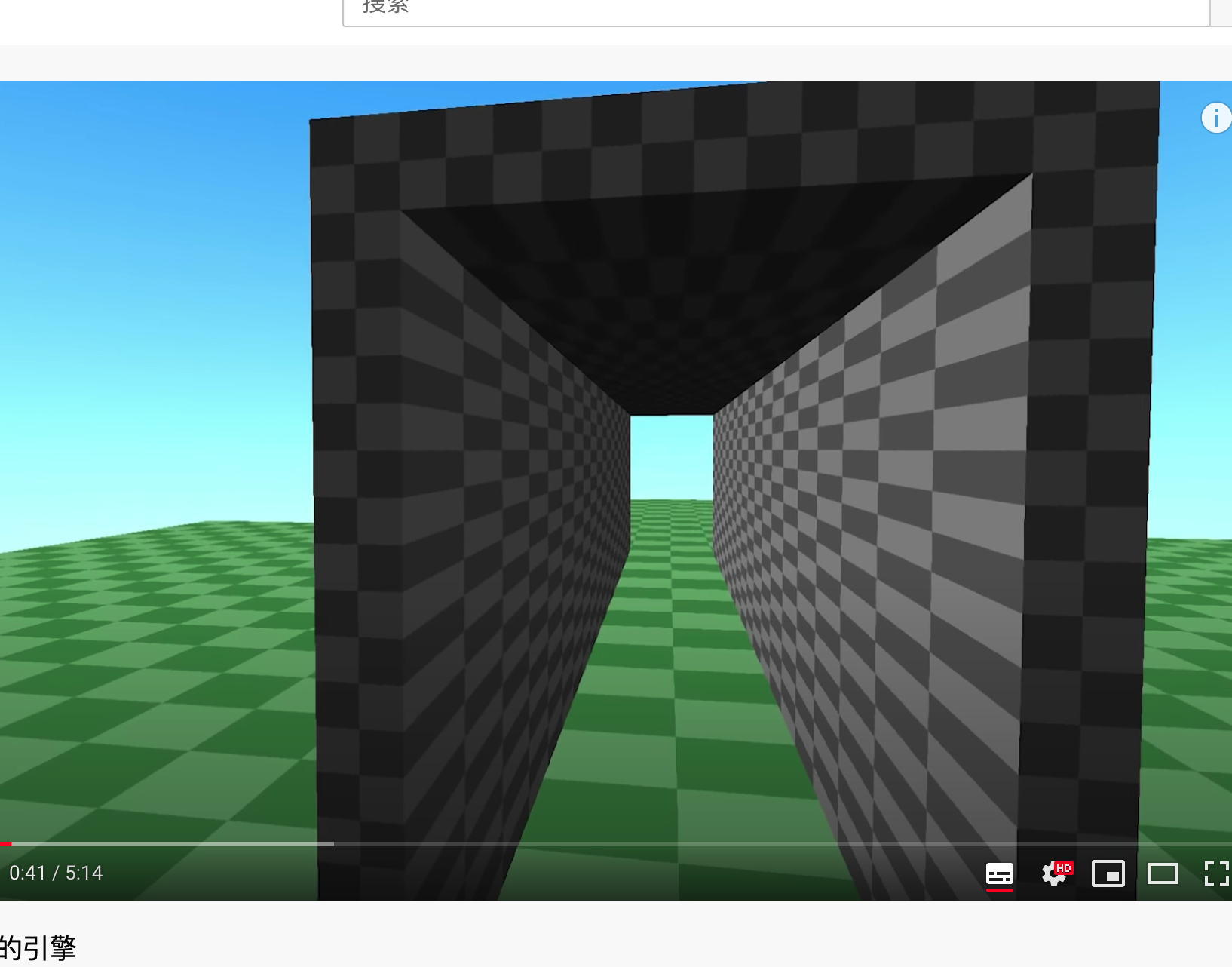

从外面看很短的墙,进去后很长。从外面看很长的墙,进去后看很短。在里面绕几圈后,外面的其他房子越变越大,反向绕几圈后,外面的房子越变越小。非欧几何的很多定理都跟欧几里得几何不一样。例如:三角形的内角和小于180度,或者三角形的内角和大于180度,两条平行线会相交等等。
A NonEuclidean rendering engine for Windows, written in C++ OpenGL. To see what this code is about, check out this video: https://youtu.be/kEB11PQ9Eo8
0x07 为什么现代软件开发令人伤心
https://www.roguelazer.com/2020/07/etcd-or-why-modern-software-makes-me-sad/
etcd 共识算法最早是为一个并不成功的项目CoreOS Container Linux编写的,并且提供了简单的HTTP API,这个作者用它写了很多项目。然后,自从K8S用了etcd之后,etcd的接口被加入了gRPC的复杂接口,内部实现也加了了很多侵入式的数据结构。作者认为,这之后etcd就变的不正交了,不再简洁友好。作者认为K8S是自从systemd之后又一个令系统变的复杂的系统,一个显著的特点就是它对etcd库本身的影响。此外,K8S迫使你编写一堆YAML配置系统,在一个Mesh里编写代码,令现代软件开发变的更糟糕,令人(特别是作者)伤心。
这就是作者写这篇文章的全部。一句话:作者不喜欢K8S,更不喜欢K8S影响了etcd项目,让它变得不再正交和简洁。
0x08 设计/内容/商业的交集=付费社区
https://subpixel.space/entries/come-for-the-network-pay-for-the-tool/

0x09 高阶初学者的系统设计介绍
Systems design for advanced beginners:
https://robertheaton.com/2020/04/06/systems-design-for-advanced-beginners/
0x0A 概率统计可视化教程
https://seeing-theory.brown.edu/basic-probability/cn.html
顺便记录下,有一天朋友发了个图说他买的棘轮螺丝套筒套件,他无聊排序了下,发现漏了,于是找卖家补发了货物:

我想起了这是个贝叶斯统计的好题材,出了个题:
- 一个棘轮螺丝套筒工厂,组装漏掉零件的概率是1%,组装不漏零件的概率是99%;
- 一个棘轮螺丝套筒图片识别AI,在零件丢失的情况下,检测成功的概率是90%,在零件不丢失的情况下,有5%的概率会误报;
- 现在,一个棘轮螺丝套筒套装被AI检测为漏装了零件,请问这个棘轮螺丝套筒实际漏装了零件的可能性多大?
0x0B Flash已死,Flash不死
http://www.flashgamehistory.com/
FLASH
GAMES
shaped the video game industry
Flash is dead. But the influence of Flash games on modern gameplay is inescapable.
0x0C 最快的大数乘法算法
https://www.quantamagazine.org/mathematicians-discover-the-perfect-way-to-multiply-20190411/

0x0D 深度SVG动画生成
https://github.com/alexandre01/deepsvg

0x0E why GNU grep is fast
作者回复:https://lists.freebsd.org/pipermail/freebsd-current/2010-August/019310.html
Summary:
- Use Boyer-Moore (and unroll its inner loop a few times).
- Roll your own unbuffered input using raw system calls. Avoid copying
the input bytes before searching them. (Do, however, use buffered
output. The normal grep scenario is that the amount of output is
small compared to the amount of input, so the overhead of output
buffer copying is small, while savings due to avoiding many small
unbuffered writes can be large.) - Don't look for newlines in the input until after you've found a match.
- Try to set things up (page-aligned buffers, page-sized read chunks,
optionally use mmap) so the kernel can ALSO avoid copying the bytes.
The key to making programs fast is to make them do practically nothing. 😉
--end--

 浙公网安备 33010602011771号
浙公网安备 33010602011771号