Continuous improvement of self-driving cars using dynamic confidence-aware reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Nature Machine Intelligence, 2023, 5(2): 145-158
Abstract
今天的自动驾驶汽车已经取得了令人印象深刻的驾驶能力,但在长尾情况下仍存在不确定性。用更多的数据训练基于强化学习的自动驾驶算法并不总能带来更好的性能,这是一个安全问题。在此,我们提出了一种动态置信强化学习(DCARL)技术,以保证持续改进。持续改进意味着更多的训练始终会提高或保持其当前的性能。我们的技术能够使用驾驶过程中收集的数据提高性能,而不需要长时间的预训练阶段。我们使用模拟和在实验车辆上评估了所提出的技术。结果表明,所提出的DCARL方法能够在各种情况下实现持续改进,同时,在任何阶段都匹配或优于默认的自动驾驶策略。这项技术在2022年北京冬奥会上在车辆上进行了演示和评估。
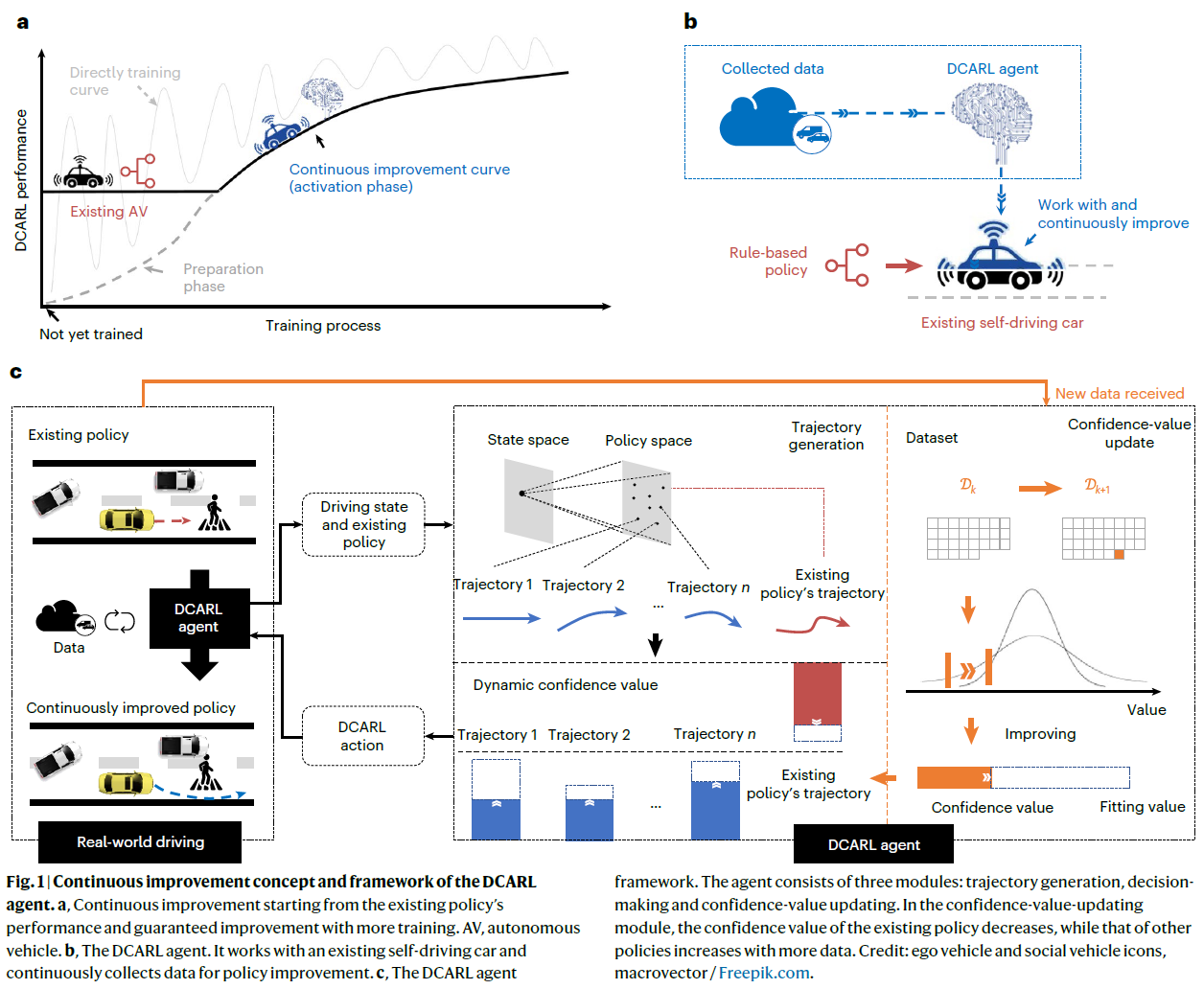
自动驾驶汽车正在世界许多地方部署。然而,它们在“长尾”案件中的表现仍然令人担忧。许多数据驱动方法,如强化学习(RL),提供了一种从收集的数据中学习并不断更新驾驶策略的潜在方法1。RL已经在几个应用领域证明了其价值,例如国际象棋、Go2,3和视频游戏4。最近的一些研究已经开始在特定场景中训练基于RL的自动驾驶策略5-8。然而,很少有汽车公司准备在其生产车辆上部署这项技术9。两个主要问题是:数据驱动的智能体通常需要很长的训练时间,而且训练后的性能无法保证10;并且对于先前不可见的场景,经过训练的智能体可能不会胜过现有的规则或基于模型的策略11。在提高训练性能12和训练效率13、增加外部安全防护装置14,15以及为训练收集更多数据16方面进行了许多努力,但在全面的训练数据集出现之前,没有一项工作从根本上解决了“长尾情况下的不确定性能”这一关键问题。
在这篇文章中,我们呼吁进行范式转换,以训练RL智能体,该智能体可以在任何训练阶段应用,并具有保证的下限性能,并且其性能保证从具有更多数据的下限持续改进(图1a)。下限性能来自默认的自动驾驶算法,该算法可处理大多数驾驶情况,但对于剩余的长尾情况,应进一步改进17-19。该技术直接与给定的自动驾驶算法一起工作,并在驾驶过程中不断接收数据以进行改进(图1b)。我们将所提出的技术称为动态置信强化学习(DCARL)智能体,框架如图1c所示。在此框架中,最重要的模块是训练策略的动态置信值,该值随着数据的增加而单调增加。动态置信值不仅基于预期性能,而且基于实现该性能的置信度来计算。DCARL智能体具有以下四个关键特征,可以解决前面提到的问题。
(1) 不需要长时间的预训练。我们的DCARL智能体可以直接与大多数现有的自动驾驶算法一起工作,这些算法具有与基准相同的状态和动作空间。对于非RL策略,需要转换器来对齐状态和动作空间。当训练不足时,智能体可以使用原始驾驶策略(参见图1a中的“尚未训练”一点)。
(2) 通过更多训练数据实现的改进保证。我们的DCARL智能体可以在可接受的真实世界不确定性(包括固定反馈误差或标准噪声分布)下使用更多训练数据持续改进(参见图1a中的持续改进曲线)。
(3) 基于现有自动驾驶算法的性能保证。许多现有的自动驾驶汽车可以在许多情况下安全驾驶,但当新收集的数据用于进一步训练时,性能并不总是会提高20。当我们将DCARL智能体与这些现有的自动驾驶算法相结合时,现有的驾驶策略保证了基准性能(参见图1a中的准备阶段)。
(4) 最终是一个纯数据驱动的自动驾驶算法。通过更多的训练,我们的智能体在更多情况下获得比原始策略更好的性能,并可能最终接管大多数场景,成为完全数据驱动的策略。
