「算法笔记」后缀系列
2020 年写的 SA(已折叠)
一、定义
后缀数组(Suffix Array),简称 SA。
后缀数组 是一个通过对字符串的所有后缀经过排序后得到的数组。形式化的定义如下:
- 令字符串 \(S=S_1 S_2 \cdots S_n\),\(S[i\sim j]\) 表示 \(S\) 的子串,下标从 \(i\) 到 \(j\)。\(S\) 的 后缀数组 \(A\) 被定义为一个数组,内容是 \(S\) 的所有后缀经过字典排序后的起始下标。即,\(\forall 1<i\leq n\),有 \(S[A_{i-1}\sim n]<S[A_i\sim n]\) 成立。
例如 \(S=\text{banana\$}\) 有后缀(假设 \(\text{\$}\) 的字典序小于任何字母):

对所有后缀按字典序升序排序后:(可得 \(A=[7,6,4,2,1,5,3]\))

二、倍增算法求解
1. 一些定义
方便起见,我们定义:
-
\(\text{suffix}(i)\) 表示第 \(i\) 个位置开始的后缀,即 \(S[i\sim n]\)。
-
\(sa(i)\) 表示将所有后缀排序后排名为 \(i\) 的后缀的起始下标。即排名为 \(i\) 的后缀为 \(\text{suffix}(sa(i))\)。
-
\(rk(i)\) 表示以起始下标为 \(i\) 的后缀的排名,也就是 \(\text{suffix}(i)\) 的排名。显然有 \(sa(rk(i))=i,rk(sa(i))=i\)。
朴素的求后缀数组的方法是,直接对 \(n\) 个后缀进行排序,由于比较两个字符串是 \(\mathcal{O}(n)\) 的,所以排序是 \(\mathcal{O}(n^2\log n)\) 的,这些不再赘述。
2. 主要思路
倍增算法的主要思路是:对所有长度为 \(2^k\) 的字符串进行排序,并求出它们的排名(即 \(rk(i)\) 数组)。当 \(2^k\geq n\) 后,每个位置开始的长度为 \(2^k\) 的子串就相当于所有的后缀了,此时的 \(rk(i)\) 数组就是答案(此时这些子串一定都已经比较出大小,即 \(rk(i)\) 数组中没有相同的值)。
如何比较两个长度为 \(2^k\) 的串?先将所有的 \(S[i]\) 进行排序,然后每次通过 \(S[i\sim i+2^{k-1}-1]\) 的大小关系求出 \(S[i\sim i+2^k-1]\) 的大小关系(串的右端点省略了和 \(n\) 取最小值的操作)。
具体来说,假如当前我们已经把长度为 \(2^{k-1}\) 的子串排好序并求出了 \({rk'}(i)\)。那么长度为 \(2^k\) 的子串可以用两个长度为 \(2^{k-1}\) 的子串的排名作为关键字表示,记为二元组 \(({rk}'(i),{rk}'(i+2^{k-1}))\),以该二元组的第一部分为第一关键字,第二部分为第二关键字;当 \(i+2^{k-1}>n\) 时,则令 \(rk'(i+2^{k-1})\) 的值为 \(0\),因为其对应子串为空串,字典序最小。
得到这些二元组后,就可以将长度为 \(2^k\) 的子串进行排序,得到它们的 \(rk(i)\) 值。
3. 具体实现
用 sort 进行排序:\(\mathcal{O}(n\log^2 n)\)。
#include<bits/stdc++.h> #define int long long using namespace std; const int N=1e6+5; int n,m,sa[N],rk[N],t[N],p; char s[N]; bool cmp(int x,int y){ return rk[x]==rk[y]?rk[x+m]<rk[y+m]:rk[x]<rk[y]; } signed main(){ scanf("%s",s+1),n=strlen(s+1); for(int i=1;i<=n;i++) rk[i]=s[i],sa[i]=i; sort(sa+1,sa+1+n,cmp); for(int k=1;k<=n;k<<=1){ m=k,p=0,sort(sa+1,sa+1+n,cmp),memcpy(t,rk,sizeof(rk)); //t 是原先的 rk 数组。 for(int i=1;i<=n;i++) rk[sa[i]]=(t[sa[i]]==t[sa[i-1]]&&t[sa[i]+k]==t[sa[i-1]+k]?p:++p); //去重操作。若两个子串相同,它们对应的 rk 也需要相同。 } for(int i=1;i<=n;i++) printf("%lld%c",sa[i],i==n?'\n':' '); return 0; }
在刚刚的 \(\mathcal{O}(n\log^2 n)\) 做法中,用 sort 单次排序是 \(\mathcal{O}(n\log n)\) 的,若能 \(\mathcal{O}(n)\) 排序,就能 \(\mathcal{O}(n\log n)\) 计算后缀数组了。
考虑使用 基数排序。那么这个基数排序具体怎么实现呢?
现在我们已经得到了长度为 \(2^{k-1}\) 的子串的排名,需要计算长度为 \(2^k\) 的子串的排名。
定义 \(t(i)\) 表示 按第二关键字 排序后排名为 \(i\) 的后缀的起始位置,即 \(t(i)\) 满足以 \(t(i)+2^{k-1}\) 开头的长度为 \(2^{k-1}\) 的子串按字典序排列。\(cnt(i)\) 表示基数排序需要的桶。
假设我们已经求出了 \(t(i)\)。我们知道,\(t(i)\) 是已经以第二关键字排好序的,所以我们要做的就是,以第一关键字排序,并保持第二关键字的相对顺序不变,并把排序的结果存在 \(sa(i)\) 中。
实现二元组排序的方式是,把第一关键字放在桶里,然后按第二关键字的顺序拿出来。具体地:
- 首先用桶(即 \(cnt(i)\) 数组)统计第一关键字(也就是所有长度为 \(2^{k-1}\) 的子串)的每个排名的出现次数,并对其做前缀和,得到小于等于当前排名的子串个数。
- 同一个桶内的元素的顺序由第二关键字就决定。倒序枚举第二关键字的排名 \(i\),它对应的第一关键字的排名为 \(rk(t(i))\),其对应的桶为 \(cnt(rk(t(i)))\),那么 \(sa(cnt(rk(t(i))))=t(i)\),然后 \(cnt(rk(t(i)))=cnt(rk(t(i)))-1\)。我们倒着枚举倒着拿走桶中的元素,这样就能够维护第二关键字的相对顺序了。
时间复杂度:\(\mathcal{O}(n\log n)\)。
//Luogu P3809 #include<bits/stdc++.h> #define int long long using namespace std; const int N=1e6+5; int n,m,sa[N],rk[N],t[N],cnt[N],p,tot; char s[N]; void rsort(){ //基数排序,解释过了 for(int i=1;i<=m;i++) cnt[i]=0; for(int i=1;i<=n;i++) cnt[rk[i]]++; for(int i=1;i<=m;i++) cnt[i]+=cnt[i-1]; for(int i=n;i>=1;i--) sa[cnt[rk[t[i]]]--]=t[i]; } signed main(){ scanf("%s",s+1),n=strlen(s+1),m=max(n,(int)'z'); //m: 桶的大小 for(int i=1;i<=n;i++) rk[i]=s[i],t[i]=i; rsort(); for(int k=1;k<=n;k<<=1){ tot=p=0; for(int i=n-k+1;i<=n;i++) t[++tot]=i; //这些后缀的第二关键字为空串,因此排在最前面 for(int i=1;i<=n;i++) if(sa[i]-k>0) t[++tot]=sa[i]-k; //sa[i]-k>0,它可以作为别的子串第二关键字 rsort(),swap(t,rk); //swap(t,rk): 此时的 t 已经没用了,而我们还要更新 rk,所以 t 变为上一次的 rk 用来备份 for(int i=1;i<=n;i++) rk[sa[i]]=(t[sa[i]]==t[sa[i-1]]&&t[sa[i]+k]==t[sa[i-1]+k]?p:++p); } for(int i=1;i<=n;i++) printf("%lld%c",sa[i],i==n?'\n':' '); return 0; }
事实上,还有不常见的 DC3 算法,时间复杂度为线性,但常数比较大,实际运行时间与倍增法相当。
Tips:
//swap(t,rk) 有时非常慢!必要时 for(int i=1;i<=n;i++) swap(t[i],rk[i]); for(int i=1;i<=n;i++) rk[sa[i]]=(t[sa[i]]==t[sa[i-1]]&&t[sa[i]+k]==t[sa[i-1]+k]?p:++p); //sa[i]+k<=n&&sa[i-1]+k<=n,多组数据的时候要注意 //if(p==n) break; //一个小优化
Update:感觉基数排序的部分讲的还不太清楚,来补充一下(参考 tls 博客)。
先考虑一维的基数排序(假如我们要对 \(a\) 排序),我们记一个桶 \(c_i\) 表示值为 \(i\) 的 \(a_i\) 有多少个,然后对 \(c_i\) 做一遍前缀和,得到 \(\leq i\) 的数的个数。那么如果 \(a_i\) 互不相同的话,排名为 \(c_{a_i}\) 的数就是 \(a_i\)。而如果有 \(a_i\) 相同,则显然排名在 \((c_{a_i-1},c_{a_i}]\) 之间的数都等于 \(a_i\)。考虑从后往前扫一遍,每次将 \(a_i\) 的排名设为 \(c_{a_i}\) 并令 \(c_{a_i}\) 减 \(1\),这样所有相同的 \(a_i\) 都被赋上了一个不同的排名,并且对于相同的 \(a_i\),位置越靠后的排名越靠后,也就是我们对 \((a_i,i)\) 这个二元组排了一遍序。
考虑我们在刚才的基数排序中为什么要从后往前扫,因为这样一来如果有 \(a_i\) 相同的那么位置靠后的排名永远比位置靠前的排名高,也就是 按第二维降序 的顺序更新桶。那么二维也是一样的。
具体来说,我们要对 \(rk_i\) 按第二关键字排序,记 \(c_i\) 表示值为 \(i\) 的 \(rk_i\) 有多少个,然后对 \(c_i\) 做一遍前缀和,再记一个 \(t_i\) 表示按第二关键字排序后排名为 \(i\) 的后缀的起始位置,从后往前扫一遍,将普通情况下的“设 \(i\) 的排名为 \(cnt_{rk_i}\),再令 \(cnt_{rk_i}\) 减 \(1\)”,改为“设 \(t_i\) 的排名为 \(cnt_{rk_{t_i}}\),再令 \(cnt_{rk_{t_i}}\) 减 \(1\)”,也就是将 \(i\) 换成 \(t_i\)。
三、求最长公共前缀
求原串任意两个后缀的 最长公共前缀(LCP)。
1. 一些定义
对于后缀 \(\text{suffix}(i)\) 和 \(\text{suffix}(j)\),我们定义 \(\text{lcp}(i,j)=k\),其中 \(k\) 为满足 \(\forall 1\leq p\leq k,\text{suffix}(i)_p=\text{suffix}(j)_p\) 的最大值。
接下来再定义一些值:
-
\(\text{LCP}(i,j)=\text{lcp}(sa(i),sa(j))\),即排名为 \(i,j\) 的后缀的最长公共前缀。
-
\(height(i)=\text{LCP}(i-1,i)\),即排名为 \(i-1,i\) 的后缀的最长公共前缀。显然有 \(height(1)=0\)(排名为 \(1\) 的字符串和空串的 \(\text{lcp}\) 显然为 \(0\))。
-
\(h(i)=height(rk(i))\),即 \(\text{suffix}(i)\) 与它前一个排名的后缀的最长公共前缀。
我们的最终目的是求解 \(height(i)\) 数组,原因会在后面说明。
两个基本的等式:\(\text{LCP}(i,j)=\text{LCP}(j,i),\text{LCP}(i,i)=n-sa(i)+1\)。
2. LCP 的性质
在证明接下来的内容之前,先证明一个引理(性质 \(1\),称为 LCP Lemma)
\(\forall 1\leq i<k<j\leq n,\text{LCP}(i,j)=\min(\text{LCP}(i,k),\text{LCP}(k,j))\)
证明:设 \(p=\min(\text{LCP}(i,k),\text{LCP}(k,j))\),则有 \(\text{LCP}(i,k)\geq p,\text{LCP}(k,j)\geq p\)。
设 \(\text{suffix}(sa(i))=u,\text{suffix}(sa(k))=v,\text{suffix}(sa(j))=w\),则 \(u,v\) 的前 \(p\) 个字符相等,\(v,w\) 的前 \(p\) 个字符相等。这样得到 \(u,w\) 的前 \(p\) 个字符相等,即 \(\text{LCP}(i,j)\geq p\)。
我们考虑反证法。假如 \(\text{LCP}(i,j)\geq p+1\),则有 \(u_{p+1}=w_{p+1}\),由于排名 \(i<k<j\),那么 \(u_{p+1}=v_{p+1}=w_{p+1}\),这与条件矛盾。故 \(\text{LCP}(i,j)=p\)。
推论:根据上面的引理,可以得到一个推论(性质 \(2\),称为 LCP Theorem):
\(\forall 1\leq i<j\leq n,\text{LCP}(i,j)=\min\limits_{i<k\leq j}\text{LCP}(k-1,k)\)
证明:结合引理可得:\(\text{LCP}(i,j)=\min(\text{LCP}(i,i+1),\text{LCP}(i+1,j))\)。
可以将 \(\text{LCP}(i+1,j)\) 继续拆下去,正确性显然。
根据这个推论,由于 \(height(i)=\text{LCP}(i-1,i)\),所以 \(\text{LCP}(i,j)=\min\limits_{i<k\leq j}height(k)\)。如果能求出 \(height\) 数组,那么 \(\text{lcp}\) 问题就转化为了一个 区间最小值问题,显然可以通过 ST 表 解决。
这也是求解 \(height(i)\) 数组的原因。
4. 最重要的性质
通过上述分析,我们还是没法求 \(height\) 数组。于是我们要证明一个 最重要的性质:
\(h(i) \geq h(i-1)-1\)
证明:
-
若 \(h(i-1)=0\),结论显然成立。
-
否则在 \(\text{suffix}(i-1)\) 与它前一个排名的后缀的最长公共前缀的基础上,去掉 第一个字符,就找到了一个后缀与 \(\text{suffix}(i)\) 的最长公共前缀 \(\geq h(i-1)-1\)。进而有 \(height(rk(i))\geq height(rk(i-1))-1\),即 \(h(i)\geq h(i-1)-1\)。
5. 代码实现
求 \(height\) 数组的代码:
for(int i=1,k=0;i<=n;i++){ if(k) k--; //h[i]>=h[i-1]-1 int j=sa[rk[i]-1]; //h[i]=height[rk[i]]=LCP(rk[i]-1,rk[i])=lcp(sa[rk[i]-1],sa[rk[i]])=lcp(sa[rk[i]-1],i) while(i+k<=n&&j+k<=n&&s[i+k]==s[j+k]) ++k; //因为 h[i]>=h[i-1]-1,所以可以直接从 k 开始算 ht[rk[i]]=k; //h[i]=height[rk[i]], 这里 height 简写成了 ht }
\(k\) 不会超过 \(n\),最多减 \(n\) 次,所以最多加 \(2n\) 次,总复杂度就是 \(\mathcal{O}(n)\)。
后缀数组求 \(\text{lcp}\) 完整代码:
#include<bits/stdc++.h> #define int long long using namespace std; const int N=1e5+5; int n,m,q,sa[N],rk[N],t[N],cnt[N],p,tot,ht[N],f[N][30],x,y; char s[N]; void rsort(){ for(int i=1;i<=m;i++) cnt[i]=0; for(int i=1;i<=n;i++) cnt[rk[i]]++; for(int i=1;i<=m;i++) cnt[i]+=cnt[i-1]; for(int i=n;i>=1;i--) sa[cnt[rk[t[i]]]--]=t[i]; } void getht(){ //求 height 数组 for(int i=1,k=0;i<=n;i++){ if(k) k--; int j=sa[rk[i]-1]; while(i+k<=n&&j+k<=n&&s[i+k]==s[j+k]) ++k; ht[rk[i]]=k; } } void getst(){ for(int i=1;i<=n;i++) f[i][0]=ht[i]; for(int j=1;j<=log2(n);j++) for(int i=1;i+(1<<j)-1<=n;i++) f[i][j]=min(f[i][j-1],f[i+(1<<(j-1))][j-1]); } int query(int x,int y){ if(x==y) return n-x+1; x=rk[x],y=rk[y]; //将 lcp 变为 LCP if(x>y) swap(x,y);x++; //LCP(i,j)=height(k) (i<k<=j),k 取不到 i int k=log2(y-x+1); return min(f[x][k],f[y-(1<<k)+1][k]); } signed main(){ scanf("%s",s+1),n=strlen(s+1),m=max(n,(int)'z'); for(int i=1;i<=n;i++) rk[i]=s[i],t[i]=i; rsort(); for(int k=1;k<=n;k<<=1){ tot=p=0; for(int i=n-k+1;i<=n;i++) t[++tot]=i; for(int i=1;i<=n;i++) if(sa[i]-k>0) t[++tot]=sa[i]-k; rsort(),swap(t,rk); for(int i=1;i<=n;i++) rk[sa[i]]=(t[sa[i]]==t[sa[i-1]]&&t[sa[i]+k]==t[sa[i-1]+k]?p:++p); } getht(),getst(),scanf("%lld",&q); while(q--){ scanf("%lld%lld",&x,&y); printf("%lld\n",query(x,y)); } return 0; }
(附写到一半然后被删掉的 height 数组的应用,建议跳过这个直接去看论文 qwq)
四、其他应用
先讲一下后缀数组求一个子串在原串中的出现次数:
求 \(s\) 的子串 \(s[l\sim r]\) 在 \(s\) 中的出现次数,就等价于求有多少个 \(\text{suffix}(j)\) 满足 \(\text{lcp}(j,l)\geq r-l+1\)。
考虑将 \(n\) 个后缀放在字典序排名数组 \(rk_i\) 上,显然对于所有 \(\text{lcp}(j,l)\geq r-l+1\),它们的 \(rk\) 值应道是一段连续的区间 \([L,R]\),而这个区间又可以通过二分 + ST 表求出。具体来说,二分找到最小的满足 \(\min\limits_{i=t+1}^{rk_l} height_i\geq r-l+1\) 的 \(t\) 记为该区间的左端点 \(L\);同理找到最大的满足 \(\min\limits_{i=rk_l+1}^t height_i\geq r-l+1\) 的 \(t\) 即为该区间的左端点 \(R\)。然后返回 \(R-L+1\) 即可,正确性显然。
时间复杂度 \(\mathcal O(\log n)\)(不考虑预处理的话)。
其他的可参考 后缀数组 (SA) - OI Wiki 以及 论文。
Upd on 2021.7.27:更新了一些应用,详见 「笔记」2021.7.27 后缀数组,密码可以找我要鸭。
2020 年写的 SAM(已折叠)
一、引入
顾名思义,后缀自动机(Suffix Automaton,简称 SAM)是一个 自动机。这里的自动机指的是确定有限状态自动机(DFA)。
DFA?DFA 的作用就是识别字符串。可以把一个 DFA 看成一个 边上带有字符 的有向图。
图中的节点就是 DFA 中的状态,边就是状态间的转移(DFA 的转移函数)。
DFA 存在一个指定的 起始状态(对应图的起始节点),以及多个 接受状态。
-
一个 DFA 读入字符串 \(S\) 后,会从起始节点开始,第 \(i\) 次沿着字符 \(S_i\) 的转移边走。
-
读入完成后,若 \(S\) 最后位于一个接受状态,则称 DFA 接受 \(S\),否则称 DFA 不接受 \(S\)(转移过程中没有出边,也称 DFA 不接受 \(S\))
其实就是,从起始节点出发,每次沿着与当前字符对应的边走,走完了,并且最后位于可接受的节点上,那就 ok,否则就是不 ok。
二、定义
后缀自动机 是可以且仅可以接受一个母串 \(S\) 的后缀的 DFA。SAM Drawer。
SAM 的结构包含两部分:有向单词无环图(DAWG,它是一个 DAG)以及一棵树(parent 树),它们的节点集合相同。
目标:最小化节点集合大小(SAM 是满足是可以接受 \(S\) 所有后缀的 最小的 DFA)。
1. Endpos 集合
先引入一个概念:子串的结束位置集合 Endpos(或者称其为 Right 集合)。在下文写作 \(\text{end}\)。
记 \(S\) 的一个子串 \(T\) 在 \(S\) 中出现的 结束位置 集合为 \(\text{end}(T)\)。
举个栗子,比如 \(S=\text{banana}\),则 \(\text{end}(\text{ana})=\{4,6\}\)。
对于两个子串 \(t_1,t_2\),若 \(\text{end}(t_1)=\text{end}(t_2)\),则 \(t_1,t_2\) 属于一个 \(\text{end}\) 等价类。
Endpos 集合的性质:对于非空子串 \(t_1,t_2\ (|t_1|\leq|t_2|)\):
-
若 \(\text{end}(t_1)=\text{end}(t_2)\),则 \(t_1\) 在 \(S\) 中每次出现,都是以 \(t_2\) 的后缀形式存在。
-
若 \(t_1\) 为 \(t_2\) 的后缀,则 \(\text{end}(t_2)\subseteq \text{end}(t_1)\);否则 \(\text{end}(t_2)\cap \text{end}(t_1)=\varnothing\)。
-
一个 \(\text{end}\) 等价类中的串为 某个前缀 的 长度连续的后缀。
- \(\text{end}\) 等价类的个数为 \(\mathcal{O}(n)\) 级别。
根据合并等价类的思想,我们将 Endpos 集合完全相同的子串合并到同一个节点。这样一来大大优化了时间和空间复杂度。
\(\text{end}\) 的等价类构成了 SAM 的状态集合。即 SAM 的每一个节点表示的「Endpos 集合相等的子串」的集合。
2. DAWG
DAWG 是 DAG,其中每个 节点 表示一个或多个 \(S\) 的子串。特别地,起始节点对应空串 \(\varnothing\)。
每条转移边上有且仅有一个字符。从起始节点出发,沿着转移边移动,则每条 路径 都会唯一对应 \(S\) 的一个子串。
SAM 维护的是子串,即 SAM 的 DAG 上跑出来的串都是原串的子串。
到达某节点的路径可能不止一条。一个节点对应一些字符串的集合,集合的元素对应这些路径。
不存在可代表同一子串的两个不同状态,因为每个子串唯一地对应一条路径。
规定:除起始节点外,每个节点都是 不同的 \(\text{end}\) 等价类,对应该等价类内子串的集合。
设 \(u\) 的长度最小、最大的子串为 \(\min(u)\) 以及 \(\max(u)\)。
根据 Endpos 集合的性质,每个节点所代表的字符串是 \(S\) 某个前缀 的 长度连续的后缀,则状态 \(u\) 中所有的字符串都是 \(\max(u)\) 的不同后缀,且字符串长度覆盖区间 \([|\min(u)|,|\max(u)|]\)。
3. parent 树
定义:定义 \(u\) 的 parent 指针指向 \(v\),当且仅当 \(|\min(u)|=|\max(v)|+1\),且 \(v\) 代表的子串均为 \(u\) 子串的后缀,记作 \(\text{next}(u)=v\)。也可以将 parent 指针称为后缀链接。
显然,所有节点沿着 parent 指针向前走,都会走到 DAWG 的起始节点(即代表空串的节点。走的过程中串的长度越来越短,总会走到空串)。因此以 parent 指针为边,所有节点组成了一棵树,称为 parent 树。
parent 指针的性质:
-
若 \(|\min(u)|=1\),则 \(\text{next}(u)\) 为起始节点。
-
\(\text{next}(u)\) 所对应的字符串长度严格小于 \(u\) 所表示的字符串。
-
\(\text{end}(u)\subsetneq\text{end}(\text{next}(u))\)。(注意这里是 \(\subsetneq\) 不是 \(\subseteq\),因为若两者相同,那么 \(u\) 和 \(\text{next}(u)\) 应该被合并为一个节点)
-
\(\max(\text{next}(u))\) 为 \(\min(u)\) 的次长后缀(最长为其本身)。
parent 树的性质:
-
在 parent 树中,子节点的 \(\text{end}\) 集合一定是父亲的真子集,即 \(\text{end}(u)\subsetneq\text{end}(\text{next}(u))\)。
-
