SQLSERVER中的假脱机spool
SQLSERVER中的假脱机spool
假脱机是中文的翻译,而英文的名字叫做 spool
在徐海蔚老师写的《SQLSERVER企业级平台管理实践》里提到了一下假脱机
在SQLSERVER I/O问题的那一节
在性能监视器里,有一个计数器“worktables/sec” :
每秒创建的工作表数。例如,工作表可用于存储查询假脱机(query spool),LOB变量,XML变量,表变量,游标的临时结果
在《剖析SQLServer执行计划》里也提到了假脱机
(13) 有时查询优化器需要在tempdb数据库中建立临时工作表。如果是这样的话
就意味着图形执行计划中有标识成Index Spool, Row Count Spool或者Table Spool的图标。
任何时候,使用到工作表一般都会防碍到性能,因为需要额外的I/O开销来维护这个工作表。
之前本人也写过一篇文章:对于索引假脱机的一点理解
假脱机在MSDN中的执行计划中的逻辑运算符和物理运算符中提到了几个假脱机相关的运算符(详见本文最后面)
Eager Spool
Lazy Spool
Index Spool (有时候也叫 Nonclustered Index Spool)
Row Count Spool
Spool
Table Spool
Window Spool
Spool, Table Spool, Index Spool, Window Spool 和 Row Count Spool是物理运算符
Eager Spool 和 Lazy Spool是逻辑运算符
这些运算符描述了假脱机是如何工作的,在这里你需要非常清楚逻辑运算符和物理运算符的区别
MSDN中的解释:
逻辑运算符:逻辑运算符描述了用于处理语句的关系代数操作。 换言之,逻辑运算符从概念上描述了需要执行哪些操作,换句话说就是,对数据操作的逻辑抽象表达
物理运算符:物理运算符实施由逻辑运算符描述的操作。 每个物理运算符都是一个执行某项具体操作的对象或例程,换句话说就是,真正干活的
例如,某些物理运算符可访问表、索引或视图中的列或行。 其他物理运算符执行其他操作,如计算、聚合、数据完整性检查或联接。
物理运算符具有与其关联的开销。