文献中的经典RL框架也考虑了安全性,旨在提高性能,但在实践中,更多的训练并不总是带来更好或更安全的性能。此外,假设和安全定义可能不针对持续改进现有自动驾驶汽车所提出的要求。例如,安全策略改进21旨在避免风险的策略更新,但需要大量数据。离线RL22可以基于有限的数据集训练智能体,但可能没有性能下限。在安全RL研究23中,一个广泛使用的思想是解决约束马尔可夫决策过程问题,以使每个更新的策略满足给定的约束24。这些方法通常需要每个策略违反约束的概率,但数据不足或模型不准确25,26可能会导致较大误差,可能导致这些方法失败。引入专家或保障策略是安全的另一个想法。例如,学徒学习27,28和DAgger29旨在训练策略以接近专家策略。当策略与专家非常不同时,安全DAgger30和选择性DAgger31将直接调用专家策略。这些方法旨在模仿专家策略,但我们的智能体可以甚至被鼓励偏离基准。Shield-RL32和法律安全策略14可使用手动设计的原则来判断当前策略是否安全,并在必要时要求保障策略,但这些原则可能并不总是与实际驾驶条件相匹配。
我们持续改进的主要概念是估计动态置信值,以表示策略的预期性能以及实现该性能的信心。它可以在训练数据不足的情况下更好地适应驾驶环境的不确定性。这种想法的灵感来源于这样一种现象,即由于观察到的模型的置信度提高,在收集数据时,可以减少驾驶过程中的认知不确定性33。此外,最近的一些研究似乎表明,人类的学习过程与学习成绩和自信心的提高有关34。我们之前的工作20建议使用固定的最差驾驶性能作为置信值。我们基于这一想法,进一步探索动态更新的置信值,以便使用更多数据和真实车辆应用程序进行持续改进。置信值表示预期性能是否能够反映其实际驾驶性能,考虑到特定情况下更新的驾驶体验的差异和重复次数。策略的最差置信值(WCV)定义如下:
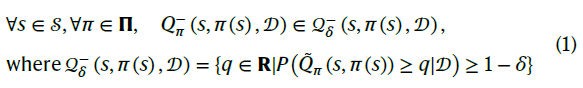
其中![]() 表示当策略π用于给定状态
表示当策略π用于给定状态![]() 时的WCV。∏是包含候选策略的集合。
时的WCV。∏是包含候选策略的集合。![]() 表示策略π(s)下的理想价值,即策略的实际期望累积奖励。该值仅存在于概念中,未直接观察到。P表示概率,q属于实数域R。
表示策略π(s)下的理想价值,即策略的实际期望累积奖励。该值仅存在于概念中,未直接观察到。P表示概率,q属于实数域R。![]() 表示数据集并且
表示数据集并且![]() ,其分别表示在时间tk和tk+1处接收的数据集。δ ∈ (0,1)确定所需的策略置信度。较低的δ值导致更严格的置信要求,但也可能需要更多的数据进行训练。公式(1)表示实际值大于WCV的概率高于1−δ。
,其分别表示在时间tk和tk+1处接收的数据集。δ ∈ (0,1)确定所需的策略置信度。较低的δ值导致更严格的置信要求,但也可能需要更多的数据进行训练。公式(1)表示实际值大于WCV的概率高于1−δ。
新接收的数据用于动态更新WCV,以不断提高置信值,如图2b所示,所需属性如下:
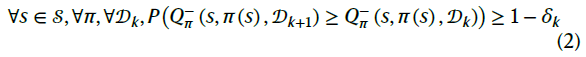
其中公式(2)表明,WCV用更多训练数据改进的可能性很高。
最后,DCARL引入了一个现有的驾驶策略作为原始策略和改进的性能基准,表示为π0。我们进一步计算了π0的最佳置信值(BCV)![]() 作为激活训练的RL策略的阈值。它遵循WCV的类似定义,但随着数据的增加,从非常大的值收敛到实际值。当数据不足时,大的BCV可以避免不合理地激活RL智能体。因此,在不同的训练阶段,DCARL不可能比原始策略差,如下所示:
作为激活训练的RL策略的阈值。它遵循WCV的类似定义,但随着数据的增加,从非常大的值收敛到实际值。当数据不足时,大的BCV可以避免不合理地激活RL智能体。因此,在不同的训练阶段,DCARL不可能比原始策略差,如下所示:
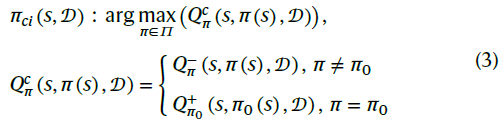
其中πci(s, 𝒟)表示用数据𝒟训练的DCARL策略。上标c表示置信值。
