Human-level control through deep reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
 NATURE, no. 7540 (2015): 529-533
NATURE, no. 7540 (2015): 529-533
Abstract
强化学习理论在动物行为上,深入到心理和神经科学的角度,关于在一个环境中如何使得智能体优化他们的控制,提供了一个正式的规范。为了利用强化学习成功的接近现实世界的复杂度的环境中,然而,智能体遇到了一个难题:他们必须从高维感知输入中得到环境的有效表征,然后利用这些来将过去的经验应用到新的场景中去。显著地,人类和其他动物看起来可以通过一个和谐的智能体和层次感知处理系统的有效组合进而解决这个问题。前者通过丰富的神经数据解释了由
METHODS
Preprocessing. 直接处理原始的Atari 2600帧(图片像素为210 x 160,调色板有128个颜色),可能在计算和内存需求方面要求很高。我们为了降低输入的维度,采取了一个基础的预处理步骤,用Atari 2600仿真器来进行人为处理。首先,为了编码单张图像,我们采用当前编码帧和前一帧每一个像素点色彩值的最大值。移除闪烁是很有必要的,因为一些物体仅仅出现在奇数帧,而有一些则只出现在偶数帧,由于有限数量的sprites Atari 2600导致的artefact会立马显现。其次,我们然后从RGB帧中提取Y通道,也就是经常说的亮度,并将其重新缩放为84 x 84。下面描述的算法1中的函数Φ将此预处理应用于m个最近的帧并将它们堆叠起来以生成Q函数的输入,其中m = 4,尽管该算法对m的不同值鲁棒(例如,3或5)。
Code availability. 源代码可以在以下网址获得:https://sites.google.com/a/deepmind.com/dqn (仅用于非商业用途)。
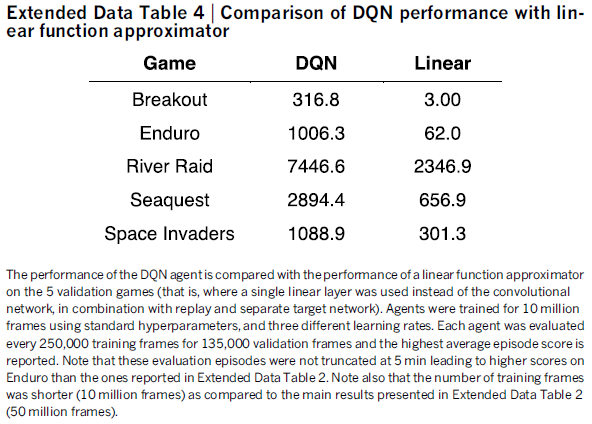