注意:窗口假脱机是没有Eager Spool和Lazy Spool之分的,因为他既是逻辑运算符也是物理运算符!!
简单来讲 SQL Server做某项操作由物理运算符来做,而具体怎样做就由逻辑运算符来决定
打个比方:小明在佛山,想去广州,小明可以选择开汽车去广州,踩自行车去广州,骑摩托车去广州(相当于做某项操作)
小明可以根据当时的路况:
(1)踩自行车:如果道路比较拥堵,踩自行车不用怕,最多的车也能过,他可以选择使劲的踩(Eager Spool)或者慢慢踩(Lazy Spool)
(2)开汽车:如果道路比较畅通,他可以选择开快一点(Eager Spool)或者开慢一点(Lazy Spool)
(3)骑摩托车:如果道路比较拥堵,他可以选择抄小路,然后开快一点(Eager Spool)或者开慢一点(Lazy Spool)
在图形执行计划中,你会发现Table Spool 有时候会带有 Eager Spool ,有时候又会带有 Lazy Spool
因为Table Spool是物理运算符,Eager Spool和Eager Spool 是逻辑运算符
Table Spool(表假脱机)
SQL脚本如下:
表假脱机 Eager Spool
----表假脱机 Eager Spool USE [Spool] GO CREATE TABLE Sales (EmpId INT, Yr INT, Sales MONEY) INSERT Sales VALUES(1, 2005, 12000) INSERT Sales VALUES(1, 2006, 18000) INSERT Sales VALUES(1, 2007, 25000) INSERT Sales VALUES(2, 2005, 15000) INSERT Sales VALUES(2, 2006, 6000) INSERT Sales VALUES(3, 2006, 20000) INSERT Sales VALUES(3, 2007, 24000) SELECT * FROM [dbo].[Sales] SELECT EmpId, Yr, SUM(Sales) AS Sales FROM Sales GROUP BY EmpId, Yr WITH CUBE
例子出处:http://www.sqlskills.com/blogs/conor/grouping-sets-rollups-and-cubes-oh-my/
In this case, it writes the data to a temporary spool, sorts the output of that
and then re-reads that spool in the second branch.
表假脱机 Lazy Spool
--表假脱机 Lazy Spool USE [AdventureWorks] GO SELECT *,COUNT(*) OVER() from production.[Product] AS p JOIN production.[ProductSubcategory] AS s ON s.[ProductCategoryID]=p.[ProductSubcategoryID]
例子出处:http://sqlblog.com/blogs/rob_farley/archive/2013/06/11/spooling-in-sql-execution-plans.aspx
Row Count Spool(行计数假脱机)
SQL脚本如下:
--行计数假脱机 USE [Spool] GO --建表 CREATE TABLE tb1(ID int) GO CREATE TABLE tb2(ID int) GO --插入测试数据 DECLARE @i INT SET @i= 500 WHILE @i > 0 begin INSERT INTO dbo.tb1 VALUES ( @i ) SET @i = @i -1 end GO DECLARE @i INT SET @i= 500 WHILE @i > 0 begin INSERT INTO dbo.tb2 VALUES ( @i ) SET @i = @i -1 end --行计数假脱机 SELECT * FROM tb1 WHERE id NOT IN(SELECT id FROM tb2)
例子出处:http://niutuku.com/tech/MsSql/238716.shtml
Index Spool (索引假脱机)
Lazy Spool
SQL脚本如下:
--索引假脱机(Index Spool) USE [Spool] GO --建表 create table tb(aa int,bb char(1)) GO --插入测试数据 insert tb values(1,'A') insert tb values(1,'B') insert tb values(1,'C') insert tb values(1,'D') insert tb values(2,'E') insert tb values(2,'F') insert tb values(2,'G') insert tb values(2,'H') insert tb values(3,'I') insert tb values(3,'J') insert tb values(3,'K') insert tb values(3,'L') --查询数据 SELECT * FROM tb a WHERE bb = ( SELECT TOP 1 bb FROM tb WHERE aa = a.aa ORDER BY NEWID() )
例子出处:http://www.cnblogs.com/lyhabc/archive/2013/04/19/3029840.html
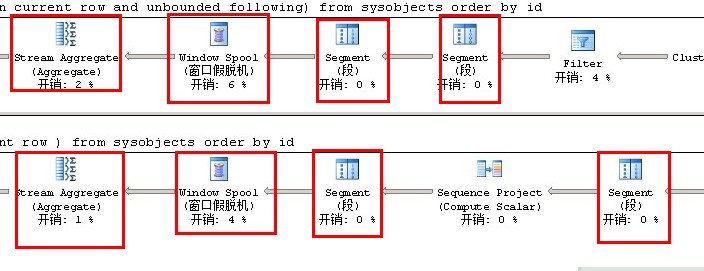
Window Spool (窗口假脱机)
Window Spool 这个执行计划和OVER() 开窗函数息息相关,因为只有OVER()函数才会使用到Window Spool 这个执行计划
http://msdn.microsoft.com/zh-cn/library/ms189461.aspx
大家可以看一下MSDN中对OVER()开窗函数里ROWS选项和RANGE选项的解释
ROWS | RANGE
通过指定分区中的起点和终点,进一步限制分区中的行数。 这是通过按照逻辑关联或物理关联对当前行指定某一范围的行实现的。物理关联通过使用 ROWS 子句实现。
ROWS 子句通过指定当前行之前或之后的固定数目的行,限制分区中的行数。
此外,RANGE 子句通过指定针对当前行中的值的某一范围的值,从逻辑上限制分区中的行数。
基于 ORDER BY 子句中的顺序对之前和之后的行进行定义。
窗口框架“RANGE … CURRENT ROW …”包括在 ORDER BY 表达式中与当前行具有相同值的所有行。
例如,ROWS BETWEEN 2 PRECEDING AND CURRENT ROW 意味着该函数对其操作的行的窗口在大小上是 3 行,以当前行之前(包括当前行)的 2 行开头。
SQL脚本如下:
use master GO --range select count(*) over (order by id RANGE between current row and unbounded following) from sysobjects order by id --rows select count(*) over (order by type ROWS current row ) from sysobjects order by id
例子出处:http://www.sqlteam.com/forums/topic.asp?TOPIC_ID=182542
对上面这些运算符的解释:
假脱机运算符会取出表中的一部分的数据集,将他们存放在tempdb数据库里的临时结构里
这个临时结构一般就是堆表或者非聚集索引,但是有一个物理运算符例外,临时结构是不存放数据的,
他只存放假脱机里保存的数据的行数,而这个物理运算符就是Row Count spool
Index Spool(放非聚集索引数据的):索引假脱机只有非聚集索引假脱机,没有聚集索引假脱机,结合我以前写的两篇文章,解释一下原因
SQLSERVER当遇到复杂的查询的时候,需要把部分结果集放到tempdb数据库里的非聚集索引页里(说白了就是在tempdb数据库里建立
表的非聚集索引)以加快查找的速度的时候就会用到索引假脱机
例如上面的例子,SQL语句用到了子查询(tb表),SQLSERVER需要把子查询里的结果集(tb表)进行排序然后将结果集放进去
非聚集索引里(对tb表建立非聚集索引),
然后用非聚集索引里的数据和主表(tb a)里的数据进行联接,并输出结果
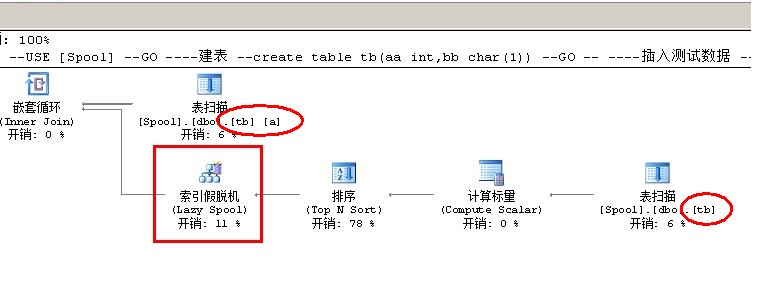
为什麽不用聚集索引?
SQLSERVER聚集索引与非聚集索引的再次研究(上/下)里说到,非聚集索引和堆表是没有连接在一起的,非聚集索引页面只有指针
指向堆表的数据页,而聚集索引的叶子节点就是数据页,索引页和数据页连接在一起,如果建立聚集索引,就需要将表(tb表)中的数据
放入到tempdb数据库里,这样开销就会很大
或者用下面两张图来描述可能会清楚一点,关键还是要读懂 SQLSERVER聚集索引与非聚集索引的再次研究(上/下)


