

Visual Instruction Tuning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

37th Conference on Neural Information Processing Systems (NeurIPS 2023)
Abstract
使用机器生成的指令跟踪数据的指令调优大语言模型(LLM)已被证明可以提高新任务的零样本能力,但这一想法在多模态领域的探索较少。我们首次尝试使用纯语言GPT-4来生成多模态语言-图像指令遵循数据。通过对这些生成的数据进行指令调整,我们引入了LLaVA:大型语言和视觉助手,这是一种端到端训练的大型多模态模型,连接视觉编码器和LLM,用于通用视觉和语言理解。为了促进未来对视觉指令遵循的研究,我们构建了两个具有多样性和挑战性的应用型任务的评估基准。我们的实验表明,LLaVA表现出令人印象深刻的多模态聊天能力,有时在没见过的图像/指令上表现出多模态GPT-4的行为,在合成的多模态指令遵循数据集上与GPT-4的相对得分为85.1%。当对Science QA进行微调时,LLaVA和GPT-4的协同作用达到了92.53%的最先进精度。我们公开GPT-4生成的可视化指令调优数据、我们的模型和代码。
1 Introduction
人类通过视觉和语言等多种渠道与世界互动,因为每个渠道在表达和交流某些概念方面都具有独特的优势,从而有助于更好地理解世界。人工智能的核心愿望之一是开发一种通用助手,它可以有效地遵循多模态视觉和语言指令,与人类在野外完成各种现实世界任务的意图相一致[4,26]。
为此,社区对开发语言增强基础视觉模型[26,16]产生了新的兴趣,该模型在开放世界视觉理解方面具有强大的能力,如分类[39,21,56,53,38]、检测[28,61,32]、分割[25,62,57]和文字说明[49,27],以及视觉生成和编辑[41,42,55,15,43,29]。我们向读者推荐Computer Vision in the Wild阅读列表,以获取最新的文献汇总[12]。在这些工作中,每个任务都由一个大型视觉模型独立解决,在模型设计中隐含地考虑了任务指令。此外,语言仅用于描述图像内容。虽然这使语言能够在将视觉信号映射到语言语义(人类交流的常见渠道)方面发挥重要作用,但它导致模型通常具有固定的界面,交互性和对用户指令的适应性有限。
另一方面,大语言模型(LLM)表明,语言可以发挥更广泛的作用:通用助理的通用接口,在该接口中,各种任务指令可以用语言明确表示,并引导端到端训练的神经助理切换到感兴趣的任务来解决它。例如,最近ChatGPT [34]和GPT-4 [35]的成功证明了对齐LLM在遵循人类指令方面的强大作用,并激发了开发开源LLM的巨大兴趣。其中,LLaMA [48]是一种与GPT-3性能相匹配的开源LLM。Alpaca [47]、Vicuna [9]、GPT-4-LLM [37]利用各种机器生成的高质量指令遵循样本来提高LLM的对齐能力,与专有LLM相比,报告了令人印象深刻的性能。重要的是,这些工作仅使用文本。
在本文中,我们提出了视觉指令调优,这是首次尝试将指令调优扩展到语言-图像多模态空间,为构建通用的视觉助手铺平道路。特别是,我们的论文做出了以下贡献:
- 多模态指令遵循数据。一个关键的挑战是缺乏视觉-语言指令遵循数据。我们使用ChatGPT/GPT-4提供了一种数据改造视角和流水线,将图像-文本对转换为适当的指令遵循格式。
- 大型多模态模型。我们开发了一个大型多模态模型(LMM),通过连接CLIP [39]的开集视觉编码器和语言解码器Vicuna [9],并对我们生成的指令视觉语言数据进行端到端微调。我们的实证研究验证了使用生成的数据进行LMM指令调整的有效性,并为构建遵循视觉智能体的通用指令提供了实用提示词。当与GPT-4集成时,我们的方法在Science QA [33]多模态推理数据集上实现了SoTA。
