

Towards artificial general intelligence with hybrid Tianjic chip architecture
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

NATURE, no. 7767 (2019): 106-+
Abstract
开发通用人工智能(AGI)1有两种通用方法:面向计算机科学和面向神经科学。由于它们的制定和编码方案存在根本差异,这两种方法依赖于不同且不兼容的平台2-8,从而阻碍了AGI的发展。一个可以支持流行的基于计算机科学的人工神经网络以及受神经科学启发的模型和算法的通用平台是非常可取的。在此,我们展示了天机芯片,它集成了这两种方法,提供了一个混合、协同的平台。天机芯片采用多核架构、可重构构建模块和混合编码方案的流线型数据流,不仅可以适应基于计算机科学的机器学习算法,还可以轻松实现类脑电路和多种编码方案。我们仅使用一块芯片,就在无人自行车系统中演示了多种算法和模型的同时处理,实现了实时物体检测、跟踪、语音控制、避障和平衡控制。我们的研究有望通过为更通用的硬件平台铺平道路来刺激AGI的发展。
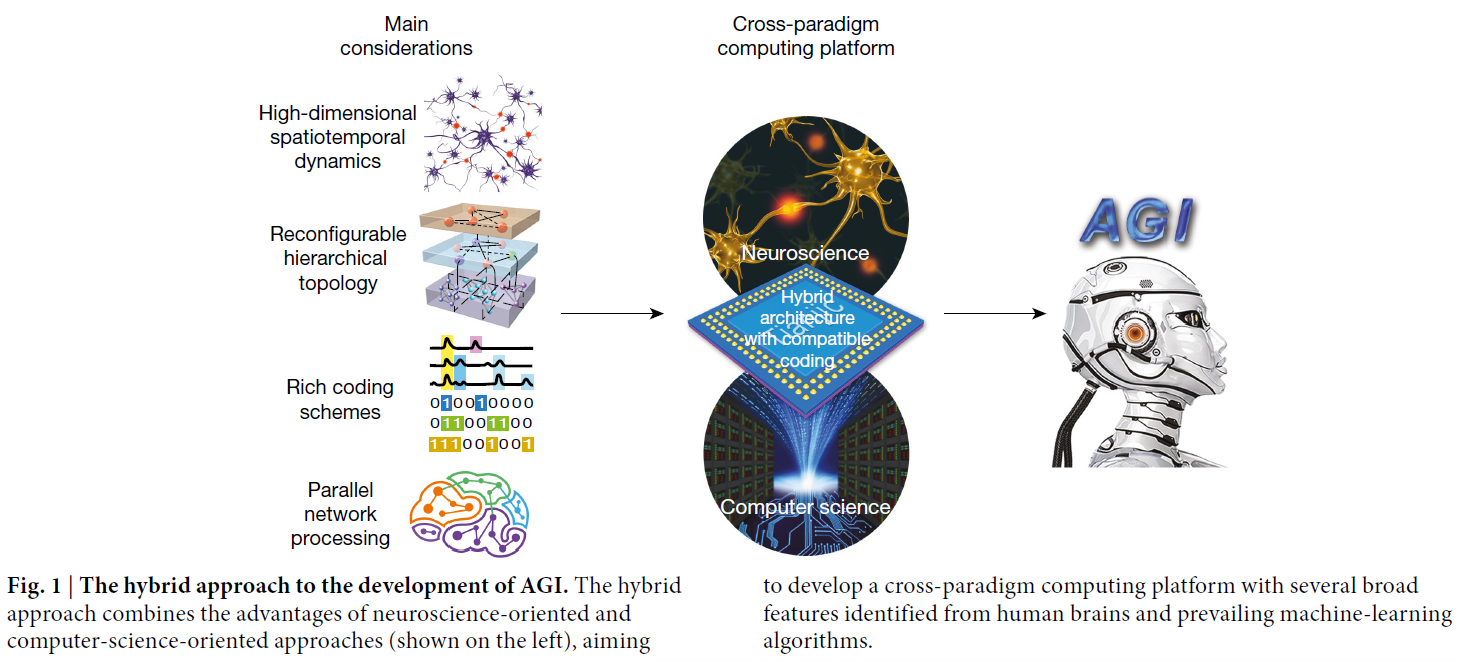
面向神经科学的AGI方法试图密切模仿大脑皮层,基于对记忆和计算之间紧密相互作用的观察、丰富的时空动态、基于脉冲的编码方案和各种学习规则9-12,这些规则通常表示为脉冲神经网络(SNN)。相比之下,面向计算机科学的方法主要涉及在计算机上执行的显式算法13。在这些算法中,流行的非脉冲人工神经网络(ANN)——在空间复杂性方面部分受到皮层的启发14——在处理特定任务15,16方面取得了实质性进展,例如图像分类17、语音识别18、语言处理19和游戏20。
尽管这两种方法都可以解决数据丰富的专业领域的子问题,但仍然难以解决与许多系统相关的不确定或不完整信息的复杂动态问题。为了进一步提高实现AGI所需的智能能力,越来越多的趋势是将更多受生物启发的模型或算法纳入流行的ANN,从而在两种方法之间进行更明确的对话22-29。鉴于机器学习和神经科学的当前进展,AGI系统至少应具有以下特点:首先,支持可以表示丰富的空间、时间和时空关系的庞大而复杂的神经网络;第二,支持分层、多粒度和多域网络拓扑,但不限于专门的网络结构;第三,支持广泛的模型、算法和编码方案;第四,支持为并行处理中的不同任务而设计的多个专业神经网络的交织协作。这需要一个通用平台来有效地支持统一架构中的这些功能,该架构可以实现流行的人工神经网络以及受神经科学启发的模型和算法。
为了支持这些特性,我们开发了一种跨范式计算芯片,可以适应面向计算机科学和面向神经科学的神经网络(图1)。设计一个与各种神经模型和算法兼容的通用平台是一项基本挑战,尤其是对于不同的人工神经网络和受生物学启发的(例如,SNN)原语。通常,ANN和SNN在信息表示、计算理念和内存组织方面具有不同的建模范式(图2a)。在这些差异中,最大的差异在于ANN以精确的多位值处理信息,而SNN使用二值脉冲序列。为了在一个平台上实现这两种模型,需要将脉冲表示为数字序列(1或0),以便它们与数字的ANN编码格式兼容。其他几个关键点也需要仔细考虑。首先,SNN在时空域中运行,这需要在一定时间内记住历史膜电位和脉冲模式,而ANN在中间累积加权激活并在每个周期刷新信息。其次,SNN的计算包括由脉冲事件驱动的膜电位积分、阈值交叉和电位重置。相比之下,人工神经网络主要与密集乘加(MAC)操作和激活转换有关。第三,SNN中脉冲模式的处理需要位可编程存储器和超高精度存储器来存储膜电位、发放阈值和不应期,而ANN只需要逐字节的存储器来进行激活存储和转换。ANN神经元和SNN神经元之间的实现比较如图2b所示。另一方面,ANN和SNN神经元之间存在一些相似之处,这为融合模型实现留下了空间。
通过编译这两个领域的各种神经网络模型,我们能够进行详细的比较,将模型数据流与相关的构建块一一对应地对齐,即轴突、突触、树突、胞体和路由器(扩展数据表1)。在这种统一抽象的基础上,我们构建了一个跨范式神经元方案(图2c)。总的来说,我们设计了共享的突触和树突,而轴突和胞体可以独立重新配置。
