Meta-Reinforcement Learning of Structured Exploration Strategies
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, Canada.
Abstract
探索是强化学习(RL)中的一个基本挑战。目前许多深度RL的探索方法使用任务不可知的目标,例如基于状态访问的信息增益或奖金。然而,RL的许多实际应用涉及学习不止一个任务,并且先前的任务可以用来告知在新任务中应该如何进行探索。在这项工作中,我们研究了先前的任务如何告知智能体如何在新的情况下有效地探索。我们引入了一种新的基于梯度的快速自适应算法——具有结构噪声的模型不可知探索(MAESN)——以从先前的经验中学习探索决策。先验经验既用于初始化策略,又用于获取潜在的探索空间,该空间可以将结构化的随机性注入到策略中,从而产生由先验知识告知的探索决策,并且比随机动作空间噪声更有效。我们表明,与先前的元RL方法、没有学到探索决策的RL和任务不可知的探索方法相比,MAESN在学习探索决策方面更有效。我们在各种模拟任务上评估了我们的方法:轮式机器人的运动、四足步行器的运动和目标操纵。
1 Introduction
深度强化学习方法已被证明可以通过简单地探索环境和体验奖励,在最少的监督下学习从游戏[17]到机器人控制[14, 20]的复杂任务。随着任务变得更加复杂或时间延长,简单的探索决策变得不那么有效。先前的工作提出了基于内在动机[23, 26, 25]、状态访问计数[16, 27, 2]、Thompson采样和自举模型[4, 18]、面对不确定性的乐观主义[3, 12]和参数空间探索[19, 8]等基于标准的指导性探索。这些探索决策在很大程度上与任务无关,因为它们旨在提供良好的探索,而不利用任务本身的特定结构。
然而,与现实世界交互的智能体可能需要学习许多任务,而不仅仅是一个,在这种情况下,应该使用先前的任务来告知如何执行新任务中的探索。例如,一个负责学习新家务的机器人可能有学习其他相关家务的经验。它可以利用这些经验来决定如何探索环境,更快地获得新技能。同样,一个以前已经学会在不同建筑中导航的步行机器人,在必须学会在迷宫中导航时,不需要重新获得行走技能,只需要在导航策略的空间中探索。
在这项工作中,我们研究了如何利用来自多个不同但相关的先前任务的经验,通过元学习自主获取定向探索决策。元学习,或学会学习,是指学习策略的问题,通过使用先前在不同但相关任务上的经验,可以快速适应新任务[23, 28, 10, 29, 1, 21, 22]。在RL的背景下,元学习算法通常分为以下类别之一——基于RNN的学习者[5, 30]和基于梯度下降的学习者[6, 15]。
RNN元学习者通过训练循环模型[5, 30]来解决元RL问题,该模型获取过去的状态、动作和奖励,并预测将最大化奖励的新动作,在几个交互事件中具有记忆。这些方法对于学习探索来说并不理想。首先,好的探索决策与最优策略有质的不同:虽然最优策略在完全观察到的环境中通常是确定性的,但探索在很大程度上取决于随机性。简单地将元RL问题改写为RL问题的方法通常会获得表现出不足以在新环境中有效探索困难任务的可变性的行为。相同的策略必须表示高度探索性的行为,并非常快速地适应最优行为,这对于动作分布的典型时不变表示来说变得很困难。其次,这些方法旨在使用循环模型来学习整个“学习算法”。虽然这使他们能够通过RNN的单次前向传播快速适应,但与从头开始学习相比,这限制了他们的渐近性能,因为学习的“算法”(即RNN)通常不符合收敛的迭代优化过程,并且不能保证不断改进。
