etcd对boltdb的使用和改进
1. etcd存储结构图
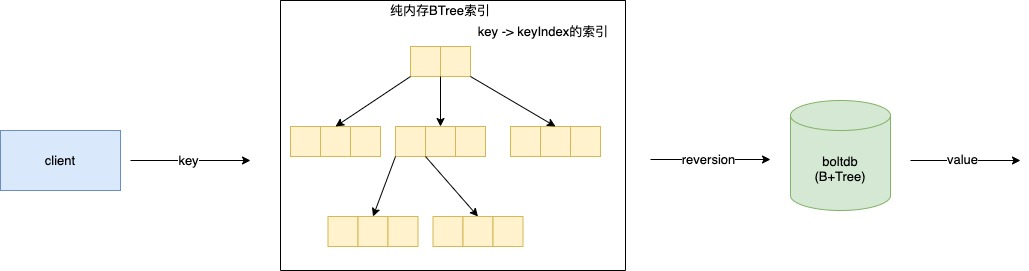
etcd存储到boltdb中的key是一个reversion,reversion可以看做是一个一直向上递增的版本号。
纯内存BTree索引我们称其为IndexTree。
所以一个key在boltdb中可能存储了多个值,但它的key reversion是不一样的,对于boltdb来说就是不同的key。但在IndexTree里一个key会对应一个KeyIndex对象。
当需要取key时需要先通过内存BTree索引得到对应的keyIndex对象,再从里面获取到reversion,再以reversion为key到botldb值进行value的获取。
以下是IndexTree的内部详情:
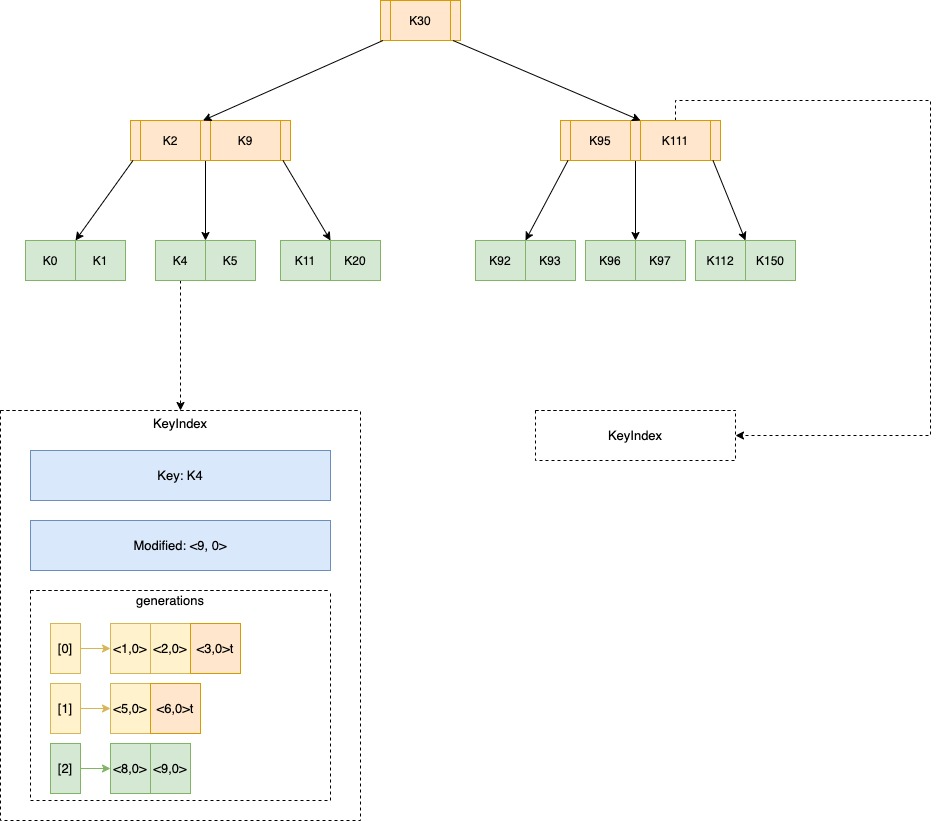
关于indexTree的具体细节可以参考2.1。
举例K4这个key在第0代具体存储在botldb中的情况:

在reversion是<3,0>时的操作是删除该key,在boltdb里只需要记录key,不需要记录value。
2. etcd对bbolt的使用
2.1. 使用reversion作为key
reversion是etcd的逻辑时钟,当etcd刚创建启动的时候版本号是1,随着对key的增删改操作而全局单调递增。
reversion的格式:
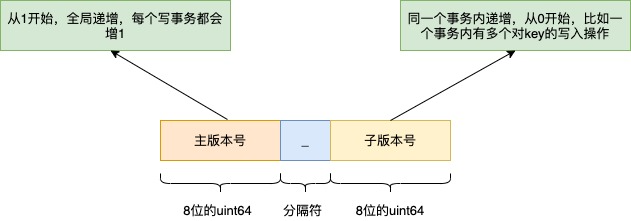
所以写入的reversion在整个系统里都是向上递增的,都是不会重复的,这也使得etcd可以构建MVCC的能力。
reversion序列化后是作为boltdb的key值,而用户key想要获取value,还需经过一层转换,即用户key到reversion的转换,这个转换就是内存索引来做的。
用户key -> KeyIndex -> reversion -> 用户value