从节点 \(v_0\) 沿着 parent 指针遍历,总会到达起始节点。设经过的节点为 \(v_1,v_2,\cdots,v_k\)。可以得到一个互不相交的区间 \([|\min(v_i)|,|\max(v_i)|]\),它们的并集形成了连续的区间 \([0,|\max(v_0)|]\),代表 \(S\) 长度为 \(|\max(v_0)|\) 的前缀的所有后缀。
parent 树本质上是 Endpos 集合构成的一棵树,体现了 Endpos 的包含关系。
注:节点 \(u\) 对应着具有相同 Endpos 的等价类,\(\text{end}(u)\) 指的是节点 \(u\) 对应的等价类的 Endpos 集合。
4. 小结
-
\(S\) 的子串可根据结束位置 Endpos 划分为若干个 \(\text{end}\) 等价类。
-
DAWG 中,每个节点表示一个或多个 \(S\) 的子串。除起始节点外,每个节点都是 不同的 \(\text{end}\) 等价类,对应该等价类内子串的集合。
- 每个节点所代表的字符串是 \(S\) 某个前缀 的 长度连续的后缀。
-
对于节点 \(u\),设 \(u\) 的长度最小、最大的子串为 \(\min(u)\) 以及 \(\max(u)\)。
-
对于两个节点 \(u,v\),\(\text{next}(u)=v\),当且仅当 \(|\min(u)|=|\max(v)|+1\),且 \(v\) 代表的子串均为 \(u\) 子串的后缀。
-
以 parent 指针为边,所有节点组成了一棵树(根节点为 DAWG 的起始节点),称为 parent 树。
可能讲的不是很清楚,摘录一下 Dls 博客 里的内容,方便理解 Parent Tree(进行了整理,应该好懂些):
我们知道,SAM 里的每个节点都代表了一堆 Endpos 集合相同的子串。容易发现,对于越短的子串,其 Endpos 集合往往越大。更具体地,若 \(t_1\) 为 \(t_2\) 的后缀,则 \(|\text{end}(t_1)|\geq |\text{end}(t_2)|\)。当且仅当取得等号时,\(t_1,t_2\) 会被压缩到同一个节点中。
而对于 \(t_2\) 的每一个后缀,一定有一个分界点,使得对于长度 \(\geq\) 该分界点的后缀,它和 \(t_2\) 的 Endpos 集合 相同;而长度 \(<\) 该分界点的后缀,因为短,所以有机会可以在 \(S\) 中出现更多次,Endpos 集合会更大,于是就和 \(t_2\) 分开了。因此:每个节点 \(p\) 中存储的一定是一堆长度连续的子串,且短的串是长的串的后缀。
对于 SAM 的每个节点都能找到一个这样的“分界点”。并且每个节点都对应了一个唯一的“分界点”。而如果 \(t_1\) 是 \(t_2\) 的一个后缀且没有和 \(t_2\) 分在一个节点中,那么 \(t_1\) 也可能成为别的子串的后缀(如 \(\text{ab}\) 既可以是 \(\text{cab}\) 的后缀,也可以是 \(\text{zab}\) 的后缀)。这样我们看到:长的串只能“对应”唯一的一个短的串,而短的串可以“对应”多个长的串,如果将“短的串”视为“长的串”的父亲,这就构成了一棵严格的树形结构。我们称为 parent 树。
这时我们发现,一个节点所代表的子串中最短的,就是它在 parent 树上的父亲所代表的的子串中最长长度的 \(+1\)。因此对每个节点都只记录最长的子串长度即可。
三、构建 SAM
SAM 的构建使用 增量法:通过 \(S\) 的 SAM 求出 \(S+c\) 的 SAM(\(c\) 为一个字符)。
加入字符 \(c\) 后,子串只增加了 \(S+c\) 的后缀,已有的子串不受影响。
\(S+c\) 的某些后缀可能在 \(S\) 出现过,在 SAM 中有其对应的节点。
SAM 中一个串只能对应一个节点,需考虑将它们对应到相应节点上。
多看几遍应该就能懂了 QAQ。
1. 初始化与判断
设此前表示 \(S\) 的节点为 \(p\)。
串 \(S+c\) 不可能出现在 \(S\) 中,它一定被对应到新节点上。设新节点为 \(u\),那么 \(|\max(u)|=|S+c|=|\max(p)|+1\)。
考虑如何判断 \(S+c\) 的后缀是否在 \(S\) 出现过。\(S+c\) 的后缀 \(=\) \(S\) 的后缀 \(+\) \(c\),判断 \(S+c\) 的后缀是否在 \(S\) 的后缀出现过,等价于判断 \(S\) 的后缀 有无转移边 \(c\)。
若 \(S\) 的某后缀有转移边 \(c\),那么它一定是新串的后缀,且说明 \(S+c\) 的该后缀在 \(S\) 中出现过。
根据 parent 树的性质,从节点 \(p\) 沿着 parent 指针遍历到达起始节点,等价于按长度递减遍历 \(S\) 的所有后缀。
从节点 \(p\) 沿着 parent 指针遍历,找到第一个有转移边 \(c\) 的节点 \(p'\)。
只需找到 \(p'\) 即可,因为 parent 树上 \(p'\) 的祖先代表的串,均为 \(p'\) 的后缀。它们对应的串的长度小于 \(p'\) 所表示的串,一定也有转移 \(c\)。
int p=lst,x=lst=++tot; //新建一个节点 x。此前表示 S 的节点为 p。 sz[x]=1,len[x]=len[p]+1; //sz(i) 表示节点 i 所代表的 Endpos 集合的大小。len(i) 表示 |max(i)|,即节点 i 长度最大的子串的长度。 //ch[p][c]=q 表示 p 经过转移边 c 后到 q while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p]; //这里的 fa(u)=v 即上文中的 next(u)=v(fa(u) 其实就是 u 在 parent 树上的父亲)。从节点 p 沿着 parent 指针遍历到达起始节点,等价于按长度递减遍历 S 的所有后缀。从节点 p 沿着 parent 指针遍历,找到第一个有转移边 c 的节点 p′。
2. 分类讨论
接下来对 \(S+c\) 的后缀在 \(S\) 中有无出现进行讨论。\(u\) 和 \(p'\) 的定义同上文。
(1)\(S+c\) 的所有后缀在 \(S\) 中 均未出现。
直接将 \(u\) 的 parent 指针指向起始状态。此时 \(u\) 表示 \(S+c\) 的所有后缀 \([1,|S+c|]\)。
if(!p){fa[x]=1;return ;} //S 中不存在子串 为 S+c 的后缀,直接将新节点的 parent 指针指向起始节点(起始节点标号为 1)。
(2)\(S+c\) 的某后缀在 \(S\) 中 出现过。设 \(p'\) 经过转移边 \(c\) 后到达节点 \(q\)(下同)。有 \(|\max(q)|=|\max(p')|+1\)。
则 \(q\) 代表的所有串,以及 parent 树上它的祖先代表的串,均为 \(S+c\) 的后缀。
\(\max(q)\) 为 \(S+c\) 的后缀,应有 \(\text{next}(u)=q\)。
此时 \(u\) 表示 \(S+c\) 的后缀 \([|\max(q)|+1,|S+c|]\)。
//S 中存在子串 为 S+c 的后缀,且 p' 经过转移边 c 后到达节点 q,有 |max(q)|=|max(p')|+1。 int q=ch[p][c],Q; //q 表示 p' 经过转移边 c 后到达的节点,Q 在下文会解释。 if(len[q]==len[p]+1){fa[x]=q;return ;} //q 代表的所有串,以及 parent 树上它的祖先代表的串,均为 S+c 的后缀。应有 next(u)=q,此时 u 表示 S+c 的后缀 [|max(q)|+1,|S+c|]。
(3)\(S+c\) 的某后缀在 \(S\) 中 出现过。有 \(|\max(q)|\neq|\max(p')|+1\)。
首先有 \(|\max(q)|>|\max(p')|+1\)(\(p'\) 经过转移边 \(c\) 可转移到 \(q\),\(|\max(q)|<|\max(p')|+1\) 不成立)。
但 \(q\) 中长度 小于等于 \(|\max(p')|+1\) 的串,及 parent 树上它的祖先代表的串,为 \(S+c\) 的后缀。
考虑将 \(q\) 拆成 \(S+c\) 的后缀部分,和非 \(S+c\) 的部分。
设将 \(q\) 的 \(S+c\) 的后缀部分放入节点 \(q'\) 中,其余的保留在 \(q\) 中。
\(q'\) 应继承 \(q\) 的转移,因为 \(q'\) 中的串与 新的 \(q\) 的串 为后缀关系(新的 \(q\) 指原来的 \(q\) 中非 \(S+c\) 的部分。为后缀关系是因为,上文中说过每个节点所代表的串是某个前缀长度连续的后缀),转移同样字符后也为后缀关系。
显然 \(|\max(q')|=|\max(p')|+1\)。
\(q'\) 代表的子串均为 \(q\) 的后缀。有 \(\text{next}(q')=\text{next}(q)\)。
又因为 \(|\min(q)|=|\max(q')|+1\),则 \(\text{next}(q)=q'\)。
\(q'\) 代表的所有串,及 parent 树上它的祖先代表的串,均为 \(S+c\) 的后缀。应有 \(\text{next}(u)=q'\),此时 \(u\) 代表 \(S+c\) 的后缀 \([|\max(q')|+1,|S+c|]\)。
最后枚举所有 可以转移到 原来的 \(q\) 的比 \(p'\) 还短的 \(S\) 的后缀,将其指向 \(q'\)。(\(p'\) 应转移到 \(q'\),则比 \(p'\) 的串还短的后缀也应转移到 \(q'\))
应转移到 新的 \(q\) 的后缀 的转移不会被修改。
//S 中存在子串 为 S+c 的后缀,但 |max(q)|!=|max(p')|+1。 Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q])); //将 q 拆成 S+c 的后缀部分,和非 S+c 的部分。将 q 的 S+c 的后缀部分放入节点 Q 中,其余的保留在 q 中。Q 应继承 q 的转移,因为 Q 中的串与 新的 q 的串 为后缀关系,转移同样字符后也为后缀关系。 fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; //Q 代表的串均为 q 的后缀。显然有 next(Q)=next(q),next(q)=Q。同时应有 next(u)=Q,此时 u 代表 S+c 的后缀 [|max(Q)|+1,|S+c|]。 while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p]; //最后枚举所有 可以转移到 原来的 q 的比 p' 还短的 S 的后缀,将其指向 Q。从 p' 开始沿着 parent 指针遍历,等价于按长度递减遍历比 p' 长度更短的 S 的所有后缀。
3. 代码
我终于会敲 SAM 板子啦!
void insert(int c){ //通过 S 的 SAM 求出 S+c 的 SAM int p=lst,x=lst=++tot; //新建一个节点 x(上文中的 u)。此前表示 S 的节点为 p。 sz[x]=1,len[x]=len[p]+1; //sz(i) 表示节点 i 所代表的 Endpos 集合的大小。len(i) 表示 |max(i)|,即节点 i 长度最大的子串的长度。 //ch[p][c]=q 表示 p 经过转移边 c 后到 q while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p]; //这里的 fa(u)=v 即上文中的 next(u)=v(fa(u) 其实就是 u 在 parent 树上的父亲)。从节点 p 沿着 parent 指针遍历到达起始节点,等价于按长度递减遍历 S 的所有后缀。从节点 p 沿着 parent 指针遍历,找到第一个有转移边 c 的节点 p′。 if(!p){fa[x]=1;return ;} //S 中不存在子串为 S+c 的后缀,直接将新节点的 parent 指针指向起始节点(起始节点标号为 1)。 //S 中存在子串 为 S+c 的后缀,且 p' 经过转移边 c 后到达节点 q,有 |max(q)|=|max(p')|+1。 int q=ch[p][c],Q; //q 表示 p' 经过转移边 c 后到达的节点。 if(len[q]==len[p]+1){fa[x]=q;return ;} //q 代表的所有串,以及 parent 树上它的祖先代表的串,均为 S+c 的后缀。应有 next(u)=q,此时 u 表示 S+c 的后缀 [|max(q)|+1,|S+c|]。 //S 中存在子串 为 S+c 的后缀,但 |max(q)|!=|max(p')|+1。 Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q])); //将 q 拆成 S+c 的后缀部分,和非 S+c 的部分。将 q 的 S+c 的后缀部分放入节点 Q 中,其余的保留在 q 中。Q 应继承 q 的转移,因为 Q 中的串与 新的 q 的串 为后缀关系,转移同样字符后也为后缀关系。 fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; //Q 代表的串均为 q 的后缀。显然有 next(Q)=next(q),next(q)=Q。同时应有 next(u)=Q,此时 u 代表 S+c 的后缀 [|max(Q)|+1,|S+c|]。 while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p]; //最后枚举所有 可以转移到 原来的 q 的比 p' 还短的 S 的后缀,将其指向 Q。从 p' 开始沿着 parent 指针遍历,等价于按长度递减遍历比 p' 长度更短的 S 的所有后缀。 }
四、复杂度
可以证明:
-
对于一个长度为 \(n\ (n\geq 2)\) 的字符串 \(S\),它的 SAM 的状态数 \(\leq 2n−1\)。
-
对于一个长度为 \(n\ (n\geq 3)\) 的字符串 \(S\),它的 SAM 的转移数 \(\leq 3n−4\)。
SAM 的 空间复杂度:
-
写成
int ch[N<<1][M](其中 \(N\) 为状态数,\(M\) 为字符集大小):空间 \(\mathcal{O}(n|\sum|)\),查询时间 \(\mathcal{O}(1)\)。 -
字符集较大时,可写成
map<int,int>ch[N<<1],空间 \(\mathcal{O}(n)\),查询时间 \(\mathcal{O}(\log|\sum|)\)。
构建 SAM 的 时间复杂度:均摊 \(\mathcal{O}(n)\)。
五、模板
Luogu P3804 【模板】后缀自动机 (SAM)。
题目大意:给定一个只包含小写字母的字符串 \(S\),求 \(S\) 的所有出现次数不为 \(1\) 的子串的出现次数乘上该子串长度的最大值。\(|S|\leq 10^6\)。
Solution:建出 SAM 后在 parent 树上 DP 即可。
#include<bits/stdc++.h> using namespace std; const int N=2e6+5,M=30; int n,lst=1,tot=1,cnt,hd[N],to[N],nxt[N],ch[N][M],len[N],fa[N],sz[N]; //注意 1 为起始节点编号,所以这里 lst 和 tot 初值为 1 long long ans; char s[N]; void add(int x,int y){ to[++cnt]=y,nxt[cnt]=hd[x],hd[x]=cnt; } void insert(int c){ int p=lst,x=lst=++tot; sz[x]=1,len[x]=len[p]+1; //sz(i) 表示节点 i 所代表的 Endpos 集合的大小,即所对应的字符串集出现的次数 while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p]; if(!p){fa[x]=1;return ;} int q=ch[p][c],Q; if(len[q]==len[p]+1){fa[x]=q;return ;} Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q])); fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p]; } void dfs(int x,int fa){ for(int i=hd[x];i;i=nxt[i]){ int y=to[i]; if(y==fa) continue; dfs(y,x),sz[x]+=sz[y]; } if(sz[x]!=1) ans=max(ans,1ll*sz[x]*len[x]); } signed main(){ scanf("%s",s+1),n=strlen(s+1); for(int i=1;i<=n;i++) insert(s[i]-'a'); for(int i=2;i<=tot;i++) add(fa[i],i); //建出 parent 树 dfs(1,0),printf("%lld\n",ans); return 0; }
为了减小常数,有时我们可以用“基数排序”代替树形 DP。我们知道,长度短的子串是长度长的子串的父亲,也即 \(len\) 值小的节点是 \(len\) 值大的节点的父亲。我们按 \(len\) 值从小到大对节点排个序,就得到了整棵树从树根到树叶的拓扑序。把这个拓扑序倒过来,for 循环一遍,就相当于树形 DP 啦。
#include<bits/stdc++.h> using namespace std; const int N=2e6+5,M=30; int n,lst=1,tot=1,ch[N][M],len[N],fa[N],sz[N],cnt[N],id[N]; //数组开两倍! long long ans; char s[N]; vector<int>v[N]; void insert(int c){ int p=lst,x=lst=++tot; sz[x]=1,len[x]=len[p]+1; while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p]; if(!p){fa[x]=1;return ;} int q=ch[p][c],Q; if(len[q]==len[p]+1){fa[x]=q;return ;} Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q])); fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p]; } signed main(){ scanf("%s",s+1),n=strlen(s+1); for(int i=1;i<=n;i++) insert(s[i]-'a'); for(int i=1;i<=tot;i++) cnt[len[i]]++; for(int i=1;i<=tot;i++) cnt[i]+=cnt[i-1]; for(int i=1;i<=tot;i++) id[cnt[len[i]]--]=i; for(int i=tot,x;i>=1;i--) x=id[i],sz[fa[x]]+=sz[x]; for(int i=1;i<=tot;i++) if(sz[i]>1) ans=max(ans,1ll*sz[i]*len[i]); printf("%lld\n",ans); return 0; }
六、性质
SAM 的性质:


同时后缀自动机还有一些有用的性质:
-
反串的 SAM 的 parent 树就是后缀树。
- 正串的 SAM 维护的是原字符串所有前缀的后缀(可以考虑 SAM 增量法的构造过程)。那么同理,反串的 SAM,维护的就是所有后缀的前缀,可以得到所有后缀构成的 Trie(压缩后),即后缀树。
- 感性理解:parent 树中,父亲是孩子的最长后缀(Endpos 不同),而把串反过来后,parent 树就满足,父亲是孩子的最长前缀(Beginpos 不同)。观察压缩后缀树的定义,Beginpos 相同的两个串才能被压缩,所以 SAM 和后缀树是有异曲同工之妙的。
-
两个串的最长公共后缀的长度,等于这两个串所代表的点在 parent 上 LCA 的 \(len\) 值。这是因为,一个串对应节点的祖先节点都是它的后缀,且深度越大长度越长。
七、简单应用
可参考 后缀自动机 (SAM) - OI Wiki 和 这个。其实这里算是搬运 qwq。
一些套路:SAM 的实质为 DAG,可以尝试是否能利用 DP 求解。
有些题目是基于 SAM 的性质的。比如“子串相关”的问题,不妨想想“从起始节点出发,每条路径唯一对应 \(S\) 的一个子串”,或许会有所帮助。
求不同子串个数:Problem(\(2\) 种方法)
-
不同子串个数等于从起始节点开始的不同路径条数。令 \(d_i\) 表示从节点 \(i\) 开始的路径数量,\(E\) 表示 DAWG 的边集,则 \(d_i=1+\sum_{(i,j)\in E} d_j\)。
-
parent 树中,每个节点对应的子串数量是 \(len(i)-len(\text{next}(i))\),对所有节点求和即可。
所有不同子串的总长度:
-
考虑不同子串数量 \(d_i\) 和总长度 \(ans_i\),同样 DP 求解。
-
每个节点对应的后缀长度为 \(\frac{len(i)\times (len(i)+1)}{2}\),减去其 \(\text{next}\) 节点的对应值就是改节点的贡献,对所有节点求和即可。
字典序第 k 小子串:Problem。
字典序第 \(k\) 小的子串对应 SAM 中字典序第 \(k\) 小的路径。计算出每个节点的路径数后,可以从 SAM 的根找到第 \(k\) 小的路径。
字典序最小的循环移位:
串 \(S+S\) 包含 \(S\) 的所有循环移位作为子串。
问题转化为在 \(S+S\) 对应的 SAM 上找最小的长度为 \(|S|\) 的路径。从起始节点出发,贪心地访问最小的字符即可。
两个串的最长公共子串:Problem。
先对 \(S_1\) 构造 SAM,对于 \(S_2\) 的每个位置,找到这个位置结束的 \(S_1\) 和 \(S_2\) 的最长公共子串长度。
设 \(p\) 为当前节点,\(l\) 为当前长度。从起始节点开始匹配,对于每一个字符 \(S_2[i]\):
-
若 \(p\) 存在转移边 \(S_2[i]\),那么就转移并使 \(l\) 加 \(1\)。
-
否则 \(p=\text{next}(p)\),直到找到有转移边 \(S_2[i]\) 的节点,\(l=len(p)\)(经过 \(\text{next}(p)\) 后到达的节点对应的最长字符串是一个子串)。
-
若仍没有找到有转移边 \(S_2[i]\) 的节点,从起始节点开始重新匹配。
最大的 \(l\) 即为答案。
n=strlen(s1+1),m=strlen(s2+1),p=1; //起始节点编号为 1 for(int i=1;i<=n;i++) insert(s1[i]-'a'); for(int i=1;i<=m;i++){ int c=s2[i]-'a'; while(p&&!ch[p][c]) p=fa[p],l=len[p]; if(ch[p][c]) p=ch[p][c],l++; else p=1,l=0; //从起始节点重新匹配 ans=max(ans,l); }
多个串的最长公共子串:Problem
对其中一个串构造 SAM,其他的串跟之前仅有两个串的方法一样跑一遍。对于每个串,记 \(mx(p)\) 表示以节点 \(p\) 为结尾的最长匹配长度。
由于是多个串,记 \(mn(p)=\min\{mx(p)\}\),\(mn(p)\) 才是所有串以 \(p\) 为结尾的最长匹配长度。
答案即为 \(\max\{mn(p)\}\)。
注意一个节点能被匹配,它在 parent 树上的所有祖先都能被匹配。所以对于每一个节点 \(u\),\(mx(u)\) 还要与 \(\max\limits_{v\in son(u)}\{\min(mx(v),len(u))\}\) 取最大值。
每一个串操作过后记得清空 \(mx\)。
#include<bits/stdc++.h> #define int long long using namespace std; const int N=1e6+5,M=30; int t,k,n,lst=1,tot=1,cnt,hd[N],to[N<<1],nxt[N<<1],ch[N][M],len[N],fa[N],mx[N],mn[N],p,l,ans; char s[N]; void add(int x,int y){ to[++cnt]=y,nxt[cnt]=hd[x],hd[x]=cnt; } void insert(int c){ int p=lst,x=lst=++tot; len[x]=len[p]+1; while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p]; if(!p){fa[x]=1;return ;} int q=ch[p][c],Q; if(len[q]==len[p]+1){fa[x]=q;return ;} Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q])); fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p]; } void dfs(int x,int fa){ for(int i=hd[x];i;i=nxt[i]){ int y=to[i]; if(y==fa) continue; dfs(y,x),mx[x]=max(mx[x],min(mx[y],len[x])); } } signed main(){ scanf("%lld",&t); while(t--){ scanf("%lld%s",&k,s+1),n=strlen(s+1),k--; for(int i=1;i<=tot;i++){ fa[i]=len[i]=hd[i]=0; for(int j=0;j<26;j++) ch[i][j]=0; } ans=cnt=0,tot=1,lst=1,memset(mn,0x3f,sizeof(mn)); for(int i=1;i<=n;i++) insert(s[i]-'a'); for(int i=2;i<=tot;i++) add(fa[i],i); for(int i=1;i<=k;i++){ scanf("%s",s+1),n=strlen(s+1),p=1,l=0; for(int i=1;i<=n;i++){ int c=s[i]-'a'; while(p&&!ch[p][c]) p=fa[p],l=len[p]; if(ch[p][c]) p=ch[p][c],l++; else p=1,l=0; mx[p]=max(mx[p],l); } dfs(1,0); for(int i=1;i<=tot;i++) mn[i]=min(mn[i],mx[i]),mx[i]=0; } for(int i=1;i<=tot;i++) ans=max(ans,mn[i]); printf("%lld\n",ans); } return 0; }