基于梯度下降的元学习器,如模型不可知元学习(MAML)[6],直接训练可以快速适应新任务的梯度下降的模型参数。这些方法的优点是允许类似于从头开始学习的渐进性能,因为自适应是使用梯度下降来执行的,同时还允许从元训练中加速。然而,我们的实验表明,由于探索决策缺乏结构化随机性,单独的MAML在学习探索方面不是很有效。
我们的目标是通过设计一种元RL算法来应对这些挑战,该算法通过遵循策略梯度来适应新任务,同时将学到的结构化随机性注入潜在空间,以实现有效的探索。我们的算法,我们称之为具有结构化噪声的模型不可知探索(MAESN),使用先验经验来初始化策略,并学习潜在的探索空间,从中可以对时间上连贯的结构化行为进行采样。这产生了随机的、基于先验知识的、比随机噪声更有效的探索决策。重要的是,策略和潜在空间被明确训练,以快速适应具有策略梯度的新任务。由于自适应是通过遵循策略梯度来执行的,因此我们的方法至少实现了与从头开始学习相同的渐近性能(并且通常表现得更好),而结构化随机性允许随机但有任务意识的探索。在先前的工作[9, 7, 13]中已经探索了潜在空间模型,尽管没有在元学习或学习探索决策的背景下。这些方法没有明确训练快速适应,第4节中的比较说明了我们方法的优势。
我们的实验评估表明,现有的元RL方法,包括MAML[6]和基于RNN的算法[5, 30],在获取复杂探索性策略的能力方面受到限制,这可能是由于它们获取策略参数化的随机结构化策略的能力受到限制,这些策略参数化只能将时间不变的随机性引入动作空间。虽然原则上某些基于RNN的架构可以捕获时间相关的随机性,但我们通过实验发现,目前的方法还不够。有效的探索决策必须从潜在有用的行为中随机选择,同时避免极不可能成功的行为。MAESN利用这一见解,通过将学到的时间相关噪声纳入其元学习潜在空间,并明确训练策略参数和潜在探索空间,以快速适应,从而获得更好的探索决策。在我们的实验中,我们发现我们能够连贯地探索,并快速适应许多具有挑战性探索组件的模拟操纵和移动任务。
元学习探索中出现的一个自然问题是:如果我们的目标是学习探索决策,以稀疏或延迟的奖励解决具有挑战性的任务,那么我们如何在元训练时解决多样化和具有挑战性任务,从而从一开始就获得这些策略?我们可以使用MAESN的一种方法是使用密集或塑造的奖励任务来元学习探索决策,这些策略适用于稀疏或延迟的奖励任务。在这种设置中,我们假设元训练任务具有良好的奖励(例如,到目标的距离),而在元测试时间看到的更具挑战性的任务将具有稀疏的奖励(如,距离目标很小的指标)。正如我们将在第4节中看到的那样,这使得MAESN能够在元测试时比以前的方法更好地解决具有挑战性的任务,因为现有的元RL方法不能仅从稀疏的奖励中有效地进行元学习。
2 Preliminaries: Meta-Reinforcement Learning
在meta-RL中,我们考虑任务上的分布τi ~ p(τ),其中每个任务τi是不同的马尔可夫决策过程(MDP)Mi = (S, A, Pi, Ri),具有状态空间S、动作空间A、转换分布Pi和奖励函数Ri。奖励函数和转换因任务而异。Meta-RL旨在学习一种策略,该策略可以尽可能有效地适应p(τ)对新任务的期望回报最大化。
我们建立在基于梯度的元学习框架MAML[6]的基础上,该框架以一种可以快速适应标准梯度下降的方式训练模型,标准梯度下降在RL中对应于策略梯度。MAML的元训练目标可以写成
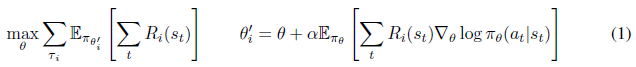
这个优化目标背后的直觉是,由于策略将在元测试时使用策略梯度进行调整,我们可以优化策略参数,以便策略梯度的一步尽可能提高其在任何元训练任务上的性能。