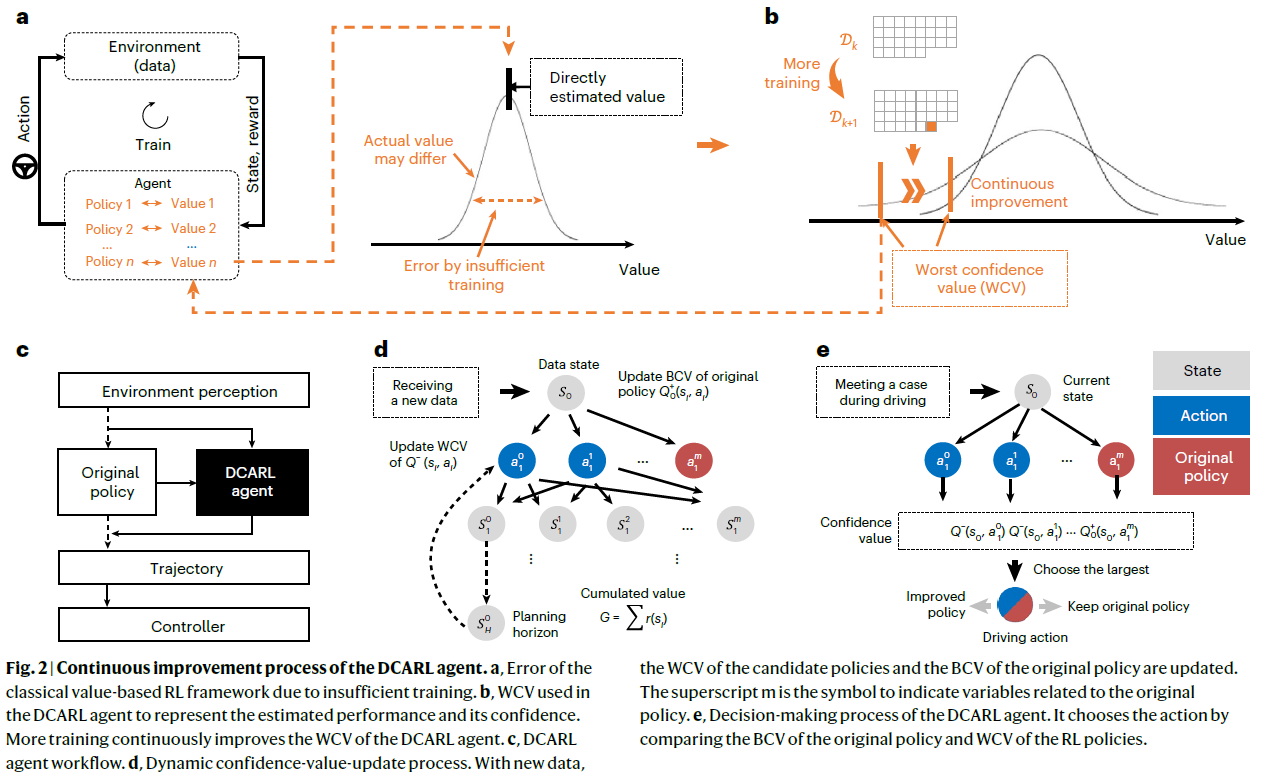
实现DCARL智能体的算法由三部分组成:(1)现有的自动驾驶算法,(2)通过新的训练数据更新的动态置信值,(3)决策模块。
(1) 现有的自动驾驶算法(如图2c所示)。DCARL智能体使用现有的自动驾驶算法作为原始策略和性能基准。它保持不变,但其置信值可能会随着训练的进行而改变,使用与RL训练过程相同的数据集。对于非RL基线策略,需要转换器将原始策略的输入编码为标准状态向量。此外,原始策略的置信值被初始化为正无穷大,而其他策略的值为负无穷大。
(2) 使用新的训练数据更新动态置信值(如图2d所示)。此模块的功能是估计候选策略的WCV和原始策略的BCV,包括两个步骤。首先,它使用具有重要采样率的蒙特卡洛原理来估计所收集轨迹的最大似然值(MLV)。然后,它估计MLV和实际值之间的最大可能误差。训练数据不足导致的误差可以通过Lindeberg–Lévy定理和自举原理来估计。也就是说,随着训练数据的增加,训练方差减小,MLV与实际值之间的误差较低。随着训练数据的增加,WCV单调增加,而原始策略的BCV不断减少。
(3) 决策模块(如图2e所示)。当遇到新的驾驶案例时,DCARL智能体选择具有最大置信值的候选驾驶轨迹。在训练开始时,使用原始策略,因为它是用大的置信值初始化的。然后,其他策略的置信度继续增加,最终其中一些策略变得高于原始策略。这一时刻被称为激活时间。之后,智能体偏离了最初的策略。达到激活水平通常需要智能体反复良好的性能,以避免由于只有少数偶尔良好的性能而导致错误激活。
上述提出的技术主要针对周围环境下的驾驶策略生成。这项工作假设感知模块用于检测和跟踪周围物体35,控制模块用于跟踪期望的轨迹36。车辆配置、算法和相关源代码是用于复现本工作的开源软件,可在https://github.com/zhcao92/DCARL中获取(参考37)。在下文中,我们主要评估DCARL的四个提到的特征。
Results
为了验证DCARL智能体的持续改进,我们设计了三个实验。在第一个实验中,继续通过模拟获得新的训练数据,并将其反馈给DCARL智能体和经典的基于价值的RL智能体,并记录其性能。然后,通过限制训练数据量,我们手动将一些测试用例设置为长尾(罕见)用例。最后,DCARL智能体被部署在开放道路上行驶的实验车辆上,并在2022年北京冬奥会上进行了演示和评估。这些结果可以通过补充软件呈现。
Continuously improved performance with increasing data
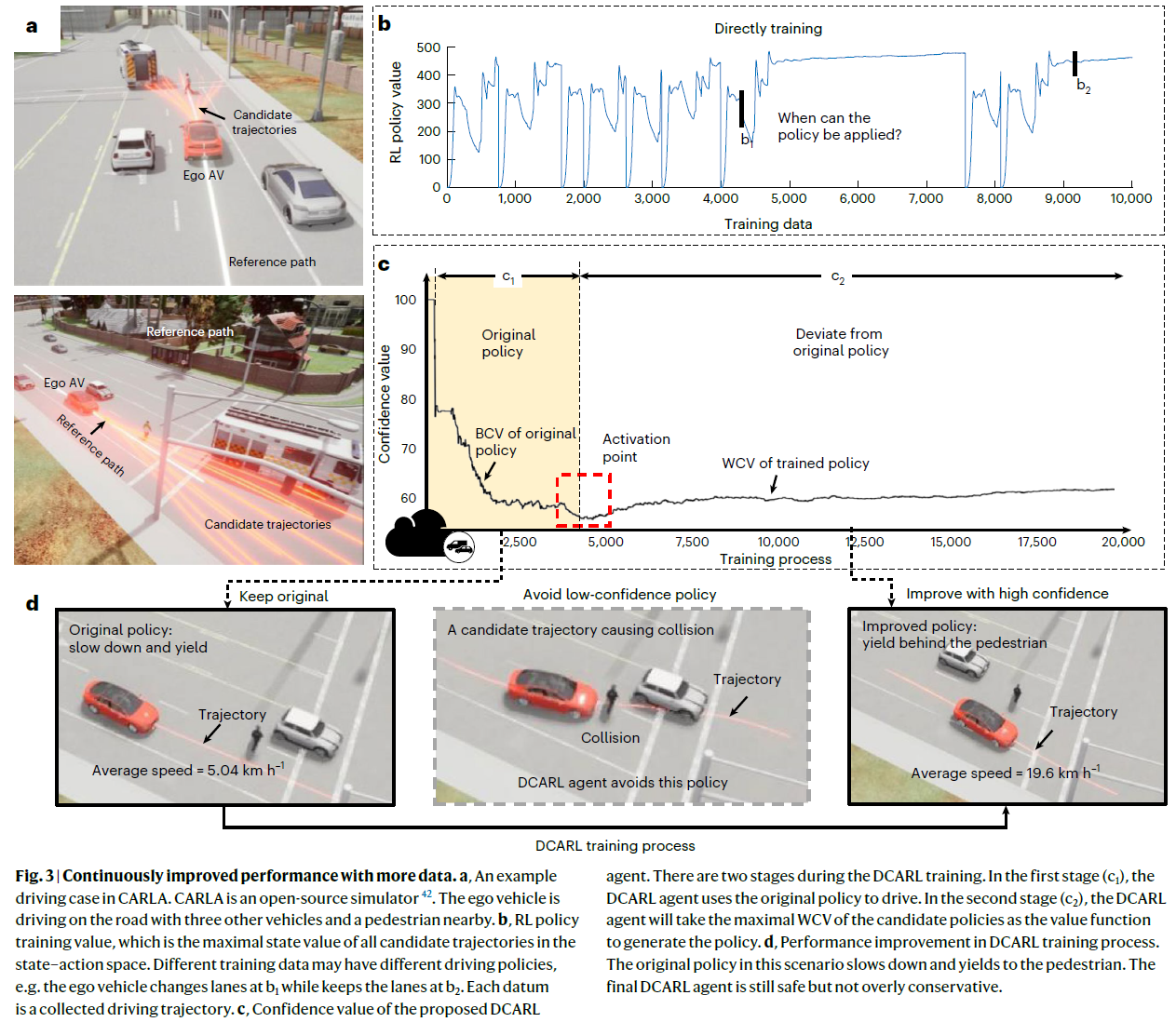
我们首先研究了DCARL智能体在不同数据量下的性能。驾驶场景如图3a所示。自主车辆与一些社会车辆一起在当地道路上行驶。一名行人也试图过马路。训练数据集包含该场景的各种轨迹及其之前的驾驶表现。为了进行比较,我们还使用基于经典值的RL框架来训练纯数据驱动的智能体,该智能体将候选轨迹映射到数据集中的预期性能,并选择具有最高值的轨迹。两个智能体的每个训练步骤都在收到数据后进行。
Classical RL agent driving performance. 图3b显示了使用广泛使用的深度Q学习框架的经典RL智能体的训练结果。它表明,性能改进不是单调的,并且行为非常不同,例如,b1变道,而b2不变道。该图说明了RL智能体训练和应用的一个关键问题:经过训练的策略不可靠,不可信。因此,在线学习和适应是有风险的,RL智能体不太可能在现实世界中部署用于任务关键型应用。
DCARL agent with continuous improvement. 图3c显示了随着训练数据的增加,所提出的DCARL智能体的性能。该过程包括两个阶段。在第一阶段(c1),BCV下降,但DCARL没有偏离基准策略。这种现象是因为BCV被设计为随着数据的增加从非常大的值收敛到实际值。当数据不足时,大的BCV可以避免不合理地激活RL智能体。在这种情况下,原始策略将保守地减速,以让行穿过行人,如图3d所示。