Model architecture. 利用神经网络,有好几种不同的方法来参数化Q。因为Q映射了历史-动作对到它们的Q值,历史和动作已经在之前的方法中被用于神经网络的输入。这种结构的主要缺点是:一个单独的前向传播需要计算每一个动作的Q值,导致计算代价和动作的数量成比例上升。我们则使用这样的一个结构,即:每一个可能的动作有一个单独的输出,仅仅将状态表征输入给神经网络。输出对应了每一个动作为每一个状态预测的Q值。这种结构的优势是:在一个给定的状态下,对于所有可能动作的Q值的计算,在网络中仅仅需要一个前向传播即可。
图1中展示的结构,给出如下的描述:传入给神经网络的输入是预处理映射完毕后的84 x 84 x 4的图像。第一个隐层:卷积核大小为8 x 8,然后有32个filter,步长为4,后面跟一个非线性整流器。第二个隐层:卷积核大小为4 x 4,然后有64个filter,步长为2,后面跟一个非线性整流器。第三个卷积层:64个filter,卷积核大小为3 x 3,步长为1,后面也跟着一个非线性整流器。最后的隐层:一个全连接层,由512个整流单元构成。输出层:一个全连接层,每一个有效地动作对应一个输出。在我们考虑的游戏中,有效动作的数量从4~18之间变换。
Training details. 我们对49个Atari 2600游戏进行了实验,其中所有其他可比方法的结果都可用。在每个游戏上训练了不同的网络:所有游戏都使用了相同的网络架构、学习算法和超参数设置(参见扩展数据表1),这表明我们的方法足够鲁棒,可以在只包含最少的先验知识的情况下处理各种游戏(见下文)。虽然我们在未修改的游戏上评估了我们的智能体,但我们仅在训练期间对游戏的奖励结构进行了一项更改。由于游戏与游戏之间的分数等级差异很大,我们将所有正奖励剪裁为1,将所有负面奖励剪裁为-1,而保持0奖励不变。以这种方式削减奖励限制了误差导数的规模,并使在多个游戏中使用相同的学习率更容易。同时,它可能会影响我们的智能体的性能,因为它无法区分不同量级的奖励。对于有生命计数器的游戏,Atari 2600模拟器还会发送游戏中剩余的生命数,然后用于在训练期间标记一个回合的结束。
在这些实验中,我们使用了RMSProp(参见http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf)算法,小批量大小为32。训练期间的行为策略是ε-greedy,其中ε在前一百万帧中从1.0线性退火到0.1,之后固定为0.1。我们总共训练了5000万帧(即总共大约38天的游戏体验),并使用了100万最近的回放缓存帧。
