Learning Invariant Representations for Reinforcement Learning without Reconstruction
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Published as a conference paper at ICLR 2021
ABSTRACT
我们研究了表征学习如何在不依赖领域知识或像素重建的情况下,从丰富的观察(如图像)中加速强化学习。我们的目标是学习提供有效下游控制和对任务无关细节的不变性表征。互模拟度量量化了连续MDP中状态之间的行为相似性,我们建议使用它来学习仅编码来自观察的任务相关信息的鲁棒潜在表征。我们的方法训练编码器,使潜在空间中的距离等于状态空间中的互模拟距离。我们使用修改的视觉MuJoCo任务证明了我们的方法在忽略与任务无关的信息方面的有效性,其中背景被移动的干扰物和自然视频代替,同时实现了SOTA性能。我们还测试了一个第一人称公路驾驶任务,其中我们的方法学习了对云、天气和时间的不变性。最后,我们提供了从互模拟度量的属性得出的泛化结果,以及与因果推理的链接。
1 Introduction
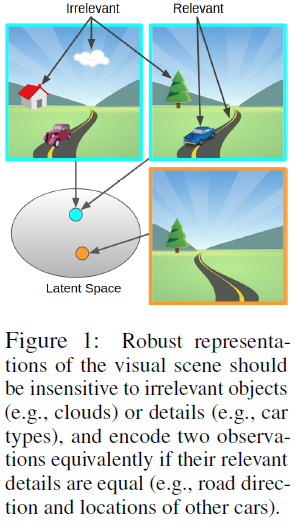
从图像中学习控制对于许多现实世界的应用来说都很重要。虽然深度强化学习(RL)在模拟任务中取得了许多成功,但从真实视觉中学习控制更为复杂,尤其是在户外,图像揭示了复杂和非结构化世界的详细场景。此外,尽管许多RL算法最终可以在给定无限数据的情况下从真实图像中学习控制,但在昂贵且受限于实时的真实试验中,数据效率通常是必要的。用于模拟视觉任务的数据高效学习的现有方法通常使用表征学习。表征学习通过将图像编码成更适合RL的更小的矢量表示来总结图像。例如,序列自编码器旨在学习流观测值的无损表征,以充分重建当前观测值并预测未来观测值,从而训练各种RL算法(Hafner等人,2019年;Lee等人,2020年;Yarats等人,2021)。然而,这些方法是任务无关的:模型代表了他们在世界上观察到的所有动态元素,无论它们是否与任务相关。我们认为,在真实图像的情况下,这种表征很容易用不相关的信息“分散”RL算法的注意力。分心问题在流行的模拟MuJoCo和Atari任务中不太明显,因为观察空间的任何变化都可能与任务相关,因此值得代表。相比之下,自动驾驶汽车观察到的视觉图像主要包含与任务无关的信息,例如云形状和架构细节,如图1所示。
与其学习专注于云和建筑物的精确重建的控制不可知表征,我们更希望从有损编码器获得更压缩的表征,该编码器只保留与任务相关的状态信息。如果我们希望学习仅捕获状态的任务相关元素且对任务无关信息不变的表征,直观地,我们可以利用奖励信号来帮助确定任务相关性,如Jonschkowski & Brock(2015)所示。由于累积奖励是我们的目标,状态元素不仅影响当前的奖励,而且也影响未来的状态元素,进而影响未来的奖励。这种递归关系可以提炼为状态抽象的递归任务感知概念:理想的表征是一种可以预测奖励的表征,也可以预测未来的自身。
我们建议使用互模拟度量来学习这种不变表征,其中两个观测编码之间的距离对应于两个观测的“行为差异”(Ferns & Precup,2014)。我们的主要贡献是基于适用于下游控制的互模拟度量的实用表征学习方法,我们称之为控制的深度互模拟(DBC)。此外,我们还提供了理论分析,证明了真实MDP的最优价值函数和由学习表示构建的MDP的最优价值函数之间的价值边界。经验评估表明,与使用重建损失或对比损失的现有方法相比,我们使用互模拟的非重建方法对任务无关干扰物更为鲁棒。我们最初的实验将自然视频插入MoJoCo控制任务的背景中,作为复杂的分心。我们的第二个设置是使用CARLA的高保真公路驾驶任务(Dosovitskiy等人,2017),表明即使在具有许多干扰的高度逼真的图像上,也可以有效地训练我们的表现,如树木、云、建筑物和阴影。有关视频示例,请参见https://sites.google.com/view/deepbisim4control。代码位于https://github.com/facebookresearch/deep_bisim4control。