随着训练数据的增加,WCV继续增加,原始策略的BCV继续减少。当DCARL智能体有足够的信心相信RL智能体将优于原始策略时,它将进入第二阶段(c2),并使用经过训练的策略。在此阶段,WCV持续改进,性能保证与原始策略相同或更好。与最初的策略相比,训练有素的策略仍然是安全的,但将平均行驶速度从5 km/h提高到20 km/h。
这一结果表明了DCARL智能体的两个好处:它的性能保证与原始策略相同或更好,并且随着数据的增加,它会继续改进。
DCARL agent for long-tail cases
在现实驾驶中,自动驾驶车辆可能会遇到一些罕见的情况。这种长尾问题对自动驾驶技术的发展提出了严峻的挑战。所收集的数据集可能只有这些长尾案例的少量数据,这导致数据驱动智能体的安全问题。所提出的DCARL框架可以使用保守的原始策略14,该策略始终与所有目标保持长距离。对于正常驾驶而言,该策略可能过于保守,但DCARL智能体在任何驾驶情况下都可以依靠该策略来确保安全,尤其是在没有足够信心的情况下。随着数据的收集,DCARL可以不断改进,并在某些情况下偏离原始策略,以获得更高的效率和更高的可信度。通过这种方式,一些长尾情况可以逐渐转变为常见情况,但其他情况仍然可以使用原始的保守策略具有性能下限。
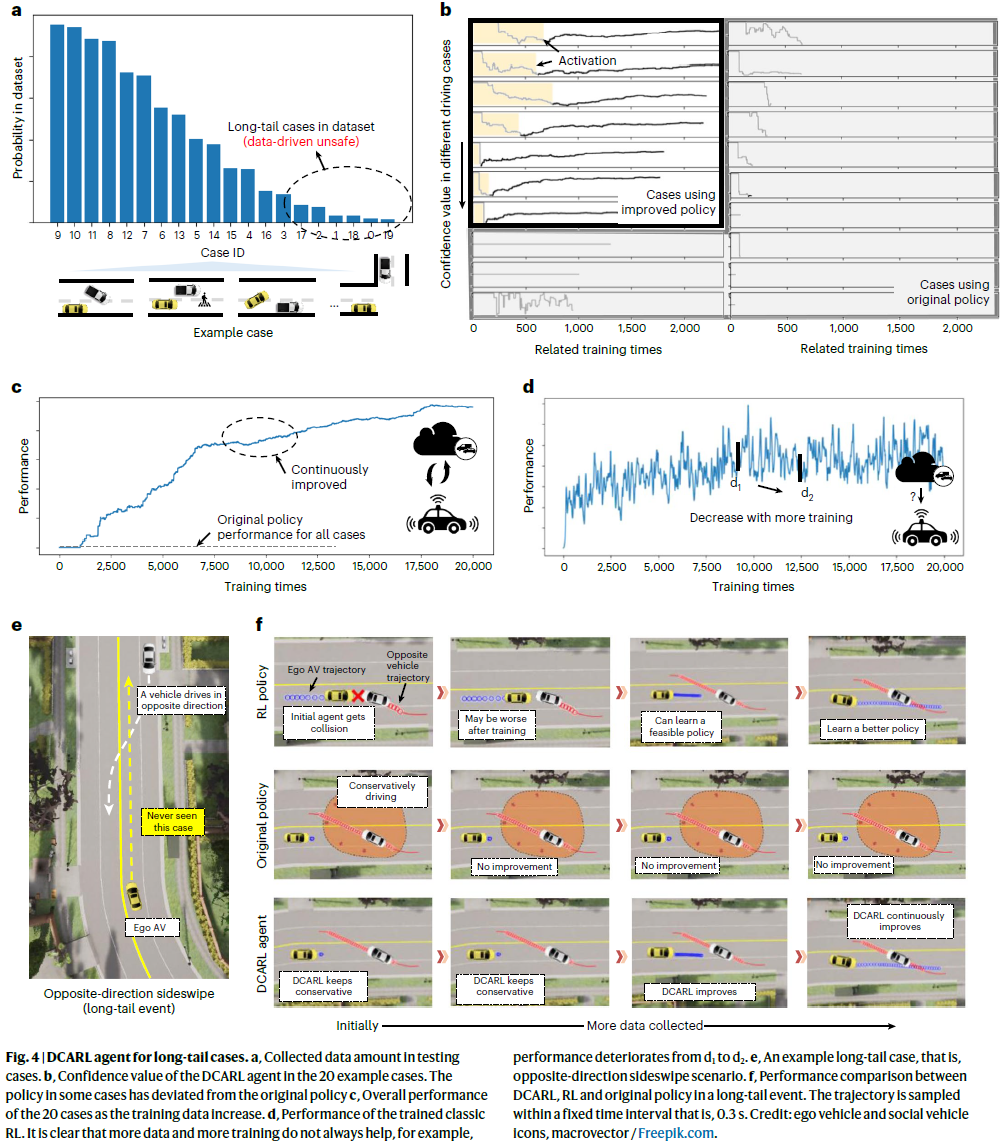
为了进行评估,我们首先随机抽取了20个驾驶案例,其中训练数据点的数量非常不同,如图4a所示,以反映长尾问题。图4b显示了这些情况下的训练阶段,其中DCARL智能体在某些情况下进入第二阶段,而在其他情况下保持原始策略。
图4c显示了20个案例的总体性能。随着训练数据的增加,性能不断提高。由于产品原始策略是保守的,DCARL智能体将从安全但保守的驾驶性能开始,但最终实现更好的驾驶性能。为了进行比较,我们还使用相同的训练数据集训练了一个经典的基于价值的RL策略,如图4d所示。这表明,更多的数据和更多的训练并不总是能带来更好的表现。这是DCARL智能体旨在避免的关键问题。
为了直观起见,我们进一步以Waymo报告的拐角情况为例17,即图4e所示的反向侧滑。请注意,(1)被测试的智能体从未在数据集中看到过相同或相似的驾驶案例,以及(2)初始RL策略在开始时失败。图4f显示了与RL智能体和产品原始策略相比,不同训练阶段的测试结果。当自主车辆第一次遇到这种长尾情况时,RL智能体与对面车辆相撞,而DCARL智能体在很长的距离内减速。在这种情况下收集到更多数据后,DCARL智能体确认,在接下来的几秒钟内,靠近对面车辆是安全的,因此,它开始偏离原始策略。RL智能体也可以最终改进,但经过训练的策略并不总是改进性能。这些碰撞会引起强烈的安全问题,并阻碍其应用。如果只使用原始策略来驱动,性能将永远不会随着更多数据而改变,因此,它无法将长尾情况变为常见情况。
总之,所提出的DCARL智能体支持使用产品保守原始策略的自动驾驶算法的连续学习。它的设计目的是在经过充分训练后最终接管。
Field testing
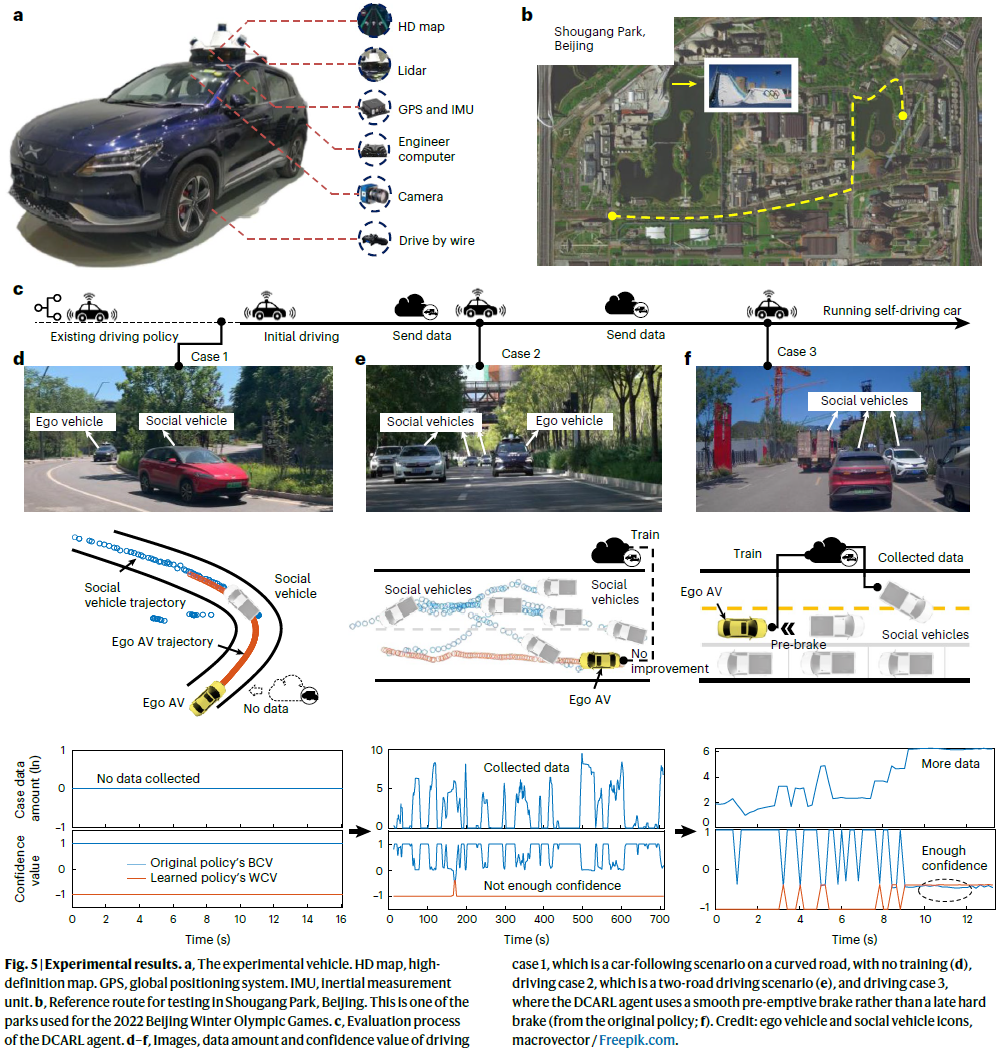
我们在自动驾驶车辆上部署了DCARL算法,如图5a所示。该车配备了传感器(激光雷达和摄像头)、控制器和计算单元。详细配置和算法包含在补充部分1中。
我们在2022年冬奥会期间在首钢公园部署了车辆,首钢公园是一个地理隔离的城市驾驶环境,如图5b所示。所提出的DCARL智能体直接在现有的自动驾驶车辆上工作,并且对该操作领域的知识很少。考虑到周围的目标,现有的驾驶策略可以沿着车道行驶,但可能不符合真实的驾驶条件,应予以改进。本实验将观察自动驾驶过程中收集的更多数据对驾驶性能的影响。
