boltdb架构解析
1. 整体系统架构

boltdb是单机kv数据库,所有数据都保存在一个文件中,通过内存映射的方式进行数据读取和写入,存储结构采用类B+树的组织形式,支持一写多读的事务机制,支持bucket增删改查、bucket嵌套和k/v增删改查等功能,etcd的底层存储系统就是基于boltdb实现的,不过etcd是fork了bolt项目并基于此进行了优化。
2.详细数据结构

DB:代表着boltdb文件对象,引用着多个全局对象,比如meta对象、freelist对象、锁对象和事务列表等;
meta:db的元数据对象,里面保存着根pgid、freelist pgid、上次事务id和pageSize等基础信息;
Bucket:代表着一组key的集合,Bucket可以进行嵌套成为该Bucket的子Bucket;
page:boltdb文件里最小单位的保存结构,一般一个page size是4KB大小,但当里面的key比较大时也可能超过4KB,则这个page对象实际占用着文件里的2个page size大小;
node:当page加载到内存且有ele元素修改时就会初始化为node对象,是内存B+数的节点概念;
Tx:事务对象,包括读事务和写事务;
Cursor:游标概念,也可以叫它为访问对象,通过它在一个指定的Bucket B+树上进行遍历游走;
freelist:保存着可重复使用的pgid列表。
3. 数据组织格式

pgid是划分的Page的序号,从0开始,逐渐自增。
文件里的内容组织可以看做是由一个个的page组成,每个page大小一般为4KiB(大多数操作系统的页大小都是4KiB),根据page内容可以划分为三种类型:
(1)meta类型
(2)freelist类型
(3)数据类型:数据类型有划分为分支节点类型和叶子节点类型。
为什么要对齐操作系统的页大小呢?
因为操作系统是以页为单位管理内存的,当从磁盘加载数据时,最小的基本单位也是页大小,即使你只加载1字节,也会将1个页大小的数据加载进来,写时也是类似,避免同一个对象的数据跨页存储,这样读写都会导致至少两次IO,boltdb中以操作系统设置的页大小作为存储对象的基本单元,这样可以更高效的读写数据。
3.1. meta类型
meta在db文件中一共有2个,分别是meta0和meta1,它们分别保存在pgid 0和pgid 1的位置上。一般在进行数据操作前都是先通过它来先找到根部pgid,然后加载出根部的Bucket,然后进行查找,它相当于保存着整颗B+树的入口。
从文件里加载出来的Page内存形式的数据结构:
type page struct { id pgid // 该page对应的pgid值 flags uint16 // 该page的类型 count uint16 // 内部保存着的元素数量 overflow uint32 // 溢出的page的数量,一个物理结构page可能不够保存 ptr uintptr // 数据段,保存着真实数据 }
meta的内存形式的数据结构:
type meta struct { magic uint32 // 魔数,通过它来识别是否是boltdb的db文件 version uint32 // 版本号 pageSize uint32 // 操作系统设置的页大小 flags uint32 // 标识是meta类型的page root bucket // 指向根的pgid值 freelist pgid // 指向freelist的pgid值 pgid pgid // 当前用到的最大 page id(不包括),也即用到 page 的数量 txid txid // 上次写入的事务ID值 checksum uint64 // 校验和,用来检查meta数据的完整性 }

这里我们可以看到有meta0和meta1两个meta数据,这样做的原因是什么呢?
这是为了防止一个meta写坏了的情况下,可以通过另外一个meta进行恢复。
想象一下这个场景,当所有新page都落盘后,最后在进行meta的写入的时候,假设刷到一半,正好程序被kill掉了,这时程序再起来时读到刚刚那个写到一半的meta通过它的checksum就会发现它是个错的meta,此时就可以从另外一个meta进行加载恢复。
3.2. freelist类型
freelist在db文件中只有一个,但它的pgid不是固定在pgid 2的,随着数据的写入,freelist也会进行变更,它的pgid也是会进行变化的。它维护着空闲的pgid序号,当在执行时遇到需要分配pgid时,都会先从它这里查找空闲的pgid号,如果没有满足的则会对db文件进行扩充,得到一个新的pgid。
freelist的内存形式的数据结构:
type freelist struct { ids []pgid // 所有空闲的pgid列表 pending map[txid][]pgid // 保存着txid事务执行时free掉的pgid,当事务成功完成时可释放到ids列表中 cache map[pgid]bool // 用它可以快速查找到某pgid是否在ids或者在pending中 }