八、广义 SAM
广义 SAM:SAM 的多串版本。即对多个串建立 SAM。可参考 这里。
广义 SAM 是一种用于维护 Trie 的子串信息的 SAM 的简单变体。
1. 离线做法
离线做法,即将所有串离线插入到 Trie 树中,依据 Trie 树构造广义 SAM。
具体操作:
-
将所有字符串插入到 Trie 树中。
-
对 Trie 进行 BFS 遍历,记录下顺序以及每个节点的父亲。
-
将得到的 BFS 序列按照顺序,把 Trie 树上的每个节点插入到 SAM 中。\(last\) 为它在 Trie 树上的父亲对应的 SAM 上的节点(其中 \(last\) 表示插入字符之前的节点)。也就是每次找到插入节点的父亲作为 \(last\) 往后接即可。
用 BFS 而不是 DFS 是因为 DFS 可能会被卡。
\(insert\) 部分和普通 SAM 一样。加上返回值方便记录 \(last\)。
//Luogu P6139 #include<bits/stdc++.h> using namespace std; const int N=3e6+5,M=27; int n,ch[N][M],pos[N],fa[N],len[N],tot=1; long long ans; char s[N]; queue<int>q; struct Trie{ int ch[N][M],fa[N],c[N],tot; //分别为 Trie 上的转移数组、父节点、节点对应的字符、节点总数 }T; void insert_(char* s){ int len=strlen(s+1),p=1; for(int i=1;i<=len;i++){ int k=s[i]-'a'; if(!T.ch[p][k]) T.ch[p][k]=++T.tot,T.fa[T.tot]=p,T.c[T.tot]=k; p=T.ch[p][k]; } } int insert(int c,int lst){ //将 c 接到 lst 后面。返回值为 c 插入到 SAM 中的节点编号 int p=lst,x=++tot; len[x]=len[p]+1; while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p]; if(!p){fa[x]=1;return x;} int q=ch[p][c],Q; if(len[q]==len[p]+1){fa[x]=q;return x;} Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q])); fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p]; return x; } signed main(){ scanf("%d",&n),T.tot=1; //根初始化为 1 for(int i=1;i<=n;i++) scanf("%s",s+1),insert_(s); for(int i=0;i<26;i++) if(T.ch[1][i]) q.push(T.ch[1][i]); //插入第一层字符 pos[1]=1; //Tire 树上的编号为 1 的节点(根节点)在 SAM 上的位置为 1(根节点) while(q.size()){ int x=q.front();q.pop(); pos[x]=insert(T.c[x],pos[T.fa[x]]); //pos[x]: Trie 上节点 x 的前缀字符串(路径 根到 x 所表示的字符串)在 SAM 中的对应节点编号 for(int i=0;i<26;i++) if(T.ch[x][i]) q.push(T.ch[x][i]); } for(int i=2;i<=tot;i++) ans+=len[i]-len[fa[i]]; printf("%lld\n",ans); return 0; }
2. 在线做法
在线做法,即不建立 Trie,直接把给出的串插入到广义 SAM 中。
这里 SAM 的 \(insert\) 部分和普通 SAM 存在差别。
//Luogu P6139 #include<bits/stdc++.h> #define int long long using namespace std; const int N=3e6+5,M=27; int n,m,ch[N][M],pos[N],fa[N],len[N],lst,tot=1,ans; char s[N];
int insert(int c,int lst){ //返回值为 c 插入到 SAM 中的节点编号 int p=lst,x=0; if(!ch[p][c]){ //如果这个节点已存在就不需要新建了 x=++tot,len[x]=len[p]+1; while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p]; } if(!p){fa[x]=1;return x;} //1 int q=ch[p][c],Q=0; if(len[q]==len[p]+1){fa[x]=q;return x?x:q;} //2 Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q])); fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p]; return x?x:Q; //3 } signed main(){ scanf("%lld",&n); for(int i=1;i<=n;i++){ scanf("%s",s+1),m=strlen(s+1),lst=1; for(int j=1;j<=m;j++) lst=insert(s[j]-'a',lst); } for(int i=2;i<=tot;i++) ans+=len[i]-len[fa[i]]; printf("%lld\n",ans); return 0; }
可以证明最坏复杂度为线性。
九、参考资料
2020 年写的后缀树(已折叠)
一、后缀树
前置知识:字典树(Trie)。
后缀树:所有后缀 \(S[i\sim n]\,(1\leq i\leq n)\) 组成的 Trie 树。
本质不同的子串个数可以达到 \(\mathcal{O}(n^2)\) 级别,故节点数为 \(\mathcal{O}(n^2)\),与枚举原串的每个子串等价。
叶子节点只有不超过 \(\mathcal{O}(n)\) 个,因此大部分节点都有且仅有一个孩子。
(每分叉一次就会多一个叶子节点。一开始根节点算一个叶子节点,最后有不超过 \(n\) 个叶子节点,也就是多了不超过 \(n-1\) 个叶子节点。所以分叉的点数一定小于等于 \(n-1\)。那么其他的节点都是不分叉的,因此大部分节点都有且仅有一个孩子。)
大部分节点都 只有一个孩子,考虑合并这样的链信息。即我们可以 缩掉仅有一个孩子的节点。就像这样:
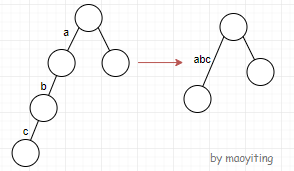
这样新的树中的节点数就变成 \(\mathcal{O}(n)\) 的了。
所以后缀树是所有后缀组成的,经过 信息压缩 后的 Trie 树。
二、虚树
1. 定义
对于树 \(T=(V,E)\),给定关键点 \(S⊆V\),则可以定义 虚树 \(T'=(V',E')\)。
-
对于节点集合 \(V'⊆V\) ,使得 \(u\in V'\) 当且仅当 \(u\in S\),或者 \(∃x,y\in S\),使得 \(\text{LCA}(x,y)=u\)。(即 \(u\in V'\) 当且仅当 \(u\) 为关键点或关键点的 \(\text{LCA}\))
-
对于边集 \(E'\),\((u,v)\in E'\),当且仅当 \(u,v∈V'\),且 \(u\) 是 \(v\) 在 \(V'\) 中深度最浅的祖先。
与之前所说的联系:假如把所有叶子节点当做关键点的话,任意两个叶子节点的 \(\text{LCA}\) 一定是分叉点,那么 \(V'\) 就是所有的叶子节点以及分叉点组成的集合。
而 \(E'\) 其实就是把不分叉的链缩成一条边后的边集(即 \(E'\) 中的一条边对应着一条没有子树的链)。这与我们之前说的「缩掉仅有一个孩子的节点」对应。
2. 构建虚树
考虑增量法,每次向虚树中增加一个关键点。
按 DFS 序依次加入 \(u\in S\),栈维护 右链(栈中相邻的两个节点在虚树上也是相邻的,并且栈中节点 DFS 序单调递增)。
每加入一个关键点 \(u\),设上一个关键点为 \(v\),令 \(\text{LCA}(u,v)=w\),将栈顶 \(dep_x>dep_w\) 的弹栈,加入 \(w,u\) 即为新的右链。
(若栈顶存在 \(dep_x=dep_w\),则不加入 \(w\)。)

在此过程中维护每个点的父节点,最终连边即可得到 \(E′\)。
设 \(n=|S|\)。时间复杂度:\(\mathcal{O}(n\log n)\)。
三、SA 构建后缀树
后缀数组 + 虚树。
虚树的角度:
-
按字典序 DFS,则节点排序相当于对后缀进行排序,亦即后缀数组。
-
求出后缀数组后,即可用单调栈维护右链了。
-
\(\text{LCA}\) 对应了两个节点的 \(\text{LCP}\),因此可以 RMQ。
时间复杂度:\(\mathcal{O}(n\log n)\)。
(不会 SAM 就可以用 SA+虚树 的方法啦)
四、SAM 构建后缀树
我们同样可以使用 后缀自动机 来构建后缀树:
定理:后缀自动机的 parent 树为反串后缀树。
正串的 SAM 维护的是原字符串所有前缀的后缀(可以考虑 SAM 增量法的构造过程)。那么同理,反串的 SAM,维护的就是所有后缀的前缀,可以得到所有后缀构成的 Trie,即后缀树。
建出反串的 SAM 之后,就会直接得到后缀树。
时间复杂度: \(\mathcal{O}(n|\sum|)\) 或 \(\mathcal{O}(n\log n)\)。
五、Ukkonen 算法
Ukkonen 算法可以 \(\mathcal{O}(n)\) 构建后缀树。
(可以康 这里)
2021 年写的 SAM(已折叠)
一、一些概念
后缀自动机(SAM)是可以且仅可以接受一个母串 \(S\) 的后缀的 DFA。SAM Drawer。
1. Endpos 集合
子串的结束位置集合。比如 banana 中,\(\text{endpos}(\text{ana})=\{4,6\}\)。
对于两个子串 \(t_1,t_2\),若 \(\text{endpos}(t_1)=\text{endpos}(t_2)\),则 \(t_1,t_2\) 属于一个 \(\text{endpos}\) 等价类。
对于非空子串 \(t_1,t_2\,(|t_1|\leq |t_2|)\):
-
若 \(t_1,t_2\) 属于同一个 \(\text{endpos}\) 等价类,则 \(t_1\) 在 \(S\) 中每次出现,都是以 \(t_2\) 的后缀形式存在。
-
若 \(t_1\) 为 \(t_2\) 的后缀,则 \(\text{endpos}(t_2)\subseteq \text{endpos}(t_1)\);否则 \(\text{endpos}(t_2)\cap \text{endpos}(t_1)=\varnothing\)。
(补:根据这个性质,对于 Parent 树上一个节点,其儿子的 \(\text{endpos}\) 集合没有交集,所以线段树合并维护 \(\text{endpos}\) 集合时可以省略
l,r) -
一个 \(\text{endpos}\) 等价类中的串为 某个前缀 的 长度连续的后缀。
(补:因此,已知 \(\text{endpos}\) 集合和长度 \(len\),就能唯一确定出一个子串)
-
\(\text{endpos}\) 等价类的个数为 \(\mathcal{O}(n)\) 级别。会在后文提及。
根据合并等价类的思想,我们将 \(\text{endpos}\) 集合完全相同的子串合并到同一个节点。这样一来大大优化了时间和空间复杂度。SAM 的每个节点都表示一个 \(\text{endpos}\) 等价类。
2. Parent Tree
我们知道,SAM 里的每个节点都代表了一堆 \(\text{endpos}\) 集合相同的子串。容易发现,对于越短的子串,其 \(\text{endpos}\) 集合往往越大。更具体地,若 \(t_1\) 为 \(t_2\) 的后缀,则 \(|\text{endpos}(t_1)|\geq |\text{endpos}(t_2)|\),当且仅当取得等号时,\(t_1,t_2\) 会被压缩到同一个节点中。
而对于 \(t_2\) 的每一个后缀,一定有一个分界点,使得对于长度 \(\geq\) 该分界点的后缀,它和 \(t_2\) 的 \(\text{endpos}\) 集合相同;而长度 \(<\) 该分界点的后缀,因为短,所以有机会可以在 \(S\) 中出现更多次,\(\text{endpos}\) 集合会更大,于是就和 \(t_2\) 分开了。因此,每个节点 \(p\) 中存储的一定是一堆长度连续的子串,且短的串是长的串的后缀。
对于 SAM 的每个节点都能找到一个这样的“分界点”,并且每个节点都对应了一个唯一的“分界点”。而如果 \(t_1\) 是 \(t_2\) 的一个后缀且没有和 \(t_2\) 分在一个节点中,那么 \(t_1\) 也可能成为别的子串的后缀(如 ab 既可以是 cab 的后缀,也可以是 zab 的后缀)。这样我们看到:长的串只能“对应”唯一的一个短的串,而短的串可以“对应”多个长的串,如果将“短的串”视为“长的串”的父亲,这就构成了一棵严格的树形结构。我们称为 Parent 树。
注意到短串对应的多个长串,它们的 \(\text{endpos}\) 集合无交(因为它们没有后缀关系,一个出现的位置另一个必然做不到也在这个位置出现)。对于一个父节点,其若干个儿子的 \(\text{endpos}\) 相当于将父节点的 \(\text{endpos}\) 分割成若干不相交的子集,最终会产生不多于 \(n\) 个叶节点。所以树的节点数也只有 \(\mathcal O(n)\)。
在 Parent 树中,一个节点 \(i\) 表示一个类,节点 \(i\) 的父亲记为 \(link_i\)(也被称为“后缀链接”)。显然 \(\text{endpos}(i)\subsetneq \text{endpos}(link_i)\),\(link_i\) 代表的子串均为 \(i\) 子串的后缀。
设节点 \(i\) 对应对应的等价类中最长的子串为 \(\max(i)\),最短的为 \(\min(i)\)。则 \(|\min(i)|=|\max(link_i)|+1\),这个也很好理解。因此对每个节点都只记录最长的子串长度即可。
Parent 树本质上是 \(\text{endpos}\) 集合构成的一棵树,体现了 \(\text{endpos}\) 的包含关系。
二、后缀自动机
1. 状态 & 转移
在 SAM 中我们把一个 \(\text{endpos}\) 等价类作为一个状态。
SAM 是由一个 Parent 树和一个 DAG 组成的,它们的状态集合相同。Parent Tree 和 DAG 是两种完全不同的边(一个是 \(link_x\),一个是转移边 \(ch_{x,c}\)),只是共用相同的节点。
当我们在 DAG 上从一个状态 \(x\) 走到 \(ch_{x,c}\) 时,意味着在 \(ch_{x,c}\) 表示的部分字符串(“部分”是因为可以有多个点连向同一个点,接的 \(c\) 相同,但是起点不同)是的 \(x\) 后面 追加一个字符 \(c\) 得到的。在 SAM 的 DAG 上从起始状态跑出来的串都是原串的 子串。
比如 abab 的 SAM 长这样(Max 表示 \(|\max(p)|\),size 表示 \(\text{endpos}\) 集合的大小,节点旁边写着的是 \(\text{endpos}\) 集合和所代表的字符串,黑色边表示 DAG 上的转移边,红色边是 Parent 树上的边):

2. 构建
增量法,通过 \(S\) 的 SAM 求出 \(S+c\) 的 SAM。加入字符 \(c\) 后,子串只增加了 \(S+c\) 的后缀,已有的子串不受影响。
\(S+c\) 的某些后缀可能在 \(S\) 出现过,在 SAM 中有其对应的节点。
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
lst 表示上一次添加的位置,fa[p] 表示 \(p\) 在 Parent 树上的父亲(也就是上面说的 \(link_p\)),len[p] 表示 \(|\max(p)|\)。
-
int p=lst,x=lst=++tot; len[x]=len[p]+1; while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];新建节点 \(x\) 表示新串,\(\text{endpos}(x)=\{n\}\) 不可能与之前建的任何一个节点相同。对于上一步中的旧串肯定也有一个为它建的节点,设为 \(p\)。
p=fa[p]就是在遍历旧串的后缀,如果当前的 \(p\)(设表示的字符串为 \(s_p\))没有ch[p][c],说明 旧串中不存在 \(s_p+c\),不难发现 \(s_p+c\) 是新串的后缀,所以这些后缀是新出现的,\(\text{endpos}(s_p+c)=\{n\}\)。我们直接令ch[p][c]=x,相当于把 \(s_p+c\) 加到了 \(x\) 表示的字符串中,同时 \(\text{endpos}(s_p+c)=\text{endpos}(S+c)=\{n\}\),正确性是有保证的。然而一旦发现
ch[p][c]这个转移存在,说明 \(s_p+c\) 已经在旧串中出现了,那么 \(\text{endpos}(s_p+c)\neq \{n\}\),直接连边有失妥当,我们需要对此进一步处理。 -
if(!p){fa[x]=1;return ;}!p就是跳出 SAM 而终止,说明之前的节点中没有新串的后缀,没有节点的 \(\text{endpos}\) 会多一个 \(n\)。直接fa[x]=1即可。
-
int q=ch[p][c],Q; if(len[q]==len[p]+1){fa[x]=q;return ;}当前的 \(s_p+c\) 在旧串中出现过并且是新串的后缀。我们先看 \(q\) 表示的所有串是否都能作为新串的后缀。
发现这种情况成立当且仅当 \(|\max(q)|=|\max(p)|+1\)(这等价于 \(\max(q)=\max(p)+c\),而 \(p\) 是旧串的后缀)。那么 \(q\) 及 \(q\) 的祖先在这次
insert()后,其 \(\text{endpos}\) 都增加了 \(n\)。我们直接令fa[x]=q即可,因为“后缀”和“\(\text{endpos}\) 集合包含关系”都满足了(\(n\in\text{endpos}(q)\))。
但是如果这个条件不成立,意味着 \(q\) 中存在一个比 \(|\max(p)|+1\) 更长的子串(因为 \(p\) 经过转移边 \(c\) 到 \(q\),所以显然不会更短),这样更长的子串必然不会是新串的后缀,因为在不断遍历旧串后缀直到有出边 \(c\) 时,\(|\max(p)|+1\) 相当于是最长的在 \(S+c\) 里出现过的后缀。
-
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q])); fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];“不会全是新串的后缀”的话,会出现什么问题呢?\(q\) 的一部分较短后缀是新串的后缀(它们的 \(\text{endpos}\) 集合会多出一个 \(n\)),但是另一部分较长的后缀却不是新串的后缀(\(\text{endpos}\) 集合没变化),此时 \(q\) 的字符串 \(\text{endpos}\) 集合已经出现不同,我们注定要将它们拆成两部分。
我们新建一个状态 \(Q\),表示 \(q\) 中是新串后缀的那部分。首先我们沿用 \(q\) 的所有转移,相当于拆出来 \(q\) 和 \(Q\) 一起转移到
ch[q][c],ch[q][c]代表的子串不变(原来是通过完整的 \(q\) 转移过去)。\(Q\) 所代表的子串是从 \(q\) 中分离出来的,并且都是 \(q\) 所代表子串的后缀。显然fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q(fa的改变可以看作fa[q]和q这条树枝上插入了一个Q)。while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];中,ch[p][c]==q是什么意思呢?对于一个存在 \(c\) 转移的一个 \(p\) 的祖先,其转移结果ch[p][c]肯定是新串的后缀。而现在 \(q\) 不是新串的后缀(是新串后缀的部分被截到 \(Q\) 里去了),那直接将转移重定向到 \(Q\) 就行了。
3. 复杂度
-
对于一个长度为 \(n\,(n\geq 2)\) 的字符串 \(S\),它的 SAM 状态数 \(\leq 2n-1\)。
Parent 树上最多只有 \(n\) 个叶节点,一个分叉点会合并至少两个子节点,Parent 树为完全二叉树时节点数最多,为 \(2n-1\) 个。
不过实际上看代码能知道节点数了,每次扩展最多 \(+2\) 个节点。
-
对于一个长度为 \(n\,(n\geq 3)\) 的字符串 \(S\), 它的 SAM 转移数 \(\leq 3n-4\)。
SAM 的 空间复杂度:
- 写成
int ch[N<<1][M](其中N为状态数,M为字符集大小):空间 \(\mathcal O(n|\sum|)\),查询时间 \(\mathcal O(1)\). - 字符集较大时,可写成
map<int,int>ch[N<<1],空间 \(\mathcal O(n)\),查询时间 \(\mathcal O(\log|\sum|)\)。
构建 SAM 的 时间复杂度:均摊 \(\mathcal O(n)\)。
4. 模板
给出一个只包含小写字母的字符串 \(S\),求 \(S\) 的所有出现次数不为 \(1\) 的子串的出现次数乘上该子串长度的最大值。
\(|S|\leq 10^6\)。
出现次数等价于 \(\text{endpos}\) 集合的大小。
上面提到 \(\text{endpos}\) 的分割关系构成一棵 Parent 树,记 \(sz_i=|\text{endpos}(i)|\),首先不考虑信息丢失,那么 \(sz_i=\sum_{fa_j=i} sz_j\)。
接下来考虑丢失的那个(丢失是因为这个位置长度到顶了,无法往前扩展。这也暗示了最多只能丢失一个)。向前扩展导致长度到顶的只有一个位置,而这个必然是一个前缀,也就是说只有在一个可以表示主串一个前缀的状态的 \(\text{endpos}\) 才会拥有这样的元素。代码中只要在 insert() 中加上一句 sz[x]=1 即可。
#include<bits/stdc++.h>
using namespace std;
const int N=2e6+5,M=30;
int n,lst=1,tot=1,ch[N][M],len[N],fa[N],sz[N]; //数组开两倍!注意 lst=tot=1
long long ans;
char s[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
sz[x]=1,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void dfs(int x,int fa){
for(int y:v[x])
if(y!=fa) dfs(y,x),sz[x]+=sz[y];
if(sz[x]>1) ans=max(ans,1ll*sz[x]*len[x]);
}
signed main(){
scanf("%s",s+1),n=strlen(s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a');
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1,0),printf("%lld\n",ans);
return 0;
}
为了减小常数,有时我们可以用“基数排序”代替树形 DP。
具体来说,在 DAG 或 Parent 树上 DFS 的操作,可以用拓扑序替代:\(len_p>len_{fa_p}\)(短串是长串的父亲),\(len_p<len_{ch_{p,c}}\)。
以在 Parent 树上 DFS 为例,我们按 \(len\) 值从小到大对节点排个序,就得到了整棵树从树根到树叶的拓扑序。把这个拓扑序倒过来,for 循环一遍,就相当于树形 DP 啦。
for(int i=1;i<=tot;i++) cnt[len[i]]++;
for(int i=1;i<=tot;i++) cnt[i]+=cnt[i-1];
for(int i=1;i<=tot;i++) id[cnt[len[i]]--]=i;
模板题完整代码:
#include<bits/stdc++.h>
using namespace std;
const int N=2e6+5,M=30;
int n,lst=1,tot=1,ch[N][M],len[N],fa[N],sz[N],cnt[N],id[N]; //数组开两倍!
