Can a Fruit Fly Learn Word Embeddings?
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Published as a conference paper at ICLR 2021
ABSTRACT
果蝇大脑的蘑菇体是神经科学中研究最好的系统之一。它的核心是一群Kenyon细胞,它们从多种感觉模态接收输入。这些细胞被前部成对的侧神经元抑制,从而产生输入的稀疏高维表征。在这项工作中,我们研究了该网络主题的数学形式化,并将其应用于学习非结构化文本语料库中的单词与其上下文之间的相关结构,这是一种常见的自然语言处理(NLP)任务。我们证明了该网络可以学习单词的语义表示,并且可以生成静态和上下文相关的单词嵌入。与使用密集表征进行词嵌入的常规方法(例如BERT, GloVe)不同,我们的算法以稀疏二值哈希码的形式对词及其上下文的语义进行编码。通过词相似性分析,词义歧义消除和文档分类对学到的表征的质量进行评估。结果表明,果蝇网络不仅可以实现与NLP中现有方法相当的性能,而且,它仅使用了一部分计算资源(较短的训练时间和较小的内存占用)。
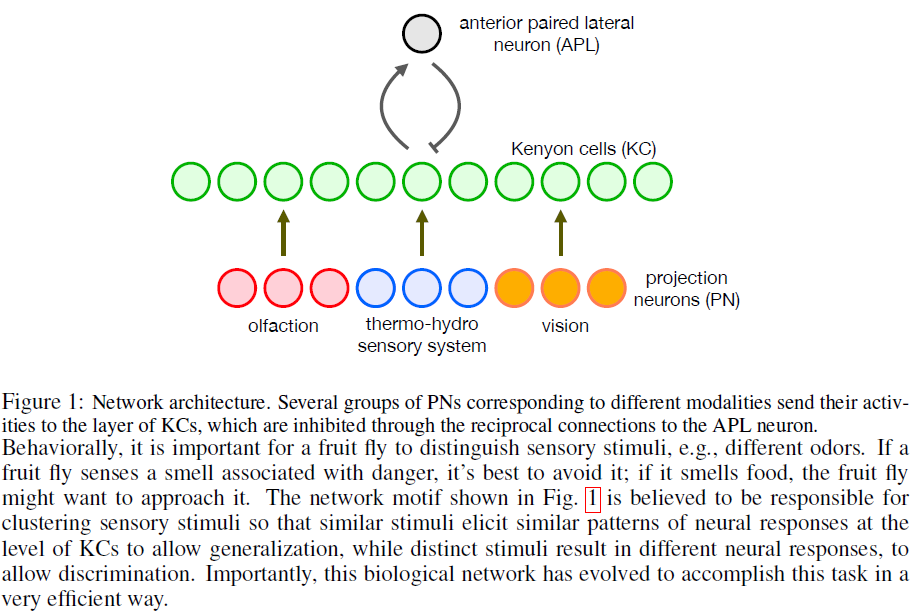
1 INTRODUCTION
深度学习在计算机视觉,自然语言处理和许多其他领域取得了巨大的进步。虽然从生物学中获得了高层启发,但当前一代的深度学习方法并不一定是生物学合理的。这就提出了一个问题,即生物系统是否可以进一步为新的网络结构和学习算法的开发提供信息,从而导致机器学习任务的竞争表现或对智能行为的深入了解。我们的工作受到这种动力的启发。我们研究了从果蝇大脑建立的神经生物学网络主题,并研究了将其重新用于解决NLP中常见的机器学习任务的可能性。我们将此练习视为一个toy模型示例,阐明了对自然发生的算法进行"重新编程"的可能性和行为(嗅觉,视觉和水热感官系统的输入刺激的聚类组合)到原始生物不会自然参与的感兴趣的目标算法(从原始文本中学习单词嵌入)。
蘑菇体(MB)是大脑的主要区域,负责处理果蝇的感官信息。它从一组投影神经元(PN)接收输入,这些输入从几种感觉模态传达信息。嗅觉是主要方式[2],但也有来自PN的输入,它们负责感测温度和湿度[29],以及视觉输入[45; 6]。这些感觉输入通过一组突触权重转发给大约2000个Kenyon细胞(KC)群体[26]。KC通过前对侧(APL)神经元相互连接,后者将强大的抑制信号发送回KC。这种循环网络有效地实现了KC之间的"赢家通吃"竞争,并使一小部分顶部活化神经元沉默[8]。这是我们在本文中研究的网络主题。其原理图如图1所示。KC还将其输出发送到蘑菇体输出神经元(MBON),但是MB网络的这一部分未包含在我们的数学模型中。
在计算语言学中,有很长的传统[19],即使用语言单元的分布特性来量化它们之间的语义相似性,正如JR Firth在名言中所总结的那样:"一个单词的特点是其所拥有的陪伴"[14]。这个想法导致了强大的工具,例如潜在语义分析[9],主题建模[3]和语言模型,例如word2vec[30],GloVe[34],以及最近依赖于Transformer模型[44]的BERT[10]。具体来说,对word2vec模型进行训练以在给定上下文的情况下最大化单词的可能性,GloVe模型利用全局词-词共现统计,而BERT使用深层神经网络专注于预测被掩盖的词(以及下一个句子)。这样,所有这些方法都利用单个单词及其上下文之间的相关性,以学习有用的单词嵌入。