在轴突块中,我们部署了一个小的缓冲存储器来记忆SNN模式中的历史脉冲模式。该缓冲存储器支持可重新配置的脉冲收集持续时间和通过移位操作的逐位访问。在ANN模式下,相同的内存可以重组为乒乓块,用于缓冲输入和输出数据;这将并行处理的计算和数据传输解耦。在这里,突触权重和神经元参数被固定到片上存储器中,从而通过最小化处理单元和存储器之间的数据移动来实现本地化的高吞吐量计算。在树突块中,SNN模式下的膜电位积分和ANN模式下的MAC共享相同的计算器,在处理过程中统一了SNN和ANN的高级抽象。具体来说,在ANN模式下,MAC单元用于执行乘法和累加;在SNN模式中,提供了一种绕过机制来跳过乘法,以便在长度为1的时间窗口下减少能量。胞体可以重新配置为具有潜在存储、阈值比较、确定性或概率性发放以及SNN模式下的潜在重置功能的脉冲发生器;或ANN模式下的简单激活函数块。膜电位的渗漏函数可以通过固定或自适应渗漏来降低电位值。ANN模式中的激活函数依赖于提供任意函数的可重构查找表(LUT)。
通过结合轴突、突触、树突和胞体块,我们设计了一个统一的功能核心(FCore)(图2d;更多详细信息,请参见扩展数据图1)。为了实现深度融合,几乎整个FCore都可重新配置以在不同模式下实现高利用率。树突和胞体在操作过程中被分成多个组。每个组内的计算是并行化的(每个时钟周期每个树突有16个MAC),而组间执行是串行化的。FCore能够涵盖大多数ANN和SNN使用的线性积分和非线性变换操作。此外,为了在神经元之间传递信息,我们构建了一个路由器来接收和发送消息。由于消息可以根据配置以ANN或SNN格式编码,因此我们为路由数据包设计了统一格式,并为传输这两种消息类型设计了共享路由基础设施。路由数据包通常包含控制、地址和数据段,其中数据段可以是ANN模式中的多位激活值,也可以是SNN模式中的任何内容,因为路由数据包本身充当脉冲事件。根据需要,pre-soma可以根据胞体配置将输出打包成SNN或ANN数据包,而post-axon根据其轴突配置将路由数据包解析为SNN或ANN格式。
由于轴突(输入)和胞体(输出)完全独立的可配置性,以及共享的树突(计算),FCore通过适当地连接多个核心为构建同构或异构网络提供了极大的灵活性。如果我们将所有单元配置为相同的模式,则可以实现SNN或ANN网络原语的同质范式,它支持许多单范式模型,包括SNN和ANN(例如,多层感知器(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)和基于发放率的仿生神经网络)。此外,FCore允许构建用于探索混合建模的异构网络。通过在不同模式下独立配置轴突和胞体,我们可以轻松实现具有"ANN-输入和SNN-输出"或"SNN-输入和ANN-输出"的混合网络原语(图2e)。换句话说,FCore可以充当ANN/SNN转换器(详见方法)。这种跨范式方案开辟了设计创新混合模型的可能性,为跨模型探索提供了一个高效的平台。
为了支持大型网络或多个网络的并行处理,我们的天机芯片采用多核架构,分散局部内存,实现及时无缝通信。该芯片上的FCore以二维(2D)网格方式排列,如图2e, f所示。每个FCore的路由器中的可重新配置路由表允许任意连接拓扑。通过配置路由表,我们可以将一个神经元连接到FCore内部或外部甚至芯片外部的任何其他神经元,这有助于构建多粒度网络拓扑(例如,前馈或循环)。此外,除了普通的点对点(P2P)路由外,天机还包含几种特殊策略来增加其fan-in能力(一个神经元可以处理的输入数量)和fan-out能力(一个神经元可以驱动的输出数量)。对于典型的神经形态核心,fan-in和fan-out的数量通常受到内存和接口的限制,这限制了模型规模。在天机中,每个FCore的fan-in和fan-out可以通过设计中间神经元横向协作、interFCore分层累积、intraFCore/interFCore神经元复制或interFCore多播路由来轻松扩展(详见方法)。加上芯片级的二维网格堆积,天机对超大型神经网络表现出很强的可扩展性,同时在并发处理过程中仍然保持深度交织的神经网络之间的无缝通信。
