Long Short-Term Memory Spiking Networks and Their Applications
摘要:郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

ICONS 2020, July 28–30, 2020, Oak Ridge, TN, USA
LSTM简介:https://zhuanlan.zhihu.com/p/32085405;https://www.jianshu.com/p/95d5c461924c
ABSTRACT
基于事件的神经形态系统的最新进展引起了对SNN的使用和开发的极大兴趣。但是,脉冲神经元的不可微分性使SNN与常规反向传播技术不兼容。尽管在训练常规DNN方面取得了显著进展,但对SNN的训练方法仍然知之甚少。在本文中,我们提出了一种训练循环SNN的新颖框架。类似于RNN在DNN中学习时间序列模型中提供的好处,我们基于LSTM网络开发SNN。我们显示LSTM脉冲网络学习脉冲时间和时序依赖性。我们还开发了一种基于LSTM的SNN中误差反向传播的方法。在基于LSTM的SNN中进行反向传播的已开发结构和方法使他们能够学习长期依赖关系,其结果与传统LSTM相当。代码可在github上找到;https://github.com/AliLotfi92/SNNLSTM
1 INTRODUCTION
DNN的开发和成功训练已在不同的应用领域(例如计算机视觉和机器学习)取得了突破性的成果[19, 21, 33]。尽管神经网络受神经系统中神经元的启发,但众所周知,神经系统中的学习和计算主要是以基于事件的脉冲计算单元为基础的[7]。因此,SNN已被提出以更好地模仿生物神经网络的能力。尽管SNN可以代表生物神经网络的潜在时空行为,但由于训练困难,因此它们受到的关注要少得多,因为一般情况下脉冲无法微分,并且基于梯度的方法不能直接用于训练。
与DNN相似,SNN由多层构成,每层包含几个神经元。但是,它们的功能有所不同,SNN共享脉冲而不是浮点值。
通常,可以将DNN和SNN简化为优化的ASIC和/或使用GPU并行。由于时间稀疏性,SNN的ASIC实现被发现具有更高的能源和资源效率,出现了具有高能效的神经形态芯片,包括Loihi [6],SpiNNaker [10]和其他[27, 28]。 只要能有效地训练它们并以类似于DNN的方式执行,这种能源效率以及相对简单的推理就使SNN具有吸引力。
通过本文,我们将重点放在循环SNN上。与循环DNN相似,循环SNN是一类特殊的SNN,它配备有内部存储器,该存储器由网络本身管理。这种额外的存储使它们能够处理序列数据集。因此,它们在包括语音识别和语言建模在内的不同任务中很受欢迎。
尽管有大量关于训练SNN的文献,但与我们对DNN训练机制的理解相比,该领域(尤其是循环SNN)仍处于起步阶段。SNN训练文献的很大一部分集中在通过一层网络来训练前馈SNN [14, 24]。最近,一些发展使得能够训练多层SNN [31],但是,训练循环SNN仍处于起步阶段。