由于MAML在面临分布外任务时恢复到传统的策略梯度,它为我们考虑元探索算法的设计提供了一个自然的起点:通过从一种基本上与任务无关的RL方法相同的方法开始,在最坏的情况下从头开始学习,我们可以对其进行改进,以结合从经验中获取随机探索决策的能力,同时保持渐近性能。
3 Model Agnostic Exploration with Structured Noise
虽然元学习已被证明对几个RL问题的快速适应是有效的[6, 5],但现有的方法通常侧重于探索不重要且一些随机试验足以确定目标的任务[6],或者策略应该获得一致的“搜索”对策,例如在新的迷宫中找到出口[5]。这两种适应机制都与随机探索有很大不同。正如我们的实验所证明的那样,需要随机结构化探索来发现目标的任务不容易被这种方法捕获。具体来说,这些方法有两个主要缺点:(1)策略的随机性仅限于来自动作分布的时不变噪声,这从根本上限制了它所能代表的探索行为。(2)对于基于RNN的方法,策略适应新环境的能力是有限的,因为适应是通过循环网络的前向传递来执行的。如果这一次前向传播没有产生良好的表现,就没有进一步的改进机制。通过梯度下降进行调整的方法,如MAML,只需恢复到标准策略梯度,在最坏的情况下可以进行缓慢但稳定的改进,但没有解决(1)。在本节中,我们介绍了一种基于梯度元学习的结构化探索行为学习新方法,该方法能够学习良好的探索行为,并快速适应需要大量探索的新任务,而不会影响渐进性能。
3.1 Overview
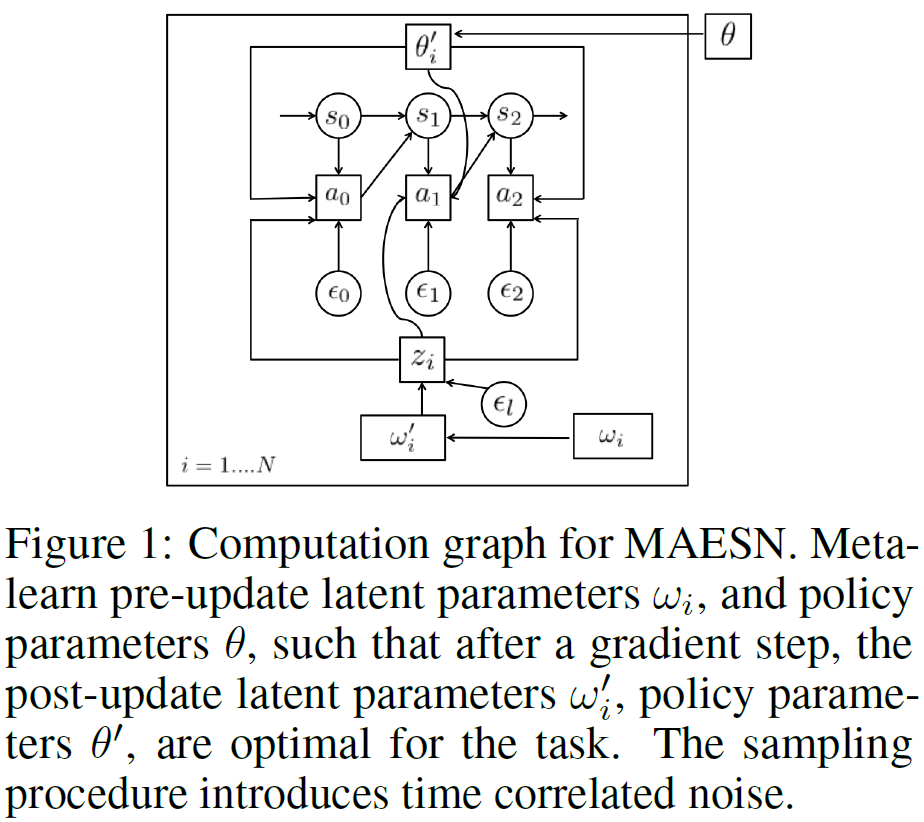
我们的算法,我们称之为结构噪声的模型不可知探索(MAESN),将结构随机性与MAML相结合。MAESN是一种基于梯度的元学习算法,它不仅通过干扰动作,还通过学到的潜在空间引入随机性,从而使探索与时间相关。策略和潜在空间都使用元学习进行训练,以明确提供对新任务的快速适应。当在元测试时间解决新任务时,每个事件都会从这个潜在空间生成不同的样本(并在整个事件中保持固定),提供结构化和时间相关的随机性。由于元训练,通过策略梯度更新,潜在变量的分布可以快速适应任务。我们首先展示了如何通过潜在空间引入结构化随机性,然后描述了如何对策略和潜在空间进行元训练,以形成我们的整体算法。
3.2 Policies with Latent State
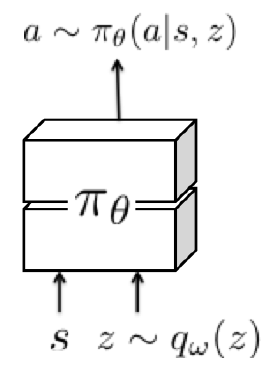
典型的随机策略以独立于每个时间步骤的方式参数化动作分布πθ(a|s)。这种表示在整个轨迹中没有时间相关随机性的概念,因为随机性在每一步都是独立添加的。在这种表示下,对于每个时间步骤独立地对加性噪声进行采样。这限制了可能的探索决策的范围,因为策略在每个时间步骤都会“改变主意”。分布πθ(a|s)通常也用简单的参数族表示,例如单峰高斯分布,这限制了它的表现力。为了结合时间相关探索,并允许策略对更复杂的时间相关随机过程进行建模,我们可以根据从学到的潜在分布中提取的每回合随机变量来调整策略,如下图所示。由于这些潜在变量每回合只采样一次,因此它们提供了时间上一致的随机性。凭直觉,该策略只决定在每一回合中尝试做什么一次,并承诺执行该计划。由于提供随机样本作为输入,非线性神经网络策略可以将该样本转换为任意复杂的分布。生成的策略可以写成πθ(a|s, z),其中z ~ qw(z),并且qw(z)是带参数w的潜在变量分布。例如,在我们的实验中,我们考虑形式为qw(z) = N(μ, σ),使得w = {μ, σ}。这种形式的结构化随机性可以通过对整个行为或目标进行采样来提供更连贯的探索,而不是简单地依赖于独立的随机行为。
我们讨论了如何元学习潜在表征并快速适应新任务。在先前的工作[9, 7]中已经探索了相关的表示,但简单地将随机变量输入到策略中本身并不能快速适应新任务。为了实现快速适应,我们可以结合元学习,如下所述。