2 Related Work
我们的工作建立在先前对MDP状态聚合中的互模拟的广泛研究基础上。
Reconstruction-based Representations. 从图像中进行深度强化学习的早期工作(Lange & Riedmiller,2010;Lange等人,2012)使用了两步学习过程,其中首先使用重建损失训练自编码器以学习低维表征,然后使用该表征学习控制器。这允许有效利用大型未标记数据集来学习控制表征。在实践中,不能保证学到的表征将捕获对控制任务有用的信息,并且这些方法通常需要大量的专家知识和技巧才能工作。在基于模型的RL中,该问题的一个解决方案是端到端联合训练编码器和动力学模型(Watter等人,2015;Wahlström等人,2015)——这在学习有用的面向任务的表征方面被证明是有效的。Hafner等人(2019)和Lee等人(2020)使用重建损失学习潜在状态模型,但这些方法难以学习准确的长期预测,通常仍需要大量手动调整。Gelada等人(2019)还提出了一种基于潜在动力学模型的方法,并使用Atari中的重建损失将其方法与互模拟度量相联系。他们表明,DeepMDP表征中的l2距离是互模拟距离的上限,而我们的目标直接学习了一种表征,其中潜在空间中的距离是互模拟度量。此外,他们的结果依赖于学习的表征是Lipschitz的假设,而我们表明,通过直接学习基于互模拟的表征,我们保证了生成Lipschitz-MDP的表征。我们通过实验证明,我们的非重建DBC方法对复杂的干扰物更为鲁棒。
Contrastive-based Representations. 对比损失是一种自监督的方法,通过加强数据之间的相似性约束来学习有用的表征(van den Oord等人,2018;Chen等人,2020)。相似性函数可以以启发式数据增强的形式作为领域知识提供,其中我们最大化了相同数据点(Laskin等人,2020)或附近图像块(Hénaff等人,2020年)的增强之间的相似性,并最小化了不同数据点之间的相似。在缺乏这一领域知识的情况下,可以通过预测未来来训练对比表征(van den Oord等人,2018)。在我们的实验中,我们与这种方法进行了比较,结果表明DBC的鲁棒性大大提高。虽然对比损失不需要重建,但它们本质上没有一种无需人工工程就能确定下游任务相关性的机制,并且当仅针对预测进行训练时,它们的目标是捕捉观察中的所有可预测特征,这在真实图像上表现不佳,原因与世界模型一样。更好的方法是以数据驱动的方式将下游任务的知识结合到相似性函数中,以便用于在像素方面非常不同的图像(例如照明或纹理变化),也可以被分组为关于下游目标类似的。
Bisimulation. 在马尔可夫决策过程(MDPs)中定义了各种形式的状态抽象,以将状态分组为簇,同时保留一些属性(例如,每个状态的最优价值、所有价值或所有动作价值)(Li等人,2006)。最严格的形式是互模拟(Larsen & Skou,1989),它通常保留了大多数属性。关于给定测试的任何动作序列的奖励序列输出,互模拟仅输出不可区分的状态分组。一个相关的概念是互模拟度量(Ferns & Precup,2014),它衡量“行为相似”状态的程度。Ferns等人(2011)定义了关于连续MDP的互模拟度量,并提出了一种蒙特卡洛算法,用于使用经验测量的过渡分布之间的Wasserstein距离的精确计算来学习该度量。