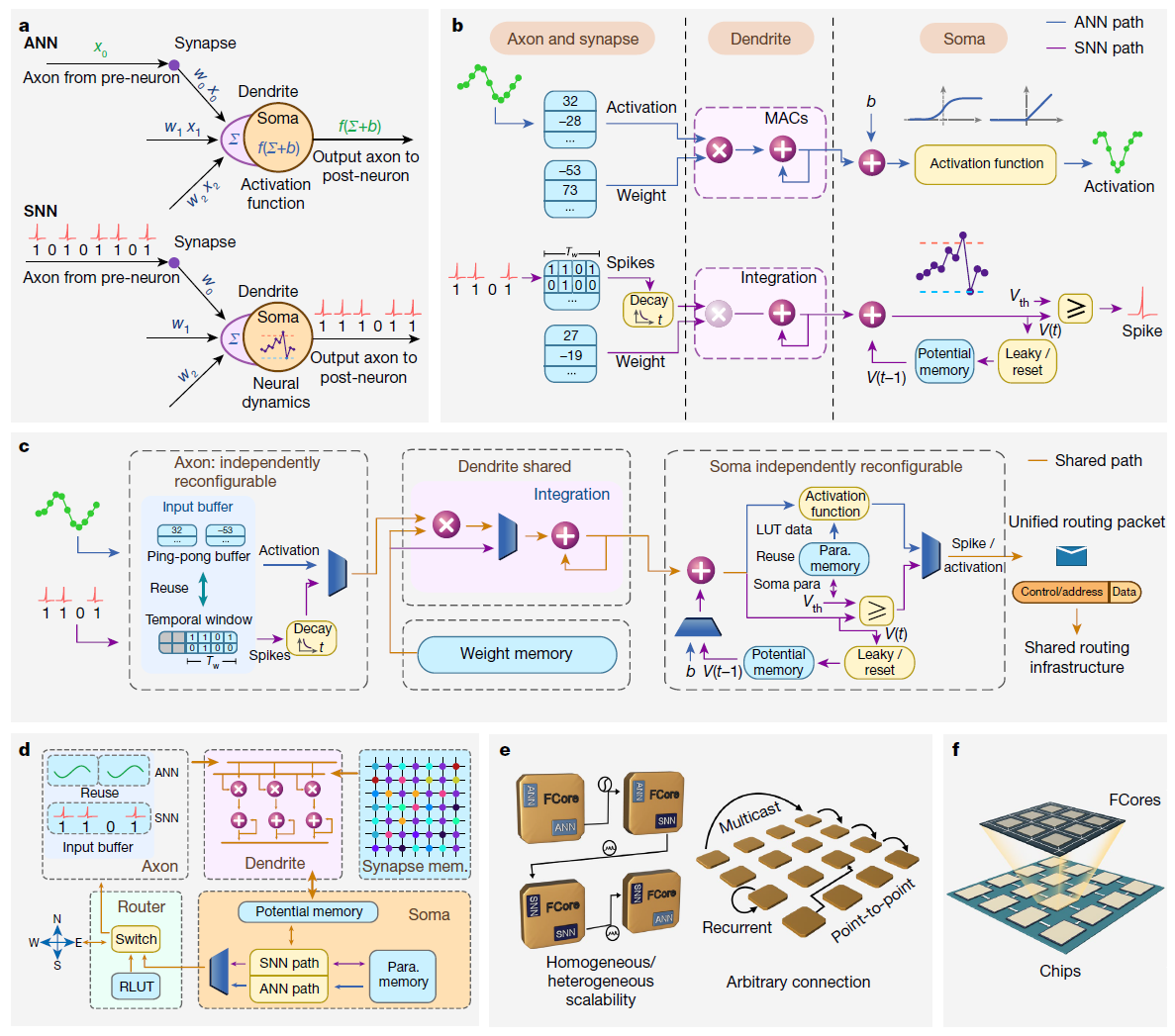
图2 | 天机芯片的设计。a,人工神经网络或生物启发(例如,SNN)神经元的计算模型。w0, w1, w2是突触权重;x0, x1, x2是输入激活;Σ 是树突状积分;f 是激活函数;b 是偏差。b,ANN或SNN神经元的实现图。V(t)是时间步骤 t 处的神经元膜电位,Vth是发放阈值。蓝色框中的数字是输入激活/脉冲和权重值的示例。SNN路径中褪色的紫色乘数表示树突可能绕过乘法(例如,在时间窗口长度等于1的情况下)。c,混合电路图,显示了融合了ANN和SNN组件的跨范式神经元。Para. memory,参数内存。d,统一功能核心(FCore)图。每个FCore包括轴突、突触、树突、胞体和路由器构建块。Synapse mem.,突触记忆。e,FCores的灵活建模配置和连接拓扑。编码方案可以在ANN和SNN模式之间自由转换,从而实现异构神经网络。该方案还允许灵活连接以实现任意网络拓扑。f,2D网格架构在核心和芯片级别的层次结构示意图,展示了该技术的扩展能力。RLUT,路由查找表。
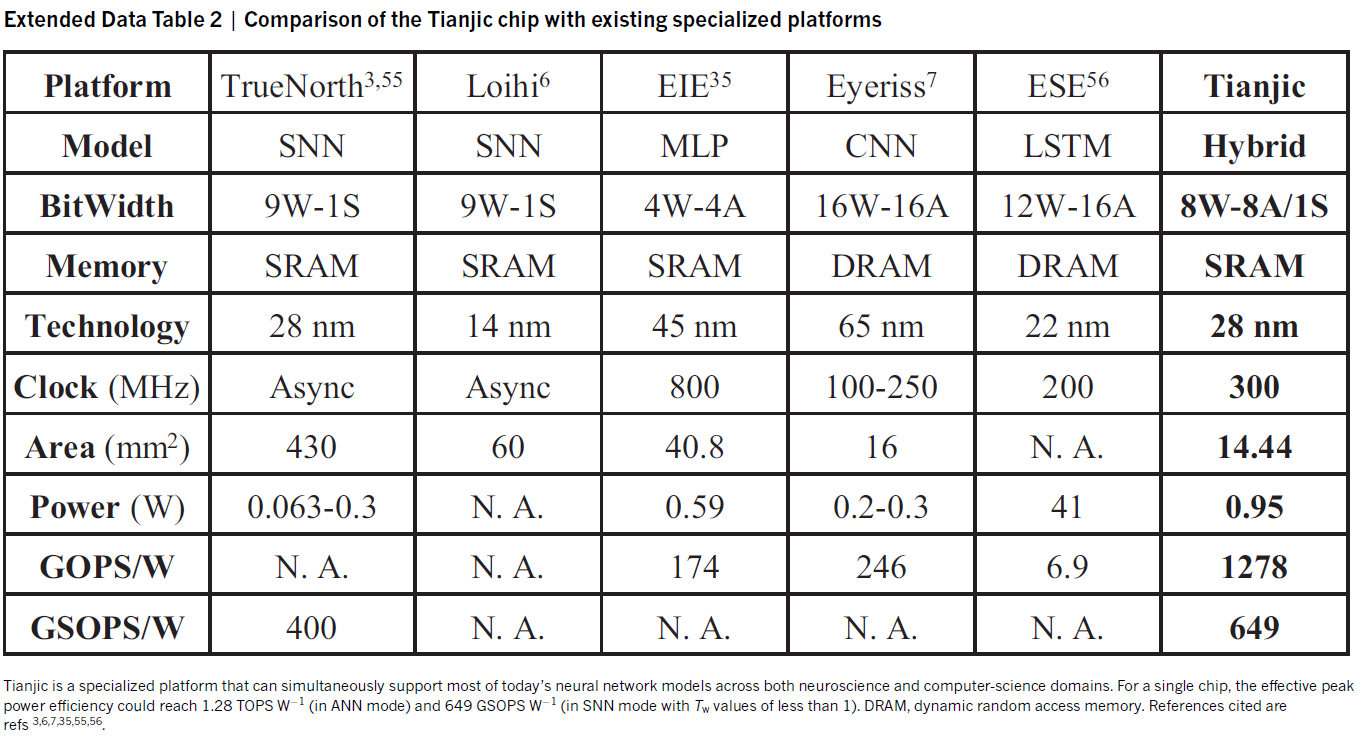
天机芯片和测试板的布局和物理视图如图3a和扩展数据图2所示。该芯片由156个FCore组成,包含约40000个神经元和1000万个突触。天机集成电路采用28纳米工艺制造,芯片面积为3.8 × 3.8 mm2(扩展数据表2)。每个单独块占用的芯片面积,包括轴突、树突、胞体、路由器、控制器和其他芯片开销,如图3b所示。由于资源重用,仅比单个范式(大约3%)略大的区域用于融合SNN和ANN模式。FCore的功率分解如图3c所示。在操作过程中,树突模块(此处包括执行树突整合时涉及的轴突和突触块)消耗的功率最多(63%)。凭借其分布式片上存储器和分散式多核架构,天机集成电路提供超过每秒610千兆字节(GB)的内部存储器带宽,并在以300 MHz运行时的ANN模式中产生每瓦特每秒1.28兆兆次运算(TOPS)的有效峰值性能。在SNN模式下,通常使用突触操作对芯片进行基准测试,天机芯片的有效峰值性能约为每秒650千兆突触操作(GSOPS)每瓦。详细信息可在扩展数据表2中找到。
天机能够支持多种神经网络模型,包括受神经科学启发的网络(例如,SNN和基于发放率的生物启发神经网络)和面向计算机科学的网络(例如,MLP、CNN和RNN)。图3d显示了在天机芯片上测试不同网络模型与通用处理单元(GPU;有关模型详细信息,请参见方法)的结果。通过形成并行片上存储器层次结构并以流方式组织数据流,天机芯片可以提供比GPU更高的吞吐量(1.6到102倍)和电源效率(12到104倍)。这些网络在芯片上的详细映射如扩展数据图3所示。
此外,天机可以在一个芯片内同时部署多个专家网络,包括大多数类型的SNN和ANN。借助灵活可重构的编码方案,它支持异构神经网络,深度融合了两种范式。例如,天机可以轻松部署具有大量树突状分支的大规模SNN。传统上,每个FCore允许的突触输入的数量是相同的(例如,少于256个输入),如果仅使用二值脉冲信号进行FCore间通信,这通常会限制模型的准确性,因为在树突集成过程中面对超大的神经元fan-in会严重损失精度。通过在ANN模式下配置一些FCore来以更高的精度积累膜电位(充当树突树的中继器),而不是仅仅通过SNN模式下的脉冲进行通信,天机集成电路能够以高精度实现大规模SNN来自中间膜电位的直接转移。如图3e所示,与仅SNN配置相比,具有树突状继电器的混合神经网络的准确度提高了11.5%,而无需增加神经元的数量。这种混合范式带来的额外开销可以忽略不计,因为天机可以自然地在FCore内实现异构转换。更全面的分析可以在方法中找到。