3.3 Meta-Learning Latent Variable Policies
给定如上所述的潜在可变条件策略,我们的目标是对其进行训练,以便从一系列训练任务中获取连贯的探索决策,从而能够快速适应来自类似分布的新任务。我们使用变分推理和基于梯度的元学习相结合的方法来实现这一点。具体而言,我们的目标是对策略参数θ进行元训练,使其能够利用潜在变量对新任务进行连贯的探索,并尽快适应行为。为此,我们共同学习一组策略参数和一组潜在空间分布参数,以便它们在策略梯度自适应步骤后为每个任务实现最佳性能。这一程序鼓励策略实际利用潜在变量进行探索。从一个角度来看,MAESN可以被理解为用潜在空间来增强MAML以注入结构化噪声。从不同的角度来看,这相当于学习一个结构化的潜在空间,类似于[9],但经过训练可以快速适应新任务。[6]可以快速适应简单的任务,[9]可以学习结构化的潜在空间,MAESN可以实现结构化的探索和快速适应。如我们的实验所示,现有的两种方法都不能有效地学习复杂且随机的探索决策。
为了形式化元训练的目标,我们引入了一个模型参数化,其中策略参数θ在所有任务中共享,每个任务的变分参数wi,用于任务i=1, 2, ... , N, 其参数化每个任务的潜在分布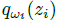 。我们用θ, wi指代更新前参数。元训练涉及优化一组训练任务的更新前参数,以便在策略梯度更新后最大化期望奖励。作为变分推理的标准,我们还将每个任务的更新前分布和先验p(z)的KL散度加入了目标,先验在我们的实验中只是一个单位高斯分布。如果没有这个额外损失,每个任务的参数wi可以简单地记住特定任务的信息。KL损失确保在元测试时间为新任务采样z ~ p(z)仍然产生有效的结构化探索。
。我们用θ, wi指代更新前参数。元训练涉及优化一组训练任务的更新前参数,以便在策略梯度更新后最大化期望奖励。作为变分推理的标准,我们还将每个任务的更新前分布和先验p(z)的KL散度加入了目标,先验在我们的实验中只是一个单位高斯分布。如果没有这个额外损失,每个任务的参数wi可以简单地记住特定任务的信息。KL损失确保在元测试时间为新任务采样z ~ p(z)仍然产生有效的结构化探索。
对于元训练的每次迭代,我们从更新前参数θ, wi表示的潜在变量条件策略中采样,对每个任务的变分参数(以及可选的策略参数)执行“内部”梯度更新,以获得任务特定的更新后参数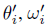 ,然后通过该更新传播梯度以获得θ, w0, w1, ... , wN的元梯度,使得用更新后潜在条件策略的所有任务的期望任务奖励总和最大化,而更新前分布相对于先验p(zi)的KL散度被最小化。注意,KL散度损失应用于更新前分布
,然后通过该更新传播梯度以获得θ, w0, w1, ... , wN的元梯度,使得用更新后潜在条件策略的所有任务的期望任务奖励总和最大化,而更新前分布相对于先验p(zi)的KL散度被最小化。注意,KL散度损失应用于更新前分布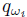 ,而不是更新后分布,因此在内部更新后,策略可以在每个任务上表现出非常不同的行为。计算更新后参数下的奖励梯度需要通过内部策略梯度项进行差分,如MAML[6]中所述。
,而不是更新后分布,因此在内部更新后,策略可以在每个任务上表现出非常不同的行为。计算更新后参数下的奖励梯度需要通过内部策略梯度项进行差分,如MAML[6]中所述。
算法1中提供了元训练过程的简要描述,表示MAESN的计算图如图1所示。完整的元训练问题可以在数学上表述为