然而,这种方法不能很好地扩展到大型状态空间。Taylor等人(2009)将MDP同态与宽松的概率互模拟联系起来,并定义了宽松的互模拟度量。然后,他们基于MDP同态的这个度量计算一个价值边界,其中聚合了近似等价的状态-动作对。最近,Castro(2020)提出了一种基于策略互模拟度量进行计算的算法,而无需学习表征。他们关注确定性设置和策略评估问题。我们相信,我们的工作是首次提出一种基于梯度的方法,用于直接学习具有互模拟度量属性的表征空间,并表明它在策略优化设置中有效。
3 Preliminaries
我们首先介绍了符号,并概述了环境中底层结构的现实假设。然后,我们回顾状态抽象和状态相似性度量。


1 注意,d是一个伪度量,意味着两个不同状态之间的距离可以为零,对应于行为等价。
4 Learning Representations for Control with Bisimulation Metrics
我们提出了用于控制的深度互模拟(DBC),这是一种从非结构化、高维状态学习控制策略的数据高效方法。与之前的互模拟工作相反,该工作通常旨在学习状态之间形式为![]() 的距离函数,我们的目标是学习表征Z,在表征Z下l1距离对应于互模拟度量,然后使用这些表征来改进强化学习。我们的目标是学习编码器:
的距离函数,我们的目标是学习表征Z,在表征Z下l1距离对应于互模拟度量,然后使用这些表征来改进强化学习。我们的目标是学习编码器:![]() ,其捕获适合控制的状态表征,同时丢弃与控制无关的任何信息。任何依赖于状态重建的表征都不能做到这一点,因为这些无关的细节对重建仍然很重要。我们假设互模拟度量可以获得这种类型的表征,而无需任何重构。
,其捕获适合控制的状态表征,同时丢弃与控制无关的任何信息。任何依赖于状态重建的表征都不能做到这一点,因为这些无关的细节对重建仍然很重要。我们假设互模拟度量可以获得这种类型的表征,而无需任何重构。
互模拟度量是一种有用的状态抽象形式,但现有的训练距离函数的方法要么不缩放到像素观察值(Ferns等人,2011)(由于公式(3)中的max算子),要么仅为(固定)策略评估设置而设计(Castro,2020)。相比之下,随着策略的在线改进,我们学习了策略输入的改进表征。我们的π*-互模拟度量是用梯度下降学习的,我们证明了它在某些假设下收敛到定理1中的一个不动点。为了训练我们的编码器Φ,使其符合我们期望的关系![]() ,我们绘制一批状态对,并最小化策略上互模拟度量与潜在空间中的l1距离之间的均方误差:
,我们绘制一批状态对,并最小化策略上互模拟度量与潜在空间中的l1距离之间的均方误差:
![]()
其中zi=Φ(si),zj=Φ(sj),r是奖励,z表示具有停止梯度的Φ(s)。公式(4)还使用概率动态模型![]() ,其输出高斯分布。因此,我们在公式(4)中使用2-Wasserstein度量W2,而不是公式(3)中的1-Wasserstein,因为W2度量具有方便的闭合形式:
,其输出高斯分布。因此,我们在公式(4)中使用2-Wasserstein度量W2,而不是公式(3)中的1-Wasserstein,因为W2度量具有方便的闭合形式:![]()
![]() ,其中
,其中![]() 是Frobenius范数。对于所有其他距离,我们继续使用l1范数。我们的模型架构和训练如图2和算法1所示。
是Frobenius范数。对于所有其他距离,我们继续使用l1范数。我们的模型架构和训练如图2和算法1所示。
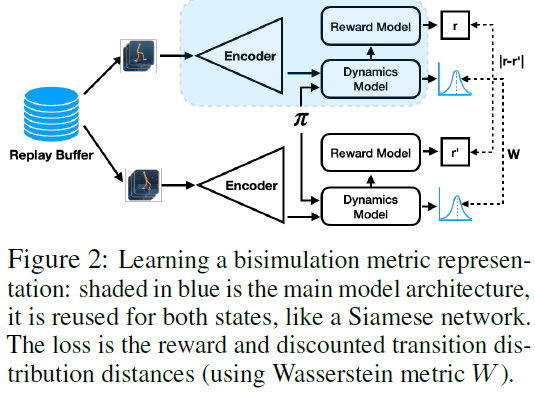