天机的使用还可以探索更多生物学上合理的认知模型。例如,天机可以实现连续吸引子神经网络(CANN)30、synfire链31和树突状多室模型32(图3f)。我们还开发了一种软件工具,可以自动转换多模式和混合网络,以满足天机芯片的硬件约束。总体而言,天机采用非冯诺依曼范式,具有混合兼容性、多核架构、本地化内存和流线型数据流,能够支持跨范式建模,最大限度地提高并行度,提高电源效率。
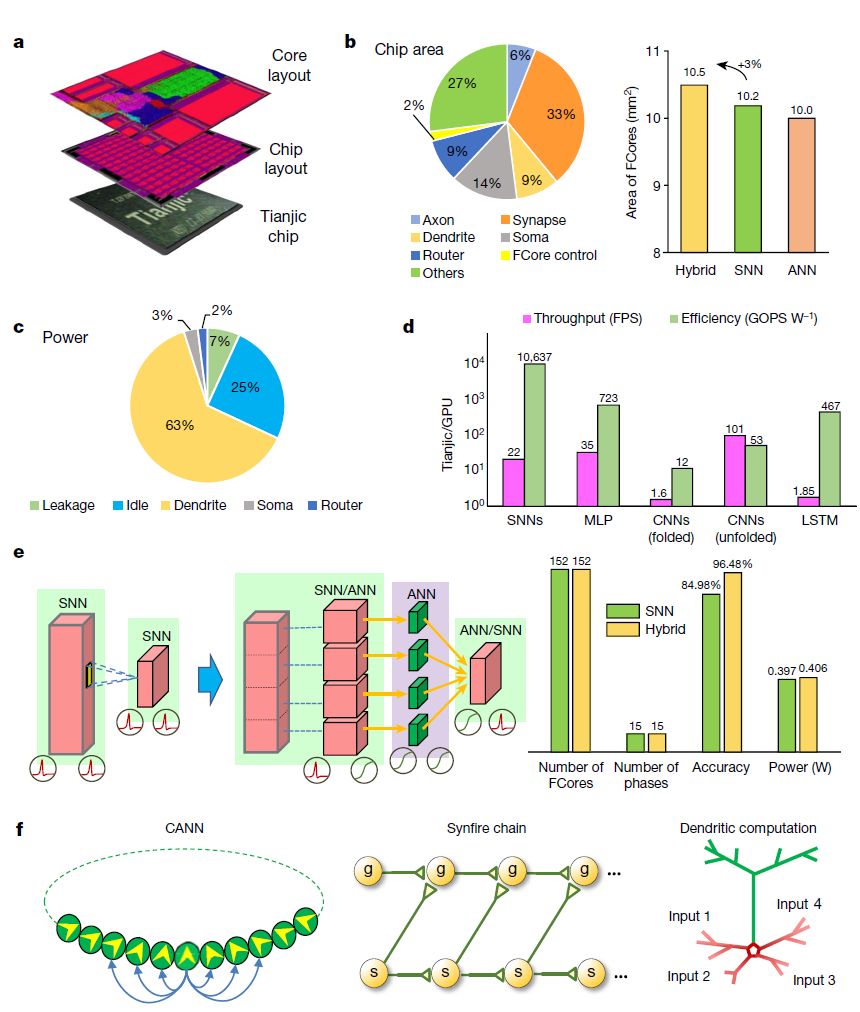
图3 | 芯片评估和建模总结。a,天机芯片的集成布局和封装。b,左,不同特征(轴突、树突、路由器等)占据的芯片面积百分比。没错,由于高度的资源共享和可重构性,只需要增加很小的面积(大约3%)就可以融合两种范式。c,FCore 的功率击穿。d,在各种单范式模型中评估FCore性能,包括SNN、MLP、CNN(在折叠或展开映射下)和长短期记忆网络(LSTM)。GOPS,每秒千兆操作;FPS,每秒帧数。e,左,使用ANN树突状中继实现大规模SNN的示例。右,在ANN继电器的帮助下以高精度传输中间膜电位,混合设备能够实现比单独的SNN更高的识别精度,而硬件开销可以忽略不计。f,天机芯片还可以支持更多生物学上合理的神经网络模型(例如,CANN;基于时序编码的synfire神经链;以及树突状多室模型)。g,graded;s,synfire。
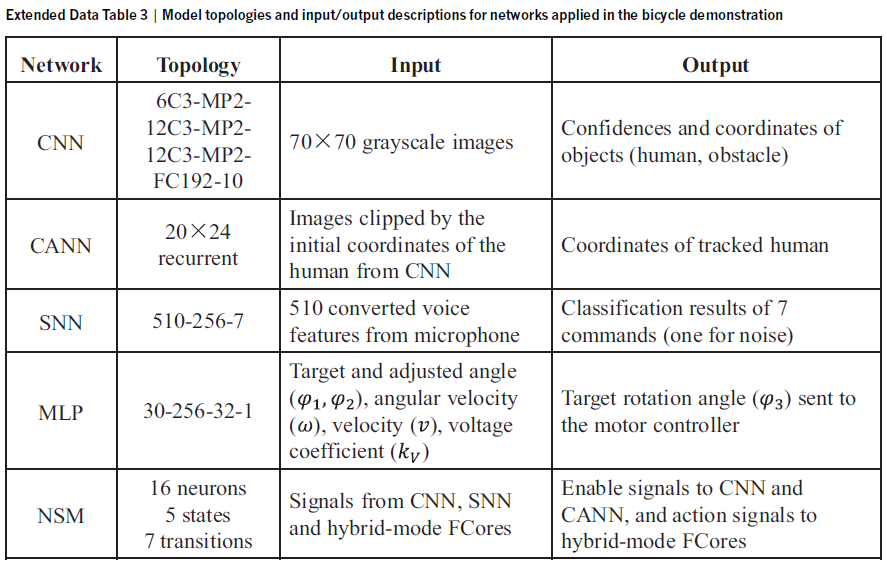
为了展示构建类脑跨范式系统的实用性,我们设计了一个无人驾驶自行车实验,通过在一个天机芯片内并行部署多个专用网络。配备通用算法和模型,自行车能够执行实时物体检测、跟踪、语音命令识别、越过减速带、避障、平衡控制和决策(图4a)。实现这些功能涉及三大挑战:首先,在室外自然环境中检测并平滑跟踪移动的人,在减速带上骑行,并在必要时自动避开障碍物;其次,根据平衡控制、语音命令和视觉感知生成实时电机控制信号,以保持自行车朝着正确的方向行驶;三是实现多式联运的信息整合和及时决策。为了完成这项任务,我们开发了几个神经网络,包括用于图像处理和对象检测的CNN、用于人类目标跟踪的CANN、用于语音命令识别的SNN以及用于姿态平衡和方向控制的MLP(图4b)。在这里,CANN利用通过非线性树突操作实现的膜电位归一化机制。为了整合这些网络并实现高级决策,我们开发了基于SNN的神经状态机(NSM)。NSM接收来自其他网络(CNN、SNN)的输入,并将使能信号(CNN、CANN)和动作信号(例如,强制转弯、避障)输出到下游的FCore,用于自行车电机控制。为实验训练了五个离散状态(参见方法和扩展数据表3)。
在路测之前,CNN、CANN、SNN和MLP网络经过预训练并编程到天机芯片上。 由于其分散式架构和任意路由拓扑,天机电允许所有神经网络模型并行运行,并实现模型之间的无缝通信,使自行车能够顺利完成这些任务(见补充视频)。图4c可视化了响应不同语音命令的输出脉冲信号;图4d给出了避障和S曲线路径时的跟踪性能;图4e说明了基于物理测量的不同速度下姿态和转向控制的学习。该演示提供了一个极好的实验平台,可以用来研究AGI迭代演化中的关键问题。例如,时空复杂度高的问题可以通过实时随机引入新的变量来产生,例如不同的路况、噪音、天气因素、多种语言、更多的人等等。通过探索能够适应这些环境变化的解决方案,可以检查对AGI至关重要的问题——例如泛化、鲁棒性和自主学习。
总之,我们开发了天机芯片,它同时支持基于计算机科学的机器学习算法和基于神经科学的仿生模型。可以自由集成各种神经网络和混合编码方案,实现多个网络之间的无缝通信,包括SNN和ANN。我们的研究检查了一种新颖的神经形态架构,该架构通过将跨范式模型和算法集成到一个平台上来提供灵活性;我们希望我们的发现将加速AGI的发展,并提供许多可能的实际应用。
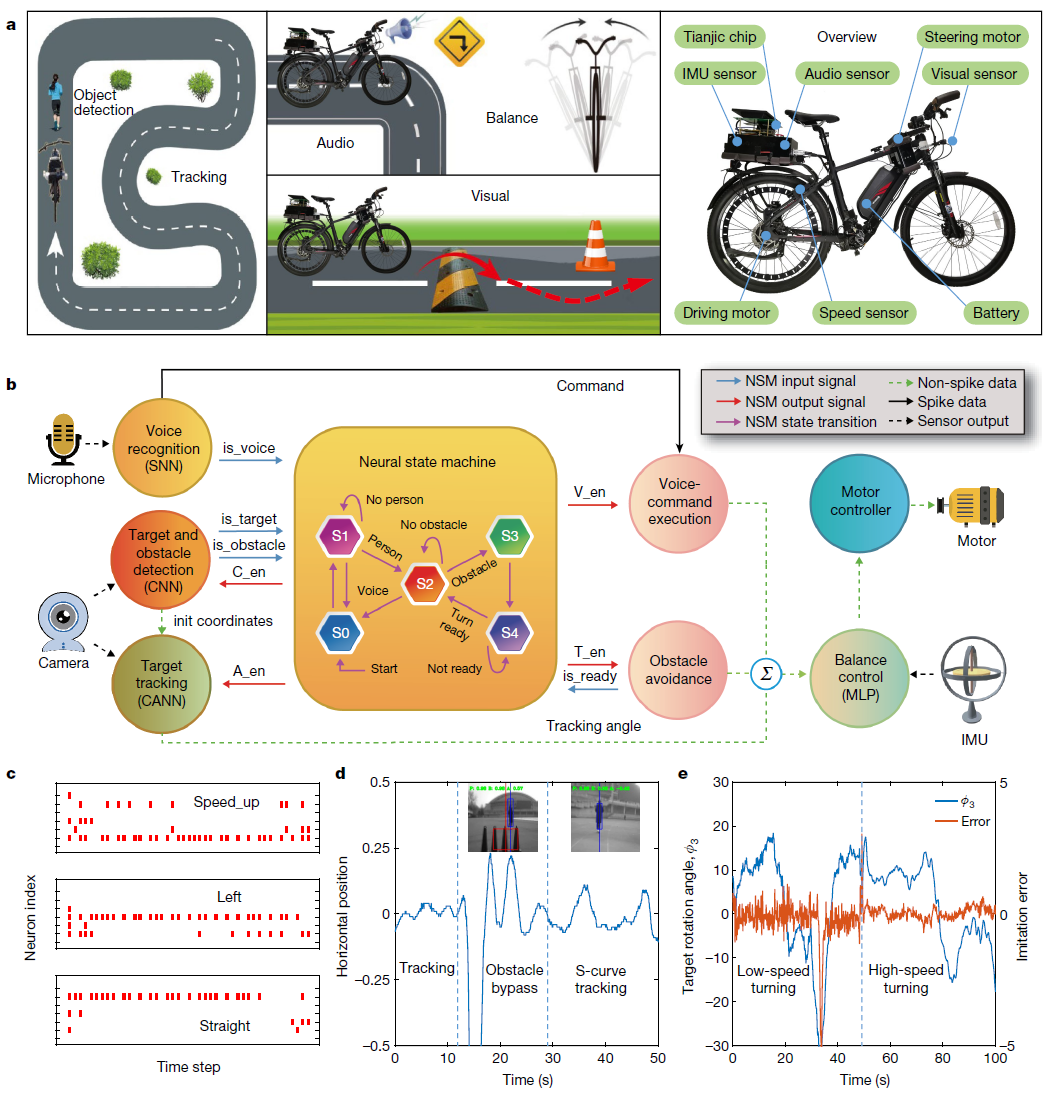