long long ans;
char s[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
sz[x]=1,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
signed main(){
scanf("%s",s+1),n=strlen(s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a');
for(int i=1;i<=tot;i++) cnt[len[i]]++;
for(int i=1;i<=tot;i++) cnt[i]+=cnt[i-1];
for(int i=1;i<=tot;i++) id[cnt[len[i]]--]=i;
for(int i=tot,x;i>=1;i--) x=id[i],sz[fa[x]]+=sz[x];
for(int i=1;i<=tot;i++)
if(sz[i]>1) ans=max(ans,1ll*sz[i]*len[i]);
printf("%lld\n",ans);
return 0;
}
同时 SAM 还有一些有用的性质:
-
\(s\) 的子串和 SAM 中从起始状态开始的路径一一对应。
-
具体求 \(\text{endpos}\) 集合可以用线段树合并。
-
SAM 的每个节点表示的串的个数为 \(len_i-len_{fa_i}\),表示的串互为后缀关系,长度在 \(len_{fa_i}+1\) 到 \(len_i\) 之间。
-
SAM 的 Parent 树中 \(fa_i\) 表示的串是 \(i\) 表示的串的后缀。反串 SAM 的 Parent 树就是后缀树。
- 正串的 SAM 维护的是原字符串所有前缀的后缀(可以考虑 SAM 增量法的构造过程)。那么同理,反串的 SAM,维护的就是所有后缀的前缀,可以得到所有后缀构成的 Trie(压缩后),即后缀树。
-
两个串最长公共后缀的长度,等于这两个串所代表的点在 Parent 上 LCA 的 \(len\) 值。这是因为,一个串对应节点的祖先节点都是它的后缀,且深度越大长度越长。
三、简单应用
1. 子串相关
从 DAWG 的起始节点 \(q_0\) 出发,每条路径唯一对应 \(S\) 的一个子串。因为 SAM 即能表示出所有子串,又不会出现两条不同路径表示同一个子串。
-
判断子串:判断 \(s\) 是否为 \(t\) 的子串。
对 \(t\) 建立后缀自动机 \(D_t\)(\(D_t\) 表示 \(t\) SAM 对应的 DAG),从根开始跑一遍 \(s\)。由于 \(D_t\) 中包含了 \(t\) 的所有子串,那么如果 \(s\) 在跑的过程中走到了空状态,那么说明不是 \(t\) 的子串。
-
子串出现次数
\(\text{endpos}\) 集合大小求出来就可以了。
-
本质不同的子串数
-
离线做法
\(s\) 本质不同的子串树即为 \(D_s\) 中根开始的不同路径数。
设 \(f_x\) 表示从状态 \(x\) 开始的不同路径数,\(f_x=1+\sum_{ch(x,c)=y}f(y)\)。那么答案就是 \(f_{q_0}-1\),复杂度线性。
-
在线做法
考虑到一个状态表示的子串长度连续,并且短串都是长串的后缀。那么 \(x\) 这个状态表示了 \([|\min(x)|,|\max(x)|]\) 这么多本质不同的子串。这些子串显然不能在其他状态中,于是所有状态包含的子串数之和记为答案:\(\sum_{x\in D_s}(len_x-len_{fa_x})\)。
在实际维护时我们只要对于新建的那个 \(x\) 更新答案,不管 \(Q\) 是因为它只是分割了一个 \([|\min(Q)|,|\max(Q)|]\) 区间,并没有对答案产生贡献。复杂度显然也是线性。
-
-
本质不同子串总长
-
离线做法
在原来 \(f\) 的基础上设 \(g_x\) 为从状态 \(x\) 开始的不同路径总长,\(g_x=f_x+\sum_{ch(x,c)=y}g_y\)。
-
在线做法
动态维护 \(\large\sum_{x\in D_s}(\frac{len_x\times (len_x+1)}{2}-\frac{len_{fa_x}\times (len_{fa_x}+1)}{2})\) 即可。
-
2. 最长公共子串
-
两个串的最长公共子串:给定 \(s,t\),求 \(s,t\) 的最长公共子串。
首先对 \(s\) 建立 SAM \(D_s\),然后对于 \(t\) 的每一个前缀,我们希望这个前缀有尽量长的后缀可以匹配。换句话说,对于 \(t\) 的每一个位置,我们要找到这个位置结束的 \(s\) 和 \(t\) 的最长公共子串长度。
那么先把 \(t\) 放在 SAM 上跑,如果能走转移就走转移,否则我们慢慢从前面缩减长度,也就是跳 \(fa\),直到存在一个当前字符的转移为止。
答案我们实时更新,每走一次转移取一次最大值即可。
复杂度仍为线性,因为我们维护 \(t\) 的起始位置和终止位置都在后移。
n=strlen(s1+1),m=strlen(s2+1),p=1; for(int i=1;i<=n;i++) insert(s1[i]-'a'); for(int i=1;i<=m;i++){ int c=s2[i]-'a'; while(p&&!ch[p][c]) p=fa[p],l=len[p]; if(ch[p][c]) p=ch[p][c],l++; else p=1,l=0; //从起始节点重新匹配 ans=max(ans,l); } -
首先我们对其中一个串建 SAM 其他的往上面跑,对于每个串,求出 \(mx_i\) 表示以状态 \(i\) 为结尾的最长匹配长度。然后记 \(mn_i\) 表示 \(mx_i\) 的历史最小值(因为是多个串,\(mn_i\) 才是所有串以 \(i\) 为结尾的最长匹配长度)。答案为 \(\max\{mn_i\}\)。
注意一个节点能被匹配,它在 Parent 树上的所有祖先都能被匹配。所以对于每一个节点 \(i\),所以 \(mx_{fa_i}\gets \max(mx_{fa_i},mx_i)\)。别忘了确保 \(mn_i\leq len_i\)。
#include<bits/stdc++.h> using namespace std; const int N=1e6+5,M=30; int t,k,n,lst=1,tot=1,ch[N][M],len[N],fa[N],mx[N],mn[N],p,l,ans; char s[N]; vector<int>v[N]; void insert(int c){ int p=lst,x=lst=++tot; len[x]=len[p]+1; while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p]; if(!p){fa[x]=1;return ;} int q=ch[p][c],Q; if(len[q]==len[p]+1){fa[x]=q;return ;} Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q])); fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p]; } void dfs(int x,int fa){ for(int y:v[x]) if(y!=fa) dfs(y,x),mx[x]=max(mx[x],min(mx[y],len[x])); } signed main(){ scanf("%d",&t); while(t--){ scanf("%d%s",&k,s+1),n=strlen(s+1),k--; for(int i=1;i<=tot;i++) fa[i]=len[i]=0,v[i].clear(),fill(ch[i],ch[i]+26,0); ans=0,tot=lst=1,memset(mn,0x3f,sizeof(mn)); for(int i=1;i<=n;i++) insert(s[i]-'a'); for(int i=2;i<=tot;i++) v[fa[i]].push_back(i); for(int i=1;i<=k;i++){ scanf("%s",s+1),n=strlen(s+1),p=1,l=0; for(int i=1;i<=n;i++){ int c=s[i]-'a'; while(p&&!ch[p][c]) p=fa[p],l=len[p]; if(ch[p][c]) p=ch[p][c],l++; else p=1,l=0; mx[p]=max(mx[p],l); } dfs(1,0); for(int i=1;i<=tot;i++) mn[i]=min(mn[i],mx[i]),mx[i]=0; } for(int i=1;i<=tot;i++) ans=max(ans,mn[i]); printf("%d\n",ans); } return 0; }
3. 字典序相关
-
字典序第 \(k\) 小子串:本质不同/位置不同。
字典序第 \(k\) 小的子串对应 SAM 中字典序第 \(k\) 小的路径。
如果没有本质不同的条件,建 SAM,在 Parent 树上 DP 求出每个状态表示的字符串的出现次数 \(sz\)。
再在 DAWG 上按照字典序跑,跑到一个节点就令 \(k\gets k-sz_i\),并转移。没有转移可走时递归回溯。当 \(k=0\) 时,当前跑到的字符串记为所求。
但是没有转移可走时会回溯,某些状态在遍历过一遍后又回溯到上一状态,不能可能作为答案,复杂度爆炸。考虑预处理经过某一状态的路径条数 \(sum\),转移到某状态前先判断 \(sum\) 是否 \(<k\),若满足条件,则令 \(k\gets k-sum\),并直接考虑下一转移。
如果要求本质不同,直接赋 \(sz_i=1\),即钦定每个子串仅出现 \(1\) 次,再按上述过程跑即可。
//Luogu P3975 #include<bits/stdc++.h> using namespace std; const int N=1e6+5,M=30; int n,t,k,x,lst=1,tot=1,ch[N][M],len[N],fa[N],sz[N],f[N],cnt[N],id[N],num; char s[N],ans[N]; void insert(int c){ int p=lst,x=lst=++tot; sz[x]=1,len[x]=len[p]+1; while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p]; if(!p){fa[x]=1;return ;} int q=ch[p][c],Q; if(len[q]==len[p]+1){fa[x]=q;return ;} Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q])); fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p]; } signed main(){ scanf("%s%d%d",s+1,&t,&k),n=strlen(s+1); for(int i=1;i<=n;i++) insert(s[i]-'a'); for(int i=1;i<=tot;i++) cnt[len[i]]++; for(int i=1;i<=tot;i++) cnt[i]+=cnt[i-1]; for(int i=1;i<=tot;i++) id[cnt[len[i]]--]=i; for(int i=tot;i>=1;i--){ if(t) sz[fa[id[i]]]+=sz[id[i]]; else sz[id[i]]=1; } sz[1]=0; for(int i=tot;i>=1;i--){ x=id[i],f[x]=sz[x]; for(int j=0;j<26;j++) if(ch[x][j]) f[x]+=f[ch[x][j]]; } if(k>f[1]) puts("-1"),exit(0); for(int x=1;;){ if((k-=sz[x])<=0) break; for(int i=0;i<26;i++) if(ch[x][i]){ if(k>f[ch[x][i]]) k-=f[ch[x][i]]; else{putchar('a'+i),x=ch[x][i];break;} } } return 0; } -
字典序最小的循环移位
串 \(S+S\) 包含 \(S\) 的所有循环移位作为子串。
问题转化为在 \(S+S\) 对应的 SAM 上找最小的长度为 \(|S|\) 的路径。从 \(q_0\) 出发,贪心地访问最小的字符即可。
四、广义 SAM
广义 SAM:SAM 的多串版本。即对多个串建立 SAM。
广义 SAM 是一种用于维护 Trie 的子串信息的 SAM 的简单变体。
将多个模式串插入到 Trie 后,即可使用广义 SAM 维护多模式串的信息。其基本思想是将多串的信息进行压缩,使得 SAM 在仍满足节点数最少的同时 包含所有子串的信息。此时 SAM 中的一个状态可能同时代表多个串中相应的子串。
1. 离线做法
将所有串离线插入到 Trie 树中,依据 Trie 树构造广义 SAM。
对所有串建出 Trie,然后 BFS 遍历 Trie,每个点在父亲的基础上扩展即可。
- 将所有字符串插入到 Trie 树中。
- 对 Trie 进行 BFS 遍历,记录下顺序以及每个节点的父亲。
- 将得到的 BFS 序列按照顺序,把 Trie 树上的每个节点插入到 SAM 中。\(last\) 为它在 Trie 树上的父亲对应的 SAM 上的节点(其中 \(last\) 表示插入字符之前的节点)。也就是每次找到插入节点的父亲作为 \(last\) 往后接即可。
用 BFS 而不是 DFS 是因为 DFS 可能会被卡。
insert 部分和普通 SAM 一样。加上返回值方便记录 \(last\)。
//Luogu P6139
#include<bits/stdc++.h>
using namespace std;
const int N=3e6+5,M=27;
int n,ch[N][M],pos[N],fa[N],len[N],tot=1;
long long ans;
char s[N];
queue<int>q;
struct Trie{ int ch[N][M],fa[N],c[N],tot;}T;
void insert_(char* s){
int len=strlen(s+1),p=1;
for(int i=1;i<=len;i++){
int k=s[i]-'a';
if(!T.ch[p][k]) T.ch[p][k]=++T.tot,T.fa[T.tot]=p,T.c[T.tot]=k;
p=T.ch[p][k];
}
}
int insert(int c,int lst){ //将 c 接到 lst 后面。返回值为 c 插入到 SAM 中的节点编号
int p=lst,x=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return x;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return x;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
return x;
}
signed main(){
scanf("%d",&n),T.tot=1;
for(int i=1;i<=n;i++) scanf("%s",s+1),insert_(s);
for(int i=0;i<26;i++)
if(T.ch[1][i]) q.push(T.ch[1][i]); //插入第一层字符
pos[1]=1; //Tire 树上的编号为 1 的节点(根节点)在 SAM 上的位置为 1(根节点)
while(q.size()){
int x=q.front();q.pop();
pos[x]=insert(T.c[x],pos[T.fa[x]]); //pos[x]: Trie 上节点 x 的前缀字符串(路径 根到 x 所表示的字符串)在 SAM 中的对应节点编号
for(int i=0;i<26;i++)
if(T.ch[x][i]) q.push(T.ch[x][i]);
}
for(int i=2;i<=tot;i++) ans+=len[i]-len[fa[i]];
printf("%lld\n",ans);
return 0;
}
2. 在线做法
不建立 Trie,直接把给出的串插入到广义 SAM 中。
insert 部分和普通 SAM 存在差别,需记录当前串插入前缀对应的节点编号,并且如果当前插入新串之前已经有一个为它建的节点,这次就不再建了。

注意这份广义 SAM 板子 fa[0] 不一定是 0。
//Luogu P6139
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=3e6+5,M=27;
int n,m,ch[N][M],pos[N],fa[N],len[N],lst,tot=1,ans;
char s[N];
int insert(int c,int lst){ //返回值为 c 插入到 SAM 中的节点编号
int p=lst,x=0;
if(!ch[p][c]){ //如果这个节点已存在就不需要新建了
x=++tot,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
}
if(!p){fa[x]=1;return x;} //1
int q=ch[p][c],Q=0;
if(len[q]==len[p]+1){fa[x]=q;return x?x:q;} //2
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
return x?x:Q; //3 为什么设 lst=Q 呢?因为 q 不是新串的后缀,等下一次 insert 的第一步遍历旧串的后缀就出问题了
}
signed main(){
scanf("%lld",&n);
for(int i=1;i<=n;i++){
scanf("%s",s+1),m=strlen(s+1),lst=1;
for(int j=1;j<=m;j++) lst=insert(s[j]-'a',lst);
}
for(int i=2;i<=tot;i++) ans+=len[i]-len[fa[i]];
printf("%lld\n",ans);
return 0;
}
可以证明最坏复杂度为线性。
尽量别写伪广义 SAM(只要每次插入一个串就 lst=1),会出现奇奇怪怪的问题,具体见 ix35 帖子。画广义 SAM。
五、后缀树
后缀树就是反串的 Parent 树。同样,Parent 树就是反串的后缀树。
因为 Parent 树中父亲是儿子 \(\text{endpos}\) 不同的最长后缀,后缀树中父亲是儿子 \(\text{beginpos}\) 不同的最长前缀。
Parent 树实际上就是反着看字符的 trie 把树上相邻的一些 \(\text{endpos}\) 集合相同的点压在一起。用红色标出每个前缀,红色点形成的虚树就是反串的后缀树了。比如:

建完正串 Parent 树后,我们人脑将所有串反一下(因为在反串上看跟正串是反过来的),找出正串每个前缀对应的状态标为关键点,后缀树就是关键点集合形成的虚树。
六、例题
CF1037H Security(*3200)
给出一个字符串 \(s\),\(q\) 次操作,每次给出 \(l,r,t\),求字典序最小的 \(s[l:r]\) 的子串 \(s'\) 使得 \(s'>t\)(字典序)。
\(1\leq |s|\leq 10^5\),\(1\leq q\leq 2\times 10^5\),\(\sum|t|\leq 2\times 10^5\)。
对于这种区间子串的题目,我们直接在 SAM 上贪心时,不知道当前的选择是否可行(即选一个字符后判断可不可能当前选取的整个字符串落在区间 \([l,r]\) 中),那么可以用线段树合并维护 \(\text{endpos}\) 集合,然后直接贪心选取即可。注意要贪到第 \(|t|+1\) 位(因为可能当前 \(s'=t\),那么再选一个字符就好了)。
#include<bits/stdc++.h>
using namespace std;
const int N=4e5+5,M=27;
int n,m,q,l,r,x,tot=1,lst=1,len[N],ch[N][M],fa[N],cnt,rt[N],lc[N<<5],rc[N<<5],pos[N];
char s[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void modify(int &p,int l,int r,int pos){
if(!p) p=++cnt;
if(l==r) return ;
int mid=(l+r)/2;
if(pos<=mid) modify(lc[p],l,mid,pos);
else modify(rc[p],mid+1,r,pos);
}
int merge(int x,int y,int l,int r){
if(!x||!y) return x|y;
int p=++cnt,mid=(l+r)/2;
if(l==r) return p;
lc[p]=merge(lc[x],lc[y],l,mid);
rc[p]=merge(rc[x],rc[y],mid+1,r);
return p;
}
int query(int p,int l,int r,int lx,int rx){
if(!p) return 0;
if(l>=lx&&r<=rx) return 1;
int mid=(l+r)/2,ans=0;
if(lx<=mid) ans|=query(lc[p],l,mid,lx,rx);
if(rx>mid) ans|=query(rc[p],mid+1,r,lx,rx);
return ans;
}
void dfs(int x,int fa){
for(int y:v[x])
if(y!=fa) dfs(y,x),rt[x]=merge(rt[x],rt[y],1,n);
}
signed main(){
scanf("%s%d",s+1,&q),n=strlen(s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a'),modify(rt[lst],1,n,i);
for(int i=1;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1,0);
while(q--){
scanf("%d%d%s",&l,&r,s+1),pos[0]=1,m=strlen(s+1);
for(int i=1;i<=m;i++) pos[i]=ch[pos[i-1]][s[i]-'a'];
for(int i=m;i>=0;i--) if(pos[i]) //前 i 位相同(显然字典序大于的那位越后面越优)
for(int j=(i==m?0:s[i+1]-'a'+1);j<26;j++){
if(!(x=ch[pos[i]][j])) continue;
if(query(rt[x],1,n,l+i,r)){ //判断当前选取的字符串能否落在 [l,r] 中
for(int k=1;k<=i;k++) putchar(s[k]);
putchar(j+'a'),puts(""); goto qwq;
}
}
puts("-1");
qwq:;
}
return 0;
}
P4770 [NOI2018] 你的名字
给出一个字符串 \(s\),\(q\) 次询问,每次给出 \(l,r,t\),求 \(t\) 有多少个本质不同子串没有在 \(s[l:r]\) 中出现过。
\(|s|,|t|\leq 5\times 10^5\),\(q\leq 10^5\),\(\sum|t|\leq 10^6\)。
对 \(s\) 建立 SAM,用线段树合并维护 \(\text{endpos}\) 集合。
对 \(t\) 的每个前缀 \([1,i]\),在 \(s[l:r]\) 上匹配,求出最长的匹配长度 \(f_i\),表示 \(t[i-f_i+1,i]\) 在 \(s[l:r]\) 中出现过且 \(f_i\) 是最大的。换句话说,\(t\) 中以 \(i\) 结尾的、长度大于 \(f_i\) 的子串没有在 \(s[l:r]\) 中出现过。
怎么求 \(f\)?每次添加一个字符 \(t_i\),设加入 \(t_{i-1}\) 后在节点 \(p\),匹配长度为 \(len\),那么就查询是否某个 \(x\in\text{endpos}(ch_{p,t_i})\),使得 \(x\in[l+len,r]\)(保证当前状态当前长度的字符串在 \(s[l:r]\) 中出现过),如果存在就 \(p\gets ch_{p,t_i},len\gets len+1\),不存在就 将匹配长度减小 \(1\)(注意不是跳 \(fa\),可能状态 \(p\) 时当前长度不满足,但是长度减小就满足了),如果长度减小到 \(len_{fa_p}\) 再跳 \(fa\)。最后 \(f_i\gets len\)。
然后再对 \(t\) 建立 SAM,对于一个节点 \(p\),设 \(pos\in\text{endpos}(p)\),对答案的贡献是 \(\max(len_p-\max(len_{fa_p},f_{pos}),0)\),因为\(f_{pos}\) 是最大的,所以这个点长度 \(>f_{pos}\) 的串都可以贡献。
#include<bits/stdc++.h>
using namespace std;
const int N=1e6+5;
int n,m,q,l,r,cnt,rt[N],lc[N<<5],rc[N<<5],pos[N],f[N];
char s[N];
long long ans;
vector<int>v[N];
struct SAM{
int tot=1,lst=1,len[N],ch[N][27],fa[N];
void clear(){
for(int i=1;i<=tot;i++) fill(ch[i],ch[i]+26,0),len[i]=fa[i]=pos[i]=0;
tot=lst=1;
}
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
fa[Q]=fa[q],pos[Q]=pos[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; //pos[Q]=pos[q]!