按照之前玩Atari 2600游戏的方法,我们还使用了一种简单的跳帧技术。更准确地说,智能体在第k帧而不是每一帧上查看并选择动作,并且在跳过的帧上重复其最后一个动作。因为向前运行模拟器一步需要比让智能体选择一个动作少得多的计算,所以这种技术允许智能体玩大约k倍的游戏而不会显著增加运行时间。我们在所有游戏中都使用k = 4。
所有超参数和优化参数的值都是通过对Pong、Breakout、Seaquest、Space Invaders和Beam Rider游戏进行非正式搜索来选择的。由于计算成本高,我们没有执行系统的网格搜索。这些参数然后在所有其他游戏中保持固定。所有超参数的值和描述在扩展数据表1中提供。
我们的实验设置相当于使用以下最少的先验知识:输入数据包括视觉图像(促使我们使用卷积深度网络)、特定于游戏的分数(没有修改)、动作数量,尽管不是它们的对应关系(例如,向上"按钮"的规范)和生命计数。
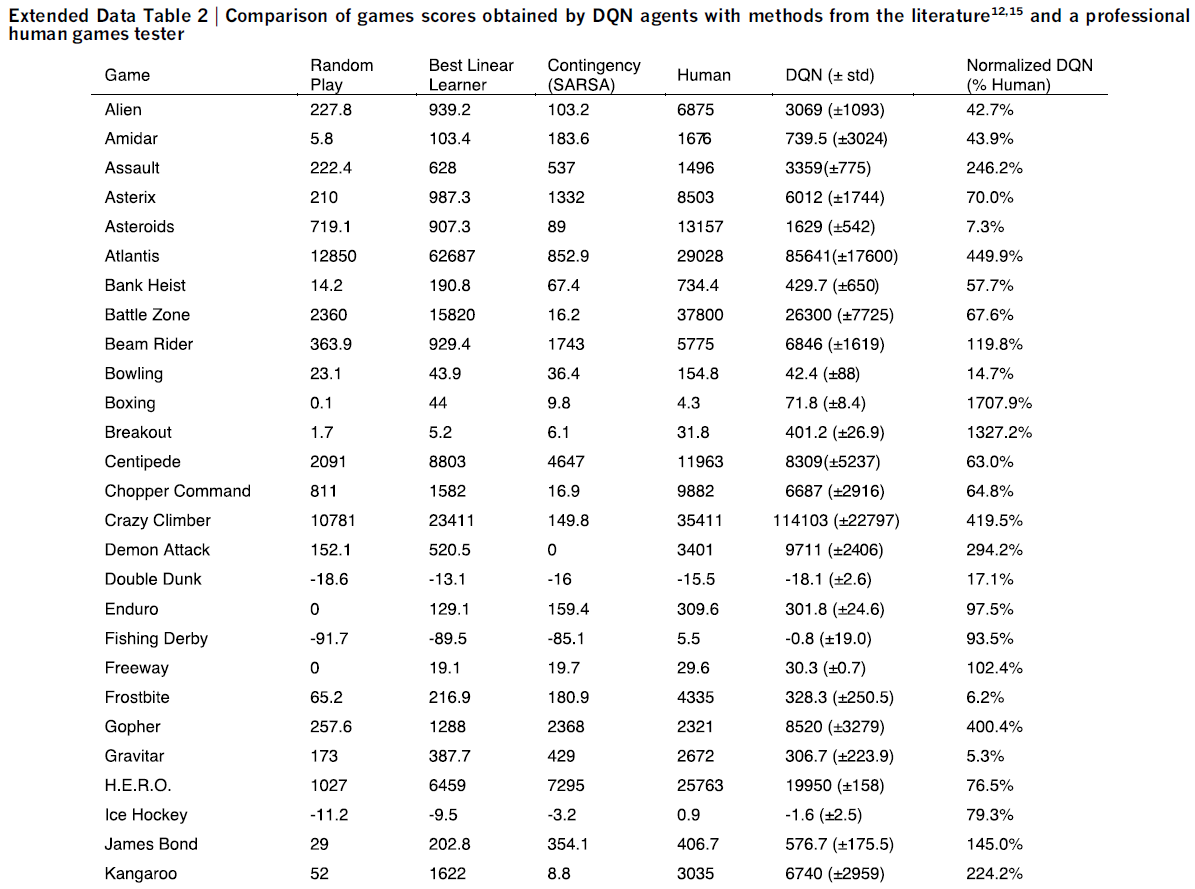
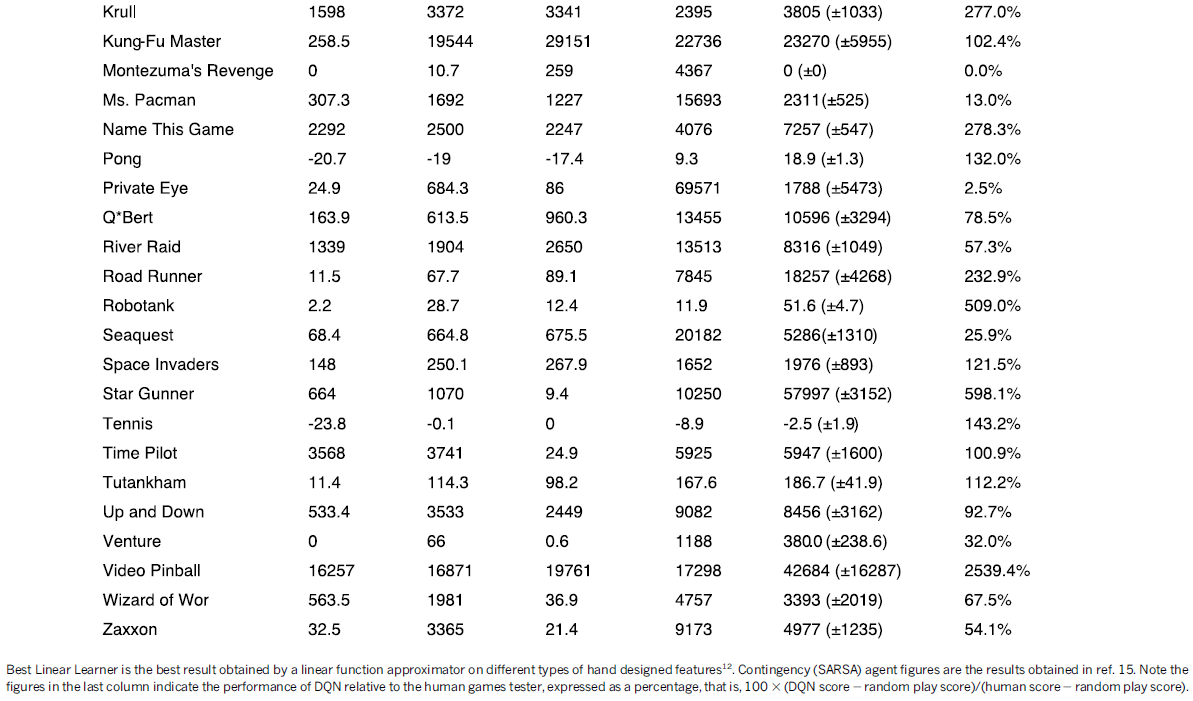
Evaluation procedure. 通过使用不同的初始随机条件('noop';参见扩展数据表1)和ε-greedy策略(ε=0.05),通过玩每个游戏30次,每次最多5分钟来评估经过训练的智能体。采用此程序是为了最大程度地减少评估过程中过拟合的可能性。随机智能体用作基准比较,并选择10 Hz的随机动作,每六帧重复一次,在中间帧上重复其最后一个动作。10 Hz大约是人类玩家可以选择"开火"按钮的最快频率,并且将随机智能体设置为该频率可避免在少数游戏中出现虚假基准分数。我们还评估了选择动作的随机智能体的性能60 Hz(即每一帧)。这产生的影响很小:仅在六个游戏(Boxing、Breakout、CrazyClimber、Demon Attack、Krull和Robotank)中将归一化DQN的性能改变了5%以上,并且在所有这些游戏中,DQN的性能都远远超过了专家级人类。
专业人类测试员使用与智能体相同的模拟器引擎,并在受控条件下进行游戏。不允许人类测试员暂停、保存或重新加载游戏。与最初的Atari 2600环境一样,模拟器以60 Hz运行并且音频输出被禁用:因此,感官输入等同于人类玩家和智能体之间。人类性能是在每场比赛大约2小时的练习后,从每场比赛的大约20个回合持续最多5分钟获得的平均奖励。