图4 | 无人驾驶自行车天机芯片多模态集成演示。a,左和中,自行车实验中进行的任务的图示,包括实时物体检测、跟踪、语音感知、越过减速带、自动避障和姿态平衡。右,这辆自行车配备了摄像头、陀螺仪、车速表、电机和天机芯片。IMU,惯性测量单元。b,无人驾驶自行车实验中使用的多个神经网络示意图。NSM图中的状态定义为:语音命令执行(S0)、人体检测(S1)、人体跟踪(S2)、避障开始(S3)和避障完成等待(S4)。初始坐标是初始化坐标。C_en、A_en、V_en和T_en分别表示CNN、CANN、语音控制和转向控制的使能信号。c,SNN语音命令识别测试。产生最多脉冲的神经元表示结果分类。d,跟踪测试。y轴显示人在帧中的相对水平位置。自行车自动避开了障碍物,然后跟着一位教练沿着S形曲线跑。e,通过MLP网络进行平衡控制和转向,该网络通过使用比例-积分-微分算法在不同速度(从低到高)下模仿几个调整良好的控制器的输出进行训练。
Methods
Description of the unified model. 天机是一个专业平台,支持当今跨神经科学和计算机科学领域的大多数神经网络模型,这些模型通常使用不同的方式来表示信息。我们重新检查了神经科学领域(例如SNN、基于发放率的仿生神经网络等)和计算机科学领域(例如MLP、CNN和RNN)中最广泛使用的神经网络模型,以及我们提出了一个统一的描述,以使模型实现与轴突、突触、树突、胞体和路由器隔间保持一致。我们确定了ANN和SNN神经元之间的异同,并根据它们各自的函数将操作和转换安排到这些隔间中(参见扩展数据表1)。通过对齐数据流,天机可以灵活地在单一或混合范式中实现各种模型。
Design philosophy. 天机采用海量并行的众核架构。每个FCore包括几个块:轴突、树突(带突触)、胞体和路由器。使我们能够实现混合范式的三个关键设计是: 独立可重构的轴突和胞体。 轴突和胞体可以独立配置成不同的模式。轴突根据其模式配置接收和组织SNN输入或ANN输入。类似地,胞体根据其模式配置生成SNN输出或ANN输出。当轴突和胞体配置为相同的操作模式(ANN或SNN)时,FCore分别以纯ANN或SNN模式运行,我们称之为单范式FCore。当轴突和胞体配置成不同的操作模式时,FCore处理ANN输入并发放SNN输出,或处理SNN输入并生成ANN输出;我们称之为混合FCore。
Shared dendritic integration. 用于处理SNN输入和ANN输入的树突集成共享相同的计算器(乘法器和累加器),尽管它们具有不同的处理操作和样式。在每个时间阶段,树突在处理ANN输入时都会执行强MAC。在处理SNN输入时,当积分时间窗口的长度大于1时,树突也会执行MAC;如果这个时间窗口小于1,则树突只执行加法运算并绕过乘法器;如果没有接收到脉冲,则树突会跳过所有操作。
Unified routing infrastructure. FCore的互连共享相同的路由基础设施,以统一格式传输路由数据包。pre-soma可以根据胞体配置将输出打包成SNN或ANN数据包,而post-axon根据其轴突配置将路由数据包解析为SNN或ANN格式。
Hybrid configuration. 在网络层面,除了构建传统的单范式ANN或SNN,天机网络还提供了两个粒度级别的混合建模。在粗粒度级别,我们可以将一些FCore配置为ANN模式,而将其他FCore配置为SNN模式,以分别执行ANN和SNN。通过这种方式,我们可以在同一个硬件平台上同时实现ANN和SNN,同时运行,而无需使用各种芯片构建异构系统。这也简化了电路板上片外通信接口的设计,因为天机使用了统一的数据包格式和路由基础设施。在细粒度级别,我们可以配置以混合模式工作的FCore (ANN中的轴突和SNN中的胞体,反之亦然),以构建具有混合信号编码的网络。
需要注意的是,为了实现特定的目标应用,轴突和胞体的工作模式在初始配置后是固定的,在随后的执行过程中没有任何模式切换。混合模式下的信号转换不需要额外的开关电路和开销,因为它自然是在FCore的关键数据路径上执行的。
Architecture design. FCore架构示意图如图1所示。天机的跨范式计算是通过共享树突、可独立重构的轴突和胞体以及统一的互联基础设施来实现的。