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
}S,T;
void modify(int &p,int l,int r,int pos){
if(!p) p=++cnt;
if(l==r) return ;
int mid=(l+r)/2;
if(pos<=mid) modify(lc[p],l,mid,pos);
else modify(rc[p],mid+1,r,pos);
}
int merge(int x,int y,int l,int r){
if(!x||!y) return x|y;
int p=++cnt,mid=(l+r)/2;
if(l==r) return p;
lc[p]=merge(lc[x],lc[y],l,mid);
rc[p]=merge(rc[x],rc[y],mid+1,r);
return p;
}
int query(int p,int l,int r,int lx,int rx){
if(!p) return 0;
if(l>=lx&&r<=rx) return 1;
int mid=(l+r)/2,ans=0;
if(lx<=mid) ans|=query(lc[p],l,mid,lx,rx);
if(rx>mid) ans|=query(rc[p],mid+1,r,lx,rx);
return ans;
}
void dfs(int x,int fa){
for(int y:v[x])
if(y!=fa) dfs(y,x),rt[x]=merge(rt[x],rt[y],1,n);
}
signed main(){
scanf("%s%d",s+1,&q),n=strlen(s+1);
for(int i=1;i<=n;i++) S.insert(s[i]-'a'),modify(rt[S.lst],1,n,i);
for(int i=1;i<=S.tot;i++) v[S.fa[i]].push_back(i);
dfs(1,0);
while(q--){
scanf("%s%d%d",s+1,&l,&r),m=strlen(s+1),T.clear(),ans=0;
for(int i=1;i<=m;i++) T.insert(s[i]-'a'),pos[T.lst]=i;
int p=1,len=0;
for(int i=1;i<=m;i++){
while(1){
int x=S.ch[p][s[i]-'a'];
if(x&&query(rt[x],1,n,l+len,r)){p=x,len++;break;}
if(!len) break;
if(--len==S.len[S.fa[p]]) p=S.fa[p];
}
f[i]=len;
}
for(int i=2;i<=T.tot;i++) ans+=max(T.len[i]-max(f[pos[i]],T.len[T.fa[i]]),0);
printf("%lld\n",ans);
}
return 0;
}
CF204E Little Elephant and Strings(*2800)
给出 \(n\) 个字符串 \(s_{1\sim n}\),对于每个 \(s_i\),求有多少个它的子串出现在至少 \(k\) 个字符串中。
\(1\leq n,k\leq 10^5\),\(\sum|s_i|\leq 10^5\)。
对所有 \(s_i\) 建立广义 SAM,对于每个节点维护一棵线段树表示它属于了的字符串。在 Parent 树上从下往上合并,若属于字符串的数量 \(\geq k\),就打上标记。
然后再从上往下走,每个节点产生的贡献,就是 Parent 树上离它最近的有标记的祖先的 \(|\max(p)|\),因为若 \(p\) 出现在至少 \(\geq k\) 个字符串中,\(p\) 的祖先肯定也是。
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+5;
int n,m,k,tot=1,lst,ch[N][27],fa[N],len[N],cnt,rt[N],lc[N<<5],rc[N<<5],val[N<<5];
long long ans[N];
char s[N];
vector<int>v[N],q[N];
int insert(int c,int lst){
int p=lst,x=0;
if(!ch[p][c]){
x=++tot,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
}
if(!p) return fa[x]=1,x;
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,x?x:q;
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
len[Q]=len[p]+1,fa[Q]=fa[q],fa[x]=fa[q]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
return x?x:Q;
}
void modify(int &p,int l,int r,int pos){
if(!p) p=++cnt;
if(l==r){val[p]=1;return ;}
int mid=(l+r)/2;
if(pos<=mid) modify(lc[p],l,mid,pos);
else modify(rc[p],mid+1,r,pos);
val[p]=val[lc[p]]+val[rc[p]];
}
int merge(int x,int y,int l,int r){
if(!x||!y) return x|y;
int p=++cnt,mid=(l+r)/2;
if(l==r){val[p]=val[x]|val[y];return p;}
lc[p]=merge(lc[x],lc[y],l,mid);
rc[p]=merge(rc[x],rc[y],mid+1,r);
val[p]=val[lc[p]]+val[rc[p]];
return p;
}
void dfs(int x){
for(int y:v[x]) dfs(y),rt[x]=merge(rt[x],rt[y],1,n);
}
void dfs2(int x,int res){
if(val[rt[x]]>=k) res=len[x];
for(int y:v[x]) dfs2(y,res);
for(int i:q[x]) ans[i]+=res;
}
signed main(){
scanf("%d%d",&n,&k);
for(int i=1;i<=n;i++){
scanf("%s",s+1),m=strlen(s+1),lst=1;
for(int j=1;j<=m;j++)
lst=insert(s[j]-'a',lst),modify(rt[lst],1,n,i),q[lst].push_back(i);
}
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1),dfs2(1,0);
for(int i=1;i<=n;i++) printf("%lld ",ans[i]);
return 0;
}
CF666E Forensic Examination(*3100)
给出字符串 \(s\) 和 \(m\) 个模式串 \(t_1\sim t_m\),\(q\) 次询问,每次询问 \(s[p_l:p_r]\) 在 \(t_l\sim t_r\) 中哪个串里出现次数最多,并输出出现次数。
多解输出下标最小的 \(t\)。
\(1\leq |s|,q\leq 5\times 10^5\),\(1\leq m,\sum |t_i|\leq 5\times 10^4\)。
对 \(s\) 和所有 \(t_i\) 建立广义 SAM。
在建 SAM 时记录 \(s\) 的每个前缀在 SAM 中对应的状态。\(s[p_l:p_r]\) 是 \(s[1:p_r]\) 的一个后缀,对应状态是 \(s[1:p_r]\) Parent 树上的祖先。从 \(s[1:p_r]\) 的对应状态在 Parent 树上倍增,就可以得到 \(s[p_l:p_r]\) 对应状态。
设 \(s[p_l:p_r]\) 的对应状态为 \(p\),那我们还需找到一个最小的 \(i\in[l,r]\),使得 \(p\) 的子树中 \(t_i\) 每个前缀的结束状态个数最大。对每一个状态都建立一棵线段树,维护当这个状态作为 \(s[p_l:p_r]\) 对应状态时的答案(区间最大值、区间最大值对应的最小编号)。在线构建 SAM 时在对应状态的线段树上插入 \(t\) 的下标,线段树合并更新信息。
查询 \(p\) 对应状态线段树上区间 \([l,r]\) 的答案即可。
#include<bits/stdc++.h>
using namespace std;
const int N=1.2e6+5;
int n,m,t,tot=1,lst,len[N],fa[N],ch[N][26],pos[N],f[N][22],cnt,rt[N],lc[N<<4],rc[N<<4];
char a[N],b[N];
vector<int>v[N];
pair<int,int>s[N<<4];
int insert(int c,int lst){
int p=lst,x=0;
if(!ch[p][c]){
x=++tot,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
}
if(!p){fa[x]=1;return x;}
int q=ch[p][c],Q=0;
if(len[q]==len[p]+1){fa[x]=q;return x?x:q;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
return x?x:Q;
}
void pushup(int p){s[p]=max(s[lc[p]],s[rc[p]]);}
void modify(int &p,int l,int r,int pos){
if(!p) p=++cnt;
if(l==r){s[p].first++,s[p].second=-l;return ;}
int mid=(l+r)/2;
if(pos<=mid) modify(lc[p],l,mid,pos);
else modify(rc[p],mid+1,r,pos);
pushup(p);
}
int merge(int x,int y,int l,int r){
if(!x||!y) return x|y;
int p=++cnt,mid=(l+r)/2;
if(l==r) return s[p]=s[x],s[p].first+=s[y].first,p;
lc[p]=merge(lc[x],lc[y],l,mid);
rc[p]=merge(rc[x],rc[y],mid+1,r);
return pushup(p),p;
}
auto query(int p,int l,int r,int lx,int rx){
if(!p) return make_pair(0,0);
if(l>=lx&&r<=rx) return s[p];
int mid=(l+r)/2; auto ans=make_pair(0,0);
if(lx<=mid) ans=max(ans,query(lc[p],l,mid,lx,rx));
if(rx>mid) ans=max(ans,query(rc[p],mid+1,r,lx,rx));
return ans;
}
void dfs(int x,int fa){
for(int i=0;i<=19;i++) f[x][i+1]=f[f[x][i]][i];
for(int y:v[x])
if(y!=fa) f[y][0]=x,dfs(y,x),rt[x]=merge(rt[x],rt[y],1,m);
}
signed main(){
scanf("%s%d",a+1,&m),n=strlen(a+1);
for(int i=1;i<=m;i++){
scanf("%s",b+1),lst=1;
int len=strlen(b+1);
for(int j=1;j<=len;j++) lst=insert(b[j]-'a',lst),modify(rt[lst],1,m,i);
}
lst=1;
for(int i=1;i<=n;i++) pos[i]=lst=insert(a[i]-'a',lst);
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1,0),scanf("%d",&t);
while(t--){
int l,r,x,y;
scanf("%d%d%d%d",&l,&r,&x,&y);
auto get=[&](int l,int r){
int x=pos[r];
for(int i=20;i>=0;i--)
if(f[x][i]&&len[f[x][i]]>=r-l+1) x=f[x][i];
return x;
};
auto ans=query(rt[get(x,y)],1,m,l,r);
printf("%d %d\n",!ans.first?l:-ans.second,ans.first);
}
return 0;
}
CF700E Cool Slogans(*3300)
给出一个长度为 \(n\) 的字符串 \(s\),要构造一个最长的字符串 \(t_{1\sim k}\),满足:
- 对于 \(i\in[1,k]\),\(t_i\) 为 \(s\) 的子串。
- 对于 \(i\in[2,k]\),\(t_{i-1}\) 在 \(t_i\) 中出现了至少两次。
\(1\leq n\leq 2\times 10^5\)。
对 \(s\) 建立 SAM,用线段树合并求出每个节点的 \(\text{endpos}\) 集合。
在 Parent 树上从根向下 DP,设 \(f_i\) 表示到节点 \(i\) 时的最大值。
如果一个父节点的子串在子节点的子串中出现了至少两次,则转移时 \(f\) 加一,否则不变。
考虑如何判断是否出现了至少两次。如果 \(t_2\) 在 \(t_1\) 中出现了两次,那么在 \(t_1\) 在 \(s\) 出现的每个地方,\(t_2\) 都出现了两次。
找到 \(x\) 对应的 \(\text{endpos}\) 中的任意一个位置 \(pos\),则 \(pos\) 处的 \(fa_x\) 的子串一定出现了一次。那么另一次只要在 \([pos-len_x+len_{fa_x},pos-1]\) 中有出现就行了。
时间复杂度 \(\mathcal O(n\log n)\)。
#include<bits/stdc++.h>
using namespace std;
const int N=4e5+5;
int n,tot=1,lst=1,ch[N][27],fa[N],f[N],top[N],len[N],ed[N],cnt,rt[N],lc[N<<5],rc[N<<5],ans;
char s[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
ed[Q]=ed[q],fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; //ed[Q]=ed[q]!
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void modify(int &p,int l,int r,int pos){
if(!p) p=++cnt;
if(l==r) return ;
int mid=(l+r)/2;
if(pos<=mid) modify(lc[p],l,mid,pos);
else modify(rc[p],mid+1,r,pos);
}
int merge(int x,int y,int l,int r){
if(!x||!y) return x|y;
int p=++cnt,mid=(l+r)/2;
if(l==r) return p;
lc[p]=merge(lc[x],lc[y],l,mid);
rc[p]=merge(rc[x],rc[y],mid+1,r);
return p;
}
int query(int p,int l,int r,int lx,int rx){
if(!p) return 0;
if(l>=lx&&r<=rx) return 1;
int mid=(l+r)/2,ans=0;
if(lx<=mid) ans|=query(lc[p],l,mid,lx,rx);
if(rx>mid) ans|=query(rc[p],mid+1,r,lx,rx);
return ans;
}
void dfs1(int x){
for(int y:v[x]) dfs1(y),rt[x]=merge(rt[x],rt[y],1,n);
}
void dfs2(int x){
if(x==1) f[x]=0;
else if(fa[x]==1) f[x]=1,top[x]=x;
else{
if(query(rt[top[fa[x]]],1,n,ed[x]-len[x]+len[top[fa[x]]],ed[x]-1)) f[x]=f[fa[x]]+1,top[x]=x;
else f[x]=f[fa[x]],top[x]=top[fa[x]];
}
ans=max(ans,f[x]);
for(int y:v[x]) dfs2(y);
}
signed main(){
scanf("%d%s",&n,s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a'),modify(rt[lst],1,n,ed[lst]=i);
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs1(1),dfs2(1),printf("%d\n",ans);
return 0;
}
P4022 [CTSC2012]熟悉的文章
给出字典 \(t_{1,2,\cdots,m}\),\(n\) 次询问,每次给出一个字符串 \(s\),你可以将 \(s\) 分为若干段,使得所有在字典的某个串中出现过、长度 \(\geq l\) 的子段,长度之和 \(\geq 0.9|s|\),求符合条件的 \(l\) 的最大值。
输入文件的长度 \(\leq 1.1\times 10^6\)。
首先答案具有可二分性,问题转化为,给定 \(l\),求符合条件子段的长度之和。
设 \(f_i\) 表示 \(s[1:i]\) 能匹配的最大长度之和,那么 \(f_i=\max(f_{i-1},\max\limits_{j=i-len_i}^{i-l}f_j+i-j)\),其中 \(len_i\) 表示 \(s[1:r]\) 在字典中的最大匹配长度。对所有 \(t_i\) 建立广义 SAM,将 \(s\) 放在广义 SAM 上跑,在失配时跳 Parent 树,对每个位置记录终止节点的 \(|\max(p)|\) 即可(类似于求两个串的最长公共子串那样)。
因为每向右移动一位,\(len\) 最多增加一位,所以 \(i-len_i\) 单调不减,那么维护 \(f_j-j\) 的单调递减队列,单调队列优化 DP 就好了。
#include<bits/stdc++.h>
using namespace std;
const int N=2.2e6+5;
int t,n,m,lst,tot=1,ch[N][2],fa[N],len[N],q[N],f[N],mxl[N];
char s[N];
int insert(int c,int lst){
int p=lst,x=0;
if(!ch[p][c]){
x=++tot,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
}
if(!p) return fa[x]=1,x;
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,x?x:q;
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
len[Q]=len[p]+1,fa[Q]=fa[q],fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
return x?x:Q;
}
int calc(int x){
int l=1,r=0;
fill(f+1,f+1+n,0),q[1]=0;
for(int i=x;i<=n;i++){
f[i]=f[i-1];
while(l<=r&&f[i-x]-(i-x)>f[q[r]]-q[r]) r--;
q[++r]=i-x;
while(l<=r&&q[l]<i-mxl[i]) l++;
if(l<=r) f[i]=max(f[i],f[q[l]]+i-q[l]);
}
return f[n];
}
signed main(){
scanf("%d%d",&t,&m);
for(int i=1,len;i<=m;i++){
scanf("%s",s+1),lst=1,len=strlen(s+1);
for(int j=1;j<=len;j++) lst=insert(s[j]-'0',lst);
}
for(int i=1;i<=t;i++){
scanf("%s",s+1),n=strlen(s+1);
for(int j=1,p=1,l=0;j<=n;j++){
int c=s[j]-'0';
while(p&&!ch[p][c]) p=fa[p],l=len[p];
if(!p) p=1,l=0;
else p=ch[p][c],l++; mxl[j]=l;
}
int l=0,r=n,ans=0;
while(l<=r){
int mid=(l+r)/2;
if(calc(mid)>=n*0.9) ans=mid,l=mid+1;
else r=mid-1;
}
printf("%d\n",ans);
}
return 0;
}
CF616F Expensive Strings(*2700)
给出 \(t_{1\sim n}\) 和 \(c_{1\sim n}\),求 \(\max f(s)=\sum_{i=1}^n c_i\times p_{s,i}\times |s|\) 的最大值,其中 \(s\) 为任意字符串,\(p_{s,i}\) 为 \(s\) 在 \(t_i\) 中的出现次数。
\(1\leq n\leq 10^5\),\(-10^7\leq c_i\leq 10^7\),\(\sum |t_i|\leq 5\times 10^5\)。
如果 \(s\) 没有在 \(t_i\) 中出现过,\(f(s)=0\)(所以答案的初始值应赋为 \(0\) 而不是 \(-\infty\))。
然后考虑 \(s\) 在 \(t_i\) 中出现过的情况。对所有 \(t_i\) 建立广义 SAM。
考虑 SAM 上每个状态所表示的意义:出现位置相同的字符串集合。也就是说,对于 SAM 上的一个状态 \(x\),它所表示的所有字符串 \(s\) 的 \(\sum_{i=1}^n c_i\times p_{s,i}\) 是相同的,所以它对答案的可能贡献就是 \(\sum_{i=1}^n c_i\times p_{s,i}\times |\max(x)|\)。\(\sum_{i=1}^n c_i\times p_{s,i}\) 可以直接在 Parent 树上树形 DP 求出。
#include<bits/stdc++.h>
using namespace std;
const int N=1e6+5;
int n,m,x,lst,tot=1,ch[N][27],fa[N],len[N];
long long val[N],ans;
char s[N];
vector<int>pos[N],v[N];
int insert(int c,int lst){
int p=lst,x=0;
if(!ch[p][c]){
x=++tot,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
}
if(!p) return fa[x]=1,x;
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,x?x:q;
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
len[Q]=len[p]+1,fa[Q]=fa[q],fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
return x?x:Q;
}
void dfs(int x){
for(int y:v[x]) dfs(y),val[x]+=val[y];
}
signed main(){
scanf("%d",&n);
for(int i=1;i<=n;i++){
scanf("%s",s+1),lst=1,m=strlen(s+1);
for(int j=1;j<=m;j++)
lst=insert(s[j]-'a',lst),pos[i].push_back(lst);
}
for(int i=1;i<=n;i++){
scanf("%d",&x);
for(int j:pos[i]) val[j]+=x;
}
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1);
for(int i=1;i<=tot;i++) ans=max(ans,len[i]*val[i]);
printf("%lld\n",ans);
return 0;
}
CF653F Paper task(*2600)
给出一个长度为 \(n\) 的括号串 \(s\) ,求有多少种本质不同的合法括号子串。
\(n\leq 5\times 10^5\)。
首先设 ( 为 \(1\)、) 为 \(-1\),做一个前缀和得到 \(s_i\)。
先考虑没有“本质不同”怎么做。若 \([l,r]\) 为合法括号子串,则 \(s_{l-1}=s_r\),\(\forall i\in[l,r],s_i\geq s_{l-1}\)。可以预处理每种前缀和的所有位置,存到 vector 里。枚举 \(r\),在 \(s_r\) 对应的 vector 里二分出最小的 \(l-1\)(满足 \(\min\limits_{l\leq i\leq r} s_i\geq s_{l-1}=s_r\),也就是说,如果设 \(r\) 左边第一个 \(<s_r\) 的是 \(k\),那么 \(l>k\),直接单调栈维护就行了)。
计算本质不同子串,可以想到 SAM。对 \(s\) 建立 SAM,对于状态 \(x\),考虑 \(x\) 代表的子串对答案的贡献。我们从它对应的 \(\text{endpos}\) 中随便选一个,作为合法括号子串的右端点,不妨设为 \(pos\),那么我们二分出最小的 \(l\in[pos-len_x+1,pos-len_{fa}]\),和上面的方法一样做即可。
#include<bits/stdc++.h>
using namespace std;
const int N=1e6+5;
int n,s[N],top,st[N],L[N],ed[N],tot=1,lst=1,fa[N],ch[N][2],len[N];
long long ans;
char a[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p) return fa[x]=1,void();
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,void();
Q=++tot,ed[Q]=ed[q],memcpy(ch[Q],ch[q],sizeof(ch[q])); //ed[Q]=ed[q]!