- 多模态指令遵循基准。我们为LLaVA-Bench提供了两个具有挑战性的基准,包括各种配对图像、说明和详细注释。
- 开源。我们向公众发布了以下资产:生成的多模态指令数据、代码库、模型检查点和可视化聊天演示。
2 Related Work
Multimodal Instruction-following Agents. 在计算机视觉中,现有的构建指令跟随智能体的工作可以大致分为两类:(i)端到端训练的模型,对每个特定的研究主题分别进行探索。例如,视觉语言导航任务[3,19]和Habitat [46]要求具身人工智能智能体遵循自然语言指令,并采取一系列动作来完成视觉环境中的目标。在图像编辑域中,给定输入图像和告诉智能体要做什么的书面指令,InstructionPix2Pix [6]通过遵循人工指令来编辑图像。(ii)通过LangChain [1]/LLM [34]协调各种模型的系统,例如Visual ChatGPT [52]、X-GPT [62]、MM-REAT [54]、VisProg [18]和ViperGPT [45]。虽然在构建指令跟随智能体方面有着相同的目标,但我们专注于为多个任务开发一个端到端训练的语言-视觉多模态模型。
Instruction Tuning. 在自然语言处理(NLP)社区中,为了使LLM(如GPT-3 [7]、T5 [40]、PaLM [10]和OPT [59])能够遵循自然语言指令并完成现实世界的任务,研究人员探索了LLM指令调整的方法[36,51,50],从而分别产生了指令调整的对应物,如InstructionGPT [36]/ChatGPT [34]、FLAN-T5 [11]、FLAN-PaLM [11]和OPT-IML [22]。结果表明,这种简单的方法可以有效地提高LLM的零样本和小样本泛化能力。因此,将NLP的思想借用到计算机视觉中是很自然的。更广泛地说,具有基础模型的教师-学生蒸馏思想已在其他主题中进行了研究,如图像分类[14]。Flamingo [2]可以被视为多模态域中的GPT-3时刻,因为它在零样本任务迁移和上下文学习方面具有强大的性能。在图像-文本对上训练的其他LMM包括BLIP-2 [27]、FROMAGe [24]和KOSMOS-1 [20]。PaLM-E [13]是一种用于具身人工智能的LMM。基于最近“最好的”开源LLM——LLaMA,OpenFlamingo [5]和LLaMA-Adapter [58]是开源的努力,使LLaMA能够使用图像输入,为构建开源的多模态LLM铺平了道路。虽然这些模型具有很好的任务迁移泛化性能,但它们并没有明确地与视觉语言指令数据进行调整,而且与纯语言任务相比,它们在多模态任务中的性能通常不足。本文旨在填补这一空白,并研究其有效性。最后,请注意,视觉指令调整与视觉提示词调整不同[23]:前者旨在提高模型的指令跟随能力,而后者旨在提高模型自适应中的参数效率。

3 GPT-assisted Visual Instruction Data Generation
社区见证了公共多模态数据(如图像-文本对)数量的激增,从CC [8]到LAION [44]。然而,当涉及到多模态指令遵循数据时,可用的数量是有限的,部分原因是创建此类数据的过程很耗时,而且在考虑人群搜索时定义不太明确。受最近GPT模型在文本注释任务[17]中的成功启发,我们提出基于广泛存在的图像对数据,利用ChatGPT/GPT-4进行多模态指令遵循数据收集。