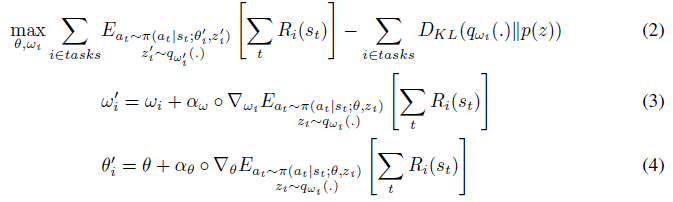
这两个目标项是每个任务在更新后参数下的期望回报,以及每个任务的更新前潜在分布与先验之间的KL散度。这些α值是每个参数的步长,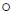 是一个元素乘积。最后一次更新(到θ)是可选的。我们发现,事实上,我们可以通过省略此更新来获得更好的结果,这对应于简单地对初始策略参数θ进行元训练以有效地使用潜在空间,而无需明确训练参数本身以进行快速自适应。包括更新使由此产生的优化问题更具挑战性。
是一个元素乘积。最后一次更新(到θ)是可选的。我们发现,事实上,我们可以通过省略此更新来获得更好的结果,这对应于简单地对初始策略参数θ进行元训练以有效地使用潜在空间,而无需明确训练参数本身以进行快速自适应。包括更新使由此产生的优化问题更具挑战性。
MAESN通过使用潜在变量z实现结构化探索,同时通过策略梯度明确训练快速适应。原则上,我们可以在根本不进行元训练的情况下训练这样的模型进行自适应,这类似于[9]提出的模型。然而,正如我们将在实验评估中显示的那样,元训练产生了更好的结果。
有趣的是,在元训练过程中,我们发现对于每个任务,更新前变分参数wi通常在收敛时都接近于先验。这有一个简单的解释:元训练优化更新后奖励,此时wi已更新为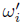 ,所以即使wi匹配先验,它不匹配内部更新后的先验。这允许学到的策略在元测试时成功执行新任务,因为我们没有很好的初始化w,别无选择,只能从先验开始,如下一节所述。
,所以即使wi匹配先验,它不匹配内部更新后的先验。这允许学到的策略在元测试时成功执行新任务,因为我们没有很好的初始化w,别无选择,只能从先验开始,如下一节所述。

3.4 Using the Latent Space for Exploration
令我们考虑一个具有奖励Ri的新任务τi,以及一个学到的具有策略参数θ的模型。变分参数wi特定于元训练中使用的任务,对新任务没有用处。然而,由于KL散度损失(公式3)促使更新前参数接近先验,所有变分参数wi在收敛时趋向先验(图5a)。因此,对于新任务中的探索,我们可以将潜在分布初始化为先验,即qw(z) = p(z)。在我们的实验中,我们使用μ = 0和σ = I的先验。然后,适应新任务通过简单地使用策略梯度通过RL目标上的反向传播来调整w,![]() ,其中R表示沿着轨迹的奖励总和。自从我们在内循环中元训练适应w,我们也在元测试时调整这些参数。要计算关于w的梯度,我们需要通过采样操作z ~ qw(z)进行反向传播,使用似然比或重参数化技巧(如果可能的话)。似然比更新为
,其中R表示沿着轨迹的奖励总和。自从我们在内循环中元训练适应w,我们也在元测试时调整这些参数。要计算关于w的梯度,我们需要通过采样操作z ~ qw(z)进行反向传播,使用似然比或重参数化技巧(如果可能的话)。似然比更新为

由于元训练,这种自适应方案具有在新任务上快速学习的优点,同时由于我们简单地使用策略梯度,保持了良好的渐近性能。
4 Experiments
我们的实验旨在比较评估我们的元学习方法,并研究以下问题:(1)使用MAESN的元学习探索决策是否能够连贯地探索并快速适应新任务,与从头开始学习相比具有显著优势?(2)MAESN的元学习与之前的元学习方法(如MAML[6]和RL2[5])以及潜在空间学习方法[9]相比如何?(3)我们能否将探索行为可视化,并通过MAESN看到连贯的探索决策?(4)我们能更好地了解MAESN的哪些组成部分是最关键的吗?我们所有实验的视频和实验细节可以在https://sites.google.com/view/meta-explore/。