以下是KeyIndex的结构图:
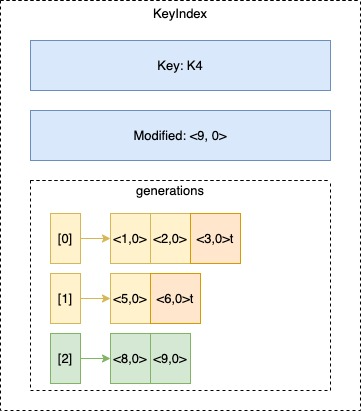
字段generations字段保存着该key的所有历史变动,它是个列表,每个单元代表一代,像上图的0和1带,后面都追加了个t,表示在此reversion时该key进行了删除,当key被删除时,该代的最后一个reversion会追加t标识,同时新增一个空的单元。
在查找时,如果client端指定了reversion,则按照指定的reversion找,这样可以找到历史版本,如果没指定,则按照当前事务的reversion找,即找到该key最新的reversion,比如<9, 0>。
由于插入的reversion key都是顺序递增的,所以写入一个page时,填充率可以设置高点(在etcd里设置了90%),减少页面的分裂(从而也减少了父页面的调整),同时是顺序写入,写时(etcd里是批量方式写入)修改大部分情况就集中在一个或几个page中,在sync时效率也会更高。
2.2. 读写事务的使用方式
etcd里只会维护一个读事务readTx和一个写事务batchTx。
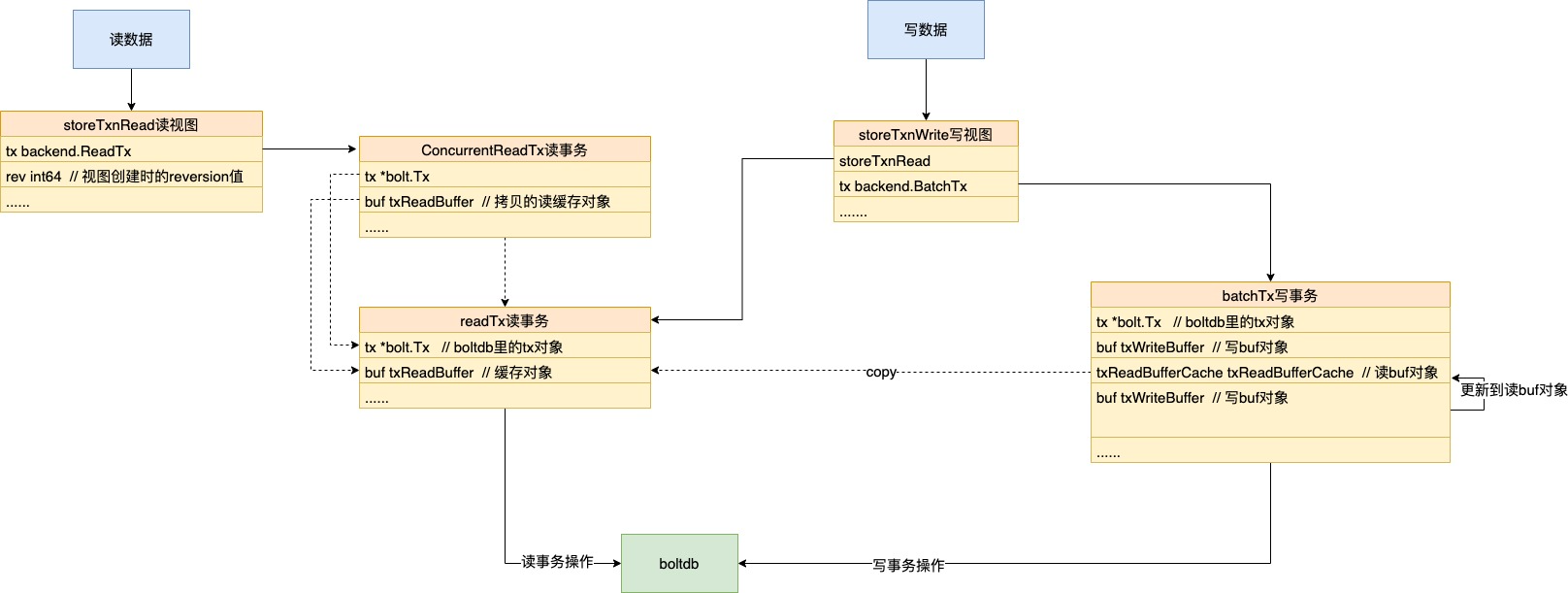
boltdb每次只能开启一个写事务,如果每个请求的修改都开一个写事务进行提交,那么写性能将会非常差,所以etcd是使用批量提交的方式。
但etcd不是直接使用boltdb提供的批量能力,而是自己上层维护了一个batchTx,自己来做聚合提交,这样会更加灵活高效。
批量提交的设计跟boltdb里的差不多,也是通过延时或者数量来决定是否要进行commit。但数据的提交时刻是不确定的,如果还没真正提交成功,那么此时再开启读事务时读不到的,所以为了能够即时读取到插入的数据,在写入流程中还会有个writeBack的流程。
写入流程:

writeBack的主要任务就是将新写入的数据更新到readBuf中去,这样新创建的读事务,就可以立刻看到这部分更新。
