

对于索引假脱机的一点理解
对于索引假脱机的一点理解
在SQLSERVER执行计划里不知道大家有没有看过“索引假脱机”这个运算符
在QQ群里综合了各位大侠的解释:假脱机 有索引假脱机 和 表假脱机两种
先来运行一下下面的SQL代码:
1 USE [tempdb] 2 GO 3 create table #tb(aa int,bb char(1)) 4 GO 5 insert #tb values(1,'A') 6 insert #tb values(1,'B') 7 insert #tb values(1,'C') 8 insert #tb values(1,'D') 9 10 insert #tb values(2,'E') 11 insert #tb values(2,'F') 12 insert #tb values(2,'G') 13 insert #tb values(2,'H') 14 15 insert #tb values(3,'I') 16 insert #tb values(3,'J') 17 insert #tb values(3,'K') 18 insert #tb values(3,'L')
1 --SQL1 2 SELECT * FROM #tb a 3 WHERE bb IN 4 ( 5 SELECT TOP 1 bb FROM #tb 6 WHERE aa=a.aa 7 ORDER BY NEWID() 8 ) 9 10 --SQL2 11 SELECT * FROM #tb a 12 WHERE bb = 13 ( 14 SELECT TOP 1 bb FROM #tb 15 WHERE aa=a.aa 16 ORDER BY NEWID() 17 ) 18 19 --drop table tb
你会发现SQL1的执行计划和SQL2的执行计划很不一样
SQL1的执行计划
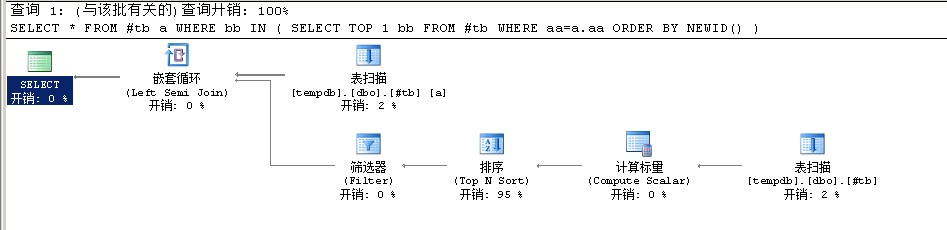
SQL2的执行计划
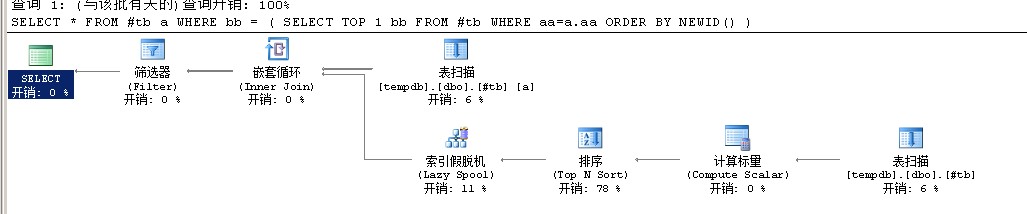
对于执行计划的解释:
1 据楼主的语句, 第一个使用的是IN, 所以IN 里面的, 被查询优化器判定为 subquery (子查询) 2 3 而第二个使用的是 =, 所以查询优化器判定 = 后面的是一个表达式 4 5 因此在判定查询方法的时候, 产生了差异, 对于查询, 查询优化器认为具有不确定性, 所以每条记录都要去执行一次子查询; 而对于表达式, 查询优化器认为它具有确定性, 所以对于每个 aa, 计算一次就行了 6 7 如果把楼主的第一个查询中的 IN, 也改成表达式, 则可以看到会使用与查询2一样的执行计划, 结果也也查询2一样, 有固定的记录数
但是还是有些云里雾里,然后听了QQ群里面的某位大侠的解释
1 XXXX(17478043) 9:28:19 2 索引假脱机是 系统在查询的时候表和数据放入tempdb里然后临时创建一个索引 3 ,表假脱机是为了避免 重复更新某些列,从而提高性能, 4 估计是把整张表放入tempdb,因为那张表更新频繁, 5 所以SQL决定把整个表放入tempdb做下一步的排序或者其他操作, 6 不受其他的更新插入操作影响,这是我的个人理解