Incorporating control. 我们将我们的表征学习方法(算法1)与软行动器-评判器(SAC)算法相结合(Haarnoja等人,2018),以设计一种实用的强化学习方法。我们在算法2中稍微修改了SAC,以允许价值函数反向传播我们的编码器,这可以进一步提高性能(Yarats等人,2021;Rakelly等人,2019年)。尽管原则上,我们的方法可以与任何RL算法相结合,包括无模型DQN(Mnih等人,2015)或基于模型的PETS(Chua等人,2018)。DBC的实现细节和超参数值汇总在附录表2中。我们通过依次迭代更新三个组件来训练DBC:策略π(在本例中为SAC)、编码器Φ和动态模型![]() (第7-9行,算法1)。我们发现单个损失函数对训练来说不太稳定。算法1中每个损失函数J(·)的输入表示哪些组件被更新。在每个训练步骤之后,使用策略π在环境中进行步进,数据被收集在回放缓存D中,并且随机选择一批以重复训练。
(第7-9行,算法1)。我们发现单个损失函数对训练来说不太稳定。算法1中每个损失函数J(·)的输入表示哪些组件被更新。在每个训练步骤之后,使用策略π在环境中进行步进,数据被收集在回放缓存D中,并且随机选择一批以重复训练。
5 Generalization Bounds and Links to Causal Inference
虽然DBC支持无需像素重建的表征学习,但它留下了一个问题,即生成的表征到底有多好。在本节中,我们将进行理论分析,以限制通过DBC学习的表征训练的价值函数的次优性。

MDP动力学与因果推断和因果图有很强的联系,因果图是有向无环图(Jonsson & Barto,2006;Schölkopf,2019;Zhang等人,2020)。具体而言,时间 t 处的状态和动作会影响时间t+1处的下一状态。在这项工作中,我们关注状态空间中对当前和未来奖励产生影响的组成部分。控制表征的深度互模拟连接到因果特征集,或预测目标变量所需的最小特征集(Zhang等人,2020)。
定理3(与因果特征集的联系(Zhang等人(2020)中的定理1))。如果我们使用互模拟度量对观察进行划分,那么这些聚类(互模拟划分)对应于观察空间关于当前和未来奖励的因果特征集。
这种联系告诉我们,这些特征是当前和未来奖励的最小充分统计,因此包括(并且仅包括)奖励变量 r 的因果祖先。
定义3(因果祖先)。在因果图中,节点对应于变量,父节点P和子节点C之间的有向边是因果关系,节点的因果祖先AN(C)是从C到根节点的路径中的所有节点。
如果存在干扰因素变量的干预,或控制渲染函数q的变量,从而控制渲染观察但不影响回报,则因果特征集将对这些干预具有鲁棒性,并在线性函数近似设置中正确预测当前和未来的奖励(Zhang等人,2020)。例如,在自动驾驶中,干预可以是从白天到晚上的变化,这会影响观察空间,但不会影响动态或奖励。最后,我们证明了基于互模拟度量的表征可以推广到具有相同因果祖先的其他奖励函数。
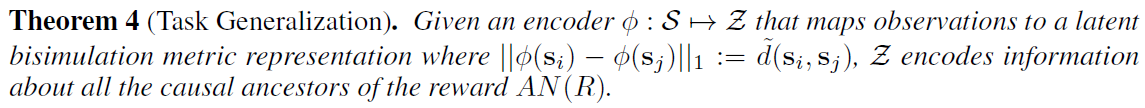
附录中的证明。这一结果表明,只要新的奖励函数具有相同因果祖先的子集,所学习的表征将推广到不可见的奖励函数。例如,为机器人行走学到的表征可能会推广到学习跑步,因为奖励函数取决于前进速度和所有影响前进速度的因素。然而,该表征不会推广到拾取对象,因为这些对象将被学到的表征忽略,因为它们不太可能是为行走设计的奖励函数的因果祖先。定理4表明,所学到的表征对于伪相关性或不在AN(R)中的因素的变化是鲁棒的。这补充了定理5,即表示是最优价值函数的最小充分统计量,改进了非最小表示的泛化。
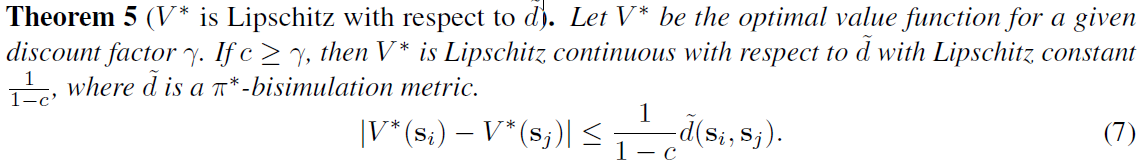
参见Ferns等人(2004)中的定理5.1以获得证明。我们在第6.2节中对这些发现进行了实证验证。
6 Experiments