Table Spool(放符合查询条件的数据的):把表中的数据放进tempdb数据库里

为什麽第一个查询会用到Table Spool?因为CUBE这个数据汇总关键字会将表中的数据进行汇总,汇总的过程比较复杂
把表中的数据放进去tempdb数据库里的工作表(worktable/临时表)里进行复杂的汇总计算是比较好的
他避免了阻塞,以防止长期锁住表中的数据
关于CUBE关键字可以看一下我这篇文章:SQLSERVER中的ALL、PERCENT、CUBE关键字、ROLLUP关键字和GROUPING函数
Row Count Spool(放表行数的):存放中间结果/表的数据的行数,上面的例子里用于计算表中的数据行数并保存在tempdb数据库的
Row Count Spool里,为后面两表联接选用执行计划提供选择依据

Eager Spool逻辑运算符:一次性将所有数据放入到Spool里
Lazy Spool逻辑运算符:逐次逐次地将数据放入Spool里
在上面的例子里
Tabel Spool Eager Spool

SQLSERVER使用Eager Spool一次性将Sales 表中的数据存放到tempdb数据库的工作表里面,方便快速统计
Row Count Spool

SQLSERVER使用计数器每次读取到一行就加1,这样一次一次地统计表中的行数(这里只是比喻,SQLSERVER内部可能并不是这样统计!)
Window Spool(放开窗函数数据):根据MSDN中的定义,OVER 子句定义查询结果集内的窗口或用户指定的行集。 然后,开窗函数将计算窗口中每一行的值
SQLSERVER将窗口中的结果集放入Spool里,以加快后续操作的速度
对于单独一个窗口来讲:单独一个窗口属于Eager Spool(一次性将结果集放进去窗口里)
对于表中的窗口来讲:属于Lazy Spool ,因为每个窗口把数据存放进去窗口里的速度/顺序不是一致的,逐次逐次地将数据存放进去每个窗口
为什麽需要假脱机?
说白了,假脱机就是tempdb数据库里的临时表
为什么需要临时表呢,主要有两个原因:
1:数据需要再次被调用,达到缓存的效果
2:使临时表数据与源表数据保持隔离,使用临时表解决数据可见性问题,例如万圣节问题里,用table spool解决数据可见性问题
第二个原因很容易理解,就像第一个例子中的Tabel Spool那样,需要把表数据放进Tabel Spool里,以方便进行数据汇总,而不影响原表数据
第一个原因可以再举一个例子
公用表表达式(CTE)
1 USE [AdventureWorks]
2 GO
3 WITH managers AS(
4 SELECT [EmployeeID],[ManagerID]
5 from [HumanResources].[Employee]
6 WHERE [ManagerID] IS NULL
7 UNION ALL
8 SELECT e.[EmployeeID],e.[ManagerID]
9 from [managers] m
10 JOIN [HumanResources].[Employee] e
11 ON e.[ManagerID]=m.[EmployeeID]
12 )
13
14 SELECT * FROM [managers]
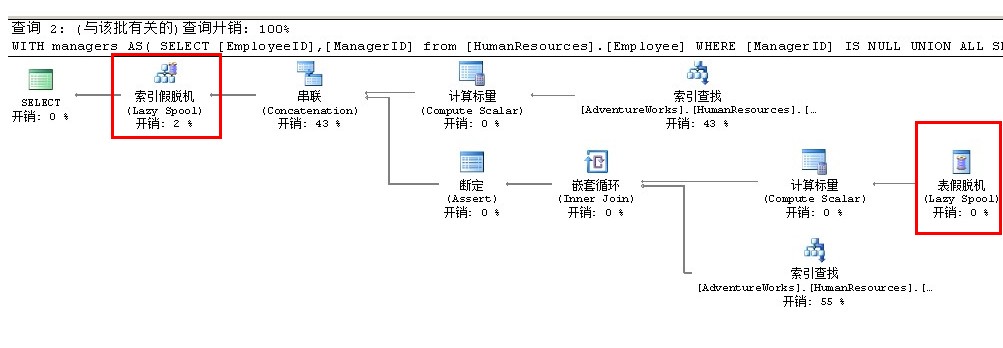
索引假脱机运算符负责把数据一条一条地塞进去tempdb的临时表里,并且是Lazy的,为什麽是Lazy的?
因为刚开始的时候只有一行记录,后来慢慢一条一条数据地从最右边的表假脱机里获取数据

我们还是先分析一下整个执行计划以方便理解,我们可以将整个执行计划拆解为三部分
第一部分 执行计划的右上角
1 SELECT [EmployeeID],[ManagerID]
2 from [HumanResources].[Employee]
3 WHERE [ManagerID] IS NULL

这部分的执行计划只查找到一条记录

他把这条记录放入索引假脱机里

第二部分 UNION ALL


将第一部分的结果和第三部分的结果合并在一起
第三部分 执行计划的右下角
1 SELECT e.[EmployeeID],e.[ManagerID]
2 from [managers] m
3 JOIN [HumanResources].[Employee] e
4 ON e.[ManagerID]=m.[EmployeeID]
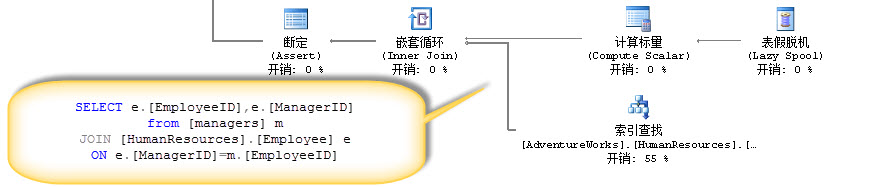
最右边的表假脱机运算符负责把表数据装载入表假脱机里,这个装载过程也是逐条数据装载的
那么,执行计划里的表假脱机和索引假脱机主要有什么用???
表假脱机主要用作公用表表达式里的递归调用
1 WITH managers AS(
2 SELECT [EmployeeID],[ManagerID]
3 from [HumanResources].[Employee]
4 WHERE [ManagerID] IS NULL
5 UNION ALL
6 SELECT e.[EmployeeID],e.[ManagerID]
7 from [managers] m
8 JOIN [HumanResources].[Employee] e
9 ON e.[ManagerID]=m.[EmployeeID]
10 )
SELECT e.[EmployeeID],e.[ManagerID]
from [managers] m
JOIN [HumanResources].[Employee] e
ON e.[ManagerID]=m.[EmployeeID]
上面的代码是每次递归的时候都需要调用到的,所以 SQL Server干脆把表数据放到临时表里的,不用每次都去查找记录了