同时为了尽可能的提高读写并发,防止读事务阻塞写事务的执行,在创建写视图时会将readBuf中的数据进行拷贝,这样该读事务就可以不阻塞写视图对readBuf的修改,从而不阻塞写视图的执行。
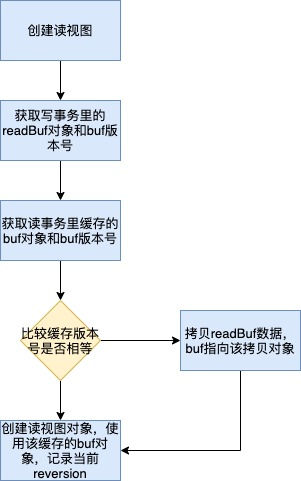
2.3. commit流程
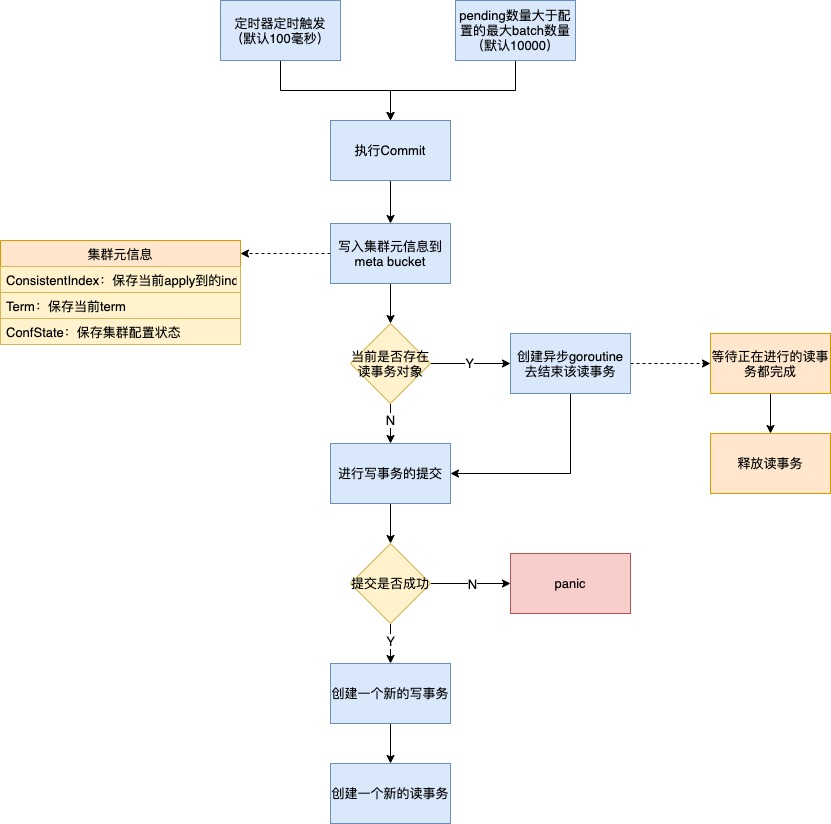
我们可以看到commit其实采用的是异步提交方式,即使数据还没落到boltdb,该数据也已经可以被读视图读取到了(读视图可以从indexTree和readBuf中可以读取到)。
假设commit失败了(一般失败可能是磁盘有问题或者磁盘容量满了),也不会影响它的正确性,因为这部分需要提交的内容已经持久化到raft log里了,同时commit失败也意味着consistentIndexKey的保存也是失败的,然后终止进程,重启的时候根据保存的consistentIndexKey继续将这部分内容进行apply。
2.4. Compaction
随着key的不断覆盖更新,某个key的版本肯定是越来越多的,如果不进行回收,那么容量肯定会一直膨胀,所以需要做compaction。
etcd可以手动指定压缩,也可以设定定期压缩策略,比如只保存12小时的版本,或者最新的10000个版本,不管是哪种策略,最后调用Compact时都是传入一个compact reversion。
Compaction的流程:
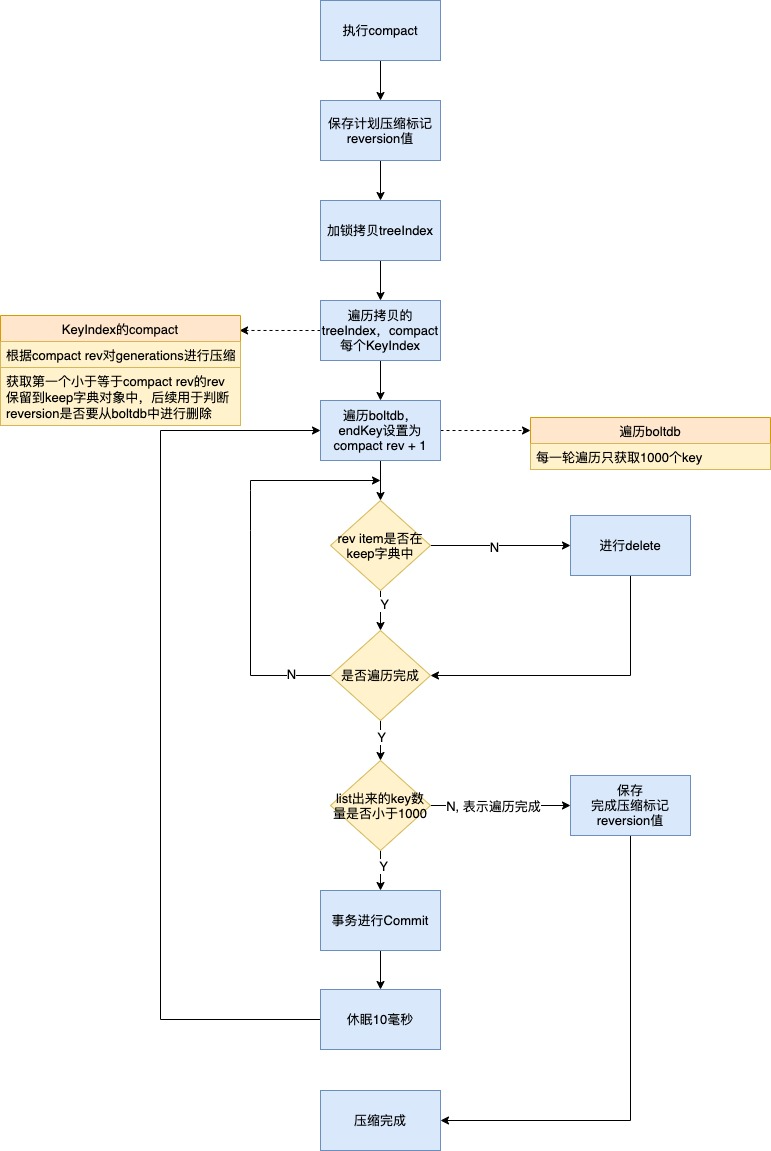
压缩其实主要压两个部分的内容,一个是内存索引的压缩,即indexTree的压缩;另外一个是boltdb的压缩,删除掉过时的reversion。
在遍历boltdb的kv时,每轮只获取1000个来进行判断是否要删除,此轮完成后都会强制进行一次forceCommit,然后休眠10毫秒,以降低对正在写的请求的影响。