在我们的工作中,我们提出以下问题:单词及其上下文之间的相关性是否可以通过KC的生物学网络从原始文本中提取出来,如图1所示?此外,KC学会的单词表征与通过现有的NLP方法获得的单词表征有何不同?尽管此网络已经发展为处理嗅觉和其他形式的感觉刺激,而不是"理解"语言,但它使用通用算法将输入(来自不同形式)嵌入具有几个理想属性的高维空间,我们将在下面讨论。
我们的方法基于最近的建议,即相互抑制的KC的循环网络可以用作"生物学"模型,以生成投影神经元层上呈现的输入数据的稀疏二值哈希码[8]。有人争论说,从PN层投射到KC层的随机权重矩阵会导致使生成的哈希码局部敏感的高度期望的属性,即,将相似的输入放置在嵌入空间中彼此靠近,并将不同的刺激推远 分开。随后的研究[39]表明,如果从数据中获知从PN到KC的权重矩阵,则与随机情况相比,哈希码的局部敏感性可以大大提高。先前在[37]中也曾探讨过使用带有随机投影的KC网络来进行NLP任务的想法,请参见第7节中的讨论。
从生物学上讲,神经科学界一直在争论这些预测是否是随机的。例如,[5]主张使用随机模型,而[47]则提供了该网络的非随机结构的证据,该结构与出现的气味的频率有关。由于我们的工作目标是建立一个有用的AI系统,而不是模仿生物系统的每个细节,因此即使果蝇可能使用随机投影,我们也采用数据驱动的突触权重策略。正如在[39]中明确证明的那样,学到的突触可导致更好的性能。
我们在这项工作中的主要贡献如下:
1. 受果蝇网络启发,我们提出了一种算法,该算法可以为单词及其上下文生成二值(而不是连续的)单词嵌入。我们系统地评估了该算法在词相似性任务,词义歧义消除和文档分类方面的性能。
2. 我们证明,与连续的GloVe嵌入相比,我们的二值嵌入导致更紧密且更好的概念分离簇,并且与GloVe的二值化版本的聚类特性一致。
3. 我们证明,训练果蝇网络比训练像BERT这样的经典NLP结构所需的计算时间少一个数量级,但代价是分类精度的降低相对较小。
2 LEARNING ALGORITHM
2.1 MATHEMATICAL FORMULATION
2.2 BIO-HASHING
3 EMPIRICAL EVALUATION
3.1 STATIC WORD EMBEDDINGS EVALUATION
3.2 WORD CLUSTERING
3.3 CONTEXT-DEPENDENT WORD EMBEDDINGS
3.4 DOCUMENT CLASSIFICATION
4 COMPUTATIONAL COMPLEXITY
5 DISCUSSION AND CONCLUSIONS
6 ACKNOWLEDGEMENTS
7 APPENDIX A. RELATED WORK.
8 APPENDIX B. TRAINING PROTOCOLS AND HYPERPARAMETER CHOICES.
9 APPENDIX C. COMPARISON WITH BINARIZED GLOVE AND WORD2VEC.
10 APPENDIX D. DETAILS OF TECHNICAL IMPLEMENTATION.
11 APPENDIX E. QUALITATIVE EVALUATION OF CONTEXTUAL EMBEDDINGS.
12 APPENDIX F. DETAILS OF GLOVE RETRAINING


 浙公网安备 33010602011771号
浙公网安备 33010602011771号