对于图像Xv及其相关联的文字说明Xc,自然地创建一组问题Xq,意图指示助手描述图像内容。我们提示GPT-4整理这样一个问题列表(详见附录)。因此,将图像-文本对扩展到其指令遵循版本的一种简单方法是Human:Xq Xv<STOP>Assistant:Xc<STOP>。尽管构建成本低廉,但这个简单的扩展版本在指令和响应中都缺乏多样性和深入的推理。
为了缓解这个问题,我们利用纯语言的GPT-4或ChatGPT作为强大的教师(两者都只接受文本作为输入),创建涉及视觉内容的指令遵循数据。具体来说,为了将图像编码为其视觉特征以提示纯文本GPT,我们使用了两种类型的符号表征:(i)说明文字通常从各种角度描述视觉场景;(ii)边界框通常定位场景中的目标,并且每个框对目标概念及其空间位置进行编码。表14的顶部方框中显示了一个示例。
这种符号表征允许我们将图像编码为LLM可识别序列。我们使用COCO图像[30]并生成三种类型的指令遵循数据。表14的底部方框中显示了每种类型的一个示例。对于每种类型,我们首先手动设计几个示例。它们是我们在数据收集过程中唯一的人工注释,并在上下文学习中用作查询GPT-4的种子示例。
- 会话:我们设计了助理和一个人之间的对话,询问有关这张照片的问题。答案的语气就像助理正在看到图像并回答问题一样。关于图像的视觉内容,我们提出了一系列不同的问题,包括目标类型、目标计数、目标动作、目标位置、目标之间的相对位置。只考虑有明确答案的问题。详细提示见附件。
- 详细说明:为了包含对图像的丰富而全面的描述,我们创建了一个具有这样意图的问题列表。我们提示GPT-4,然后整理列表(请参阅附录中的详细提示词和整理过程)。对于每个图像,我们从列表中随机抽取一个问题,要求GPT-4生成详细描述。
- 复杂的推理:以上两种类型侧重于视觉内容本身,在此基础上我们进一步创造了深入的推理问题。答案通常需要遵循严格的逻辑,逐步推理。
我们总共收集了158K个独特语言-图像指令遵循样本,其中对话样本58K个,详细描述样本23K个,复杂推理样本77K个。我们在早期实验中排除了ChatGPT和GPT-4的使用,发现GPT-4始终提供更高质量的指令遵循数据,如空间推理。
4 Visual Instruction Tuning
4.1 Architecture
主要目标是有效利用预先训练的LLM和视觉模型的功能。网络架构如图1所示。我们选择Vicuna [9]作为由Φ参数化的LLM fΦ(·),因为它在公开可用的检查点[47,9,37]中的语言任务中具有最好的指令遵循能力。
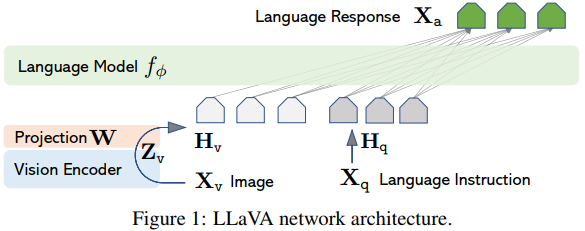
对于输入图像Xv,我们考虑预训练的CLIP视觉编码器ViT-L/14 [39],其提供视觉特征Zv=g(Xv)。在我们的实验中考虑了最后一个Transformer层之前和之后的网格特征。我们考虑一个简单的线性层来将图像特征连接到单词嵌入空间中。具体而言,我们应用可训练投影矩阵W将Zv转换为语言嵌入token Hv,其与语言模型中的单词嵌入空间具有相同的维度:
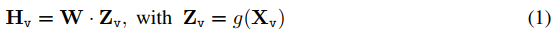
因此,我们有一系列视觉token Hv。请注意,我们的简单投影方案是轻量级的,这使我们能够快速迭代以数据为中心的实验。还可以考虑连接图像和语言表征的更复杂的方案,例如Flamingo [2]中的门控交叉注意力和BLIP-2 [27]中的Q-former。我们将探索LLaVA可能更有效、更复杂的架构设计作为未来的工作。

4.2 Training
对于每个图像Xv,我们生成多回合会话数据![]() ,其中T是回合总数。我们将它们组织成一个序列,将所有答案视为助手的回答,第 t 轮的指令
,其中T是回合总数。我们将它们组织成一个序列,将所有答案视为助手的回答,第 t 轮的指令![]() 为:
为:
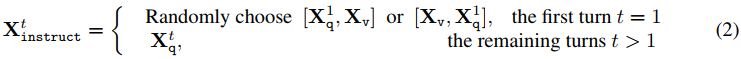