这里有一个关键点是遍历boltdb的endKey是设置为compact rev + 1,也就表明它不需要遍历完整个boltdb,而只需要顺序遍历key小于compact rev + 1的部分,这也是顺序key的优势之一。
从图中可以看到有两个标记值,分别是
(1)计划压缩标记reversion值:表示将要进行的compact需要压缩到这个reversion;
(2)完成压缩标记reversion值:表示当前已压缩完成的reversion。
设置这两个值主要是为了防止压缩进行到一半时进程终止了,重启后可以根据这两个值来继续做Compact。
以一个KeyIndex的维度来看压缩generations是怎么进行的:
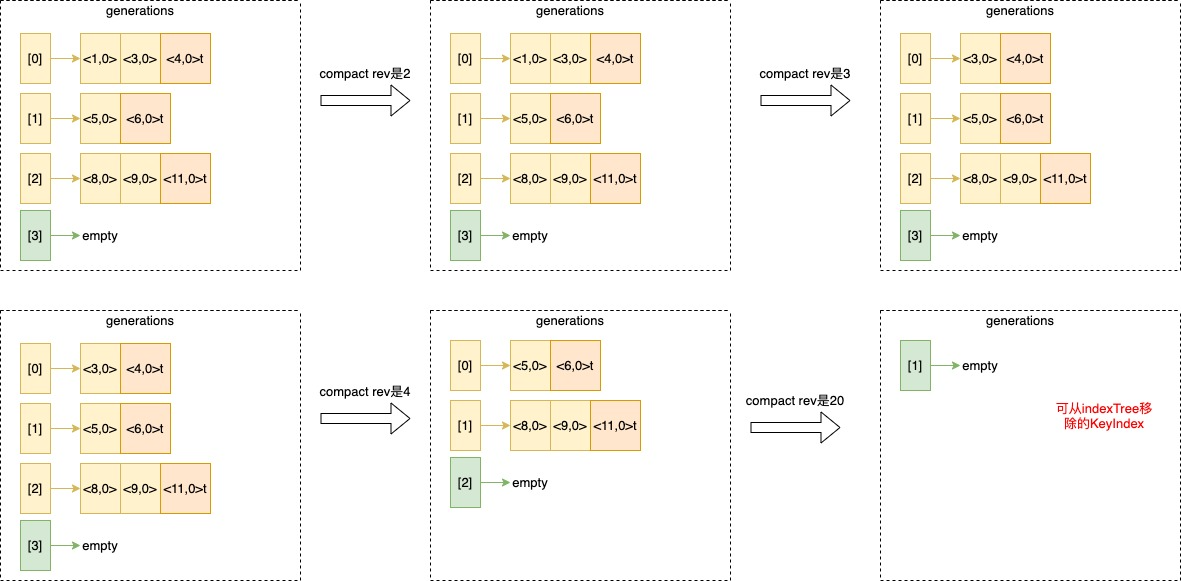
压缩的核心是:
(1)寻找目标generation,从前往后,找到一代最后一个reversion是大于等于compact rev的,假设为X;
(2)寻找reversion,从后往前,找到第一个小于等于compact rev的,将其加入keep字典对象,假设为Y;
(3)删除X之前的generation,删除Y之前的reversion;
(4)如果Y是Tombstone,则将X generation也进行删除;
(5)如果剩下的generation是个空generation,则将该KeyIndex进行删除。
3. 对boltdb的改进
etcd的v3版本,在etcd 3.5之前,存储层都是使用源生的boltdb版本作为持久化层的。
从etcd3.5.x开始后,fork并独立出了该项目叫bbolt,用于bug修复和性能优化。
3.1. freelist的优化
3.1.1. 数据结构的改变
原先的freelist的数据结构是个列表,当需要找一段连续的page页面时,它的时间复杂度是O(n),当db比较大的时候(比如100GB),这个效率就显得比较低了,commit时会出现延时抖动。
为了优化这个问题,增多了一种freelist的数据结构,使用哈希的数据结构来进行保存。