Algorithm. 我们考虑智能体与环境交互的任务,在这种情况下是Atari模拟器,在一系列动作、观察和奖励中。在每个时间步骤,智能体从一组合法的游戏动作A={1, ... , K}中选择一个动作at。动作被传递给模拟器并修改其内部状态和游戏分数。一般来说,环境可能是随机的。智能体不会观察到模拟器的内部状态;相反,智能体观察来自模拟器的图像,它是表示当前屏幕的像素值向量。此外,它还会收到一个表示游戏分数变化的奖励rt。请注意,一般来说,游戏分数可能取决于整个先前的动作和观察序列;可能只有在经过数千个时间步骤之后才能收到有关动作的反馈。
因为智能体只观察当前屏幕,任务被部分观察并且许多仿真器状态在感知上是混叠的(也就是说,仅从当前屏幕xt不可能完全了解当前情况)。因此,动作和观察序列st=x1,a1,x2,…,at-1,xt被输入到算法中,然后算法根据这些序列学习游戏策略。假设模拟器中的所有序列都在有限数量的时间步骤内终止。这种形式主义导致了一个庞大但有限的马尔可夫决策过程(MDP),其中每个序列都是一个不同的状态。因此,我们可以对MDP应用标准的强化学习方法,只需使用完整的序列st作为时间 t 的状态表征。
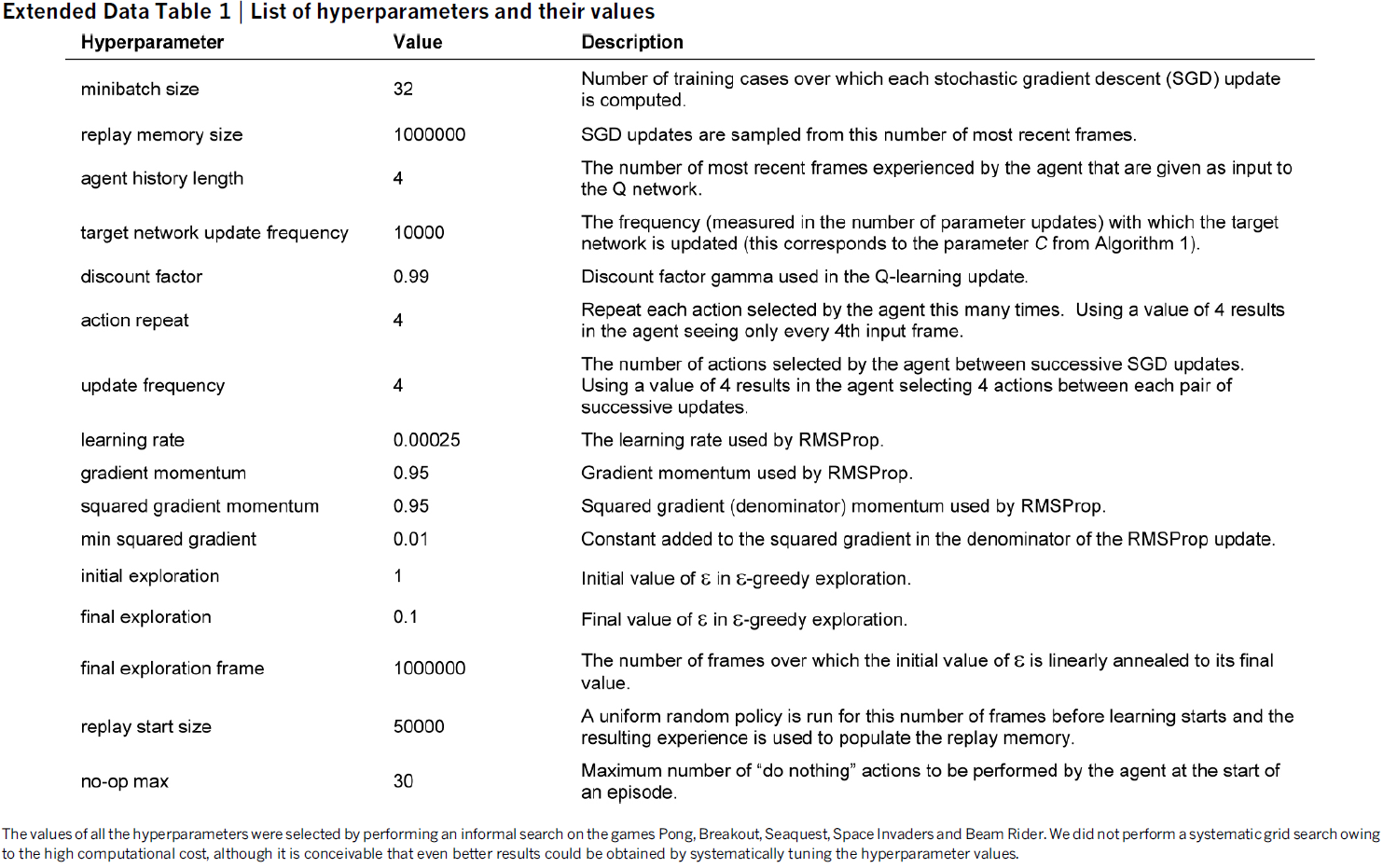
智能体的目标是通过以最大化未来奖励的方式选择动作来与模拟器交互。将时间 t 的未来折扣回报定义为![]() ,其中T是游戏终止的时间步骤。我们将最优动作价值函数Q*(s, a)定义为在看到一些序列 s 然后采取一些动作 a 之后,遵循任何策略可实现的最大期望回报,Q*(s, a) = maxπE[Rt|st=s,at=a,π],其中π是映射序列到动作(或动作分布)的策略。
,其中T是游戏终止的时间步骤。我们将最优动作价值函数Q*(s, a)定义为在看到一些序列 s 然后采取一些动作 a 之后,遵循任何策略可实现的最大期望回报,Q*(s, a) = maxπE[Rt|st=s,at=a,π],其中π是映射序列到动作(或动作分布)的策略。
最优动作价值函数遵循一个重要的恒等式,称为Bellman方程。这是基于以下直觉:如果对于所有可能的动作a'已知序列s'在下一时间步骤的最优值Q*(s, a),那么最优策略是选择动作a'最大化r+γQ*(s', a')的期望值:
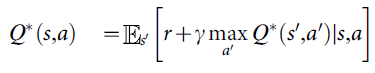
许多强化学习算法背后的基本思想是通过使用Bellman方程作为迭代更新来估计动作值函数,![]() 。这样的值迭代算法收敛到最优动作-价值函数,当i→∞时,Qi→Q*。在实践中,这种基本方法是不切实际的,因为动作-价值函数是针对每个序列单独估计的,没有任何泛化。相反,通常使用函数逼近器来估计动作值函数Q(s,a; θ)≈Q*(s,a)。在强化学习社区中,这通常是线性函数逼近器,但有时会使用非线性函数逼近器,例如神经网络。我们将权重为θ的神经网络函数逼近器称为Q-network。Q-network可以通过在迭代 i 时调整参数θi来训练,以减少Bellman方程中的均方误差,其中最优目标值为r+γ maxa'Q*(s',a')用近似目标值
。这样的值迭代算法收敛到最优动作-价值函数,当i→∞时,Qi→Q*。在实践中,这种基本方法是不切实际的,因为动作-价值函数是针对每个序列单独估计的,没有任何泛化。相反,通常使用函数逼近器来估计动作值函数Q(s,a; θ)≈Q*(s,a)。在强化学习社区中,这通常是线性函数逼近器,但有时会使用非线性函数逼近器,例如神经网络。我们将权重为θ的神经网络函数逼近器称为Q-network。Q-network可以通过在迭代 i 时调整参数θi来训练,以减少Bellman方程中的均方误差,其中最优目标值为r+γ maxa'Q*(s',a')用近似目标值![]() 代替,使用先前迭代中的参数
代替,使用先前迭代中的参数![]() 。这导致一系列损失函数Li(θi)在每次迭代 i 时发生变化,
。这导致一系列损失函数Li(θi)在每次迭代 i 时发生变化,
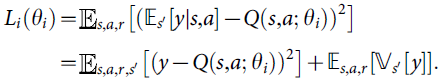
请注意,目标取决于网络权重;这与用于监督学习的目标形成对比,后者在学习开始之前就已确定。在优化的每个阶段,我们在优化第 i 个损失函数Li(θi)时将上次迭代的参数![]() 保持固定,从而产生一系列明确定义的优化问题。最后一项是目标的方差,它不依赖于我们当前正在优化的参数θi,因此可以忽略。根据权重对损失函数进行微分,我们得出以下梯度:
保持固定,从而产生一系列明确定义的优化问题。最后一项是目标的方差,它不依赖于我们当前正在优化的参数θi,因此可以忽略。根据权重对损失函数进行微分,我们得出以下梯度:
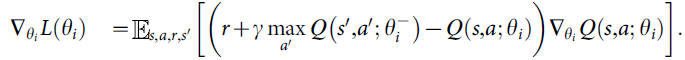
与计算上述梯度中的全部期望不同,通过随机梯度下降来优化损失函数通常在计算上是权宜之计。熟悉的Q-learning算法可以通过在每个时间步骤之后更新权重,使用单个样本替换期望值并设置![]() 。
。
请注意,该算法是无模型的:它直接使用来自模拟器的样本解决强化学习任务,而无需明确估计奖励和转换动态P(r,s'|s,a)。它也是异略的:它学习贪婪策略a = argmaxa'Q(s,a'; θ),同时遵循确保对状态空间进行充分探索的行为分布。在实践中,行为分布通常由遵循贪婪策略的ε-greedy策略选择,概率为1-ε,并选择概率为ε的随机动作。
Training algorithm for deep Q-networks. 算法1给出了训练深度Q网络的完整算法。智能体根据基于Q的ε-greedy策略选择和执行动作。因为使用任意长度的历史作为神经网络的输入可能很困难,我们的Q函数取代由上述函数Φ产生的历史的固定长度表征工作。该算法通过两种方式修改了标准在线Q学习,使其适用于训练大型神经网络而不会发散。
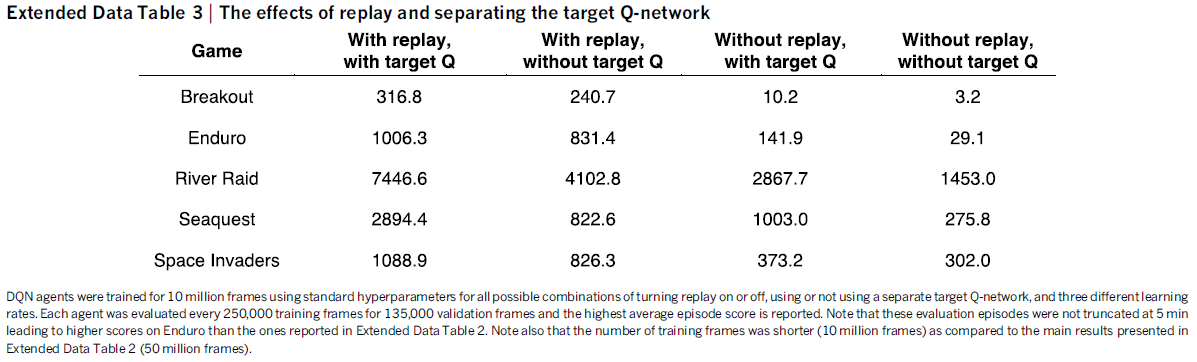
首先,我们使用一种称为经验回放的技术,其中我们将智能体在每个时间步骤的经验et = (st, at, rt, st+1)存储在数据集Dt = {e1, ... , et}中,该数据集汇集了许多回合(当达到终止状态时,回合结束)进入回放缓存。在算法的内部循环期间,我们将Q学习更新或小批量更新应用于从存储样本池中随机抽取的经验样本(s, a, r, s') ~ U(D)。这种方法比标准的在线Q学习有几个优点。首先,经验的每一步都可能用于许多权重更新,从而提高数据效率。其次,由于样本之间的强相关性,直接从连续样本中学习效率低下;随机化样本打破了这些相关性,因此减少了更新的方差。第三,在同策学习时,当前参数决定了参数训练的下一个数据样本。例如,如果最大化动作是向左移动,那么训练样本将以来自左侧的样本为主;如果最大化动作然后向右切换,则训练分布也将切换。很容易看出可能会出现不需要的反馈循环,参数可能会陷入不良的局部最小值,甚至灾难性地发散。通过使用经验回放,行为分布在其许多先前状态上平均,平滑学习并避免参数的振荡或发散。注意,在通过经验回放学习时,需要异策学习(因为我们当前的参数与用于生成样本的参数不同),这激发了Q学习的选择。