在树突块中,处理神经元被分成多个组(例如,16组)。这些组串联运行,组内的神经元在运行期间并行执行。在树突模块中,有16个8位乘法器和16个24位累加器来支持向量矩阵乘法(VMM)运算,它们由ANN和SNN模式共享。在ANN模式下,树突模块在每个时钟周期同时从轴突模块读取一个输入,并从突触存储器中读取16个8位权重,然后同时为共享相同轴突数据的16个神经元执行16个MAC。每个神经元以 8 位精度完全执行 256 次乘法运算,并以 24 位精度执行相同数量的累加。在SNN模式下,当控制历史脉冲积分持续时间的时间窗口长度(Tw)大于1时,乘法器和累加器的使用方式与ANN模式相同;否则,轴突模块仅输出1位脉冲,树突模块跳过乘法器。
轴突和胞体模块对于混合操作至关重要。如前所述,它们可以在ANN和SNN模式之间灵活独立地重新配置。在ANN模式下,轴突内存分为两个块,用作乒乓缓冲区。在SNN模式下,两个缓冲区合并为一个完整的块,以在具有可调持续时间的历史时间窗口内存储脉冲模式。额外的内存用于以乒乓方式缓冲最新的脉冲。此外,还实现了时间衰减的时间因子计算器。
在ANN模式下,胞体中的数据以"偏差、激活函数、输出传输"的方式流动。25位偏置激活值被可重新配置的10位滑动窗口截断。然后在每个FCore中应用具有10位条目和8位输出的可重新配置LUT,以实现任意激活函数。在SNN模式下,数据流变为"潜在泄漏、脉冲生成、输出传输"。截断25位膜电位(具有固定或自适应泄漏),然后与24位阈值进行比较以确定是否发放了脉冲。如果发放了脉冲,则支持多种膜电位重置模式。所有内存都在两种模式之间共享,用于存储输入/输出或突触权重、偏差、LUT、泄漏和阈值等参数。
胞体输出被打包到路由数据包中。对于interFCore传输,ANN和SNN模式共享相同的路由数据包格式,由控制、地址和数据段组成。控制段判断输入是否为SNN模式下的抑制信号。地址段包含目标FCore和存储单元地址。数据段在ANN模式中传达8位激活,或者在SNN模式中不传达任何信息(数据包本身代表脉冲事件33)。一旦接收到,后轴突根据轴突配置将数据包解析为ANN或SNN信号。神经元的控制和地址段存储在每个路由器的可重新配置的1千字节(KB)路由LUT中,具有五个通信通道:本地、东部、西部、南部和北部。
天机采用2D-mesh多核架构分层构建大型网络(core-chip-board-system)。除了正常的P2P路由方案3,还设计了一个相邻多播(AMC)路由方案来扩展fan-out。当一个FCore配置为AMC路由模式时,接收到的数据包根据配置的组播方向和距离传递到下一个FCore。这样,多个FCore 可以通过路由中继接收副本。
天机还灵活支持更多特殊操作。(1) 非线性积分:除了动态输入向量和静态权重矩阵之间的MACs,树突模块还可以进行动态输入向量之间的运算。(2) 胞体合作:相邻的胞体可以合并成一个更强的胞体,积累每个胞体的所有积分,从而在不使用额外FCore的情况下扩展 fan-in。(3) 三元突触:天机通过将每个突触的位宽减少到两个来支持三元神经网络,然后突触的数量相应增加。(4) 扩展网络的连接扩展,包括首先通过上述FCore内胞体协作或FCore外层级集成进行fan-in扩展;其次,通过神经元复制或多播路由方案进行fan-out扩展。
Chip specification. 天机芯片采用28纳米高性能低功耗(HLP)技术制造。扩展数据图2显示了布局、物理图片和测试板。一个天机芯片由156个FCore组成,并利用了权重共享技术3,35。权重指数(M)和fan-in/fan-out (N)的数量分别设置为32和256,导致每个FCore中的静态随机存取存储器(SRAM)的总数约为22 KB。扩展数据表2总结了天机芯片的配置和性能,并与现有的神经网络平台进行了比较。在300 MHz的时钟频率和0.85 V的供电电压下,天机芯片在ANN模式和SNN模式(Tw = 1)下每个FCore的典型功耗分别为6.1 mW和5.5 mW。天机需要5050个时钟周期(300 MHz时一个时钟周期为16.8 μs)来完成一轮计算和通信,这反映了最小的相位延迟。