以下是它新加的关键数据结构:
freemaps map[uint64]pidSet // key是连续页面的数量,value是个集合,每个元素是一段连续页面的起始pageId forwardMap map[pgid]uint64 // key是起始pageId,value是连续页面的数量 backwardMap map[pgid]uint64 // key是结束pageId,value是连续页面的数量
比如要找连续的5个page的pageId,则直接freemap[5]是否有值,如果有则从集合里取一个pgid返回即可,此时时间复杂度是O(1);
如果freemap[5]是空,则需要遍历freemap找到一个大于5的(最差还是O(n)),然后取出进行截取,剩余的尝试合并入其它连续的页面里去,forwardMap和backwardMap就是用来做合并的,理论上一个forwardMap对象也能反推出backwardMap,但在合并时只知道pgid的情况下,要反推出backwardMap需要O(n)的复杂度,增加这个map对象可以变为O(1)复杂度,所以这里空间换时间的思路。
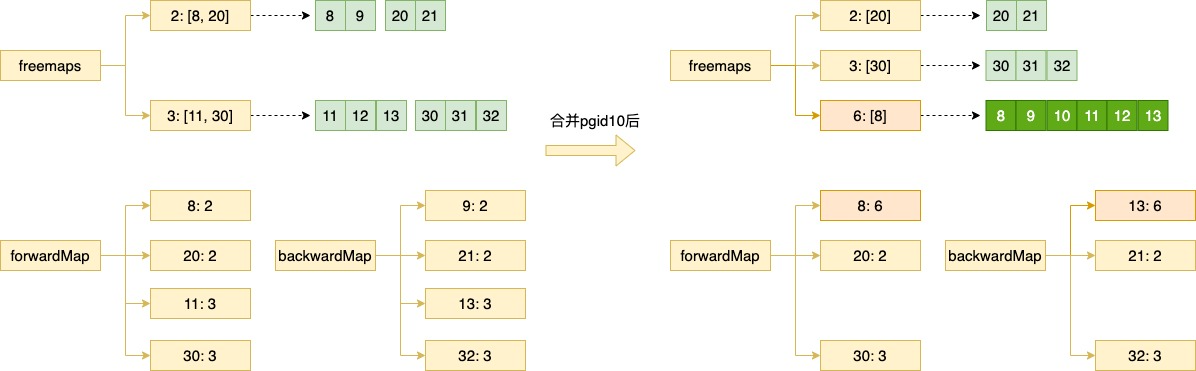
假设截取剩余的pgid是10,查看backwardMap[9]是否存在,如果是并入backwardMap[9];查看forwardMap[11]是否存在,如果是并入forwardMap[11],有可能因为pgid10,还能将backwardMap[9]和forwardMap[11]也连接起来形成一个更大更连续的page列表,合并的结果更新到freemaps。
如上图所示例子:
假设forwardMap[11]=3(即11,12,13),backwardMap[9]=2(即8,9),此时有个pgid10需要进行合并
则最后变成forwardMap[8]=6,backwardMap[13]=6,freemaps[6]=[8]