我们的中心假设是,我们的基于非重构互模拟的表征学习方法应该对任务无关的干扰物更加鲁棒。为此,我们在没有干扰器的干净环境中评估我们的方法,以及在有干扰器的更困难的环境中评估方法。我们对比了几个基准。第一个是随机潜在行动器-评判器(Stochastic Latent Actor-Critic, SLAC,Lee等人(2020)),这是一种最先进的DeepMind Control像素观察方法,它学习具有重建损失的动态模型。第二种是DeepMDP(Gelada等人,2019),这是一种最近的方法,它也使用潜在动态模型、奖励模型和分布Q学习来学习潜在的表征空间,但为此,他们需要重建损失才能扩展到Atari。最后,我们比较了使用与我们相同架构的两种方法,但将我们的互模拟损失与(1)重建损失(“Reconstruction”)和(2)对比预测编码(Oord等人,2018)(“Contrastive”)进行交换,以建立动力学模型并学习潜在表征。
6.1 Control with Background Distraction
在本节中,我们在两个设置和九个环境(图3)、finger_spin、cheetah_run和walker_walk以及附录中的其他环境中,对DBC和之前描述的DeepMind Control(DMC)套件基准(Tassa等人,2018)进行了基准测试。
Default Setting.
Simple Distractors Setting.
Natural Video Setting.
6.2 Generalization Experiments
我们用两种方式测试我们所学表征的泛化。首先,我们证明,通过使用简单的干扰物进行训练并在自然视频环境上进行测试,学到的表征空间可以推广到不同类型的干扰器。第二,我们证明,我们所学到的表征可以是有用的奖励函数,而不是它所训练的那些函数。
Generalizing over backgrounds.
Generalizing over reward functions.
6.3 Comparison with other Bisimulation Encoders
6.4 Autonomous Driving with Visual Redundancy
7 Discussion
本文提出了一种考虑下游控制的新的表征学习方法——控制的深度互模拟。观察被编码成对观察中不同任务无关细节不变的表征。我们表明,当从户外图像或其他具有背景“干扰”的图像中学习控制时,这一点很重要。与其他互模拟方法相比,当表征空间中的距离与观察之间的互模拟距离匹配时,我们显示了性能增益。
Future work: 今后的工作有几个选择。首先,我们的潜在动态模型![]() 仅用于训练公式(4)中的编码器,但也可以用于潜在空间中的多步规划。第二,估计不确定性对于产生能够在现实世界中工作的智能体也很重要,可能是通过模型集合
仅用于训练公式(4)中的编码器,但也可以用于潜在空间中的多步规划。第二,估计不确定性对于产生能够在现实世界中工作的智能体也很重要,可能是通过模型集合![]() 来检测和适应训练和测试观察之间的分布变化。第三,一个未经处理的问题是部分观察到的设置(通过使用堆叠图像假设近似完全可观察),可能使用显式存储器或隐式存储器(如LSTM)。最后,研究哪些度量(L1或L2)和动力学分布(Gaussian或非Gaussian)将是有益的。
来检测和适应训练和测试观察之间的分布变化。第三,一个未经处理的问题是部分观察到的设置(通过使用堆叠图像假设近似完全可观察),可能使用显式存储器或隐式存储器(如LSTM)。最后,研究哪些度量(L1或L2)和动力学分布(Gaussian或非Gaussian)将是有益的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号