真实世界的学习过程如图5c所示。最初,手动设计的驾驶策略实现了基本的驾驶功能。然后,车辆开始收集数据并学习,即在遵守基准驾驶策略的同时进行训练。所有驾驶案例都是在真实测试中随机发生的。我们选择以下三个案例作为示例,因为它们发生在三个训练阶段,即初始培训、准备阶段和改进阶段。补充第2.3节介绍了这些案例的细节。
Initial performance without training. 图5d显示了场地弯曲部分上的跟车情况。在此期间,DCARL智能体尚未收集任何用于训练的数据,置信值为归一化初始值,即原始策略为1,其他策略为−1,如图5d(底部)所示。根据DCARL智能体决策过程,它使用原始策略,即用于驾驶的跟车模型。
Performance with inadequate training. 图5e显示了附近有多辆人驾驶车辆的多车道驾驶情况。在这种情况下,智能体已经接受了很短时间的训练,它开始估计原始策略和其他候选策略的置信值。然而,DCARL智能体没有足够的信心胜过原始策略,如图5e(底部)所示。因此,最终选定的驾驶策略仍然是原始策略。相比之下,使用经典RL策略的自动驾驶汽车可能具有性能未知的更新策略。
Performance after adequate training. 图5f显示,一辆卡车在领先车辆前方切入,而领先车辆本身就在测试车辆前方几米处。在这种情况下,最初的策略不会预先施加制动,因为它没有很好地考虑前面的两辆车。另一方面,DCARL智能体从类似案例中收集了足够多的驾驶数据,并找到了一个更好的策略,该策略有足够的信心胜过原始策略,如图5f(底部)所示。这样,自动驾驶车辆可以先发制人地刹车,实现更安全、更平稳的减速。
总之,所提出的DCARL可以直接与现有的自动驾驶车辆一起进行道路测试。它从已知水平的驾驶性能开始,随着收集的数据越来越多,驾驶性能不断提高。也就是说,DCARL可以直接为现有的道路测试自动驾驶汽车提供持续改进能力,而无需进行长时间的预训练。
Discussion
结果表明,所提出的技术可以适用于大多数现有的自动驾驶策略。DCARL算法从驾驶数据中学习,并继续监控其最差的置信性能,只有在保证RL智能体优于原始策略后,才会激活RL智能体。该技术在具有默认策略的自动驾驶车辆上实现,并在实验中观察到持续改进。这种方法有三个显著的好处。首先,考虑到许多当前的自动驾驶算法在大多数情况下工作得相当好,但在长尾情况下性能不稳定,该技术提供了一种持续改进的潜在解决方案。其次,基于人工智能的运动规划器是任务关键型的,不能具有不可预测的性能。所提出的技术确保了原始策略提供的可理解的性能下限。最后,这项工作整合了RL和经典自动驾驶方法,并利用了这两种技术的优势。这项工作的一个限制是,对于相同的性能,DCARL智能体可能需要比经典RL更多的数据,因为它需要较高的置信度。然而,较低的数据效率不会阻碍DCARL策略的应用,因为由于现有策略的性能不断提高,DCARL智能体可以在任何训练阶段应用。图6还讨论了不同设置下所需的数据。此外,即使有足够高的置信度,DCARL智能体仍可能偶尔失败或比原始策略更糟,例如,当周围车辆突然失控时。这项工作不能完全避免这种情况,但可以保证在正常驾驶过程中发生这种情况的概率非常低。
Methods
Problem definition
在这项工作中,自动驾驶规划问题被表述为马尔可夫决策过程38,假设未来状态的条件概率分布仅取决于当前状态,即马尔可夫特性。经典RL的目标是找到使期望累积奖励最大化的最优策略,即动作-状态-价值函数![]() ,定义为:
,定义为:
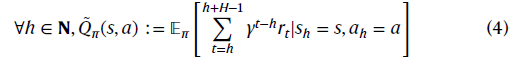
其中𝔼[·]表示期望,rt表示时间 t 的奖励。H表示规划者的有限规划范围。h是一个自然数N,表示规划从时间th开始。γ∈(0,1]是一个折扣系数。波浪表示实际值,与估计值Qπ(s, a)在训练期间不同。
想象中的问题如下:有一辆自动驾驶汽车,其原始控制策略为π0。所提出的DCARL智能体被添加以与此原始策略一起工作。收集到的驾驶数据被连续输入DCARL智能体。随着更多的训练数据,DCARL智能体将在一些驾驶案例中逐渐获得经验和信心。