而索引临时表是方便外部代码调用公用表表达式的时候不用每次都去计算公用表表达式的结果,直接把公用表表达式的结果,达到缓存的效果
放进去索引假脱机,当SELECT * FROM managers的时候,直接到索引假脱机里取数据就可以了
1 SELECT * FROM [managers]

断定运算符在这里的作用是判断是否超过系统循环次数导致造成死循环,主要是预防死循环,如果我们加上OPTION (MAXRECURSION 0)
断定运算符就会消失

1 USE [AdventureWorks]
2 GO
3 WITH managers AS(
4 SELECT [EmployeeID],[ManagerID]
5 from [HumanResources].[Employee]
6 WHERE [ManagerID] IS NULL
7 UNION ALL
8 SELECT e.[EmployeeID],e.[ManagerID]
9 from [managers] m
10 JOIN [HumanResources].[Employee] e
11 ON e.[ManagerID]=m.[EmployeeID]
12 )
13
14 SELECT * FROM [managers] OPTION (MAXRECURSION 0)

万圣节问题
网上有两篇文章介绍了这个问题
http://www.cnblogs.com/xwdreamer/archive/2012/05/28/2522404.html
simple-talk网站的文章就介绍得非常清晰
https://www.simple-talk.com/sql/learn-sql-server/operator-of-the-week---spools,-eager-spool/
万圣节问题背景
Halloween Problem是数据库系统中的一个现象,它指的是当一个查询检索了一组行,然后修改了其中一行或者多行,修改后的行再次满足查询条件,进而导致在相同的更新操作中再次访问和更新该行。
导致在某些情况下甚至可能导致无限循环。
这个问题最初是由Don Chamberlin,Pat Selinger和Morton Astrahan在1976年的万圣节那天发现的,当时他们正在处理一个查询,本来应该给那些收入低于25,000美元的员工加薪10%,
但执行完成后,数据库中所有员工的收入都至少达到了25,000美元。这是由于更新过的记录也对查询执行引擎可见,并且继续符合查询条件,导致低于25,000美元的员工记录多次匹配,
每次匹配都被加薪10%,直到他们都超过25,000美元。
Halloween Problem这个名词没有描述问题性质,仅仅是因为这个问题被发现是在万圣节那一天。自从1976年万圣节问题被发现以来,至今已经差不多有40年,尽管大部分现代数据库都解决了这个问题,
但是有些数据库还无法避免这个问题,例如CockroachDB的Pull Request 42862里被发现有Halloween Problem。
Halloween Problem的小实验
下面SQL脚本建立一个非聚集索引表,并且非聚集索引的第一个字段是salary 并且按salary升序排序!!!
USE [Spool] GO CREATE TABLE nct(id INT IDENTITY(1,1),NAME VARCHAR(30), salary INT); GO --建立非聚集索引 切记:非聚集索引的第一个字段是salary 并且按salary升序排序!!! CREATE INDEX ix_nct ON nct(salary ASC,[ID],[NAME]) GO --插入数据 INSERT INTO [dbo].[nct] ( [NAME],[salary] ) SELECT '小明', 1 UNION ALL SELECT '小华', 2 UNION ALL SELECT '小芳', 3 GO SELECT * FROM [dbo].[nct]
我们看一下非聚集索引页
CREATE TABLE DBCCResult ( PageFID NVARCHAR(200), PagePID NVARCHAR(200), IAMFID NVARCHAR(200), IAMPID NVARCHAR(200), ObjectID NVARCHAR(200), IndexID NVARCHAR(200), PartitionNumber NVARCHAR(200), PartitionID NVARCHAR(200), iam_chain_type NVARCHAR(200), PageType NVARCHAR(200), IndexLevel NVARCHAR(200), NextPageFID NVARCHAR(200), NextPagePID NVARCHAR(200), PrevPageFID NVARCHAR(200), PrevPagePID NVARCHAR(200) ) --TRUNCATE TABLE [dbo].[DBCCResult] INSERT INTO DBCCResult EXEC ('DBCC IND(Spool,nct,-1) ') SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC DBCC TRACEON(3604,-1) GO DBCC PAGE(Spool,1,47,3) GO
非聚集索引按照Salary字段升序排序
我们用SQL语句update一下小华的Salary
1 UPDATE nct SET Salary = 4
2 WHERE [NAME]='小华'