而出现索引假脱机的时候,那么表明需要做一些优化,例如加索引
1 XXXXXX(17478043) 9:29:18 2 出现索引假脱机说明你缺少某些很重要的索引 3 创建它就可以了 4 XXXXXXX 9:30:08 5 我看你昨天那个有个 排序 运算符,一般这样的运算需要使用排序或者索引
回到上面的例子,为什麽SQL1没有索引假脱机呢?
因为SQL1里使用in具有不确定性,而SQL2使用=具有确定性,然后SQL认为每次运行都需要排序干脆加一个索引算了
所以SQL2才有了“索引假脱机”这个运算符
在MSDN上找到了tempdb的其中一个用途:
1 tempdb 系统数据库是一个全局资源,可供连接到 SQL Server 实例的所有用户使用,并可用于保存下列各项: 2 3 4 •SQL Server 2005 数据库引擎创建的内部对象,例如,用于存储假脱机或排序的中间结果的工作表。
刚好QQ群里的某君也遇到“索引假脱机”
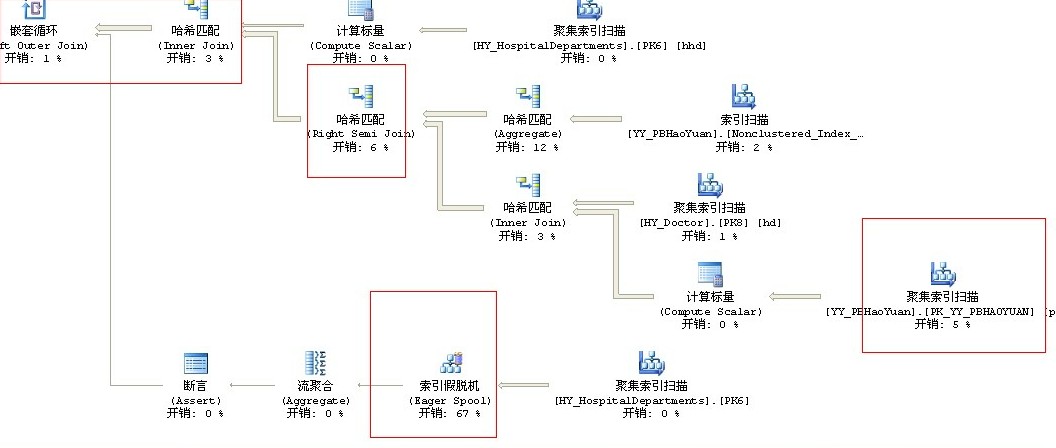
大家看了这个执行计划之后都解释了出现索引假脱机的原因:
聊天记录:
1 数据库认为帮你建一个索引再查找还快过直接扫描 2 XXXXX<huangzj1985@qq.com> 16:06:03 3 XXXXXXX,那如何优化? 4 XXXXXXXXX17478043) 16:06:37 5 建一个索引呗。。 6 XXXXXXXXX(17478043) 16:07:07 7 建了消除这个索引假脱机运算符了 8 9 XXXXXXXXXXXX(17478043) 16:07:51 10 一般情况下 需要用到聚合的列都应该有对应的索引 11 12 XXXXXXXXX(17478043) 16:08:15 13 因为聚合的第一步就是排序
14 缺少索引就会容易出现哈希运算
后来大家都给出了解决方案建议之后确实消除了这个“索引假脱机”了
1 seek 谓词 就是 索引列,这里应该是组合索引, 2 输出放到 include列 3 当然,组合顺序得考虑数据的分布情况,还有查询的语句,为了DML的性能考虑 ,可以把一些 选择性差的列放到 include 列 4 包含性索引列 5 6 7 XXXXXX 刚才那个 我加了索引和include 包含性索引列 8 确实不会有 索引假脱机了 9 10 XXXXXXXX<huangzj1985@qq.com> 9:50:39 11 速度方面呢? 12 XXXXXXXXXX(771021218) 9:50:44 13 索引假脱机 变成了 索引查找 消耗55%

现在加了索引性能好多了
所以以后大家看到“索引假脱机”不要以为SQLSERVER的索引没有起作用了,脱机了~
总结
其实关于脱机还有很多情况的,包括:lazy spool、Eagar spool、table spool、non clustered index spool...
在tempdb数据库中缓存用来处理一致性和避免hit

 浙公网安备 33010602011771号
浙公网安备 33010602011771号