在实践中,我们的算法只将最后N个经验元组存储在回放缓存中,并在执行更新时从D随机均匀采样。这种方法在某些方面是有限的,因为回放缓存不区分重要的转换,并且由于有限的内存大小N,总是用最近的转换覆盖。类似地,均匀采样对回放缓存中的所有转换给予同等的重要性。更复杂的采样策略可能会强调我们可以从中学到最多的转换,类似于优先扫描。
旨在进一步提高我们的神经网络方法稳定性的在线Q学习的第二个修改是使用单独的网络在Q学习更新中生成目标yj。更准确地说,每次C更新我们克隆网络Q以获得目标网络![]() 并使用
并使用![]() 生成Q学习目标yj以用于后续C更新到Q。与标准在线Q学习相比,这种修改使算法更稳定,其中增加Q(st, at)的更新通常也会增加所有 a 的Q(st+1, a)并因此也增加目标yj,可能导致策略振荡或发散。使用较旧的参数集生成目标会在对Q进行更新的时间与更新影响目标yj的时间之间增加延迟,从而更不可能出现发散或振荡。
生成Q学习目标yj以用于后续C更新到Q。与标准在线Q学习相比,这种修改使算法更稳定,其中增加Q(st, at)的更新通常也会增加所有 a 的Q(st+1, a)并因此也增加目标yj,可能导致策略振荡或发散。使用较旧的参数集生成目标会在对Q进行更新的时间与更新影响目标yj的时间之间增加延迟,从而更不可能出现发散或振荡。
我们还发现从更新r + γ maxa' Q(s', a'; ![]() ) - Q(s, a; θi)中裁剪误差项到-1到1之间很有帮助。因为绝对值损失函数|x|对于x的所有负值具有导数-1,对于x的所有正值具有导数1,将平方误差剪裁到-1和1之间对应于使用(-1, 1)区间外误差的绝对值损失函数。这种误差裁剪形式进一步提高了算法的稳定性。
) - Q(s, a; θi)中裁剪误差项到-1到1之间很有帮助。因为绝对值损失函数|x|对于x的所有负值具有导数-1,对于x的所有正值具有导数1,将平方误差剪裁到-1和1之间对应于使用(-1, 1)区间外误差的绝对值损失函数。这种误差裁剪形式进一步提高了算法的稳定性。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号