这里是按照非聚集索引的Range Scan读取出结果的:SQLSERVER中的ALLOCATION SCAN和RANGE SCAN
再看一下非聚集索引页面

我们看一下update前和update后非聚集索引页面的变化

可以看到,update之后非聚集索引马上根据非聚集索引键(Salary字段)重新进行升序排序
--------------------------------------------------------------------------------------------
使用下面SQL脚本建立测试环境
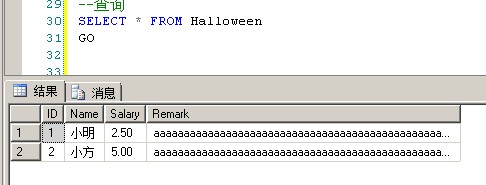
USE [Spool] GO --建表 CREATE TABLE Halloween ( ID INT IDENTITY(1, 1) PRIMARY KEY , Name VARCHAR(30) , Salary NUMERIC(18, 2), Remark NVARCHAR(3000) ) GO --插入数据 INSERT INTO [dbo].[Halloween] ( [Name], [Salary], [Remark] ) SELECT '小明',1,replicate('a', 3000) UNION ALL SELECT '小方',2,replicate('a', 3000) --建立非聚集索引 CREATE NONCLUSTERED INDEX ix_Halloween ON Halloween(Salary ASC) GO --查询 SELECT * FROM Halloween GO
我们用下面SQL语句看一下聚集索引页面和非聚集索引页面
CREATE TABLE DBCCResult ( PageFID NVARCHAR(200), PagePID NVARCHAR(200), IAMFID NVARCHAR(200), IAMPID NVARCHAR(200), ObjectID NVARCHAR(200), IndexID NVARCHAR(200), PartitionNumber NVARCHAR(200), PartitionID NVARCHAR(200), iam_chain_type NVARCHAR(200), PageType NVARCHAR(200), IndexLevel NVARCHAR(200), NextPageFID NVARCHAR(200), NextPagePID NVARCHAR(200), PrevPageFID NVARCHAR(200), PrevPagePID NVARCHAR(200) ) --TRUNCATE TABLE [dbo].[DBCCResult] INSERT INTO DBCCResult EXEC ('DBCC IND(spool,Halloween,-1) ') SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC DBCC TRACEON(3604,-1) GO DBCC PAGE(spool,1,184,3) GO DBCC PAGE(spool,1,93,3) GO
聚集索引页面

非聚集索引页面

我们update一下Salary等于1的那位员工的工资
1 UPDATE Halloween SET Salary = 2.5
2 FROM Halloween
3 WHERE Salary =1
再看一下聚集索引页面和非聚集索引页面
聚集索引页面

非聚集索引页面

非聚集索引马上按照非聚集索引键(Salary字段)进行重新排序
这里似乎没有什么问题,我们drop掉Halloween表,并重新建立测试环境
USE [Spool] GO UPDATE Halloween SET Salary = [Salary]*2.5 FROM Halloween WITH(INDEX=ix_Halloween) WHERE Salary <7
这次我们使用下面update语句,记住一定要加WITH(INDEX=ix_Halloween)
1 USE [Spool]
2 GO
3 UPDATE Halloween SET Salary = [Salary]*2.5
4 FROM Halloween WITH(INDEX=ix_Halloween)
5 WHERE Salary <7
如果我们加了WITH(INDEX=ix_Halloween),SQLSERVER就会走非聚集索引查找
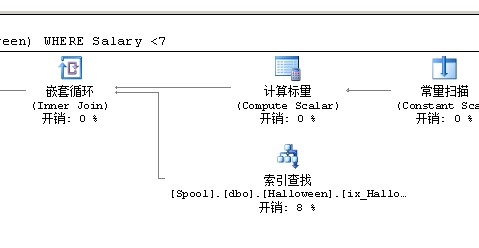
如果我们不加WITH(INDEX=ix_Halloween),SQLSERVER就会走聚集索引扫描