DCARL智能体的目标可以正式定义如下:
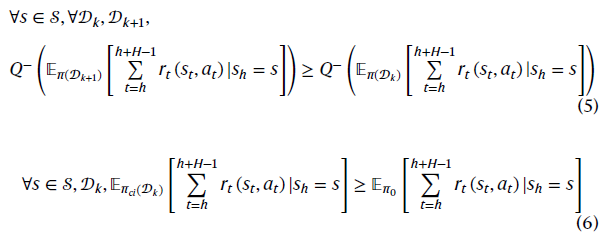
其中π0表示原始策略,将状态s映射到动作a。𝒟k和𝒟k+1分别表示在时间tk和tk+1接收的数据。𝒟k+1的数据比𝒟k更多,可以提高信心和性能。πci(𝒟)表示接收数据集𝒟后生成的策略。p(s)表示状态s的概率。Q−(·)表示WCV。请注意,智能体可以在每个时间步骤动态更新轨迹,因此,如果它撞到地平线内的汽车,危险将得到响应,或者在有风险时受到惩罚。更长的视野可能更安全,但可能会降低计算效率。此外,非常长的未来条件对当前状态的价值(和信心)影响有限。因此,我们在DCARL智能体中使用有限视界设计。一般来说,从𝒟k至𝒟k+n,描述最差置信下限的公式(5)应改进或至少保持,并且公式(6)意味着总体性能必须与原始策略相同或更好。
此DCARL智能体应更新候选策略的WCV和原始策略的BCV。WCV在公式(1)和(2)中定义。类似地,原始策略的BCV由![]() 定义如下:
定义如下:
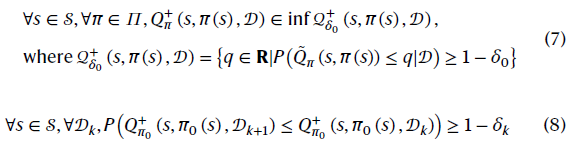
最终DCARL智能体的策略πci(s, 𝒟)遵循公式(3),即策略应该具有所有候选策略的最大置信值。通过公式(1)、(2)、(7)和(8),最终的策略πci(s, 𝒟)可以确保公式(5)和(6)中定义的持续改进(证明见定理1)。我们进一步证明,当信息包含固定反馈误差或标准噪声分布39,40时,所提出的DCARL智能体仍然可以满足要求(有关证明,请参见定理4和5)。然而,其他类型的不确定性可能无法很好地解决,例如,未检测到的物体等等。
以下各节介绍了公式(2)中估计WCV及其改进特性的方法,公式(8)中的原始策略BCV,以及公式(3)中的DCARL策略生成。
Dynamic update of confidence value
本节首先介绍用于置信值更新的动态数据集格式。然后,描述接收到新数据后的价值更新过程以满足公式(1)、(2)、(7)和(8)中的要求。
Dynamic dataset format and data collection. 收集的驾驶数据可以表示为一个序列:
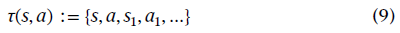
其中τ(s, a)表示使用动作a从状态s开始的轨迹。a属于动作空间𝒜。该轨迹的累积驾驶奖励可以写成:
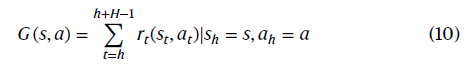
其中H表示视野。
数据集𝒟中的数据单元可以定义为![]() ,其中G(s, a)根据马尔可夫性质可以被认为是给定策略s, a, π的独立同分布采样。
,其中G(s, a)根据马尔可夫性质可以被认为是给定策略s, a, π的独立同分布采样。
数据集包含许多数据单元,定义如下:
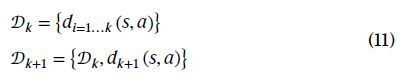
其中𝒟k包含收集的数据单元。明确地,![]() 表示从s, a开始的所有数据单元。
表示从s, a开始的所有数据单元。
WCV and BCV initialization. 最初,DCARL智能体没有任何数据。置信值WCV和BCV的初始化如下:
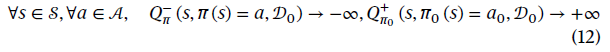
Dynamic update of WCV and BCV when receiving new data. 当新数据dk={s, a, G(s, a)}被接收时,WCV ![]() 和BCV
和BCV ![]() 更新。更新方法受到基于采样的轨迹生成方法7的启发。其基本思想是自主车辆在整个规划范围内规划一条轨迹,并在必要时调整该轨迹。在每个时间步骤中,它只考虑候选轨迹。自动驾驶车辆递归地重新检查情况,并在每个时间步骤做出新的决定。这是必要的,因为现实世界充满不确定性,无法准确预测。然后通过以下公式估算平均状态-动作价值:
更新。更新方法受到基于采样的轨迹生成方法7的启发。其基本思想是自主车辆在整个规划范围内规划一条轨迹,并在必要时调整该轨迹。在每个时间步骤中,它只考虑候选轨迹。自动驾驶车辆递归地重新检查情况,并在每个时间步骤做出新的决定。这是必要的,因为现实世界充满不确定性,无法准确预测。然后通过以下公式估算平均状态-动作价值:
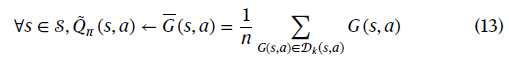
其中![]() 是
是![]() 的点估计。对于大量样本,
的点估计。对于大量样本,![]() 收敛到
收敛到![]() 。然而,由于环境的不确定性和每个驾驶场景收集的数据数量有限,估计值
。然而,由于环境的不确定性和每个驾驶场景收集的数据数量有限,估计值![]() 可能与实际值
可能与实际值![]() 不同。
不同。
可以使用Lindeberg–Lévy定理来估计分布,即概率![]() 当数据量k足够大时变得接近高斯分布,如下所示:
当数据量k足够大时变得接近高斯分布,如下所示:
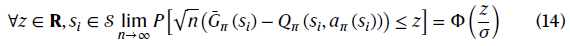
其中σ2=Var(Gπ(si))。z表示任何实数,n表示数据集中的数据数。Φ表示标准正态分布的累积分布函数。基于这一假设,WCV ![]() 使用高斯分布的累积分布函数计算:
使用高斯分布的累积分布函数计算:
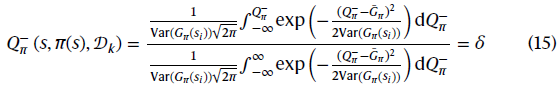
公式(15)可以满足公式(1)中的最差性能下限性质,但可能不满足公式(2)中的连续改进性质。因此,WCV应进一步调整为:
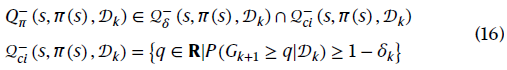
其中![]() 也应在持续改进集
也应在持续改进集![]() 中,其中,WCV低于下一个采样数据值的概率高于1−δk。p(Gk+1)由先前收集的数据拟合。通过这种方式,WCV可以满足公式(1)以及具有更多数据的连续改进性质(见定理2以获得证明)。
中,其中,WCV低于下一个采样数据值的概率高于1−δk。p(Gk+1)由先前收集的数据拟合。通过这种方式,WCV可以满足公式(1)以及具有更多数据的连续改进性质(见定理2以获得证明)。
注意,Lindeberg–Lévy定理需要大量数据(即k>30)。当数据量较小时,![]() 使用自举方法41从数据集𝒟k(s, a)估计。其主要思想是从抽样数据推断群体属性。它没有对群体分布作出假设。即,该方法提供了关于
使用自举方法41从数据集𝒟k(s, a)估计。其主要思想是从抽样数据推断群体属性。它没有对群体分布作出假设。即,该方法提供了关于![]() 通过从Dπ推断。估计
通过从Dπ推断。估计![]() 使用自举方法,我们首先对𝒟k(s, a)的子集进行采样,表示为
使用自举方法,我们首先对𝒟k(s, a)的子集进行采样,表示为![]()
![]() 。每个子集包含与原始𝒟k(s, a)相同数量的数据单元,但每个数据单元都是从原始数据集中均匀采样的。通过这种方式,我们计算
。每个子集包含与原始𝒟k(s, a)相同数量的数据单元,但每个数据单元都是从原始数据集中均匀采样的。通过这种方式,我们计算![]() ,它们是来自
,它们是来自![]() 的n个独立且相同分布的样本。
的n个独立且相同分布的样本。
这两种方法都需要少量的数据单元(即10个)。当数据量很小时,WCV值保持在初始值(接近-∞)。WCV将随着更多数据不断改进。有了足够的数据,分布将接近![]() 。更新BCV的方法与更新WCV类似。唯一的区别是BCV需要数据集𝒟k(s, π0(s)),并从分布
。更新BCV的方法与更新WCV类似。唯一的区别是BCV需要数据集𝒟k(s, π0(s)),并从分布![]() 的上界中获取。
的上界中获取。
Continuously improved policy generation
本节介绍了在公式(3)中生成持续改进策略的方法。主要思想是,最终策略的WCV应不小于原始策略的BCV。