Page里的count元素因为是uint16位的,所以当空闲的pgids大于等于0xFFFF时,count是保存不下的,它需要通过其它方式来保存它的元素数量,保存方式是使用ptr的第一个uint64大小来保存数量,其它的就是pgid列表值,如下图所示:

3.3. 数据类型
数据类型是指保存真实数据的,根据用途又可以分位叶子类型和分支类型,叶子类型就是保存着真正的用户数据,分支类型保存的是索引数据,类似B+数的索引思想,在查找某个key时,都是从上往下找的,从分支节点里层层锁定目标的范围,最终找到具体的叶子节点,然后从叶子节点中取出真正的数据。
分支类型的物理存在形式:

pos 存储的是元素头的起始地址到元素的起始地址的相对偏移量,而非以 ptr 指针为起始地址的绝对偏移量,这样可以用尽量少的位数(pos 是 uint16) 表示尽量长的距离。
叶子类型的物理存在形式:

上面是物理存在形式,它们在插入或删除key/value时都会将其转换成node对象来进行操作,物理形式的Page eles的数据就会转换成node的inodes列表,数据结构如下:
type node struct { bucket *Bucket // 记录着所处Bucket的pgid值 isLeaf bool // 是否是叶子节点 unbalanced bool // 只有进行过删除才会将其置为true spilled bool // 是否已经进行过尝试分裂 key []byte // 该node的key,是inodes里最左边的key的值 pgid pgid // 该node对应的pgid值 parent *node // 该node的父node,如果本身是bucket root node,则为nil children nodes // 保存着该node下的变动过的子node对象 inodes inodes // 该node保存着的元素值列表 }
4. 索引组织格式
4.1.索引形式
boltdb的索引组织模式类似B+树,不过它的叶子节点间并没有用指针关联起来,所以遍历时需要类似中序遍历的方式将其遍历出来,这样做的原因其实也是一个取舍问题,少了叶子节点的连接,在插入时也可以简化树的复杂度调整。
本身物理组织形式也可以看出它是一种B+树的存储组织模式,在程序刚起来时,它并不是一开始就将所有数据加载进去,而是采用内存映射的方式将整个db文件映射到进程的虚拟内存空间,当真正需要进行访问时才进行真实读取,在进行修改时读取物理空间的Page初始化为node对象,然后进行inodes的新增、更新或删除,接着内存映射方式直接写入。
通过内存映射的读写方式比read、write系统调用执行效率更高,比如read系统调用方式,首先得将文件数据拷贝到内核空间缓冲区,然后再拷贝到用户空间,使用内存映射则直接将数据拷贝到物理内存中,进程虚拟地址指向这块物理内存,它减少了一次内核空间缓冲区的数据拷贝。
为什么要有内核缓冲区呢?
对于读:内核一般最小都会读一个页的数据,但用户可能只想要一个字节,这是从内核缓冲区拷贝一个字节给用户缓冲区即可,,同时内核缓冲区的数据可以给到cache进行缓存,这样下次用户再读时就可以直接从cache中取到了;而且还可能做些预读的优化,对于顺序读帮助比较大;
对于写:用户调用了write系统调用后,会先写入到内核缓冲区,但此时内核缓冲区并不是说立马刷到磁盘,而是可能会把内核缓冲区的数据积累到一定量的时候再一次性写入,这样可以提高写效率,但坏处就可以断电可能会丢失数据。
虽然mmap帮write也避免了两态拷贝的问题,但如果对于经常写的,mmap的写效率其实会比write方式差,多次写相当于是个随机写方式。同时mmap的刷盘由系统全权控制,但是在小数据量的情况下,应由应用本身手动控制更好。

以下是索引示意图:

在boltdb中bucket是可以嵌套的,可以把最上层的节点看做是根bucket,我们在第一层创建的bucket都是在这个根bucket之下。
bucket节点可以是分支节点也可以是叶子节点,比如上面的根bucket就是叶子节点,bucket2就是分支节点,取决于它包含的元素是否足够多,当它包含的元素很多时,它就会进行分裂,产生一个parent分支节点,然后分裂出来的节点和原始的节点都会成为这个parent的分支元素,此时该parent节点成为bucket节点,同时它是分支类型的。
图上的节点在内存里就是一个node对象,图上的每个节点里包含的子元素就是上面node对象的inodes列表,是这个节点包含的子元素,如果该节点是叶子节点,那么它的子元素就是key/value值,如果该节点是分支节点,那么它的子元素并不是实际的值,只是用来索引使用的值,这一点是跟B+树一致的,这样的好处是一个页节点就可以存放很多索引key,这样能够用最少的IO就能锁定目标key的位置。
4.2. 数据插入
插入的过程:
(1)根据bucketName定位到bucket所在的那颗B+树;
(2)使用要插入的key进行二分法定位查找,查找方式如下图所示,找到该key应该要插入的节点;
(3)将该节点转换为node对象,对node对象的inodes列表进行二分查找,找到需要插入的index位置,找比插入的key刚好大一点的index位置,然后将该index位置及之后的元素都往前挪一位,然后在index位置写入这个key。
这里举例在bucket2上插入efh11这个key为例:

4.3. 节点分裂
当不断的插入key后,某个节点上的元素肯定会变得很多,这时就会触发分裂(node的size大于pageSize大小时)。
分裂的行为是自下而上的,在commit阶段时,会由rootNode节点发起对有改动的子node尝试进行spill,然后递归进行下去,由最下面的node开始进行分裂,一直回溯到rootNode的调整。
节点分裂时它是对inodes里的元素进行分裂,计算出一个分裂的index位置,然后从这个位置处将其一分为二,比如x节点进行分裂,它会得到新x节点和分裂出来的x2节点。
分裂index位置的计算方式是遍历之前x节点的inodes元素,累加这些元素值,当size大于threshold的时候就停止累加,找到这个index位置了,threshold的计算方法如下:
threshold := int(float64(pageSize) * fillPercent) // pageSize一般是4KB,fillPercent一般是0.5
取0.5是个权衡的值,如果设置的过高,则很容易触发下一次的分裂,如果设置的过低,则空间利用率比较低。
如果上层是顺序写入的情况下,fillPercent可以设置的高点,这样空间利用率高且不会有频繁分裂的劣势。
根据节点类型的不同,分裂可以归纳为两种分裂,分别是:
(1)分裂的节点是bucket节点
(2)分裂的节点不是bucket节点
4.3.1. bucket节点上进行分裂

这里以bucket1上插入数据后发生分裂为例,当插入key abc99后,bucket1这个节点的总size大小超过了threshold,需要进行分裂,遍历bucket1上的所有子元素进行每个子元素size的累加,当遍历累加到key为abc97时,发现累加size将会超过threshold,所以会停止累加,分裂的index位置即为abc99这个位置,那么[abc, abc99)为一个节点,[abc99, abc101]为分裂出来的节点,同时因为它是bucket节点,所以需要分裂出一个parent节点作为新的bucket节点,它包含一个分支元素abc,索引key为abc,inodes里面包含了abc和abc97子元素(图上没有把分支元素里面细节画出来了,其实保存在bucket1上的abc里有个pgid x的,加载这个pgid x后就变成一个分支节点node,这个node对象里的inodes列表就包含了abc元素和abc97元素)。
4.3.2. 非bucket节点上进行分裂
非bucket节点不管是分支节点类型还是叶子节点类型,分裂方式都是一样的,这里以叶子节点分裂举例。