Network deployment. 天机在网络部署方面提供了极大的灵活性。具体来说,大多数脉冲和非脉冲神经网络可以由相同的基本拓扑层构建,包括全连接层、卷积层、池化层和循环层。在网络部署期间,权重被划分并固定到FCore的突触内存中,在初始化后给定固定的工作模式和静态网络拓扑,这些内存保持不变并且不需要重新加载。为了平衡处理吞吐量和资源开销,天机支持两种映射方案:展开映射和折叠映射(扩展数据图3)。
展开映射方案将所有拓扑转换为完全连接的结构,无需资源重用。执行VMM操作的FCore通过多播路由策略共享输入,并且还需要其他用于累积部分和(称为reduce操作)的FCore。对于CANN,微分动力学被转换为差分方程,类似于LSTM的迭代格式。除了矩阵运算,向量运算(例如,在CANN中生成脉冲发放率或在LSTM中更新单元/隐藏状态)可以通过非线性树突积分来实现。另一方面,支持折叠映射方案,以减少非脉冲卷积的资源开销,具有大量数据重用和历史信息的独立性。它需要两种类型的FCore:缓冲FCore和计算FCore。权重沿特征映射的行维度在卷积中共享,这些特征映射驻留在突触内存中以供重用。在随后的计算FCore中执行的每个卷积操作之前,输入相应地使用缓冲区FCore逐行排列。通过这种方式,通过在每个阶段生成一个输出行来对卷积进行流水线化,并且这种逐行流式处理可以容忍具有过多行的CNN。
System support. 受计算机系统层次结构的启发,天机的软件工具链包含与主机相似的层级,以方便应用程序,例如用于编程的统一抽象和用于映射的自动编译器。该软件支持SNN和ANN模式下的应用程序。对于SNN,它支持两种训练方法:间接训练和直接训练。间接训练使用流行的深度学习框架使用反向传播训练ANN模型,然后将其转换为对应的SNN36。直接训练使用新兴的时空反向传播算法直接训练SNN模型。对于非脉冲人工神经网络,除了手动修改和映射现有网络的通用工作流程外,我们的编译器还可以自动将预训练模型转换为满足天机硬件约束的等效网络,从而将应用程序与目标硬件解耦。
Single-paradigm evaluation. 在此,我们详细介绍了用于评估图3d中的单范式神经网络的基准。对于SNN,我们使用了带NMNIST数据集的全连接网络38。ON型和OFF型脉冲输入数据的维度均为(34 × 34) × 2 = 2312,网络结构为2312-800-10。对于MLP,我们在ImageNet数据集41上使用了AlexNet (9216-4096-1000)39和VGG16 (25088-4096-1000)40的全连接层。对于CNN,我们在MNIST数据集42上使用LeNet-variant34网络,在CIFAR10数据集44上使用VGG843网络,在ImageNet数据集上使用AlexNet/VGG16/ResNet1817网络。对于LSTM,我们使用了两个自定义网络,在WikiText-2数据集45上具有1024个单元的一个隐藏层,在Tiny-Shakespeare数据集46上使用两个512个单元的隐藏层。报告了同一结构类别下多个网络的平均性能。使用脉冲发放率编码方案的直接训练来训练脉冲模型,使用8位权重和激活的量化训练来训练非脉冲模型。
对于小规模网络,包括图3e中的ANN/SNN混合示例(结构为input-20C3-AP2-20C2-AP2-10C2-10)和自行车实验中的所有模型,我们直接测量了准确度,测试板上的延迟和功率。我们在一个周期精确的模拟器中运行超过现有资源的大型网络,例如图3d中的那些,其精度和延迟可以与硬件一一对应。这些情况下的功率估计是根据单个芯片的测量结果推断出来的,包括泄漏功率和有功功率。在模拟中,我们放宽了两个制造成本限制:我们为完整的突触去除了权重共享技术,并忽略了芯片间通信开销,因为很容易将更多FCore集成到一个芯片中以适应更大的网络3。Titan-Xp GPU结果的编程框架是Pytorch48(SNN、MLP、CNN)和Torch (LSTM)。对于LSTM,我们使用DeepBench49的基准测试来衡量运行性能。对于推理任务,批量大小按照50建议的设置为1。