这导致了多模态指令遵循序列的统一格式,如表2所示。我们使用LLM的原始自回归训练目标,对预测token执行LLM的指令调整。

具体地,对于长度为L的序列,我们通过以下方式计算目标答案Xa的概率:
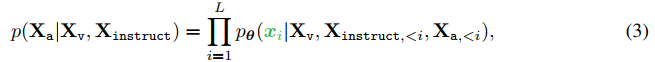
其中θ是可训练参数,Xinstruct,<i和Xa,<i分别是在当前预测token xi之前的所有轮次中的指令token和回答token。请参见表2以获取预测token的说明。对于(3)中的条件句,我们明确地添加了Xv,以强调图像是定位所有答案的,并且为了更好的可读性,我们省略了Xsystem-message和所有以前的<STOP>。对于LLaVA模型训练,我们考虑两阶段的指令调整过程。
阶段1:特征对齐的预训练。为了在概念覆盖率和训练效率之间取得平衡,我们将CC3M过滤为595K个图像-文本对。有关过滤过程的详细信息,请参阅附录。使用第3节中描述的朴素展开方法,将这些对转换为指令后面的数据。每个样本都可以被视为一个单独的会话。为了构造(2)中的输入Xinstruct,对于图像Xv,随机采样问题Xq,这是请求助手简要描述图像的语言指令。基本事实预测答案Xa是原始说明文字。在训练中,我们保持视觉编码器和LLM权重冻结,并仅在可训练参数θ=W(投影矩阵)的情况下最大化(3)的似然性。以这种方式,图像特征Hv可以与预先训练的LLM单词嵌入对齐。这个阶段可以理解为训练用于固定LLM的兼容视觉tokenizer。
阶段2:端到端微调。我们总是保持视觉编码器权重冻结,并继续更新LLaVA中投影层和LLM的预训练权重;即可训练参数为(3)中的θ={W,Φ}。我们考虑两个具体的用例场景:
- 多模态聊天机器人。我们根据第3节中的数据,通过对158K语言-图像指令进行微调,开发了一个聊天机器人。在这三种类型的回答中,会话是多回合的,而另外两种是单回合的。它们在训练中是均匀采样的。
- 科学问答。我们在ScienceQA基准[33]上研究我们的方法,这是第一个大规模的多模态科学问题数据集,通过详细的讲座和解释来注释答案。每个问题都以自然语言或图像的形式提供了一个上下文。助手用自然语言提供推理过程,并在多项选择中选择答案。对于(2)中的训练,我们将数据组织为单回合对话,将问题和上下文组织为Xinstruct,将推理和答案组织为Xa。
5 Experiments
我们分别在两个主要实验环境中评估了LLaVA在指令遵循和视觉推理能力方面的性能:多模态聊天机器人和ScienceQA数据集。我们使用8张A100训练所有模型,遵循Vicuna的超参数[9]。我们在1个epoch的过滤CC-595K子集上预训练我们的模型,学习率为2e-3,批量大小为128,并在3个epoch的LLaVA-Instruct-158K数据集上微调,学习率是2e-5,批量大小是32。有关更多训练详细信息,请参阅附录。
5.1 Multimodal Chatbot
5.2 ScienceQA
6 Conclusion
本文展示了视觉指令调整的有效性。我们提出了一种自动流水线来创建语言-图像指令遵循数据,并在此基础上训练LLaVA,这是一种多模态模型,用于遵循人类意图完成视觉任务。当对ScienceQA进行微调时,它实现了新的SoTA准确性,当对多模态聊天数据进行微调时实现了卓越的视觉聊天功能。此外,我们提出了第一个研究多模态指令遵循能力的基准。本文是视觉指令调整的第一步,主要关注现实生活中的任务。关于LLaVA在学术基准上的更多定量结果,请参考视觉指令调整的改进基线[31]。我们希望我们的工作能够启发未来建立更强大的多模态模型的研究。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号