对上面的pgid为9的叶子节点插入数据举例,当它再插入一个key abc961,让这个节点的size大小再次超过threshold,进行分裂,这里有个细节,就是被分裂出来的节点,至少要包含两个元素,所以这次分裂index的位置会只到abc96位置就停止了,那么[abc, abc96)为一个节点,[abc96, abc961]为分裂出来的节点,新分裂出来的这个节点将会被bucket1上的abc分支节点node加入到它的inodes列表中。然后子节点调整完了,再判断父节点是否需要调整,如果bucket节点需要调整则调整方式跟4.3.1方式一样。
分裂总结:分裂只会在bucket级别的node上才会分裂出一个parent,而子的分裂只会扩展出兄弟节点。
4.4. 节点合并
当进行key删除后,有些叶子节点里的大多数key可能都被删除了,那么此时其实就可以将这些包含元素很少的节点进行合并,减少节点数量,加快查询。
判断是否可以合并的规则:
如果这个节点的size大小超过25%的pageSize大小并且拥有的子元素数量大于指定值,这个指定值对于分支节点来说是1,对于叶子节点来说是2,如果不满足这个条件则需要进行合并调整。
合并的行为是自上向下调整的,只有进行过删除操作的node节点,才会进行调整,同时当子节点进行了调整时,会触发让parent节点也尝试进行调整;当本节点调整完后,再遍历该节点下面的子节点进行调整,同样只会有删除操作过的节点才会进行调整。
节点的合并也分为两种情况进行处理:
(1)合并的节点是bucket节点
(2)合并的节点是非bucket节点
4.4.1. bucket节点上进行合并
当且仅当这个node是分支节点且它的inodes列表里的元素只有1个时(一般产生分支类型的bucekt节点的时nodes列表里最少也会有2个元素),它才会进行合并操作。
合并步骤:把bucket节点的inodes上仅有的那个元素根据pgid加载为node对象,我们称为它子node对象,然后将子node的属性和inodes列表都赋值给bucket节点,接着就可以释放掉这个子node了。
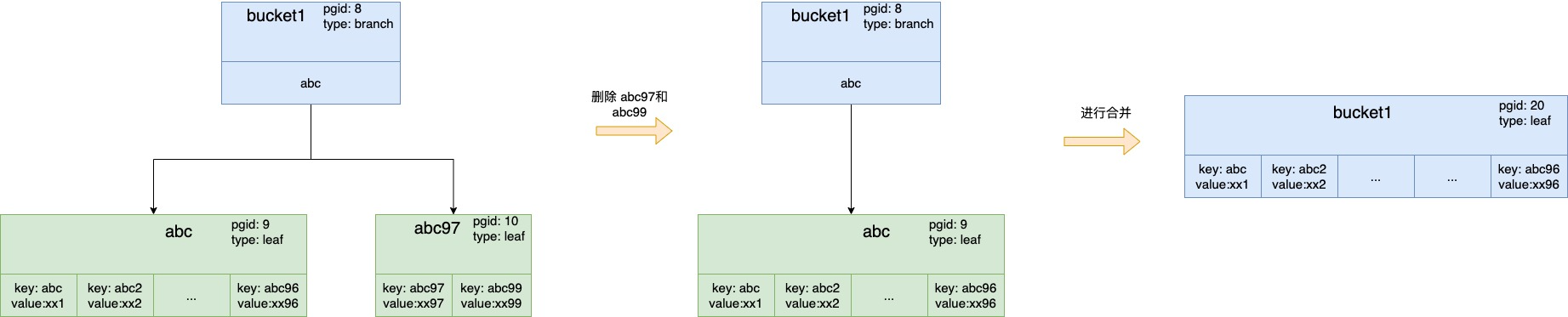
这里合并指的是bucket节点是个分支类型,然后合并后变为了叶子类型,并不是指bucket之间进行合并,每个bucket都是一颗B+树,B+树与B+树之间不互相干扰。
当插入一个node里很小的值时,展示更新索引树的逻辑,这里使用了个技巧,使用原来的oldkey来找,然后替换掉它,虽然此时不是有序的,但当轮到这个parent节点调整时,它会进行一次排序。
4.4.2. 非bucket节点上进行合并
这里分三种情况处理。
情况1:该节点下已经没有子元素了,即inodes列表为空
直接从parent中移除掉个该节点,然后触发parent尝试进行合并调整。

调整完后,可以发现,再触发parent进行调整时,它就是4.4.1上的bucket节点上进行合并。
情况2:该节点是parent节点下的最左边的节点
将右边的兄弟节点合并到该节点上来,然后触发parent尝试进行合并调整。