Implementation of a hybrid network. 我们使用与图3e相同的网络结构,严格比较了单范式(仅ANN或仅SNN)和细粒度跨范式(ANN/SNN混合)实现之间的性能。基准数据集是MNIST。除了对仅ANN和仅SNN模型使用上述训练方法外,我们还使用了从预训练SNN模型改编的混合模型。对于仅SNN和混合模式,原始像素值通过伯努利采样转换为脉冲事件。在混合模式网络中,混合层使用"SNN输入与ANN输出"FCores来整合SNN脉冲并生成ANN信号(高精度中间膜电位),然后使用"ANN输入与SNN输出"FCores累积这些ANN信号并再次发放SNN脉冲。在此示例中,仅ANN、仅SNN和混合模型都使用展开映射方案,并且为简单起见,仅将最后一个卷积层配置为混合模式。
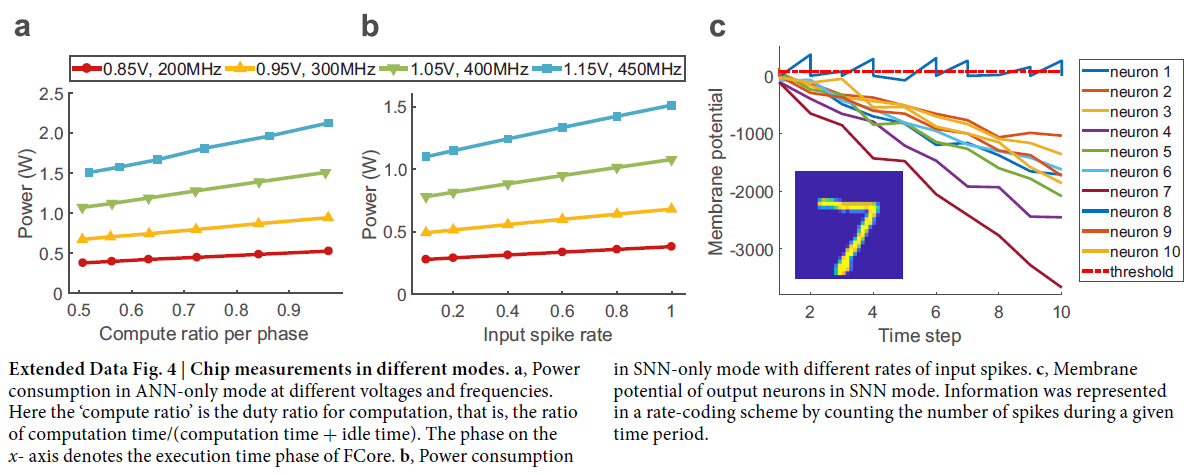
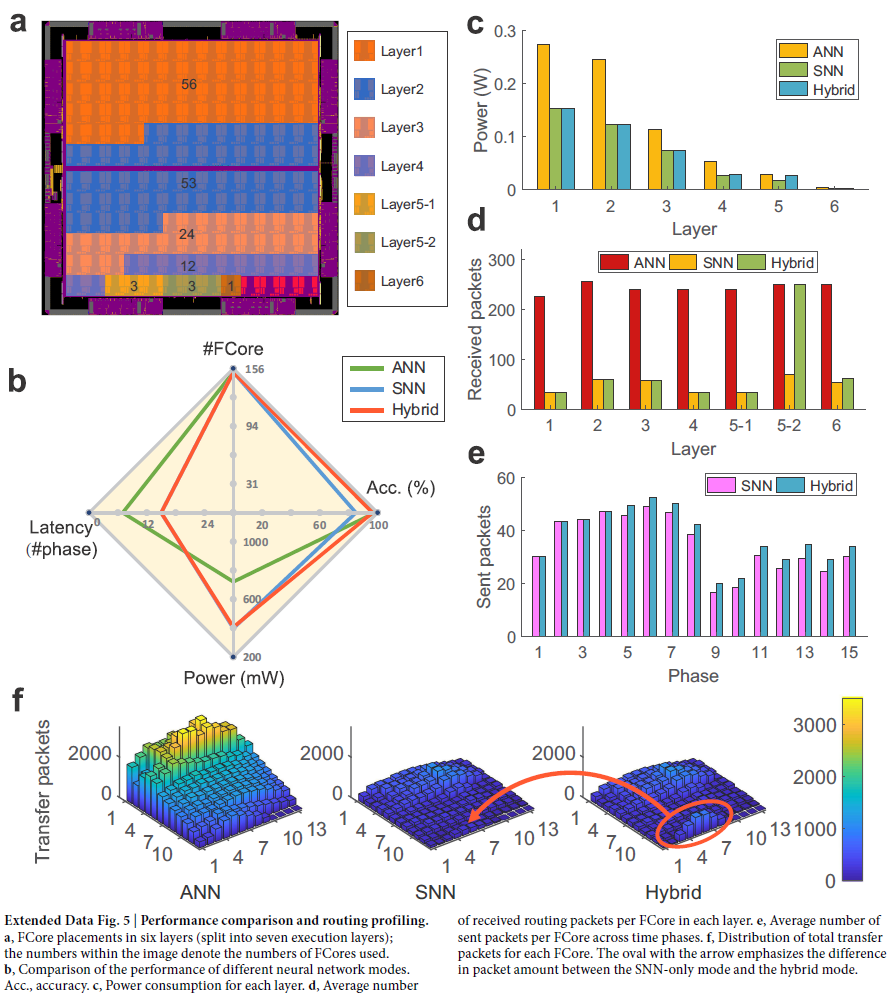
扩展数据图4, 5给出了不同配置模式和详细路由分析之间的综合比较。混合模型在纯SNN模型之外引入的额外硬件成本可以忽略不计,混合模型和纯SNN模型的成本都远低于计算密集型纯ANN模型的成本。此外,由于它避免了在输入数量超过神经元的fan-in限制时由二值脉冲引起的通信过程中的精度损失,因此混合模型继承了仅ANN模型的精度优势。在这个例子中,混合范式提供了一种有效的方式来结合纯SNN模型和纯ANN模型的优点,从而实现整体高性能。总之,天机的混合范式可以根据实际应用的要求,如低功耗、高速、高精度或整体高性能,构建各种ANN和SNN组合。
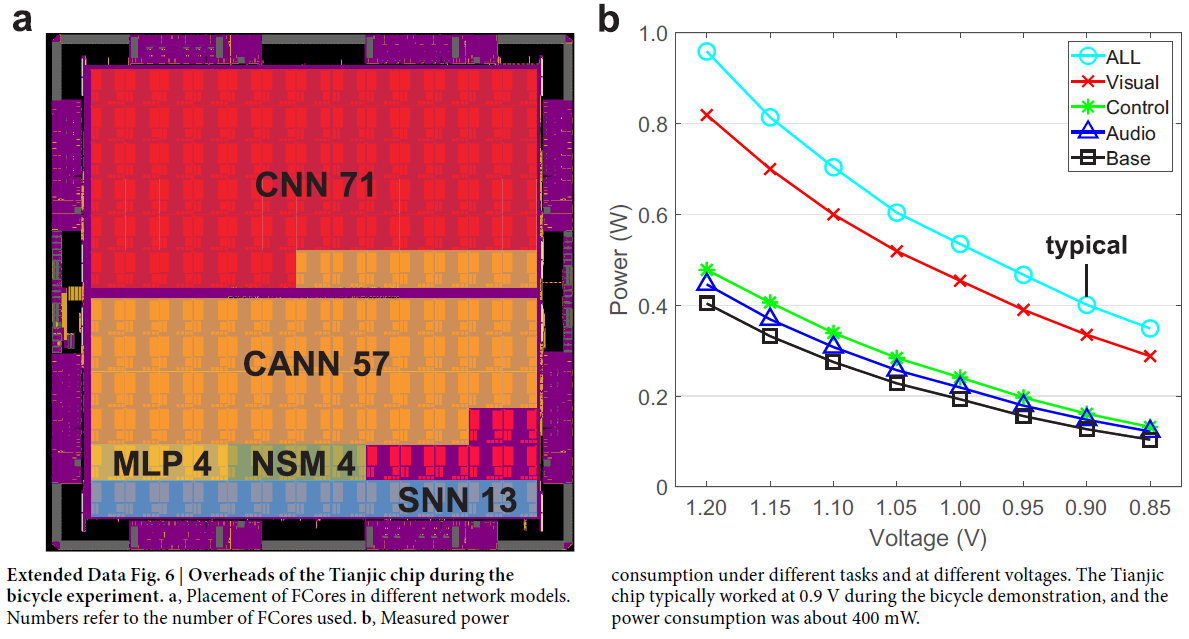
Unmanned bicycle demonstration. 详细的网络拓扑在扩展数据表3中列出。模型大小经过调整和优化,用于在单个天机芯片上演示系统功能。数据预处理在ARM处理器上进行,所有模型在天机上实现前都经过量化训练。 这些网络的映射结果和测量的功耗显示在扩展数据图6中。
来自网络摄像头的每一帧都被重新缩放为70 × 70灰度图像作为CNN输入,并在根据CNN模型生成的初始边界框作为输入注入到CANN之前进行剪辑。对于CANN,我们应用了一个修改后的模型,该模型减少了高斯凸点范围之外的远程连接。我们使用梅尔频率倒谱系数(MFCC)51方法将从麦克风获得的音频信号转换为具有不同频率的51维特征。然后,我们应用高斯总体编码策略52将每个频率特征编码为10个脉冲单元。我们采用基于LIF53神经元的全连接结构来构建上述直接方法训练的SNN模型。七个输出神经元代表六个指令命令和一个噪声情况。对于姿态和运动控制,我们选择了惯性测量单元(IMU)产生的五个信号。将最后六分之一时间步长的信号连接起来形成一个30维向量作为MLP的输入。我们训练了MLP网络来模仿几个比例积分微分控制器在不同速度(从低到高)下的输出。输出的目标旋转角度被发送到电机控制器以调整转向以保持平衡。此外,电压系数被直接发送到另一个电机(后轮)控制器以调节速度。
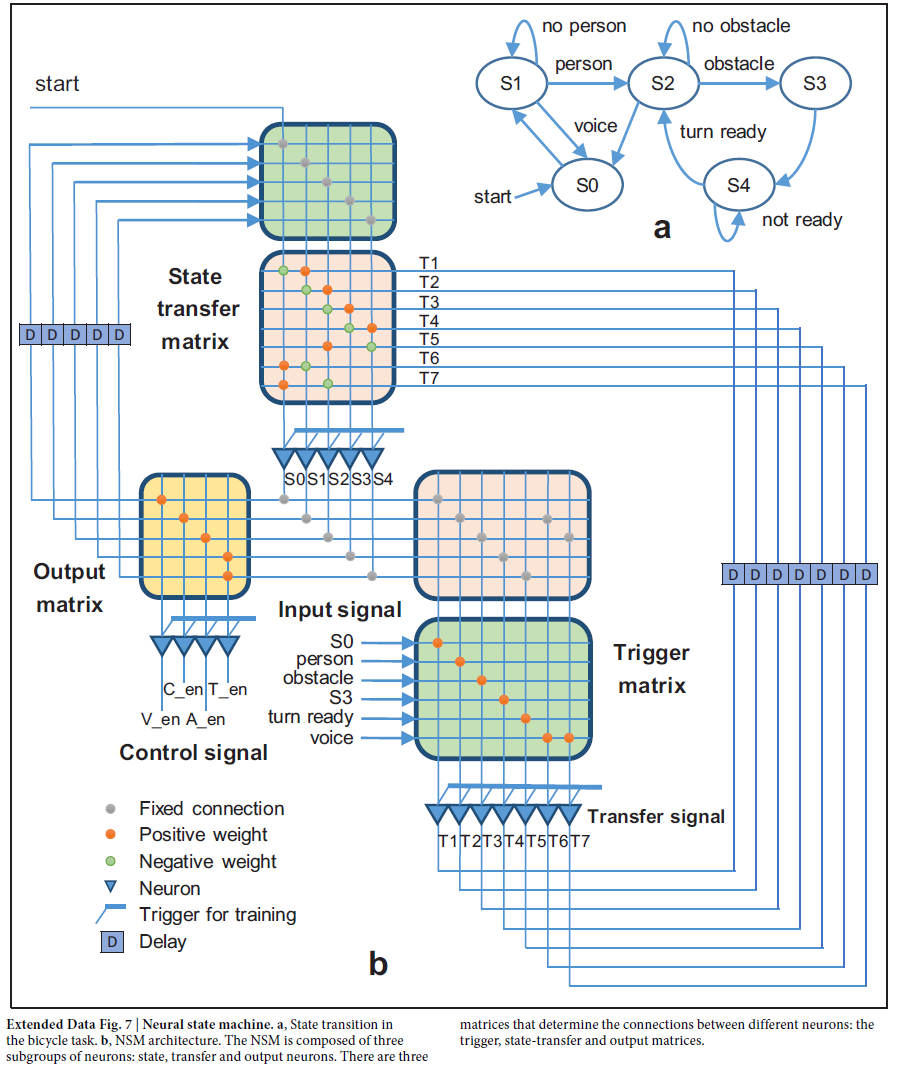
受先前工作的启发,我们设计了一个基于SNN的有限神经状态机(NSM;扩展数据图7)来整合上述不同神经网络的输出。决策模块(即NSM)和动作模块(即MLP)之间的FCore以混合模式(SNN输入和ANN输出)工作,其中包含胞体LUT中的轨迹模式以转换动作信号(脉冲)转化为目标倾角序列(实际值)。通过这种方式,NSM可以引导自行车实现强制转弯(语音命令)或避障。NSM模型的权重是按照离线脉冲时序依赖可塑性(STDP)类规则进行训练的。
Data availability
我们用于基准测试的数据集是公开的,如正文和相关参考文献中所述38,41,42,44-46。训练方法见相关参考文献36,37,47,54。文本中详细介绍了用于模拟和测量的实验设置。支持本研究结果的其他数据可根据合理要求从相应作者处获得。
Code availability
用于软件工具链和自行车演示的代码可向通讯作者合理索取。






 浙公网安备 33010602011771号
浙公网安备 33010602011771号