len[Q]=len[p]+1,fa[Q]=fa[q],fa[x]=fa[q]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
signed main(){
scanf("%d%s",&n,a+1),v[n].push_back(0);
for(int i=1;i<=n;i++){
insert(a[i]=='('),s[i]=s[i-1]+(a[i]=='('?1:-1);
ed[lst]=i,v[n+s[i]].push_back(i);
while(top&&s[st[top]]>=s[i]) top--;
L[i]=st[top],st[++top]=i;
}
for(int i=2;i<=tot;i++){
int r=ed[i],x=n+s[r],pos=lower_bound(v[x].begin(),v[x].end(),r)-v[x].begin();
auto calc=[&](int l){
return pos-(lower_bound(v[x].begin(),v[x].end(),max(l-1,L[r]))-v[x].begin());
};
ans+=calc(r-len[i]+1)-calc(r-len[fa[i]]+1);
}
printf("%lld\n",ans);
return 0;
}
P4094 [HEOI2016/TJOI2016]字符串
给出一个长度为 \(n\) 的字符串 \(s\),\(m\) 次询问,每次询问 \(s[a:b]\) 的所有子串和 \(s[c:d]\) 的 LCP 长度的最大值。
\(1\leq n,m\leq 10^5\)。
对于每一个询问,答案满足单调性,考虑二分答案。现在要 check \(s[c:c+mid-1]\) 是否在 \(s[a:b]\) 中出现过(也就是某个 \(\text{endpos}\) 在 \([a+mid-1,b]\) 中)。
对 \(s\) 建立 SAM,线段树合并维护 \(\text{endpos}\),记录每个前缀的对应状态,在 Parent 树上倍增得到子串 \(s[c:c+mid-1]\) 的状态 \(p\),看 \(p\) 某个 \(\text{endpos}\) 在 \([a+mid-1,b]\) 中即可。
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+5;
int n,m,tot=1,lst=1,pos[N],len[N],fa[N],ch[N][27],cnt,rt[N],lc[N<<5],rc[N<<5],f[N][25];
char s[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p) return fa[x]=1,void();
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,void();
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
len[Q]=len[p]+1,fa[Q]=fa[q],fa[x]=fa[q]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void modify(int &p,int l,int r,int pos){
if(!p) p=++cnt;
if(l==r) return ;
int mid=(l+r)/2;
if(pos<=mid) modify(lc[p],l,mid,pos);
else modify(rc[p],mid+1,r,pos);
}
int merge(int x,int y,int l,int r){
if(!x||!y) return x|y;
int p=++cnt,mid=(l+r)/2;
if(l==r) return p;
lc[p]=merge(lc[x],lc[y],l,mid);
rc[p]=merge(rc[x],rc[y],mid+1,r);
return p;
}
int query(int p,int l,int r,int lx,int rx){
if(!p) return 0;
if(l>=lx&&r<=rx) return 1;
int mid=(l+r)/2,ans=0;
if(lx<=mid) ans|=query(lc[p],l,mid,lx,rx);
if(rx>mid) ans|=query(rc[p],mid+1,r,lx,rx);
return ans;
}
void dfs(int x,int fa){
for(int i=0;i<=19;i++) f[x][i+1]=f[f[x][i]][i];
for(int y:v[x])
if(y!=fa) f[y][0]=x,dfs(y,x),rt[x]=merge(rt[x],rt[y],1,n);
}
signed main(){
scanf("%d%d%s",&n,&m,s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a'),pos[i]=lst,modify(rt[lst],1,n,i);
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1,0);
while(m--){
int a,b,c,d;
scanf("%d%d%d%d",&a,&b,&c,&d);
auto get=[&](int l,int r){
int x=pos[r];
for(int i=20;i>=0;i--)
if(f[x][i]&&len[f[x][i]]>=r-l+1) x=f[x][i];
return x;
};
int l=1,r=min(b-a+1,d-c+1),ans=0;
while(l<=r){
int mid=(l+r)/2;
if(query(rt[get(c,c+mid-1)],1,n,a+mid-1,b)) ans=mid,l=mid+1;
else r=mid-1;
}
printf("%d\n",ans);
}
return 0;
}
P5284 [十二省联考 2019] 字符串问题
给出一个长度为 \(n\) 的串 \(s\)。有 \(n_a\) 个 A 类串,\(n_b\) 个 B 类串,都是 \(s\) 的子串,以区间的形式给出。
有 \(m\) 个支配关系,形如第 \(i\) 个 A 类串支配第 \(j\) 个 B 类串。
你需要求出最长的字符串 \(t\) 的长度,使得 \(t\) 可以被划分成若干个 A 类串的拼接,并且相邻两个 A 类串 \(t_i\) 和 \(t_{i+1}\) 满足 \(t_i\) 支配某个 B 类串 \(j\),而 \(j\) 是 \(t_{i+1}\) 的前缀。
如果 \(t\) 可以无限长,输出 \(-1\)。
\(n,m,n_a,n_b\leq 2\times 10^5\)。
首先构建出图论模型:
- 若 \(x\) 支配 \(y\) 则将 \(A_x\) 向 \(B_y\) 连边。
- 若 \(B_j\) 是 \(A_i\) 的前缀,将 \(B_j\) 向 \(A_i\) 连边。
每个 \(A_i\) 权值为其长度,\(B_i\) 权值为 \(0\),那么拓扑排序求出最长路就是答案。如果出现环输出 \(-1\)。Hash 判前缀,复杂度 \(\mathcal O(n^2)\),复杂度瓶颈在建二类边上(需枚举 \(A_i,B_j\))。
\(i\to j\to k\),\(i\) 支配 \(j\),\(j\) 是 \(k\) 的前缀;\(i\to j\) 这样的边只会有 \(m\) 条,只需考虑优化 \(j\to k\) 这种边。考虑怎么优化建图。
前缀不好处理,将 \(s\) 翻转,这样前缀就变为了后缀,在反串中 \(j\) 是 \(k\) 的后缀。对反串 \(s'\) 建立 SAM,那么对于一个节点 \(k\),满足条件的 \(j\) 有两种,一是 \(k\) 在 Parent 树上的祖先,二是与 \(k\) 在同一节点且长度 \(<k\) 的串。
第一类直接从父亲向儿子连边即可,考虑怎么处理第二类。
不妨对每个节点开一个 vector 记录这个节点代表的所有 \(A,B\) 串(可以倍增找到代表每个 \(A,B\) 串的节点,然后把这个串加到对应节点的 vector 里)。对于每个节点,将它 vector 中的串按长度为第一关键字、是否为 \(B\) 串为第二关键字从小到大排序,然后每个 \(B\) 串向第一个比它长的 \(B\) 串(记为 \(S\))连边,并向每个比它长、比 \(S\) 短的 \(A\) 串连边即可。容易发现这样边数是 \(\mathcal O(n)\) 的,并且每个 \(B\) 串和比它长的 \(A\) 串都有连边(直接或间接,并且间接的是通过没有权值贡献的 \(B\) 串,不会对答案产生影响)。如果把每个 \(B\) 串看作一个点,那么每个 \(B\) 串管辖它和它右边那个点中间一块的 \(A\) 串,并且将相邻两个 \(B\) 串连起来使所有 \(AB\) 串串起来。
#include<bits/stdc++.h>
#define LL long long
using namespace std;
const int N=8e5+5;
int t,n,m,a[N],b[N],x,y,tot,lst,cnt,fa[N],ch[N][27],pos[N],len[N],f[N][25],isa[N],in[N],tmp[N];
LL d[N];
char s[N];
vector<int>g[N],v[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p) return fa[x]=1,void();
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,void();
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
len[Q]=len[p]+1,fa[Q]=fa[q],fa[x]=fa[q]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void get(int l,int r){
l=n-l+1,r=n-r+1,swap(l,r);
int x=pos[r];
for(int i=20;i>=0;i--)
if(f[x][i]&&len[f[x][i]]>=r-l+1) x=f[x][i];
len[++cnt]=r-l+1,v[x].push_back(cnt);
}
void add(int x,int y){g[x].push_back(y),in[y]++;}
LL topo(){
queue<int>q; LL ans=0;
for(int i=1;i<=cnt;i++){if(!isa[i]) len[i]=0; if(!in[i]) q.push(i);}
while(q.size()){
int x=q.front();
ans=max(ans,d[x]+len[x]),q.pop();
for(int y:g[x]){
d[y]=max(d[y],d[x]+len[x]);
if(!--in[y]) q.push(y);
}
}
for(int i=1;i<=cnt;i++) if(in[i]) return -1;
return ans;
}
signed main(){
scanf("%d",&t);
while(t--){
scanf("%s",s+1),n=strlen(s+1);
reverse(s+1,s+1+n),tot=lst=1;
for(int i=1;i<=n;i++) insert(s[i]-'a'),pos[i]=lst;
for(int i=1;i<=tot;i++) f[i][0]=fa[i];
for(int j=0;j<=19;j++)
for(int i=1;i<=tot;i++) f[i][j+1]=f[f[i][j]][j];
scanf("%d",&m),cnt=tot;
for(int i=1;i<=m;i++)
scanf("%d%d",&x,&y),get(x,y),isa[a[i]=cnt]=1;
scanf("%d",&m);
for(int i=1;i<=m;i++)
scanf("%d%d",&x,&y),get(x,y),isa[b[i]=cnt]=0;
for(int i=1;i<=tot;i++){
int lst=i;
sort(v[i].begin(),v[i].end(),[](int x,int y){return len[x]==len[y]?isa[x]<isa[y]:len[x]<len[y];});
for(int j:v[i]) add(lst,j),lst=!isa[j]?j:lst; //对于每个 B 串,设第一个比它长的 B 串是 S,那么它向比它长(说明这个 B 串是 A 串的后缀)、比 S 短的 A 串连边,向 S 连边
tmp[i]=lst; //记录 i 代表的最长 B 串
}
for(int i=2;i<=tot;i++) add(tmp[fa[i]],i); //fa[i] 代表的最长 B 串是节点 i 代表的所有串的后缀。节点 i 中,i 连向 i 代表的串中:1. 最短的 B 串;2. 一些短的 A 串,没有 i 代表的 B 串比它短(即没有 i 代表的 B 串是它的后缀)。符合我们的连边条件:如果把每个 B 串看作一个点,那么每个 B 串管辖它和它右边那个点中间一块的 A 串,并且将相邻两个 B 串连起来使所有 AB 串串起来。
scanf("%d",&m);
while(m--) scanf("%d%d",&x,&y),add(a[x],b[y]);
printf("%lld\n",topo());
for(int i=1;i<=tot;i++) fa[i]=0,fill(ch[i],ch[i]+26,0),v[i].clear();
for(int i=1;i<=cnt;i++) g[i].clear(),d[i]=len[i]=isa[i]=in[i]=0;
}
return 0;
}
CF235C Cyclical Quest(*2700)
给出一个字符串 \(s\),\(n\) 次询问,每次给出字符串 \(t\),求 \(t\) 所有循环同构串去重后在 \(s\) 中的出现次数之和。
\(|s|,\sum |t|\leq 10^6\),\(1\leq n\leq 10^5\)。
关于循环同构的一个常见套路是将 \(t\) 复制一份在后面,那么 \(t\) 的一个循环同构串就是 \(t+t\) 的一个长度为 \(|t|\) 的子串。
对 \(s\) 建立 SAM,记录每个节点 \(\text{endpos}\) 的大小。把 \(t+t\) 放到 SAM 上跑匹配,我们知道 SAM 中从起始状态跑出来的是 \(s\) 的子串,如果当前匹配到状态 \(x\) 且匹配长度为 \(|t|\),意味着当前匹配的这个循环同构串在 \(s\) 中的出现次数为 \(|\text{endpos}(x)|\)。
具体来说,如果当前匹配长度 \(>|t|\),那么不断将匹配长度 \(l\) 减 \(1\),如果当前状态不能表示长度为 \(l\) 的串,就往上跳 \(fa\)。
注意到题目需要去重,同时两个长度为 \(|t|\) 的 \(s\) 的不同子串一定被不同的状态表示,所以计算一个位置贡献后打上标记,后面再遇到这个位置就不算贡献了,每次查询后撤销标记即可(记录打上标记的位置)。
#include<bits/stdc++.h>
using namespace std;
const int N=2e6+5;
int n,q,tot=1,lst=1,ch[N][27],fa[N],len[N],sz[N],vis[N],ans;
char s[N];
vector<int>v[N],a;
void insert(int c){
int p=lst,x=lst=++tot;
sz[x]=1,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p) return fa[x]=1,void();
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,void();
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
len[Q]=len[p]+1,fa[Q]=fa[q],fa[x]=fa[q]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void dfs(int x){ //求 |endpos(x)|
for(int y:v[x]) dfs(y),sz[x]+=sz[y];
}
signed main(){
scanf("%s%d",s+1,&q),n=strlen(s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a');
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1);
while(q--){
scanf("%s",s+1),n=strlen(s+1),ans=0;
for(int i=1;i<=n;i++) s[i+n]=s[i];
int p=1,l=0;
for(int i=1;i<2*n;i++){ //注意这里是 <2*n
int c=s[i]-'a';
while(p&&!ch[p][c]) p=fa[p],l=len[p];
if(p){
p=ch[p][c],l++;
while(l>n) if(--l<=len[fa[p]]) p=fa[p]; //如果当前状态不能表示出这个长度为 l 的串,就跳 fa
if(l==n&&!vis[p]) ans+=sz[p],vis[p]=1,a.push_back(p);
}
else p=1,l=0;
}
printf("%d\n",ans);
for(int i:a) vis[i]=0; a.clear();
}
return 0;
}
P2178 [NOI2015] 品酒大会
给出一个长度为 \(n\) 的字符串 \(s\)。
称 \((i,j)\) 是 \(r\) 相似的,当且仅当 \(s[i,i+r-1]=s[j,j+r-1]\)。当然 \(r\) 相似的 \((i,j)\) 同时也是 \(1,2,\cdots,r-1\) 相似的。
对于每个 \(r\in[0,n-1]\),求有多少对 \(r\) 相似的 \((i,j)\),以及 \(r\) 相似的 \((i,j)\) 中 \(a_i\times a_j\) 的最大值(如果不存在,输出
0 0)。\(n\leq 3\times 10^5\),\(|a_i|\leq 10^9\)。
对 \(s\) 的反串建立 SAM,那么 \(x,y\) 的 LCP 就是其在 Parent 树上的 LCA(这是因为,翻转 \(s\) 后,一个串对应节点的祖先都是它原来的前缀,且深度越大长度越长)。
若两个子串的 \(\text{lca}\) 长度为 \(r\),它们就是 \(1,2,\cdots,r\) 相似的。那第一问就是对于每个点,看它是多少个点对的 \(\text{lca}\) 即可。 \(r\) 相似的 \((i,j)\) 同时也是 \(1,2,\cdots,r-1\) 相似的,做一个前缀和即可。
第二问只要在上述点对中找到点权相乘最大的点对即可。注意不仅要存最大值,还要存最小值,因为 \(a_i\) 可能为负,负负得正可能就变为最大的了。
#include<bits/stdc++.h>
using namespace std;
const int N=6e5+5;
int n,a[N],lst=1,tot=1,fa[N],len[N],ch[N][27],sz[N];
long long mx[N],mn[N],ans1[N],ans2[N];
char s[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
sz[x]=1,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p) return fa[x]=1,void();
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,void();
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
len[Q]=len[p]+1,fa[Q]=fa[q],fa[x]=fa[q]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void dfs(int x){
if(!mn[x]&&!mx[x]) mx[x]=-1e18,mn[x]=1e18;
for(int y:v[x]){
dfs(y);
if(mx[x]!=-1e18&&mn[x]!=1e18&&mx[y]!=-1e18&&mn[y]!=1e18) ans2[len[x]]=max(ans2[len[x]],max(mx[x]*mx[y],mn[x]*mn[y]));
mx[x]=max(mx[x],mx[y]),mn[x]=min(mn[x],mn[y]);
ans1[len[x]]+=1ll*sz[x]*sz[y],sz[x]+=sz[y];
}
}
signed main(){
scanf("%d%s",&n,s+1);
for(int i=1;i<=n;i++) scanf("%d",&a[i]);
for(int i=n;i>=1;i--) insert(s[i]-'a'),mn[lst]=mx[lst]=a[i];
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
fill(ans2,ans2+1+n,-1e18),dfs(1);
for(int i=n-1;i>=0;i--)
ans1[i]+=ans1[i+1],ans2[i]=max(ans2[i],ans2[i+1]);
for(int i=0;i<n;i++)
printf("%lld %lld\n",ans1[i],ans2[i]==-1e18?0:ans2[i]);
return 0;
}
P6793 [SNOI2020] 字符串
肯定是要让 LCP 尽量大(LCP 就是其在 Parent 树上的 LCA,类似上一题),在深度较深处合并比较优。
从深往浅考虑每个点,优先匹配其子树内的点,容易发现我们一定要贪心匹配子树内所有能匹配的点,直到只有来自同一个串的点。维护每个点剩的点有多少、来自哪个串即可。
时间复杂度 \(\mathcal O(n)\)。
#include<bits/stdc++.h>
using namespace std;
const int N=6e5+5;
int n,k,tot=1,lst=1,len[N],fa[N],ch[N][27],a[N],b[N];
long long ans;
char s[N],t[N];
vector<int>v[N];
int insert(int c,int lst){
int p=lst,x=0;
if(!ch[p][c]){
x=++tot,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
}
if(!p) return fa[x]=1,x;
int q=ch[p][c],Q=0;
if(len[q]==len[p]+1) return fa[x]=q,x?x:q;
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
len[Q]=len[p]+1,fa[Q]=fa[q],fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
return x?x:Q;
}
void dfs(int x){
for(int y:v[x])
dfs(y),a[x]+=a[y],b[x]+=b[y];
int t=min(a[x],b[x]);
ans+=1ll*t*max(k-len[x],0),a[x]-=t,b[x]-=t;
}
signed main(){
scanf("%d%d%s%s",&n,&k,s+1,t+1);
for(int i=n;i>=1;i--)
lst=insert(s[i]-'a',lst),a[lst]+=(i+k-1<=n);
lst=1;
for(int i=n;i>=1;i--)
lst=insert(t[i]-'a',lst),b[lst]+=(i+k-1<=n);
for(int i=1;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1),printf("%lld\n",ans);
return 0;
}
字符串
给出一个只包含
a到l的小写字母的字符串 \(s\)。你可以选择一个a到l的排列 \(p_a\cdots p_l\),然后令加密结果 \(t\) 为 \(p_{s_1}\cdots p_{s_n}\)。对于每个 \(i\in[1,n]\),判断是否存在一种加密方式 \(p\),满足 \(t\) 中以 \(i\) 开头的后缀是字典序最大的后缀。
\(n\leq 10^5\)。
首先一个 \(\mathcal O(n^2)\) 的做法是,对于后缀 \(i\),枚举后缀 \(j\),找到后缀 \(i,j\) 每个位置一一匹配后第一个不同的字符 \(a,b\),那么 \(i\) 想要加密后字典序更大,必须满足 \(a>b\)。如果没有不同的字符,且 \(i\) 的长度更短,那 \(i\) 的字典序一定更小(如 abb 字典序小于 abba)。这样我们可以得到若干组字母的大小关系,只需判断这些关系有没有构成环即可。找不同字符可以用求 \(\text{lcp}\) 优化。
对反串建立后缀树,那么公共前缀就变成了公共后缀。首先对于一个点 \(x\),如果在 Parent 树上 \(x\) 的子树非空,那么 \(x\) 代表的后缀一定不会成为字典最大的,因为 \(x\) 是它子树中 \(y\) 的后缀,且 \(y\) 的长度更长。
考虑 \(x\) 的两个儿子 \(i,j\),\(x\) 是 \(i,j\) 的后缀,\(x\) 的这一段显然是一样的,第一个不一样的是 \(s_{ed_i-len_x}\) 和 \(s_{ed_j-len_x}\)(\(ed_i\) 表示 \(i\) 的某个 \(\text{endpos}\))。如果 \(i\) 想要字典序更大,必须满足 \(s_{ed_i-len_x}>s_{ed_j-len_x}\),将这个关系挂到 \(i\) 上,等 dfs 到 \(i\) 时,若 \(i\) 子树大小为 \(0\),就取出这些关系更新 \(i\) 代表的后缀的答案(子树大小为 \(0\),说明 \(i\) 没有包含任何节点的 \(\text{endpos}\),\(|\text{endpos}(i)|=1\),\(i\) 是 \(s\) 的一个前缀 \([1,ed_i]\)。当然对应到原串上就是后缀)。
如果 \(i\) 的子树大小非 \(0\) 呢?我们再考虑 \(i\) 的儿子 \(p,q\),如果 \(i\) 的儿子 \(p\) 想要字典序最大,不仅要打败 \(q\),还要保证 \(i\) 能打败 \(j\),这样 \(p\) 才有机会。所以 dfs 的时候儿子要先继承父亲的字母大小关系。
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+5;
int t,n,tot,lst,a,b,len[N],fa[N],ch[N][15],ed[N],in[N],f[N][15][15],c,ans[N];
char s[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p) return fa[x]=1,void();
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,void();
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
ed[Q]=ed[q],len[Q]=len[p]+1,fa[Q]=fa[q],fa[x]=fa[q]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void dfs(int x){
if(!v[x].size()){
queue<int>q; fill(in,in+12,0),c=0;
for(int i=0;i<12;i++)
for(int j=0;j<12;j++) in[j]+=f[x][i][j];
for(int i=0;i<12;i++) if(!in[i]) q.push(i);
while(q.size()){ //拓扑排序判环
int i=q.front();c++,q.pop();
for(int j=0;j<12;j++)
if(f[x][i][j]&&!--in[j]) q.push(j);
}
ans[ed[x]]=(c==12);
}
for(int i:v[x]){ //最大出度是字符集大小,因为后缀树一个节点的儿子数量不超过字符集大小
memcpy(f[i],f[x],sizeof(f[x])); //继承父亲的信息
for(int j:v[x])
if((a=s[ed[i]-len[x]]-'a')!=(b=s[ed[j]-len[x]]-'a')) f[i][a][b]=1; //i 想要字典序更大,要满足 a 的字典序 >b
dfs(i);
}
}
signed main(){
scanf("%d",&t);
while(t--){
scanf("%s",s+1),n=strlen(s+1),tot=lst=1;
reverse(s+1,s+1+n);
for(int i=1;i<=n;i++) insert(s[i]-'a'),ed[lst]=i,ans[i]=0;
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1);
for(int i=1;i<=n;i++) putchar(ans[n-i+1]+'0'); puts("");
for(int i=1;i<=tot;i++)
fa[i]=len[i]=0,fill(ch[i],ch[i]+12,0),v[i].clear(),memset(f[i],0,sizeof(f[i]));
}
return 0;
}
Gym103427M String Problem
给出一个字符串 \(s\),对 \(s\) 的每个非空前缀,求它字典序最大的子串第一次出现的位置。
\(1\leq |s|\leq 10^6\)。
对 \(s\) 建立 SAM。从起点出发,每次选最大的转移边,走出一条路径,这样字典序最大。
注意到 \(s[1:i]\) 字典序最大的子串一定是以 \(i\) 为结尾的,因为两个子串前缀相同时长度更长的肯定更优。
dfs,每次优先走大的转移边,设当前节点 \(x\) 的 \(\text{endpos}(x)\) 中,最小的那个是 \(ed_x\)。如果 \(ans_{ed_x}\) 没有被更新,就令 \(ans_{ed_x}\gets [ed_x-l+1,ed_x]\)。至于 \(\text{endpos}(x)\) 中比 \(ed_x\) 大的位置,总会有一个前缀相同、长度更长的串去更新它。
#include<bits/stdc++.h>
using namespace std;
const int N=2e6+5,M=27;
int n,tot=1,lst=1,ch[N][M],fa[N],len[N],ed[N],ans[N];
bool vis[N];
char s[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p) return fa[x]=1,void();
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,void();
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
ed[Q]=ed[q],len[Q]=len[p]+1,fa[Q]=fa[q],fa[x]=fa[q]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void dfs(int x,int l){
if(vis[x]) return ;
vis[x]=1;
for(int i=25;i>=0;i--)
if(ch[x][i]) dfs(ch[x][i],l+1);
if(!ans[ed[x]]) ans[ed[x]]=ed[x]-l+1;
}
signed main(){
scanf("%s",s+1),n=strlen(s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a'),ed[lst]=i;
dfs(1,0);
for(int i=1;i<=n;i++) printf("%d %d\n",ans[i],i);
return 0;
}
Gym103409J Suffix Automaton
给出一个字符串 \(s\),\(q\) 次询问 \(s\) 本质不同的子串中排名为 \(k\) 的,排名的定义是长度小的先,长度相同字典序小的先,输出对应最先出现的区间。
\(1\leq |s|,q\leq 10^6\),\(1\leq k\leq 10^{12}\)。
首先二分出询问的字符串长度,把询问挂在字符串长度上,用线段树维护每个长度还没有回答的最小字典序询问。
建反串的 SAM,那么每个节点表示的串都是左端点固定的长度连续的串。
按照字典序遍历 SAM,每次让 \([len_{fa_x}+1,len_x]\) 区间 \(-1\),表示之后要求的字典序排名 \(-1\)。如果某个位置 \(=0\) 了就回答询问,并更新线段树上这个位置的值。
#include<bits/stdc++.h>
using namespace std;
const int N=2e6+5;
int n,m,x,tot=1,lst=1,len[N],fa[N],ch[N][27],sz[N],pos[N],ed[N],cur[N],mn[N<<2],tg[N<<2];
long long a[N],k;
char s[N];
pair<int,int>ans[N];
vector<pair<int,int> >q[N];
void insert(int c){
int p=lst,x=lst=++tot;
sz[x]=1,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p) return fa[x]=1,void();
int q=ch[p][c],Q;
if(len[q]==len[p]+1) return fa[x]=q,void();
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
ed[Q]=ed[q],len[Q]=len[p]+1,fa[Q]=fa[q],fa[x]=fa[q]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void down(int p){
if(tg[p]) mn[p<<1]+=tg[p],mn[p<<1|1]+=tg[p],tg[p<<1]+=tg[p],tg[p<<1|1]+=tg[p],tg[p]=0;
}
void modify(int p,int l,int r,int lx,int rx,int v){
if(lx>rx) return ;
if(l>=lx&&r<=rx){mn[p]+=v,tg[p]+=v;return ;}
int mid=(l+r)/2;
down(p);