情况3:非情况1和非情况2的情况下
将该节点合并到左边的兄弟节点上去,然后触发parent尝试进行合并调整。

其实情况2和情况3类似,都是向左节点合并的过程。
5. 事务实现原理
说到事务,想到的就是它一般都需要满足ACID特性,这些特性满足的越好,说明事务实现的越好。
A(Atomicity)即原子性:可以理解为事务中的事件要么都执行成功,要么都不执行,侧重于出现问题时的可回滚性;
C(Consistency)即一致性:侧重于数据的一致性,比如在事务执行之前和事务执行之后,数据不能错,比如在转账场景中,不能因为转账失败而出现总资金变多或变少的情况;
I(Isolation)即隔离性:事务执行期间做到的隔离级别,根据隔离强度,有4个隔离级别,分别是读未提交、读已提交、可重复读和序列化,从左往右隔离级别逐渐增强,对于boltdb来说,它实现的隔离性是可重复读级别;
D(Durability)即持久性:请求成功后,数据能够被持久化下来,即使断电重启也不会丢失数据。
以下就分别以这四个特性来说明boltdb是如何去实现的。
5.1. 原子性
boltdb的写入有个特点,就是有改动的node节点及其相关的整条链路都会进行改变,包括最顶上的meta节点,它的改变是增量方式的改变,增量的意思是指假设某个node对象变化了,那么这个node的数据就会写入到一个新的page内存页里,不影响之前的page页,在最后commit阶段时会将这些新node对象对应的page内存页进行新page id的分配,且根据pgid号计算好偏移量写入到boltdb文件中。

图中的old表示这个node对象的对应page页面在写事务成功写入后,将会加入到即将被回收的page列表(需要等待最旧的读事务id大于该写入事务id时才可回收);
图中的new表示这个node对象是进行过数据操作的,它对应的page页面是新分配的,当事务写入成功后,后续的读事务都是读到这个最新的;
图中meta里meta1标着一个latest,它的意思是这个meta是最新写入的,事务id值会比meta0的大。
备注:boltdb只支持一个写事务在运行,其它写事务需要等上个写事务完成才能开始。
写入过程:
(1)将old的node对象的pgid都加入到freelist里的pending队列里;
(2)将new的node对象的page进行写入刷盘;
(3)对meta数据进行写入刷盘。
可以看到如果在这个过程中只有当最后对meta数据进行写入刷盘后,这新写的整条链路才会生效,这也是能做到原子性的关键一步。
如果在这些过程中出现了失败,那么进行回滚,回滚主要做的就是将刚刚old node的pgid从freelist中释放出来,freelist根据它的pgid重新从内存映射中读一份出来即可,之前写入新node的page数据不用回滚,最终数据都会被新数据的覆盖掉的。
5.2. 一致性
该特性其实偏重于应用层面去判别是否满足一致性,不是存储里面的多副本一致性,这里要区分开,比如数据在执行完事务请求前后,数据是否完整的,一致的,由于5.1的原子性的实现,其实已经达到了一致性的要求。
5.3. 隔离性
boltdb目前实现的隔离级别是可重复读,已开启的读事务不受后续写入事务的影响,这个依赖于以下几点实现:
(1)boltdb只支持一写多读,这让它的事务实现大大简化;
(2)在开启读事务时,会进行最新meta元信息的拷贝,并且在db对象的txs列表中放入自己的读事务id,表示这个读事务在进行时,这个事务id相关page页面在该读事务完成之前不能进行回收,所以读事务在事务期间内任意时刻读的过期数据都是可以读到的,page数据不会销毁;
那什么时刻进行正确的回收呢?
在每次开启一个写事务时,都会从txs里找到一个最小的事务id值,然后对它进行-1得到targetTxId(表示目前db中没有比targetTxId更小的读事务在运行了),然后遍历freelist里的pending字典里所有小于等于targetTxId的key值(pending字典的key值就是写事务id值,value是该写事务对应的可以释放掉的page id列表),然后将key对应的value里的page id列表释放掉,表示后续写事务可复用这些pgid。
(3)page的写入是增量方式写入的,不会影响到老的page,这一点我们在5.1.的原子性分析上说过了,所以读事务在事务期间任意时间内读到的数据都是一样的,只要没回收,它就不会改变。
5.4. 持久性
这个在boltdb中是个可选配置,配置项是NoSync,默认是false,即每次写完新page或写完meta后都会主动调用sync进行刷盘,防止断电情况发生时会导致数据丢失,如果设置为true,虽然写入速度快了,保证不了持久性。
6. freelist对象
因为boltdb的每一次写入都会涉及到新page的分配和旧page的淘汰,所以page必然是需要进行复用的,否则整个db文件会不断的膨胀。
freelist它的主要职责就是维护一组可复用的pgid列表和一组待释放的pgid列表,分别对应到freelist的ids字段(是个列表,里面放着的都是空闲的pgid)和pendings字段(key是txid,value是该事务对应的可以淘汰的pgid列表)