该策略描述如下:
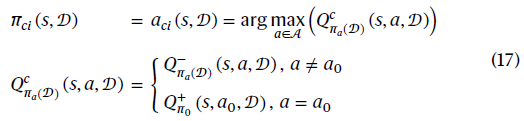
其中![]() 表示对给定数据𝒟采取动作a的置信值。总体策略为πci(s, 𝒟)。定理3证明该策略可以满足公式(3)的要求。
表示对给定数据𝒟采取动作a的置信值。总体策略为πci(s, 𝒟)。定理3证明该策略可以满足公式(3)的要求。
由于动作生成仅考虑每种情况的值,因此对应的激活点对于每种情况可能不同。例如,如果数据中包含更多关于跟车的驾驶案例,但没有那么多关于交叉口的驾驶,那么这两种场景的学习进度可能会有很大差异。一些长尾情况的存在不会影响性能改进特性,这是本工作的主要贡献。
公式(17)的策略生成过程可以描述如下。当自动驾驶车辆在道路上行驶并遇到情况时,DCARL智能体将首先从动作空间计算所有候选动作的所有WCV。然后,DCARL智能体将计算原始策略的BCV。当候选动作的最大WCV大于原始策略的BCV时,RL智能体被激活;否则,仍将使用原始策略的动作。
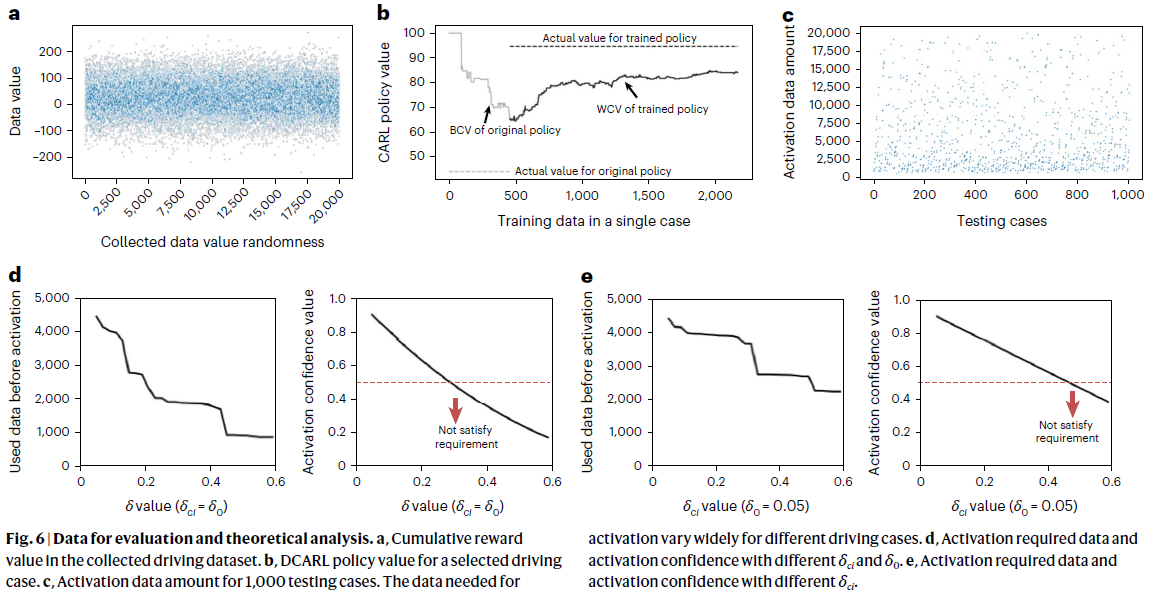
Data for evaluation and theoretical analysis
Data collection for evaluation. 通过随机采样状态s、动作a和累积奖励G(s, a)来收集用于评估的训练数据,以模拟真实驾驶中的数据收集过程。对于评估,环境将首先对于G(s, a)随机生成真值![]() 。然后按照正态分布围绕真值采样G(s, a)。一些采样数据值如图6a所示。
。然后按照正态分布围绕真值采样G(s, a)。一些采样数据值如图6a所示。
Statistical results and analysis. 图6b显示了图3c展示的案例,但具有真Q值。在第一阶段,DCARL智能体使用原始策略。估计的BCV值接近实际值,但始终大于实际值。在大约500个数据点之后,一个RL策略的WCV将大于原始策略的BCV。DCARL然后切换到使用此RL策略。
不同情况下的激活时间差异很大。图6c显示了1000种不同驾驶情况的激活时间。激活时间在50到20000个训练步骤之间变化。
Effects of δ value on the confidence and required data. δ值对DCARL智能体有两个影响:当DCARL智能体偏离基准策略时,降低δ值将增加所需的数据量(见定理6);使δ接近于零可以确保持续改进性能的更高置信度。
这项工作将δ值设置为0.05,这在训练和测试期间是固定的。δ值可以设置在(0, 0.29)的范围内。上限值旨在确保自动驾驶车辆的性能优于原始策略。因此,优于原始策略的概率应至少大于50%,即(1−δ)(1−δ0) ≥ 0.5。如果δ0=δ,我们可以得到δ < 0.29。下限值旨在确保自动驾驶车辆最终能够偏离基准策略。即,公式(16)应具有可行解,即(1−δ)(1−δ0) < 1。这个可以总结为δ > 0。
图6d, e显示了激活前使用数据的曲线和激活置信度。它首先将δci和δ0从0.05调整到0.6。然后,它只将δci从0.05调整到0.6,而δ0保持恒定0.05。我们可以得出结论,较高的δ可以减少激活所需的数据,也会降低激活置信度。











Data availability
补充软件文件包含运行和呈现所有三个实验结果的最小数据。这些数据也可在以下公共存储库中获得:https://github.com/zhcao92/DCARL(参考37)。
Code availability
自动驾驶实验的源代码可在https://github.com/zhcao92/DCARL上获得(参考文献38)。它包含了提出的DCARL规划算法以及我们的自动驾驶汽车中使用的感知、定位和控制算法。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号