if(lx<=mid) modify(p<<1,l,mid,lx,rx,v);
if(rx>mid) modify(p<<1|1,mid+1,r,lx,rx,v);
mn[p]=min(mn[p<<1],mn[p<<1|1]);
}
void upd(int p,int l,int r,int pos){
if(l==r){
ans[q[l][cur[l]-1].second]={pos,pos+l-1};
if(cur[l]==(int)q[l].size()) mn[p]=1e9;
else mn[p]=q[l][cur[l]].first-q[l][cur[l]-1].first,cur[l]++;
return ;
}
int mid=(l+r)/2;
down(p);
if(!mn[p<<1]) upd(p<<1,l,mid,pos);
if(!mn[p<<1|1]) upd(p<<1|1,mid+1,r,pos);
mn[p]=min(mn[p<<1],mn[p<<1|1]);
}
void dfs(int x){
modify(1,1,n,len[fa[x]]+1,len[x],-1);
while(!mn[1]) upd(1,1,n,ed[x]);
for(int i=0;i<26;i++) if(ch[x][i]) dfs(ch[x][i]);
}
signed main(){
scanf("%s",s+1),n=strlen(s+1);
for(int i=n;i>=1;i--) insert(s[i]-'a'),pos[i]=lst;
for(int i=1;i<=n;i++){
int x=pos[i];
while(!ed[x]&&x) ed[x]=i,x=fa[x];
}
memset(ch,0,sizeof(ch));
for(int i=2;i<=tot;i++)
a[len[fa[i]]+1]++,a[len[i]+1]--,ch[fa[i]][s[ed[i]+(len[fa[i]]+1)-1]-'a']=i;
for(int i=1;i<=n;i++) a[i]+=a[i-1];
for(int i=1;i<=n;i++) a[i]+=a[i-1];
scanf("%d",&m);
for(int i=1;i<=m;i++){
scanf("%lld",&k);
if(a[n]<k) ans[i]={-1,-1};
else x=lower_bound(a+1,a+1+n,k)-a,q[x].push_back({k-a[x-1],i});
}
for(int i=1;i<=n;i++){
sort(q[i].begin(),q[i].end());
modify(1,1,n,i,i,q[i].size()?q[i][cur[i]++].first:1e9);
}
dfs(1);
for(int i=1;i<=m;i++) printf("%d %d\n",ans[i].first,ans[i].second);
return 0;
}
con
给出一个字符串 \(s\),设 \(t\) 为将 \(s\) 的所有子串按字典序从小到大排序后拼接起来的字符串(如果同个子串出现了多次则也算多次)。
\(q\) 次询问,每次给出 \(k\),求 \(t\) 的第 \(k\) 个字符。
\(1\leq |s|,q\leq 5000\),\(1\leq k\leq |t|\)。
用 SAM 代替 Trie 给所有子串排序(sort 过不了;Trie 数组开不下,但是 SAM 压缩信息后就 ok 啦)。
建出 Parent 树后,一个点所表示的等价类中,所有子串出现的次数都等于 Parent 树上这个节点的子树大小。
#include<bits/stdc++.h>
using namespace std;
const int N=1e4+5,M=1.3e7;
int n,m,x,cnt,tot=1,lst=1,ch[N][27],fa[N],len[N],sz[N],l[M],ed[N];
long long k,a[M];
char s[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
sz[x]=1,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
ed[Q]=ed[q],fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void dfs(int x){
for(int y:v[x]) dfs(y),sz[x]+=sz[y];
}
void dfs2(int x,int d){ //d 是当前字符串长度,以 ed[x] 结尾,出现次数为 sz[x]
if(x>1) for(int i=1;i<=sz[x];i++) l[++cnt]=ed[x]-d+1,a[cnt]=a[cnt-1]+d;
for(int i=0;i<26;i++)
if(ch[x][i]) dfs2(ch[x][i],d+1);
}
signed main(){
scanf("%s%d",s+1,&m),n=strlen(s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a'),ed[lst]=i;
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1),dfs2(1,0);
while(m--){
scanf("%lld",&k),x=lower_bound(a+1,a+1+cnt,k)-a-1;
putchar(s[l[x+1]+(k-a[x])-1]);
}
return 0;
}
String
给出字符串 \(s\) 和一个数 \(k\),求字典序最小的 \(t\),使得 \(t\) 在 \(s\) 中所有出现位置的线段数为 \(k\)。
\(1\leq T\leq 100\),\(1\leq k\leq |s|\leq 10^5\),\(1\leq \sum |s|\leq 10^6\),\(s\) 只包含小写字母。
把 \(t\) 的 \(\text{endpos}\) 拿出来,若相邻两个 \(\text{endpos}\) 之差 \(>|t|\),那么线段数 \(+1\)。SAM 求出 \(\text{endpos}\) 集合,multiset 维护相邻 \(\text{endpos}\) 的差。
若线段数恰好为 \(k\),那么 multiset 中第 \(k-1\) 大的元素 \(>|t|\) 且第 \(k\) 大的元素 \(\leq |t|\)(若第 \(k\) 大存在)。线段树二分求第 \(k\) 大。
SAM 求出后缀树,按 dfs 序编号,自底向上维护 \(\text{endpos}\)(反串的 SAM,实际上就变成 \(\text{beginpos}\) 了),一个节点的 \(\text{endpos}\) 是子树 \(\text{endpos}\) 的并,可以 Dsu on tree。
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+5;
int t,n,k,tot,lst,ch[N][27],fa[N],len[N],ed[N],pos[N],sz[N],son[N],tim,dfn[N],id[N],tmp,f[N],sum[N<<2],tg[N<<2];
char a[N];
string ans;
multiset<int>s;
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
sz[x]=1,len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; //没有 ed[Q]=ed[q],保证维护子树 endpos 并时,一个 ed 只会被加入一次
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void dfs(int x){
sz[x]=1,id[dfn[x]=++tim]=x,pos[x]=ed[x];
for(int y:v[x]){
dfs(y),sz[x]+=sz[y];
if(!pos[x]) pos[x]=pos[y];
if(sz[y]>sz[son[x]]) son[x]=y;
}
}
void clr(int p){tg[p]=1,sum[p]=0;} //打上清空 tag
void down(int p){if(tg[p]) clr(p<<1),clr(p<<1|1),tg[p]=0;}
void modify(int p,int l,int r,int pos,int v){
sum[p]+=v;
if(l==r) return ;
int mid=(l+r)/2;
down(p);
if(pos<=mid) modify(p<<1,l,mid,pos,v);
else modify(p<<1|1,mid+1,r,pos,v);
}
int query(int p,int l,int r,int pos,int v){ //在 >pos 里,找第 v 大的
if(l==r) return v?1e9:l; //保证第 k-1 大的间隔 >pos 而第 k 大的间隔 <=pos
int mid=(l+r)/2;
down(p);
if(pos>mid||sum[p<<1|1]>v) return query(p<<1|1,mid+1,r,pos,v);
return query(p<<1,l,mid,pos,v-sum[p<<1|1]);
}
void add(int x){ //维护 ed 间隔
x=ed[x];
if(!x) return ;
s.insert(x);
auto it=s.lower_bound(x);
if(it!=s.begin()&&it!=s.end()) modify(1,1,n,*next(it)-*prev(it),-1);
if(it!=s.end()) modify(1,1,n,*next(it)-x,1);
if(it!=s.begin()) modify(1,1,n,x-*prev(it),1);
}
void dfs2(int x,bool o){ //Dsu on tree
for(int y:v[x]) if(y!=son[x]) dfs2(y,0);
if(son[x]) dfs2(son[x],1);
for(int y:v[x]) if(y!=son[x])
for(int i=0;i<sz[y];i++) add(id[dfn[y]+i]);
add(id[dfn[x]]);
if((tmp=query(1,1,n,len[fa[x]]+1,k-1))<=len[x]) f[x]=tmp;
if(!o) s.clear(),clr(1); //清空
}
signed main(){
scanf("%d",&t);
while(t--){
scanf("%s%d",a+1,&k),n=strlen(a+1),tim=0;
for(int i=1;i<=tot;i++)
fill(ch[i],ch[i]+26,0),fa[i]=len[i]=son[i]=pos[i]=ed[i]=0,v[i].clear();
tot=lst=1;
for(int i=n;i>=1;i--) insert(a[i]-'a'),ed[lst]=i; //建后缀树(反串的 parent 树)
for(int i=1;i<=tot;i++) v[fa[i]].push_back(i),f[i]=-1;
dfs(1),dfs2(1,0),ans="~";
for(int i=1;i<=tot;i++)
if(~f[i]) ans=min(ans,string(a+pos[i],a+pos[i]+f[i]));
if(ans=="~") puts("-1");
else cout<<ans<<endl;
}
return 0;
}
P4482 [BJWC2018]Border 的四种求法
SAM + 树链剖分 + 线段树合并
给出一个字符串 \(S\),\(q\) 次询问 \(s[l:r]\) 的 border。
\(n,q\leq 2\times 10^5\)。
等价于求最大的 \(i\in[l,r)\) 使得 \(\text{lcs}(i,r)\geq i-l+1\)。放到 Parent 树上,记 \(id_i\) 为 \(s[1:i]\) 的对应节点,那么 \(i\) 合法等价于 \(len_{\text{lca}(id_i,id_r)}\geq i-l+1\)。
一个暴力:枚举 \(id_r\) 的祖先 \(t\) 作为 \(\text{lca}(id_i,id_r)\),那么由于 \(id_i\) 在 \(t\) 的子树内,\(t\) 一定有一个 \(\text{endpos}\) 是 \(i\)(因为 SAM 中一个点的 \(\text{endpos}\) 是子树 \(\text{endpos}\) 的并)。线段树合并维护每个点的 \(\text{endpos}\) 集合。\(len_t\geq i-l+1\Leftrightarrow i\leq len_t+l-1\),于是在 \(t\) 的 \(\text{endpos}\) 集合中二分出最大的 \(i\in[l,r)\) 使得 \(i\leq len_t+l-1\) 即可。这样 \(id_i,id_r\) 一定在 \(t\) 的子树内,而 \(\text{lca}(id_i,id_r)\) 是 \(t\) 的子孙的情况一定比最终的最优答案劣(因为 \(len\) 随深度的减小而减小,\(len_t<len_{\text{lca}(id_i,id_r)}\),限制更紧)。
优化。对 Parent 树轻重链剖分,\(id_r\) 的祖先被划分进一些完整重链和 \(id_r\) 所在重链的一段前缀。离线,将询问挂在这段前缀的末尾节点和其他完整重链的末尾节点上。
对于当前重链上的点 \(t\),由于 \(\text{lca}(id_i,id_r)=t\):
- 若 \(id_r\) 在 \(t\) 的重子树内(什么时候不呢?当 \(t\) 是重链的末尾节点时):\(id_i\) 肯定在 \(t\) 的轻子树并上 \(t\)。\(len_t\geq i-l+1\Leftrightarrow i-len_t+1\leq l\),对于可能的 \(id_i\),在线段树的第 \(i\) 个位置对值 \(i-len_t+1\) 取 \(\min\),从上往下加入每个 \(t\) 对应的 \(id_i\),这样就考虑了重链一段前缀作为 \(\text{lca}\) 的情况,然后取出挂在当前 \(t\) 的询问,在线段树的位置 \([l,r)\) 中二分值 \(\leq l\) 的最大位置 \(i\) 即可。
- 若 \(id_r\) 在 \(t\) 的轻子树内:\(id_i\) 还可以在 \(t\) 的重子树。而 \(id_i\) 和 \(id_r\) 在同个 \(t\) 的轻子树内时肯定比最终的最优答案劣,故直接按暴力所说的方法对这样的 \(t\) 做一遍即可。
时间复杂度 \(\mathcal O(n\log^2 n)\)。
#include<bits/stdc++.h>
using namespace std;
const int N=4e5+5,M=N<<6;
int n,m,l[N],r[N],x,tot=1,lst=1,id[N],ch[N][26],len[N],fa[N],sz[N],son[N],top[N],cnt,ed[N],lc[M],rc[M],mn[M],ans[N];
char s[N];
vector<int>v[N],buc[N],q[N];
void modify(int &p,int l,int r,int pos,int v){
if(!p) mn[p=++cnt]=1e9;
mn[p]=min(mn[p],v);
if(l==r) return ;
int mid=(l+r)/2;
if(pos<=mid) modify(lc[p],l,mid,pos,v);
else modify(rc[p],mid+1,r,pos,v);
}
int query(int p,int l,int r,int lx,int rx,int v){
if(!p||lx>rx||mn[p]>v) return 0;
if(l==r) return l;
int mid=(l+r)/2,tmp=0;
if(rx>mid&&(tmp=query(rc[p],mid+1,r,lx,rx,v))) return tmp;
return lx<=mid?query(lc[p],l,mid,lx,rx,v):0;
}
int merge(int x,int y){
if(!x||!y) return x|y;
int p=++cnt;
mn[p]=min(mn[x],mn[y]);
lc[p]=merge(lc[x],lc[y]),rc[p]=merge(rc[x],rc[y]);
return p;
}
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,copy(ch[q],ch[q]+26,ch[Q]);
len[Q]=len[p]+1,fa[Q]=fa[q],fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void dfs(int x){
sz[x]=1;
for(int y:v[x]){
dfs(y),sz[x]+=sz[y],ed[x]=merge(ed[x],ed[y]);
if(sz[y]>sz[son[x]]) son[x]=y;
}
}
void dfs2(int x,int tp){
top[x]=tp;
if(son[x]) dfs2(son[x],tp);
for(int y:v[x]) if(y!=son[x]) dfs2(y,y);
}
signed main(){
scanf("%s%d",s+1,&m),n=strlen(s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a'),modify(ed[id[i]=lst],1,n,i,i);
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1),dfs2(1,1);
for(int i=1;i<=m;i++){
scanf("%d%d",&l[i],&r[i]),x=id[r[i]];
while(x){
q[x].push_back(i);
ans[i]=max(ans[i],query(ed[x],1,n,l[i],r[i]-1,len[x]+l[i]-1)),x=fa[top[x]];
}
}
for(int i=1;i<=n;i++){
int x=id[i];
buc[x].push_back(i);
while(x) buc[fa[top[x]]].push_back(i),x=fa[top[x]];
}
for(int i=1;i<=tot;i++) if(top[i]==i){
int x=i,rt=0;
for(int j=0;j<=cnt;j++) lc[j]=rc[j]=0; cnt=0;
while(x){
for(int j:buc[x]) modify(rt,1,n,j,j-len[x]+1);
for(int j:q[x]) ans[j]=max(ans[j],query(rt,1,n,l[j],r[j]-1,l[j]));
x=son[x];
}
}
for(int i=1;i<=m;i++) printf("%d\n",max(ans[i]-l[i]+1,0));
return 0;
}
P6292 区间本质不同子串个数
SAM + LCT
扫描线 \(r\),对于一个子串,在它当前最后一次出现的位置 \(lst\) 统计。线段树上 \(seg_l=\sum_{i=l}^r[s[i:r]\ 是最后一次出现]\),也就是一个子串的最后一次出现的右端点 \(lst\) 对 \(seg_{lst-len+1}\) 产生 \(1\) 的贡献。新加入 \(a_r\) 时,只有 \([1,r],[2,r],\cdots,[r,r]\) 的 \(lst\) 改变了,也就是 SAM 上 \(s[1:r]\) 对应状态到根的链 \(lst\) 更新为 \(r\)。
根据珂朵莉树的思想,我们将 \(lst\) 相同的段一起维护。由于要维护链,考虑 LCT 的 access。LCT 中一个 splay 维护一条实链,由于这里一次 access 都赋值成相同的数,显然一条实链中点的 \(lst\) 都相同。access 中,把 splay(x) 后就将 \(x\) 管辖的这一小段一起改了(长度 \((len_{fa_x},len_x]\) 的 \(lst\),其中 \(fa\) 是 LCT 里的 \(fa\),也就是 \(x\) 这段的上面一个点)。
时间复杂度 \(\mathcal O(n\log^2 n)\)。
#include<bits/stdc++.h>
#define ll long long
#define get(x) (ch[fa[x]][0]==x?0:ch[fa[x]][1]==x?1:-1)
using namespace std;
const int N=2e5+5;
int n,m,l,r,pos[N];
ll ans[N];
char s[N];
vector<pair<int,int> >v[N];
namespace SAM{
int tot=1,lst=1,len[N],fa[N],ch[N][27];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,copy(ch[q],ch[q]+26,ch[Q]);
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
}
namespace seg{
ll tg[N<<2],sum[N<<2];
void upd(int p,int l,int r,int v){
tg[p]+=v,sum[p]+=1ll*(r-l+1)*v;
}
void down(int p,int l,int r,int mid){
if(tg[p]) upd(p<<1,l,mid,tg[p]),upd(p<<1|1,mid+1,r,tg[p]),tg[p]=0;
}
void modify(int p,int l,int r,int lx,int rx,int v){
if(l>=lx&&r<=rx) return upd(p,l,r,v);
int mid=(l+r)/2;
down(p,l,r,mid);
if(lx<=mid) modify(p<<1,l,mid,lx,rx,v);
if(rx>mid) modify(p<<1|1,mid+1,r,lx,rx,v);
sum[p]=sum[p<<1]+sum[p<<1|1];
}
ll query(int p,int l,int r,int lx,int rx){
if(l>=lx&&r<=rx) return sum[p];
int mid=(l+r)/2; ll ans=0;
down(p,l,r,mid);
if(lx<=mid) ans=query(p<<1,l,mid,lx,rx);
if(rx>mid) ans+=query(p<<1|1,mid+1,r,lx,rx);
return ans;
}
}
namespace LCT{
int fa[N],ch[N][2],tg[N],val[N];
void upd(int p,int v){tg[p]=val[p]=v;}
void down(int p){
if(tg[p]) upd(ch[p][0],tg[p]),upd(ch[p][1],tg[p]),tg[p]=0;
}
void rotate(int x){
int y=fa[x],z=fa[y],o=get(x);
if(~get(y)) ch[z][get(y)]=x; fa[x]=z;
ch[y][o]=ch[x][o^1],fa[ch[x][o^1]]=y;
ch[x][o^1]=y,fa[y]=x;
}
void dfs(int p){
if(~get(p)) dfs(fa[p]); down(p);
}
void splay(int x){
dfs(x);
for(;~get(x);rotate(x))
if(~get(fa[x])) rotate(get(x)==get(fa[x])?fa[x]:x);
}
void access(int x,int v){
int y=0;
for(;x;x=fa[y=x]){
splay(x),ch[x][1]=y;
if(val[x]) seg::modify(1,1,n,val[x]-SAM::len[x]+1,val[x]-SAM::len[fa[x]],-1);
}
upd(y,v),seg::modify(1,1,n,1,v,1);
}
}
signed main(){
scanf("%s%d",s+1,&m),n=strlen(s+1);
for(int i=1;i<=n;i++)
SAM::insert(s[i]-'a'),pos[i]=SAM::lst;
for(int i=2;i<=SAM::tot;i++) LCT::fa[i]=SAM::fa[i];
for(int i=1;i<=m;i++)
scanf("%d%d",&l,&r),v[r].push_back({l,i});
for(int i=1;i<=n;i++){
LCT::access(pos[i],i);
for(auto p:v[i]) ans[p.second]=seg::query(1,1,n,p.first,i);
}
for(int i=1;i<=m;i++) printf("%lld\n",ans[i]);
return 0;
}
CF1276F Asterisk Substrings(*3400)
SAM + 类似 P5840 求到根路径并 + 线段树合并/启发式合并
给出一个长度为 \(n\) 的字符串 \(s\),称将字符 \(s_i\) 替换为特殊字符 \(\texttt *\) 后的字符串为 \(T_i\),求 \(\{S,T_1,T_2,\cdots,T_n\}\) 这个字符串集合的本质不同子串个数。
(\(\texttt *\) 仅为一个字符,无其他含义,不是通配符)
子串有以下几种形式:\(\varnothing\),\(\texttt *\),\(S\),\(S\texttt *\),\(\texttt * S\),\(S\texttt *T\)。前五种都很容易(比如 \(S\texttt *\) 就是去掉 \(s_n\) 后的本质不同子串计数,因为只要原来的子串未达到末尾就能补上 \(\texttt *\) 成为新串),主要是 \(S\texttt * T\)。
-
两个本质不同的 \(S\texttt * T\) 要么是 \(S\) 不同要么是 \(T\) 不同,考虑枚举 \(S\) 再处理 \(T\) 不同。
对 \(s\) 建立 SAM,枚举 SAM 上每个节点 \(x\),设其 \(\text{endpos}\) 集合为 \(\{p_1,p_2,\cdots,p_k\}\),只需考虑以 \(\{p_1+2,p_2+2,\cdots,p_k+2\}\) 开头的本质不同子串个数(由于 \(\text{endpos}\) 相同,\(x\) 上的所有串能匹配的 \(T\) 是相同的)。
-
对 \(s\) 建立后缀树,设后缀 \(p\) 在后缀树上对应节点 \(pos_p\),那么匹配 \(x\) 的 \(T\) 的个数就是 \(\{pos_{p_1+2},pos_{p_2+2},\cdots,pos_{p_k+2}\}\) 在后缀树上到根的 路径并 长度。
将这些后缀按 dfs 序排序,依次加入,上一次插入 \(x\),这一次插入 \(y\),新增的长度就是 \(d_y-d_{\text{lca}(x,y)}\)。
因为 SAM 上父亲能继承儿子的 \(\text{endpos}\),可以线段树合并维护后缀树 dfs 序,pushup 时减去左儿子最右边的点与右儿子最左边的点的 \(d_{\text{lca}}\)。当然也可以启发式合并。
时间复杂度 \(\mathcal O(n\log n)\)(因为可以预处理来 \(\mathcal O(1)\) 查询 LCA)。
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+5,M=N<<6;
int n,tot,lst,len[N],fa[N],ch[N][27],p1[N],p2[N],tim,dfn[N],id[N],dep[N],f[N][25],d[N],cnt,rt[N],mx[M],mn[M],lc[M],rc[M];
char s[N];
long long sum[M],ans=2;
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,copy(ch[q],ch[q]+26,ch[Q]);
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void dfs(int x){
id[dfn[x]=++tim]=x,dep[x]=dep[fa[x]]+1;
for(int i=0;i<=19;i++) f[x][i+1]=f[f[x][i]][i];
for(int y:v[x]) f[y][0]=x,dfs(y);
}
int lca(int x,int y){
if(dep[x]<dep[y]) swap(x,y);
for(int i=20;i>=0;i--) if(dep[f[x][i]]>=dep[y]) x=f[x][i];
if(x==y) return x;
for(int i=20;i>=0;i--)
if(f[x][i]!=f[y][i]) x=f[x][i],y=f[y][i];
return f[x][0];
}
void modify(int &p,int l,int r,int pos){
p=++cnt,mx[p]=mn[p]=pos,sum[p]=d[id[pos]];
if(l==r) return ;
int mid=(l+r)/2;
if(pos<=mid) modify(lc[p],l,mid,pos);
else modify(rc[p],mid+1,r,pos);
}
int merge(int x,int y){
if(!x||!y) return x|y;
lc[x]=merge(lc[x],lc[y]);
rc[x]=merge(rc[x],rc[y]);
mx[x]=max(mx[lc[x]],mx[rc[x]]),mn[x]=min(mn[lc[x]],mn[rc[x]]);
sum[x]=sum[lc[x]]+sum[rc[x]]-(lc[x]&&rc[x]?d[lca(id[mx[lc[x]]],id[mn[rc[x]]])]:0);
return x;
}
void dfs2(int x){
if(p1[x]&&p1[x]+2<=n) modify(rt[x],1,tim,dfn[p2[p1[x]+2]]);
for(int y:v[x])
dfs2(y),rt[x]=merge(rt[x],rt[y]);
ans+=1ll*(len[x]-len[fa[x]])*sum[rt[x]];
}
signed main(){
scanf("%s",s+1),n=strlen(s+1);
tot=lst=1;
for(int i=n;i>=1;i--)
insert(s[i]-'a'),p2[i]=lst,ans+=(i>1?2:1)*(len[lst]-len[fa[lst]]);
for(int i=2;i<=tot;i++)
v[fa[i]].push_back(i),d[i]=len[i];
dfs(1);
for(int i=1;i<=tot;i++)
len[i]=fa[i]=0,fill(ch[i],ch[i]+26,0),v[i].clear();
tot=lst=1;
for(int i=1;i<=n;i++)
insert(s[i]-'a'),p1[lst]=i,ans+=(i<n?1:0)*(len[lst]-len[fa[lst]]);
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
mn[0]=1e9,dfs2(1),printf("%lld\n",ans);
return 0;
}
后缀数组
\(\mathcal O(n\log^2 n)\):哈希 + 二分。求出 LCP,判 LCP 后一位。
\(\mathcal O(n\log n)\):倍增 + 基数排序。给 \((rk_{j-1}(i),rk_{j-1}(i+2^{j-1}))\) 排序求出 \(sa_j\),表示只考虑后缀的前 \(2^j\) 个字符。
每一轮排序中,用上一轮的 \(rk\) 求出这一轮的 \(sa\),再由这一轮的 \(sa\) 求出它对应的 \(rk\)(由于可能有相同字符串,所以 \(sa(i-1)\) 和 \(sa(i)\) 的二元组不相等时才排名 \(+1\))。
#include<bits/stdc++.h>
using namespace std;
const int N=1e6+5;
int n,m,rk[N],sa[N],t[N],p;
char s[N];
bool cmp(int x,int y){
return rk[x]==rk[y]?(x+m<=n?rk[x+m]:0)<(y+m<=n?rk[y+m]:0):rk[x]<rk[y];
}
signed main(){
scanf("%s",s+1),n=strlen(s+1);
for(int i=1;i<=n;i++) rk[i]=s[i],sa[i]=i;
sort(sa+1,sa+1+n,cmp);
for(int k=1;k<n;k<<=1){ //k=2^{j-1},k->k*2。只要 k*2>=n 即可,所以 k<n 就可以了
m=k,p=0,sort(sa+1,sa+1+n,cmp),copy(rk+1,rk+1+n,t+1); //t 是原先的 rk
for(int i=1;i<=n;i++)
rk[sa[i]]=t[sa[i]]==t[sa[i-1]]&&sa[i]+k<=n&&sa[i-1]+k<=n&&t[sa[i]+k]==t[sa[i-1]+k]?p:++p; //sa[i]+k<=n&&sa[i-1]+k<=n 多组数据时注意
}
for(int i=1;i<=n;i++) printf("%d ",sa[i]);
return 0;
}
优化给二元组排序的过程。
- 求一个新 \(sa\)(设为数组 \(t\)),按第二关键字排序:先把没有第二关键字的排前面。然后,由于排名为 \(i\) 的下标 \(sa_i\) 是下标 \(sa_i-k\) 的第二关键字,所以若 \(sa_i-k>0\) 就把它接后面。
- 按第一关键字排序。若无第二关键字,从后往前扫,
sa[cnt[rk[i]]--]=i,表示rk相同时按下标取。现在,改成sa[cnt[rk[t[i]]]--]=t[i],表示rk相同时按t取。
#include<bits/stdc++.h>
using namespace std;
const int N=1e6+5;
int n,m,rk[N],sa[N],t[N],p,tot,cnt[N];
char s[N];
void rsort(){
fill(cnt+1,cnt+1+m,0);
for(int i=1;i<=n;i++) cnt[rk[i]]++;
for(int i=1;i<=m;i++) cnt[i]+=cnt[i-1];
for(int i=n;i>=1;i--) sa[cnt[rk[t[i]]]--]=t[i];
}
signed main(){
scanf("%s",s+1),n=strlen(s+1),m=max(n,(int)'z');
for(int i=1;i<=n;i++) rk[i]=s[i],t[i]=i; //不是 sa!