7. cursor对象
cursor是游走对象,一个bucket会对应到一个cursor,在这个bucket上查找元素,都由该cursor对象进行查找,cursor对象会使用它的stack列表字段记录走过的节点,以便进行回溯,相当于它提供了能在一颗B+树上进行游走定位和遍历的能力。
它的stack字段比较关键,我们来看下它的数据结构:
type Cursor struct { bucket *Bucket stack []elemRef } type elemRef struct { page *page node *node // 一般优先看node对象是否存在,存在则直接从它找(因为它是最新的,可能插入过数据的),否则从page找,page是从mmap加载过来的 index int // inodes里的index位置 }
它提供的功能有:
(1)First、Last方法可以分别返回这个Bucket的最小的k/v值和这个Bucket下的最大的k/v值;
(2)Next、Prev方法可以分别返回当前k/v的下一个k/v和上一个k/v;
(3)Seek方法可以根据给定的key返回该k/v。

cursor stack里记录着它在游走到pgid13这个node节点时,它一共经过的节点,并且维持着先进后出的顺序,方便回溯,同时因为一个node中里面是含有多个子元素的,所以使用index来记录当前是到哪个子元素了。index+1可以往后推即next,index-1可以往前推。即prev;
在游走过程中,遍历完了一个node的所有子元素,需要换node时即可以pop出最上面的node,然后对下一个顶部的node对象进行index+1或者-1来找到下一个目标node。
以上面这个图举例,目前指向efg1,调用Next()后指向efg2,再调用Next()后就需要换node了,对cursor stack进行操作,将pgid13 pop出,pgid10变成顶部,对它的index做+1操作,得到pgid14这个node对象,将其加入stack里,然后获取pgid14的index为0的key即efi。
8.核心流程
8.1.插入key的完整过程

总的来说可以分为三个阶段:
事务开始阶段:对资源进行准备阶段,比如加锁、回收资源等操作;
事务执行阶段:业务逻辑执行过程,比如创建bucket、增删改查数据等操作
事务提交阶段:进行page的调整,比如合并或分裂,进行page数据的写入刷盘,最后释放资源。
8.2. 批量插入
boltdb主要优势在于读多写少,对于写入请求多的,如果一次只能写一个,那确实效率太低了,所以提供了批量写入的方法,在代码里是Batch方法。
跟Batch行为有关的有两个参数
MaxBatchDelay: 一批最长等待时间,默认是10ms,超过则可以将目前收到的作为一批进行同一事务处理了 MaxBatchSize: 一批最大请求数,默认是1000个,超过则可以作为一批进行同一事务处理了
在一定的时间内收集一批请求(或者请求数先到达指定数量),同一批请求用一个update事务处理,如果批量处理过程中,有某个请求失败了,则将其挪出去,让其单独去update,其它的继续开始一轮执行,但需要保证这些请求都是可重入的,因为可能会被执行多次。
8.3. remap过程
因为内存映射在刚开始映射的时候就指定了映射的长度大小(boltdb是在开始的时候指定了db文件的大小),所以随着写入量的增大,db文件原先的长度肯定是不够用的,这时之前内存映射指定的长度是不够的,所以需要重新进行映射,这个过程发生在需要分配新page时,从freelist中找不到可以复用的时候,就需要扩db文件来满足新的写入了,这个过程是先进行重映射过程,然后再进行db文件扩大,最后是新page数据通过内存映射方式写入db文件。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号