4.1 Experimental Details
在元训练期间,“内部”更新对应于标准REINFORCE,而元优化器是信任区域策略优化(TRPO)[24]。补充材料中提到了每种算法的超参数,这些材料是通过超参数扫描选择的(也在附录中详细说明)。所有实验最初都在本地2 GPU机器上运行,并使用亚马逊网络服务大规模运行。虽然我们的目标是在元测试时快速适应稀疏和延迟的奖励,但这在元训练时提出了一个重大挑战:如果任务本身太难从头开始学习,那么在元训练时间也很难解决,这使得元学习者很难取得进步。事实上,我们评估的方法,包括MAESN,都无法在元训练时在稀疏奖励任务上取得任何学习进展(参见补充材料图2中的元训练进展)。
虽然这个问题可以通过在元训练期间使用更多的样本或现有的任务不可知的探索决策来解决,但我们的方法允许更简单的解决方案。如第1节所述,我们可以在元训练期间使用塑造奖励(对于我们的方法和基准),而只有稀疏奖励用于在元测试时进行调整。如下所示,尽管奖励函数不匹配,但通过奖励塑造进行MAESN元训练的探索决策有效地推广到稀疏和延迟奖励。
4.2 Task Setup
我们在三个任务分布p(τ)上评估了我们的方法。对于每个任务家族,我们使用了100个不同的元训练任务,每个任务都有不同的奖励函数Ri。在对特定任务分布进行元训练后,MAESN能够很好地探索并快速适应从该分布中提取的任务(具有稀疏奖励)。环境的输入状态不包含目标——相反,智能体必须探索不同的位置,以通过探索定位目标。元训练和测试奖励功能的详细信息可以在补充材料中找到。
Robotic Manipulation. 这些任务的目标是用机械手将积木推到目标位置。每个任务只有一个块(智能体未知)相关,并且该块必须移动到目标位置(见图2a)。块的位置和目标是在任务之间随机化的。连贯的探索决策应该选择随机的区块移动到目标位置,在每一回合中尝试不同的区块来发现正确的区块。这项任务通常代表了机器人操作中的探索挑战:虽然机器人可能会执行各种不同的操作技能,但只有与世界上物体实际交互的动作才有助于连贯的探索。
Wheeled Locomotion. 我们考虑一个轮式机器人,它独立地控制它的两个轮子移动到不同的目标位置。任务族如图2b所示。对这一系列任务进行连贯的探索需要开车前往世界上的随机地点,这需要一种协调的行动模式,而纯粹用动作空间噪音很难实现。
Legged Locomotion. 为了了解我们是否可以扩展到更复杂的运动任务,我们考虑了一只四足动物(“蚂蚁”),其任务是步行到随机放置的目标(见图2c)。这项任务提出了进一步的探索挑战,因为只有精心协调的腿部运动才能产生到不同位置的运动,因此理想的探索决策总是步行,但要到不同的地方。
4.3 Comparisons
我们将MAESN与RL2[5]、MAML[6]进行比较,简单地学习潜在空间而不进行快速适应(LatentSpace),类似于[9]。对于从头开始的训练,我们将其与TRPO[24]、REINFORCE[31]进行比较,并将其与通用探索算法VIME[11]进行比较。更多细节可在补充材料中找到。
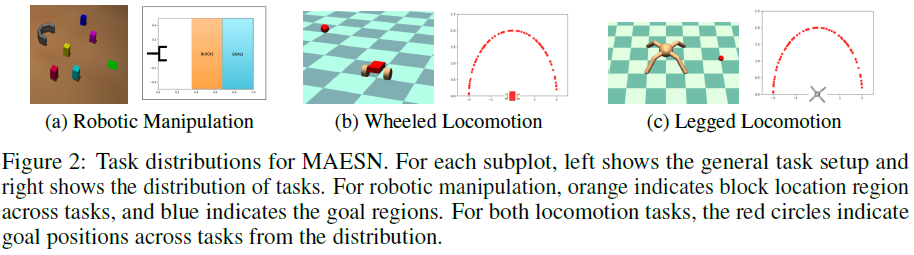
在图3中,我们报告了在元测试时使用稀疏奖励适应新任务时,我们的方法和先前方法的结果。我们绘制了所有方法在适应从任务测试集中提取的任务时获得的奖励(在30个验证任务中平均)的性能图。我们对上面讨论的任务的结果表明,MAESN能够在稀疏奖励环境中快速探索和适应。相比之下,MAML和RL2不能有效地学习探索行为。纯潜在空间模型(图3中的潜在空间)实现了合理的性能,但在潜在空间参数的初始识别之外,其改进能力有限,并且没有针对潜在空间中的快速适应进行优化。由于MAESN可以明确地训练潜在空间进行快速适应,因此它可以更快地获得更好的结果。