最近,[31]利用基于核函数的脉冲响应来捕获每个神经元的脉冲序列的时序依赖性。尽管此方法成功捕获了脉冲之间的时序依赖性,但基于核的计算成本很高。此外,需要时序卷积运算,这使其无法有效地应用于循环SNN。
Our contributions. 我们提出了一个基于LSTM单元的设计和训练循环SNN的新框架。每个LSTM单元包括三个不同的门:忘记门帮助消除无用的信息;输入门监视进入单元的信息;输出门形成单元的结果。实际上,LSTM [15]及其变体[13]是RNN的特殊情况,在某种程度上有助于解决梯度消失问题。LSTM被认为特别适合于时间序列和序列数据集。在本文中,我们利用SNN中的这种功能来提出基于LSTM的具有序列学习能力的SNN。在本文中,我们提出了一种新颖的反向传播机制和结构,与现有的循环SNN(可与常规LSTM相当)相比,它可以实现更好的性能。另外,与基于前馈神经网络的核方法相比,我们的方法不需要时序卷积机制,从而为训练SNN提供了一种较低复杂度的训练机制。
通过对各种数据集的经验评估,我们研究了我们提出的结构的性能和动态。首先,我们从toy数据集开始,然后是提供更多结构化时序依赖关系的基准语言建模和语音识别数据集。此外,与使用简单模型和网络的现有文献相比,我们的方法可实现更好的测试准确性。此外,我们还表明,这样的LSTM SNN在较大且更复杂的序列EMNIST数据集上表现良好[4]。最后,我们评估了我们所提出的循环SNN在自然语言生成中的能力,这揭示了SNN的许多有趣应用之一。
2 RELATED WORK
通常,现有的训练SNN的方法可以细分为两类:间接训练和直接训练。SNN的间接训练是指使用现有方法训练常规DNN,然后将训练后的输出关联/映射到所需SNN的那些方法。这样的机制可能相当通用且强大,但是由于获得的SNN严重依赖于相关的DNN,因此可能会受到限制。特别地,[9]提出了一个框架,在该框架中,他们优化了DNN脉冲的概率,然后将优化后的参数传递到SNN中。通过在相关的激活函数中添加噪声[22],限制概要的优势(网络的权重和偏差)[8],以及利用替代的传递函数[26],在此框架上已经有了更多的文献。
为了能够直接训练SNN,SpikeProp [2]提出了一种开创性的监督式时序学习算法。在此,作者通过利用相关的脉冲反应模型(SRM)[11]模拟神经元的动态。特别是,SpikeProp及其关联的扩展[3, 29]使用梯度下降根据实际和目标脉冲时间来更新权重。但是,该方法很难应用于基准测试任务。为了部分解决这个问题,已经开发了对SpikeProp的改进,包括MuSpiNN [12]和弹性传播[23]。最近,[17]提出了一种用于训练SNN的两级反向传播算法,[31]提出了一种用于训练SNN的框架,其中权重和延迟同时得到优化。此外,这些框架为每个神经元应用核函数,这可能是内存密集且耗时的操作,尤其是对于循环SNN。
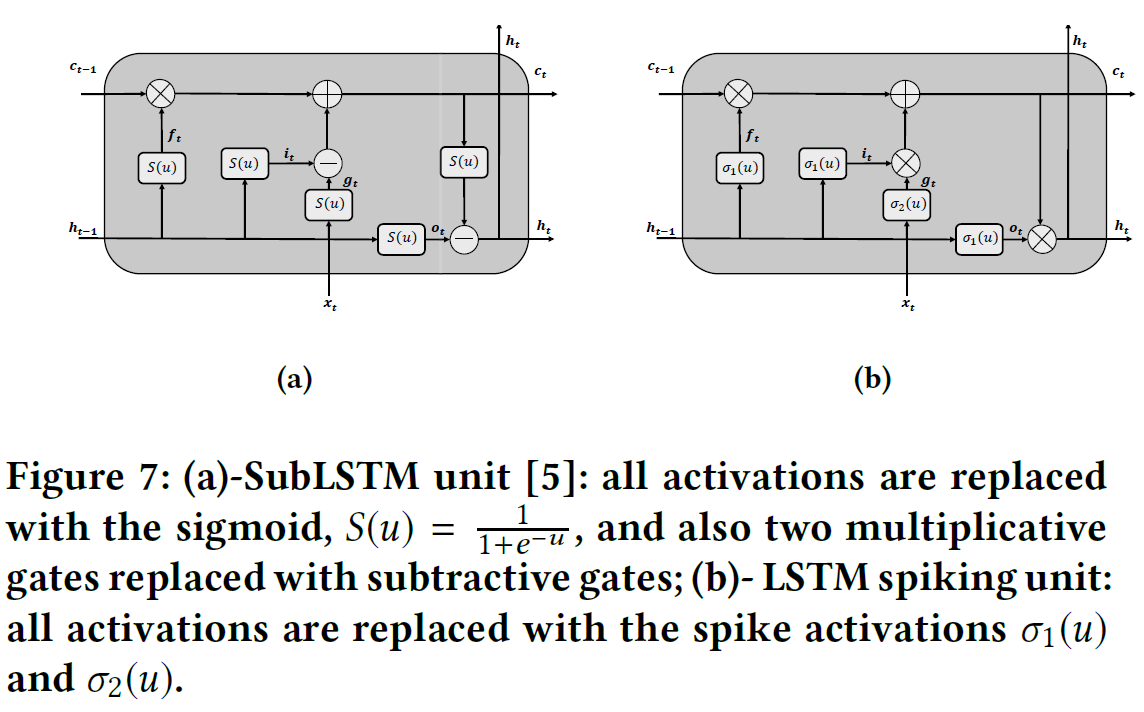