这里不讨论加不加WITH(INDEX=ix_Halloween)的问题
关键我们加WITH(INDEX=ix_Halloween)就是为了让SQLSERVER走非聚集索引
update了之后正常的结果应该是这样的

为什麽会这样?
还记得刚才我们说到了非聚集索引更新了之后马上进行排序吗?
用下面的图来表示应该会比较清楚



SQLSERVER使用Table Spool 临时表来解决万圣节问题


先将非聚集索引的数据放进去Table Spool(临时表)里,然后逐行操作临时表,临时表操作完之后,再把数据更新回去聚集索引,这样就不会遇到非聚集索引更新后马上进行排序的问题了
使用Table Spool后就能够得到正确结果
为什麽不用Index Spool而用Table Spool?
之前我们说过Index Spool在tempdb数据库里建立临时的非聚集索引临时表,把非聚集索引里的数据放进去非聚集索引临时表里,那会继续遇到万圣节问题
所以不应该使用Index Spool类型临时表
下面这个SQL语句也是使用了Table Spool来避免万圣节问题
1 USE [AdventureWorks]
2 GO
3 UPDATE s
4 SET [Name] = 'Z' + [Name]
5 FROM Production.ProductSubcategory AS s WITH ( INDEX ( [AK_ProductSubcategory_Name] ) )
6 WHERE [Name] >= 'N'


可能会遇到万圣节问题的几个场景
1、update数据的时候,如果update的是非聚集索引的第一个字段(即非聚集索引键),并且使用到非聚集索引扫描/查找,引起非聚集索引的重新排序,导致修改后的行再次满足查询条件,进而相同的更新操作中再次更新该数据行出问题。
2、不单只非聚集索引这个case,任何修改后的行再次满足查询条件导致在相同的更新操作中再次更新该行的场景都会出现万圣节问题。
所以说,除了非聚集索引这个case,列存索引也有可能出现这种情况,以后再补充测试。
SQL Server的解决方法
把非聚集索引里的数据全部移到Tabel Spool里,防止由于更新非聚集索引的非聚集索引键而引起的非聚集索引重新排序,造成数据更新错误的问题
其实Index Spool也好Table Spool又好,都是属于临时表的一种,用临时表来解决数据可见性问题,更新过的数据放入临时表,临时表里的数据不能再更新第二次
类似案例
https://time.geekbang.org/column/article/80801
create table t ( c int, d varchar(255), index idx_c (c)); insert into t select 1,'aa' ; insert into t select 2,'aa' ; select * from t insert into t(c,d) (select c+1, d from t force index(idx_c) where c < 6 order by c desc); select * from t
之前 MySQL5.6 数据库也是存在万圣节问题的,需要用户自己手动改写语句使用临时表解决
--建立非聚集索引
CREATE NONCLUSTERED INDEX ix_Halloween ON Halloween(Salary ASC)
GO
UPDATE Halloween SET Salary = [Salary]*2.5
FROM Halloween WITH(INDEX=ix_Halloween)
WHERE Salary <7
这类场景,其实都可以归纳为一边遍历数据,一边更新数据的情况,通用解决方案都是使用临时表,先暂存现有的表数据,然后对临时表的数据进行计算,计算完之后再更新回去原表
总结
假脱机运算符实际就是临时表或者表变量,它们存在目的有两个
1、以空间换时间,缓存数据提升性能
2、使临时表数据与源表数据保持隔离,使用临时表解决数据可见性问题,例如万圣节问题
万圣节问题的本质:数据库的逐行读取逐行更新
读取非聚集索引一行数据-》更新非聚集索引一行数据-》非聚集索引重新排序(问题出在这里)-》读取非聚集索引下一行数据-》更新非聚集索引下一行数据-》更新完之后把非聚集索引的修改更新回去聚集索引-》同时更新其他非聚集索引
万圣节问题用临时表解决
逐行读取非聚集索引的所有数据到临时表-》逐行更新非聚集索引的所有数据(临时表不会自动排序)-》把临时表表数据更新回去聚集索引-》同时更新其他非聚集索引
参考文章:
http://www.scarydba.com/2009/09/09/spools-in-execution-plans/
https://www.simple-talk.com/sql/learn-sql-server/operator-of-the-week---spools,-eager-spool/
http://sqlblog.com/blogs/rob_farley/archive/2013/06/11/spooling-in-sql-execution-plans.aspx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号