Policy Gradient实战(神经网络在强化学习中的意义)
输入观测的东西 经过黑盒子 输出一个概率分布
相当于也是图像识别
在Policy Gradient中,我们需要训练一个Agent。这个Agent相当于一个分类器,其输入是观测到环境的信息observation(state),输出为行为action的概率分布。我们可以用简单的多层感知机去实现这个分类器:
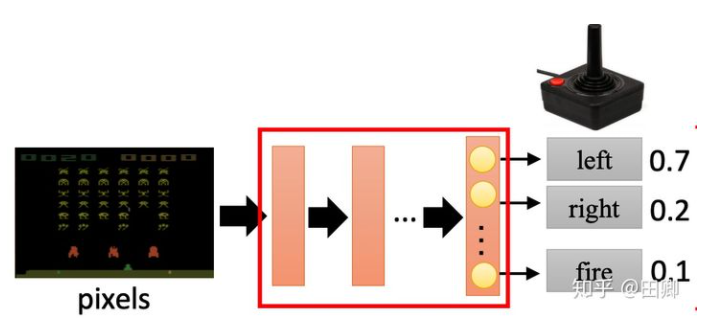
在该任务中,可以查看输入observation(state)和输出action的维度:
import gym
env = gym.make('CartPole-v1')
print(env.action_space)
Discrete(2)
print(env.observation_space)
Box(4,)
我们可以构建一个简单的多层感知机充当二分类器:
class PGN(nn.Module):
def init(self):
super(PGN, self).init()
self.linear1 = nn.Linear(4, 24)
self.linear2 = nn.Linear(24, 36)
self.linear3 = nn.Linear(36, 1)
def forward(self, x):
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = torch.sigmoid(self.linear3(x))
return x
我们的需要训练一个CartAgent,应当至少具备以下接口:
class CartAgent(object):
def init(self, learning_rate, gamma):
self.pgn = PGN()
self.gamma = gamma
self._init_memory()
self.optimizer = torch.optim.RMSprop(self.pgn.parameters(), lr=learning_rate)
def memorize(self, state, action, reward):
# save to memory for mini-batch gradient descent
self.state_pool.append(state)
self.action_pool.append(action)
self.reward_pool.append(reward)
self.steps += 1
def learn(self):
pass
def act(self, state):
return self.pgn(state)
前面提过,强化学习不同于监督学习(能够直接使用训练语料中的X和Y拟合该模型)。在Policy Gradient中,我们需要使用特殊的损失函数:
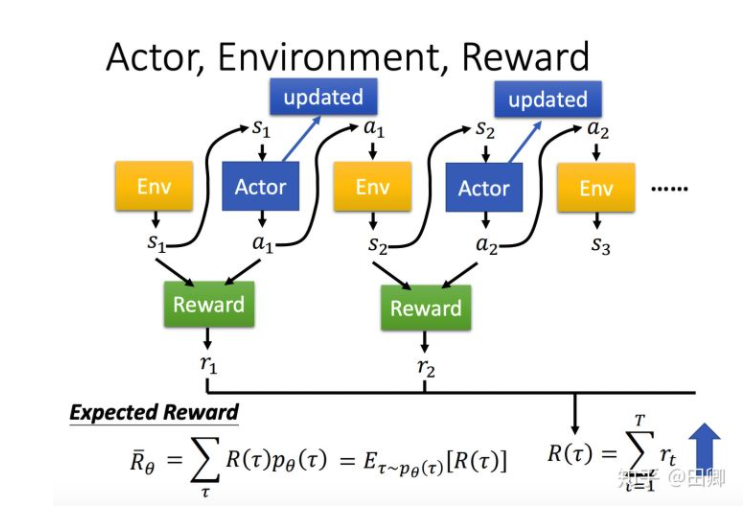
其中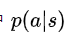 由Agent模型计算得出,
由Agent模型计算得出,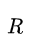
即Reward,由环境给出。这个损失函数能够提高reward值大的action出现的概率。loss的核心实现为:
def learn(self):
self._adjust_reward()
# policy gradient
self.optimizer.zero_grad()
for i in range(self.steps):
# all steps in multi games
state = self.state_pool[i]
action = torch.FloatTensor([self.action_pool[i]])
reward = self.reward_pool[i]
probs = self.act(state)
m = Bernoulli(probs)
loss = -m.log_prob(action) * reward
loss.backward()
self.optimizer.step()
self._init_memory()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号