我们还观察到,对于许多任务,从零开始学习实际上在渐进性能方面为以前的元学习方法提供了一个有竞争力的基准。这表明任务分布非常具有挑战性,简单地记忆元训练任务不足以成功。然而,在所有情况下,我们都看到MAESN在学习速度和渐进性能方面都优于从头开始学习和任务不可知探索。
在具有挑战性的腿部运动任务中,我们发现只有MAESN能够有效地适应,该任务需要连贯的步行行为到世界上的随机位置来发现稀疏的奖励。

4.4 Exploration Strategies
为了理解MAESN学习的探索决策,我们可视化了通过从具有潜在分布qw(z)(设置为先验N(0, I))的元学习潜在条件策略πθ中采样获得的轨迹。所得轨迹示出了推块任务的手的2D位置和移动任务的质心的2D位置。每个任务族的任务分布如图2a、2b、2c所示。我们可以从这些轨迹中看到(图4),学到的探索决策在连贯行为的空间中进行了广泛且有效的探索,特别是与随机探索和标准MAML相比。
4.5 Analysis of Structured Latent Space
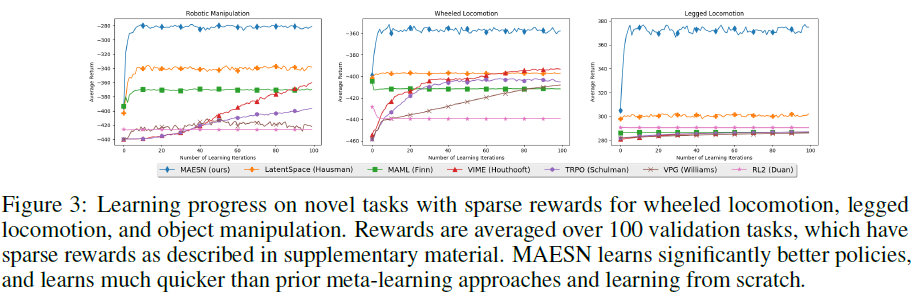
我们通过可视化2D潜在空间的预更新wi = (μi, σi)和后更新![]() 参数来研究操纵任务中学到的潜在空间的结构。变分分布被绘制为椭圆。从图5a可以看出,更新前的参数都趋向先验N(0, I),而更新后的参数移动到潜在空间中的不同位置以适应它们各自的任务。这表明元训练过程有效地利用了潜在变量,但也最大限度地减少了与先验的KL散度,确保了初始化w对先验的一项新任务将产生有效的探索。
参数来研究操纵任务中学到的潜在空间的结构。变分分布被绘制为椭圆。从图5a可以看出,更新前的参数都趋向先验N(0, I),而更新后的参数移动到潜在空间中的不同位置以适应它们各自的任务。这表明元训练过程有效地利用了潜在变量,但也最大限度地减少了与先验的KL散度,确保了初始化w对先验的一项新任务将产生有效的探索。
我们还评估了从MAESN学到的潜在空间注入的噪声是否真的用于探索。与从学习的潜在分布中采样时相比,当潜在变量z保持固定时,我们观察到用MAESN训练的策略所显示的探索行为。我们可以从图5b中看到,尽管即使没有潜在空间采样也存在一些随机探索,但当从先验中采样z时,轨迹的范围要宽得多。
5 Conclusion
我们提出了MAESN,这是一种元RL算法,通过将基于梯度的元学习与学到的潜在探索空间相结合,明确地学习探索。MAESN学习了一个潜在空间,该空间可用于将时间相关、相干的随机性注入到策略中,以在元测试时进行有效探索。一个好的探索决策必须从有用的行为中随机采样,同时忽略从不有用的行为。我们的实验评估表明,MAESN正是做到了这一点,优于先前的元学习方法和从头开始学习,包括使用任务不可知探索决策的方法。然而,值得注意的是,我们的方法与这些方法并不互斥,事实上,未来工作的一个有希望的方向是将我们的方法和这些方法结合起来[11]。

1 Experimental Details
我们所有的实现都建立在rllab(Duan et al., 2016)和MAML(Finn et al., 2017a)的开源实现之上。我们的策略都是2层的前馈策略,每个层有100个单元,并且具有ReLU非线性。我们为适应的单个步骤进行了元训练,尽管原则上可以进行更长的时间。
我们发现,要使MAESN正常工作,元学习每个参数的步长是至关重要的,而不是保持步长不变。Li等人(2017)在先前的工作中也发现了这一点。