从这里我想到一个可优化点,在commit的时刻,page修改了时会需要freelist分配一个空闲page,假设我的修改涉及到了5个page,当前freelist分配时选中1个就进行返回,但我如果有连续的5个空闲page用来做分配,这个sync的效率是不是会更高,不知官方有没有去往这个方向做优化。
3.1.2. 不进行持久化
可以通过参数NoFreelistSync配置是否要持久化freelist,如果NoFreelistSync为true则不进行持久化,这样每次commit时都少了一次freelist的持久化开销,etcd该参数设置为true。
当重启时再通过扫描整个db重新构建起freelist的数据结构,缺点就是启动时扫描db要一会儿时间。
从根root开始扫描整个db,得到所有可达的pgids列表,然后从pgid为2(0和1是meta0和meta1的序号)开始遍历到最后一个pgid,得到不可达的pgids列表,然后通过不可达的pgids列表构建出freemaps、forwardMap和backwardMap等哈希数据结构。
3.2. mlock参数的添加
mlock是memory lock的含义,即内存锁定的意思,是操作系统级别的内存管理机制。
它的主要作用是防止操作系统将内存页面交换到磁盘,减少缺页中断的触发,提升访问性能。
对应到boltdb里则是在mmap的时候进行设置,锁定db文件内存映射的这部分内存地址。
在etcd里的配置参数是experimental-memory-mlock,默认是关闭的,如果机器内存充足,且需要高性能,可以将其设置为打开,性能应该会更好点。
3.3. bug的修复
比如修复高并发访问时的bug、一些特定平台的实现等。
但总体来说,整个架构思路还是之前的,并没有做非常大的重构。
原生boltdb的架构解析文章:boltdb架构解析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号