rsort();
for(int k=1;k<n;k<<=1){
tot=p=0;
for(int i=n-k+1;i<=n;i++) t[++tot]=i;
for(int i=1;i<=n;i++)
if(sa[i]-k>0) t[++tot]=sa[i]-k;
rsort(),copy(rk+1,rk+1+n,t+1);
for(int i=1;i<=n;i++)
rk[sa[i]]=t[sa[i]]==t[sa[i-1]]&&sa[i]+k<=n&&sa[i-1]+k<=n&&t[sa[i]+k]==t[sa[i-1]+k]?p:++p;
}
for(int i=1;i<=n;i++) printf("%d ",sa[i]);
return 0;
}
H 数组
定义 \(height_i\) 表示后缀 \(sa_i\) 与后缀 \(sa_{i-1}\) 的 LCP 长度,\(h_i\) 表示后缀 \(i\) 与排名在它前一位的后缀的 LCP。\(h_i=height_{rk_i}\),\(height_i=h_{sa_i}\)。
\(h_i\) 可以继承 \(h_{i-1}\),相当于砍掉第一个字符,即 \(h_i\geq h_{i-1}-1\)(后缀 \(i-1\) 和后缀 \(i-1\) 排名前一位的在没砍掉前排名相邻,砍掉后中间可能隔一些,但都有长度为 \(h_{i-1}-1\) 的共同前缀),然后在此基础上暴力扩展。
void getht(){
for(int i=1,k=0;i<=n;i++){
if(k) k--; //h[i]>=h[i-1]-1
int j=sa[rk[i]-1]; //后缀 i 前一个排名的后缀
while(i+k<=n&&j+k<=n&&s[i+k]==s[j+k]) k++;
ht[rk[i]]=k;
}
}
应用:
-
求两个后缀的 LCP
如后缀 \(i,j\),排名 \(rk_i,rk_j\),设 \(l=rk_i,r=rk_j\) 且 \(l<r\),那么 LCP 就是排名为 \(l,l+1,\cdots,r\) 的后缀的共同前缀,即 \(\min(height_{l+1},\cdots,height_r)\)。
int lcp(int x,int y){ if(x==y) return n-x+1; //要特判 x=y x=rk[x],y=rk[y]; if(x>y) swap(x,y); x++; //注意要先保证 x<y 再 x++,否则可能 ++ 的是 y 但是 ++ 到 x 了 return k=__lg(y-x+1),min(f[x][k],f[y-(1<<k)+1][k]); } -
求子串 \(s[l:r]\) 在 \(s\) 中的出现次数
即求有多少后缀,使得它们的前缀是 \(s[l:r]\)。
由于有公共前缀的后缀字典序排在一起,所以对于前缀是 \(s[l:r]\) 的后缀,求出其中字典序最小的排名 \(L\),和字典序最大的排名 \(R\)。\(ans=R-L+1\)。
求 \(L,R\):前缀是 \(s[l:r]\),等价于和 \(s[l:n]\) 的 LCP \(\geq r-l+1\)。从 \(rk_l\) 开始分别向左向右二分即可。
-
本质不同的子串个数
子串可以理解为后缀的前缀。按字典序从小到大的顺序考虑后缀,对于排名为 \(i\) 的后缀 \(sa_i\),有 \(height_i\) 个前缀在排名为 \(i-1\) 的后缀 \(sa_{i-1}\) 里算过了,所以新增 \((n-sa_i+1)-height_i\) 个本质不同的子串。
即,子串可能是多个后缀的前缀,规定一个子串在最小的后缀里算到。
-
最小表示法(循环同构里字典序最小的)
对 \(s+s\) 做 SA,找字典序最小且下标 \(\in[1,n]\) 的后缀,即 \(sa_i\in[1,n]\)。
-
\(s,t\) 的最长公共子串
子串就是后缀的前缀,相当于要求 \(s\) 后缀和 \(t\) 后缀的 LCP 最大值。
对 \(s+t\) 做 SA。但怎么保证求的是 \(s\) 后缀和 \(t\) 后缀,不是 \(s\) 后缀和 \(s\) 后缀,或者 \(t\) 后缀和 \(t\) 后缀?
对 \(s\) 的每个后缀,找到第一个排名在它前面/后面的 \(t\) 后缀,求一下 LCP。
-
求最长的出现至少 \(k\) 次的子串。
前缀是该子串的后缀在后缀数组中是一段连续的区间。所以答案就是,选一段长度为 \(k\) 的连续区间,使得 \(height\) 的最小值最大,RMQ。
-
求最长的出现至少 \(k\) 次的子串,要求出现互不重叠。
二分答案 \(l\),转化为求长度为 \(l\) 的串最多互不重叠出现多少次。相当于选出尽量多的位置 \(p_{1\sim m}\),\(p_{i+1}-p_i\geq l\),\(\text{lcp}(p_i,p_j)\geq l\)。
对于条件 2:将 \(height_i<l\) 的所有空隙切断,分出若干段,每段内部 \(height\) 都 \(\geq l\),\(p\) 在同一段选即可。
对于条件 1:对于每一段,从左到右能选就选。
-
求第 \(k\) 小本质不同子串。
按字典序从小到大遍历所有不同子串:按字典序从小到大遍历所有后缀 \(i\),按长度从小到大枚举 \(n-i+1-height_{rk_i}\) 个新被它算到的子串。
SA 本质上是后缀树中所有后缀的 dfs 序。在后缀树中是根据字符集 bfs,可以发现两种是同样的效果。
第 \(k\) 小:二分定位到它新算到哪个后缀,然后直接算出它是哪个串。
-
品酒大会
给出字符串 \(s\) 和 \(a_{1\sim n}\),对每个 \(r\) 求满足 \(\text{lcp}(\text{suf}_x,\text{suf}_y)\geq r\) 的 \((x,y)\) 中 \(a_xa_y\) 的最大值。
\(n\leq 3\times 10^5\)。
由于 \(\text{suf}_x,\text{suf}_y\) 的 LCP 对应一个区间 \(height\) 的最小值。枚举这个最小值 \(height_i\),找到左边第一个比它小的 \(height_l\),右边第一个比它小的 \(height_r\),那么 \(x,y\in[l+1,r-1]\),LCP 都 \(\geq height_i\)。
维护区间 \(a\) 的最大/最小值即可。
-
差异
求 \(\sum_{i=1}^n\sum_{j=i+1}^n\text{lcp}(\text{suf}_i,\text{suf}_j)\)。
\(n\leq 5\times 10^5\)。
求出 \(height\) 后,相当于求所有子区间最小值的和。对每个 \(height_i\) 求出左/右边第一个比它小的,就知道有多少区间的最小值等于它了。
-
缺位匹配
给出串 \(s,t\) 求 \(s\) 有多少子串改动 \(\leq k\) 个字符就可以和 \(t\) 相等。
\(|s|,|t|\leq 10^5\),\(k\leq 20\)。
枚举 \(s\) 的每个长度为 \(|t|\) 的子串,每次贪心地往后匹配,可以发现就是进行 \(k\) 次 LCP 询问。
P1117 [NOI2016] 优秀的拆分
给出一个字符串 \(s\),求 \(s\) 所有子串拆成 AABB 形式的方案数之和。
\(1\leq T\leq 10\),\(n\leq 30000\)。
设 \(f_i,g_i\) 分别表示以 \(i\) 结尾、开头 AA 式子串数量,\(ans=\sum_{i=1}^{n-1}f_ig_{i+1}\)。
枚举 A 的长度 \(len\),在原串上每 \(len\) 个位置设置一个关键点,显然任意一个长度为 \(2len\) 的 AA 式子串一定经过两个关键点。
考虑相邻的两个关键点 \(i,j\) 会产生的贡献。设 \(x=\text{LCP}(i,j)\),\(y=\text{LCS}(i-1,j-1)\),若 \(x+y<len\),那么不存在长度为 \(2len\) 的经过 \(i,j\) 的 AA。否则可以算出 AA 分界点的区间(\(x+y-len+1\) 个):

差分算 \(f,g\) 即可。时间复杂度 \(\mathcal O(n\log n)\)。
后缀自动机
等价类:\(\text{endpos}\) 相同。一定是一堆长度连续的子串,且短串是长串的后缀。一个等价类对应 SAM 上一个节点。
- \(ch_{x,c}\):\(ch_{x,c}\) 包含节点 \(x\) 中所有字符串末尾都加一个字符
c得到的串。但 \(ch_{x,c}\) 不全是 \(x\) +c,还包含了其他 \(\text{endpos}\) 相同的串,有多个这样的 \(x\) 会一起转移到 \(ch_{x,c}\)。\(ch_{x,c}\) 构建了 SAM 的自动机部分(是个 DAG)。 - \(fa_x\):\(fa_x\) 中串是 \(x\) 中所有串的后缀,\(\text{endpos}(x)\subsetneq\text{endpos}(fa_x)\),\(|\min(x)|=|\max(fa_x)|+1\)。即 \(\min(fa_x)\) 除去自身的最长后缀,由于短,出现次数比 \(x\) 中串多,不能塞入 \(x\) 的等价类,它和它长度连续的后缀形成了另一个等价类。\(fa_x\) 构建了 SAM 的 Parent 树。
增量构造:由 \(S\) 的 SAM 求出 \(S\) + c 的 SAM。想要求,1. \(fa_x\),2. \(ch_{u,c}\to x\) 的 \(u\)。
稍微解释一下代码:
- 若 \(p\) +
c= \(q\),\(q\) 中所有串出现次数都会 \(+1\),仍然是等价类,\(fa_x=q\)。 - 若 \(p\) +
c\(\subsetneq q\),也就是我们所说的 \(ch_{p,c}\) 不全是 \(p\) +c。\(p\) +c出现次数会 \(+1\),剩余的不会(显然 \(p\) +c的串是q中较短的那些,所以判是否 \(p\) +c= \(q\) 只需判len[q]==len[p]+1),分成了两个等价类,即把 \(p\) +c拎出来成为 \(Q\),\(fa_x=Q\),剩余的留在 \(q\)。\(ch_{p,c}\gets Q\),\(p\) 的祖先是 \(p\) 的后缀,\(ch\) 也要改。
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}

后缀树
后缀树就是反串的 Parent 树。
应用:
-
求两个后缀的 LCP
后缀树上的 \(\text{lca}\)。
-
求子串 \(s[l:r]\) 在 \(s\) 中的出现次数
有多少后缀,以 \(s[l:r]\) 为前缀。那么就是求后缀树上经过 \(s[l:r]\) 走到的点的子树中接受状态的个数。
-
本质不同的子串个数
由于一个子串属于且仅属于一个等价类,等价类 \(x\) 中有 \(len(x)-len(fa_x)\) 个子串,所以 \(ans=\sum len(x)-len(fa_x)\)。
-
最小表示法(循环同构里字典序最小的)
\(s+s\) 的 SAM 上,每次走最小字符,找到最小的长度为 \(|s|\) 的路径。
-
\(s,t\) 的最长公共子串
对 \(s\) 建 SAM,求以 \(t\) 每个位置结束的最长公共子串长度。把 \(t\) 放在 SAM 上跑,能转移就转移,否则慢慢从前面缩减长度(跳 \(fa\)),直到能转移。
n=strlen(s1+1),m=strlen(s2+1),p=1; for(int i=1;i<=n;i++) insert(s1[i]-'a'); for(int i=1;i<=m;i++){ int c=s2[i]-'a'; while(p&&!ch[p][c]) p=fa[p],l=len[p]; if(ch[p][c]) p=ch[p][c],l++; else p=1,l=0; //!!! ans=max(ans,l); }
CF235C Cyclical Quest(*2700)
给出一个字符串 \(s\),\(n\) 次询问,每次给出字符串 \(t\),求 \(t\) 所有循环同构串去重后在 \(s\) 中的出现次数之和。
\(|s|,\sum |t|\leq 10^6\),\(1\leq n\leq 10^5\)。
对 \(s\) 建立 SAM。把 \(t+t\) 放到 SAM 上跑匹配,类似求最长公共子串的方法,对每个位置求以它为循环同构串结尾时在 SAM 上跑到的点 \(x\),使匹配长度为 \(|t|\)。则当前匹配的这个循环同构串在 \(s\) 中的出现次数为 \(|\text{endpos}(x)|\)。
具体地,先从当前字符转移,再通过跳 \(fa\) 将匹配长度 \(>|t|\) 调整为 \(=|t|\)(注意只有当前节点不能表示当前匹配长度才需要跳 \(fa\))。
signed main(){
scanf("%s%d",s+1,&q),n=strlen(s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a');
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1);
while(q--){
scanf("%s",s+1),n=strlen(s+1),ans=0;
for(int i=1;i<=n;i++) s[i+n]=s[i];
int p=1,l=0;
for(int i=1;i<2*n;i++){ //注意这里是 <2*n
int c=s[i]-'a';
while(p&&!ch[p][c]) p=fa[p],l=len[p];
if(p){
p=ch[p][c],l++;
while(l>n) if(--l<=len[fa[p]]) p=fa[p]; //若当前节点不能表示出这个长度为 l 的串,就跳 fa
if(l==n&&!vis[p]) ans+=sz[p],vis[p]=1,a.push_back(p); //去重,打 vis 标记
}
else p=1,l=0;
}
printf("%d\n",ans);
for(int i:a) vis[i]=0; a.clear();
}
return 0;
}
线段树合并维护 endpos
把 Parent 树子树里的 \(\text{endpos}\) 集合都合并到一起。
P4094 [HEOI2016/TJOI2016]字符串
给出一个长度为 \(n\) 的字符串 \(s\),\(m\) 次询问,每次询问 \(s[a:b]\) 的所有子串和 \(s[c:d]\) 的 LCP 长度的最大值。
\(1\leq n,m\leq 10^5\)。
二分答案,check \(s[c:c+mid-1]\) 是否在 \(s[a:b]\) 中出现过(也就是某个 \(\text{endpos}\) 在 \([a+mid-1,b]\) 中)。
对 \(s\) 建立 SAM,线段树合并维护 \(\text{endpos}\),记录每个前缀的对应状态,在 Parent 树上倍增得到子串 \(s[c:c+mid-1]\) 的状态 \(p\),看 \(p\) 某个 \(\text{endpos}\) 在 \([a+mid-1,b]\) 中即可。
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+5;
int n,m,tot=1,lst=1,pos[N],len[N],fa[N],ch[N][27],cnt,rt[N],lc[N<<5],rc[N<<5],f[N][25];
char s[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,copy(ch[q],ch[q]+26,ch[Q]);
len[Q]=len[p]+1,fa[Q]=fa[q],fa[x]=fa[q]=Q;
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void modify(int &p,int l,int r,int pos){
if(!p) p=++cnt;
if(l==r) return ;
int mid=(l+r)/2;
if(pos<=mid) modify(lc[p],l,mid,pos);
else modify(rc[p],mid+1,r,pos);
}
int merge(int x,int y,int l,int r){
if(!x||!y) return x|y;
int p=++cnt,mid=(l+r)/2;
if(l==r) return p;
lc[p]=merge(lc[x],lc[y],l,mid);
rc[p]=merge(rc[x],rc[y],mid+1,r);
return p;
}
int query(int p,int l,int r,int lx,int rx){
if(!p) return 0;
if(l>=lx&&r<=rx) return 1;
int mid=(l+r)/2,ans=0;
if(lx<=mid) ans=query(lc[p],l,mid,lx,rx);
if(rx>mid) ans|=query(rc[p],mid+1,r,lx,rx);
return ans;
}
void dfs(int x){
for(int i=0;i<=19;i++) f[x][i+1]=f[f[x][i]][i];
for(int y:v[x]) f[y][0]=x,dfs(y),rt[x]=merge(rt[x],rt[y],1,n);
}
signed main(){
scanf("%d%d%s",&n,&m,s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a'),pos[i]=lst,modify(rt[lst],1,n,i);
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs(1);
while(m--){
int a,b,c,d;
scanf("%d%d%d%d",&a,&b,&c,&d);
auto get=[&](int l,int r){
int x=pos[r];
for(int i=20;i>=0;i--)
if(f[x][i]&&r-l+1<=len[f[x][i]]) x=f[x][i];
return x;
};
int l=1,r=min(b-a+1,d-c+1),ans=0;
while(l<=r){
int mid=(l+r)/2;
if(query(rt[get(c,c+mid-1)],1,n,a+mid-1,b)) ans=mid,l=mid+1;
else r=mid-1;
}
printf("%d\n",ans);
}
return 0;
}
CF700E Cool Slogans(*3300)
给出一个长度为 \(n\) 的字符串 \(s\),要构造一个最长的字符串 \(t_{1\sim k}\),满足:
- 对于 \(i\in[1,k]\),\(t_i\) 为 \(s\) 的子串。
- 对于 \(i\in[2,k]\),\(t_{i-1}\) 在 \(t_i\) 中出现了至少两次。
\(1\leq n\leq 2\times 10^5\)。
可以加上一个条件 \(t_i\) 是 \(t_{i+1}\) 的后缀。因为如果不是,删掉 \(t_{i+1}\) 后面若干字符直到 \(t_i\) 是其后缀显然不劣。
对 \(s\) 建立 SAM,Parent 树上,若 \(x\) 是 \(y\) 的祖先,\(x\) 的子串在 \(y\) 的子串中出现了至少两次,就可以从 \(x\) 转移到 \(y\)。
考虑怎么判出现了至少两次。由于 \(x\) 中子串是 \(y\) 的后缀,所以对于 \(y\) 的 \(\text{endpos}\) 集合中任意一个位置 \(pos\),\(x\) 一定在以 \(pos\) 为结尾出现了一次,另一次只要在以 \([pos-len_y+len_x,pos)\) 为结尾出现即可。
在 Parent 树上从根向下 DP,设 \(f_x\) 表示节点 \(x\) 时的最大值,再记 \(top_x\) 表示节点 \(x\) 由哪个节点转移来。
时间复杂度 \(\mathcal O(n\log n)\)。
#include<bits/stdc++.h>
using namespace std;
const int N=4e5+5;
int n,tot=1,lst=1,ch[N][27],fa[N],f[N],top[N],len[N],ed[N],cnt,rt[N],lc[N<<5],rc[N<<5],ans;
char s[N];
vector<int>v[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(p&&!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,memcpy(ch[Q],ch[q],sizeof(ch[q]));
ed[Q]=ed[q],fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q; //ed[Q]=ed[q]!
while(p&&ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void modify(int &p,int l,int r,int pos){
if(!p) p=++cnt;
if(l==r) return ;
int mid=(l+r)/2;
if(pos<=mid) modify(lc[p],l,mid,pos);
else modify(rc[p],mid+1,r,pos);
}
int merge(int x,int y,int l,int r){
if(!x||!y) return x|y;
int p=++cnt,mid=(l+r)/2;
if(l==r) return p;
lc[p]=merge(lc[x],lc[y],l,mid);
rc[p]=merge(rc[x],rc[y],mid+1,r);
return p;
}
int query(int p,int l,int r,int lx,int rx){
if(!p) return 0;
if(l>=lx&&r<=rx) return 1;
int mid=(l+r)/2,ans=0;
if(lx<=mid) ans=query(lc[p],l,mid,lx,rx);
if(rx>mid) ans|=query(rc[p],mid+1,r,lx,rx);
return ans;
}
void dfs1(int x){
for(int y:v[x]) dfs1(y),rt[x]=merge(rt[x],rt[y],1,n);
}
void dfs2(int x){
if(x==1) f[x]=0;
else if(fa[x]==1) f[x]=1,top[x]=x;
else{
if(query(rt[top[fa[x]]],1,n,ed[x]-len[x]+len[top[fa[x]]],ed[x]-1)) f[x]=f[fa[x]]+1,top[x]=x;
else f[x]=f[fa[x]],top[x]=top[fa[x]];
}
ans=max(ans,f[x]);
for(int y:v[x]) dfs2(y);
}
signed main(){
scanf("%d%s",&n,s+1);
for(int i=1;i<=n;i++) insert(s[i]-'a'),modify(rt[lst],1,n,ed[lst]=i);
for(int i=2;i<=tot;i++) v[fa[i]].push_back(i);
dfs1(1),dfs2(1),printf("%d\n",ans);
return 0;
}
用 SAM 求 SA
upd on 2024.1.10。
对反串建 SAM,\(\text{endpos}\) 就变成了 \(\text{beginpos}\),Parent 树的后缀关系就变成了前缀关系。一个状态包含一个后缀长度连续的前缀。短的串由于出现次数更多与长的串分开,\(\text{beginpos}\) 父亲包含儿子。

将所有前缀对应的状态标记为关键点。
对每个状态 \(x\) 记录其 \(\text{beginpos}\) 集合中任意一个位置 \(pos_x\)。
连边 \((fa_x,x,S[pos_x+len_{fa_x}])\)(为什么只用考虑 \(S[pos_x+len_{fa_x}:pos_x+len_x-1]\) 的第一个字符?因为 \(|\min(x)|=|\max(fa_x)|+1\) 且 \(S[pos_x:pos_x+len_{fa_x}]\) 只会在一个状态里,所以 \(fa_x\) 不可能连出同样的 \(S[pos_x+len_{fa_x}]\)),按边的字典序 dfs 树,先访问到的关键点对应的后缀 \(rk\) 更小。
然后和 SA 一样求出 \(height\) 数组。
缺点是空间复杂度变劣了。
#include<bits/stdc++.h>
using namespace std;
const int N=2e5+5,M=27;
int n,tot=1,lst=1,pos[N],len[N],fa[N],ch[N][M],to[N][M],key[N],cnt,sa[N],rk[N],ht[N];
char s[N];
void insert(int c){
int p=lst,x=lst=++tot;
len[x]=len[p]+1;
while(!ch[p][c]) ch[p][c]=x,p=fa[p];
if(!p){fa[x]=1;return ;}
int q=ch[p][c],Q;
if(len[q]==len[p]+1){fa[x]=q;return ;}
Q=++tot,copy(ch[q],ch[q]+26,ch[Q]);
pos[Q]=pos[q],fa[Q]=fa[q],len[Q]=len[p]+1,fa[q]=fa[x]=Q;
while(ch[p][c]==q) ch[p][c]=Q,p=fa[p];
}
void dfs(int x){
if(key[x]) sa[rk[pos[x]]=++cnt]=pos[x];
for(int i=0;i<26;i++)
if(to[x][i]) dfs(to[x][i]);
}
signed main(){
scanf("%s",s+1),n=strlen(s+1);
for(int i=n;i>=1;i--)
insert(s[i]-'a'),pos[lst]=i,key[lst]=1;
for(int i=2;i<=tot;i++) to[fa[i]][s[pos[i]+len[fa[i]]]-'a']=i;
dfs(1);
for(int i=1,k=0;i<=n;i++){
if(k) k--;
int j=sa[rk[i]-1];
while(i+k<=n&&j+k<=n&&s[i+k]==s[j+k]) k++;
ht[rk[i]]=k;
}
for(int i=1;i<=n;i++) printf("%d ",sa[i]); puts("");
for(int i=2;i<=n;i++) printf("%d ",ht[i]);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号