2 Reward Functions
在训练所有任务时,我们使用密集奖励函数来实现元训练,如论文第[4]节所述。对于每项任务,密集奖励由下式给出
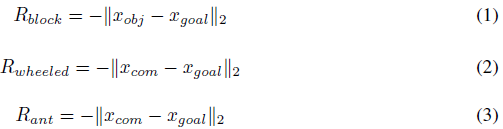
测试时间奖励更稀疏,仅在目标位置周围的区域中提供。这些任务的稀疏奖励由下式给出
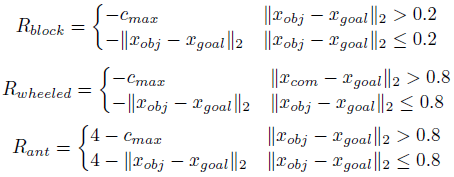
其中-cmax是一个无信息的大负常数奖励。奖励是无信息的,直到智能体/对象达到目标周围的阈值距离,然后到目标的负距离随后被提供作为奖励函数。
我们所有的实现都建立在rllab(Duan et al., 2016)和MAML(Finn et al., 2017a)的开源实现之上。我们的策略都是2层的前馈策略,每个层有100个单元,并且具有ReLU非线性。我们为适应的单个步骤进行了元训练,尽管原则上可以进行更长的时间。
我们发现,要使MAESN正常工作,元学习每个参数的步长是至关重要的,而不是保持步长不变。Li等人(2017)在先前的工作中也发现了这一点。
3 Hyperparameters
我们描述了基于梯度的元学习方法的超参数扫描。对于元训练,我们扫描了:
- MAESN、潜在空间基准和MAML中每个任务的轨迹数:[20, 50]
- MAESN中潜在参数大小,潜在空间基准:[2, 4, 8]
- MAML中的偏移变换大小:[2, 4, 8]
- MAESN中的kl权重:[0.1, 0.5],潜在空间基准中的kl权重:[0001, 0.01, 0.05]
- MAESN和MAML中的内部学习率:[0.5, 1]
对于每种方法,我们都选择了具有最优训练时间性能的超参数,然后进行元测试。元训练和元测试都是用多个种子运行的。
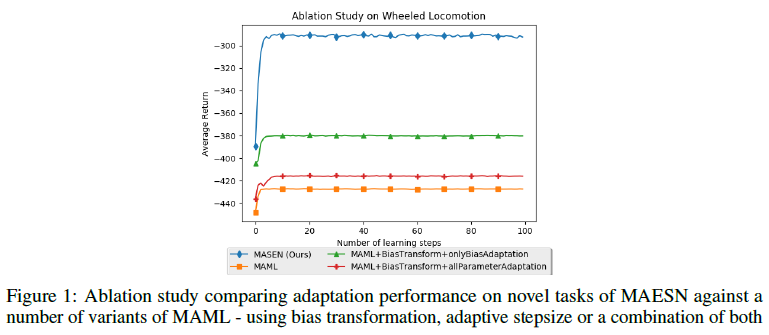
4 Ablation Study
由于MAESN引入了许多组件,如自适应步长,这是MAML框架中一个潜在的探索空间,我们进行消融,看看其中哪一个会产生重大影响。Finn等人(2017b)以前曾探索过添加学到的潜在空间(称为偏差变换),但潜在空间不是随机的,因此对探索没有帮助。
我们发现,尽管在MAML中添加偏差转换是有帮助的,但它与MAESN的性能不匹配。所考虑的变体是(1)标准MAML(2)MAML+偏置变换+自适应步长,适应内部更新中的所有参数(maml+Bias+allParameterAdaptation)(3)MAML+偏置变换+适应性步长,只适应内部更新的偏差参数(maml+Bias+onlyBiasAdaptation)。
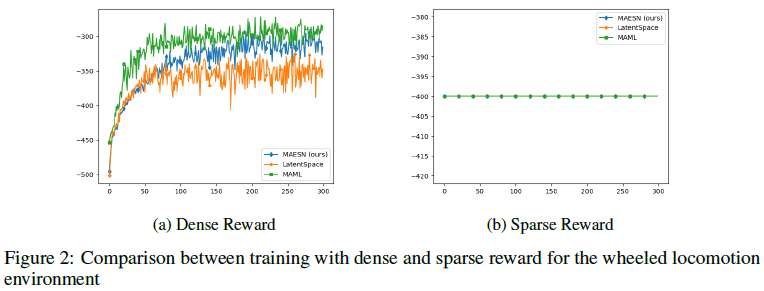
5 Meta-Training Performance
在具有稀疏奖励的元训练中,从轮式运动环境中的更新后奖励曲线可以看出,没有一种方法学会做任何事情。在具有密集奖励的元训练中,MAML和MAESN都实现了相当好的更新后奖励,如以下曲线所示。然而,从下一节中学习的探索方案中可以看出,MAESN学习了探索,而MAML没有,这使得MAESN能够更好地转移到新的稀疏奖励任务中。
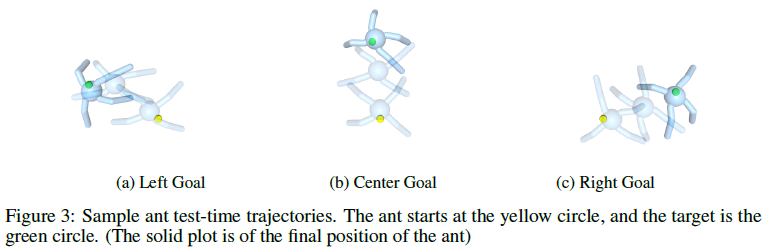
6 MAESN Test-Time Trajectories
在测试时,MAESN不仅在稀疏奖励任务上获得了很高的奖励,而且完全解决了这些问题。以下是在代表总体任务分布的几个目标上测试智能体时的轨迹。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号