与我们的工作最相关的也许是[1]中的最新工作。类似地,作者提出使用LSTM单位并结合[16]中的算法来确保LSTM单位中的神经元输出1或-1。为了进行训练,他们使用分段线性函数max {0, 1-|u|}来近似脉冲激活的梯度,其中u是激活之前神经元的输出(所谓的神经元膜电位)。但是,在本文中,我们用概率分布松弛了脉冲激活的梯度。这种松弛为每次迭代提供了更精确的网络更新。文献[5]中的作者也研究过重塑LSTM的结构,使其适合皮层回路,这与神经系统中发现的回路相似。他们在LSTM中利用sigmoid函数实现所有激活。此外,[30]是一种间接训练方法,他们首先运行常规的LSTM,然后将其映射为脉冲版本。
有用于训练SNN的受生物启发的方法,包括诸如脉冲时间依赖可塑性(STDP)[32]的直接训练方法。STDP是一种模拟人类视觉皮层的无监督学习机制。尽管这种受生物启发的训练机制令人感兴趣,但它们也难以成为基准,因此,在本文中,我们将重点放在替代直接训练方法上。
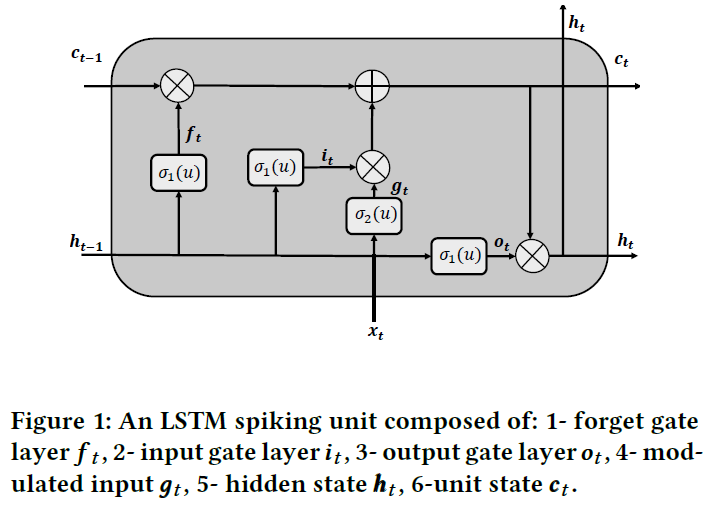
3 OUR METHODOLOGY
3.1 LSTM Spiking Neural Networks
LSTM及其变体是RNN的特殊类别,由于它们在不同的序列处理任务(包括长序列结构,即自然语言建模和语音识别)中的出色表现而受到欢迎。确实,LSTM和一般的RNN能够捕获其输入的时序依赖性,同时还能解决其他结构所面临的梯度消失问题。
因此,LSTM网络是捕获SNN模型的时序依赖性的自然候选。在应用激活之前,神经元的输出值被称为膜电位,神经元n在时间 t 表示为un(t),请参见图2a。
我们在图1中概述了LSTM脉冲单元的主要元素。一个LSTM脉冲单元具有三个相互作用的门和相关的"脉冲"函数,通常将脉冲激活σ1(u)和σ2(u)分别应用于它们各自的相关神经元。函数获取神经元的膜电位un(t),并在每个时间步骤输出或不输出脉冲。
像常规LSTM一样,这种LSTM脉冲处理单元背后的核心思想是单元状态ct,它是单元之间的流水线和信息流的管理器。实际上,这是通过不同的门和层的协作完成的。忘记门ft,决定应该删除哪些信息;输入门it,控制输入单元的信息,输入的另一个辅助层gt由另一个脉冲激活σ2(u)调节。最终,基于输出门ot和单元状态形成单元的输出。更具体地说,给定一组脉冲输入{x1, x2, ... , xT},其门和状态的特征如下:
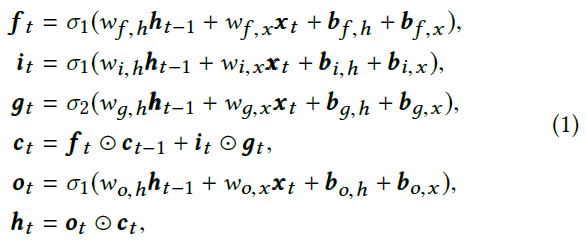
其中⊙表示Hadamard乘积,σ1(·)和σ2(·)是脉冲激活,如果神经元的膜电位分别超过阈值θ1和θ2,则它们将神经元的膜电位un(t)映射为脉冲。在本文中,我们假设两个表达式:1)唤醒模式:这是指神经元产生脉冲的情况,意味着神经元的值为1;2)睡眠模式:如果神经元的值为0。此外,w·, · 和b·, · 分别表示网络的相关权重和偏差。请注意,ft⊙ct−1 + it⊙gt可以取0, 1或2。由于2周围的梯度没有提供足够的信息,因此当该输出为1或2时,我们将其限制为输出1。我们用带有两个值1或≤1的γ来近似此阶跃函数的梯度。请注意,在这一步我们可以采用高斯近似,类似于下一节中的方法,并且我们观察到这种松弛不会影响性能。在实践中,这就是我们在实验中采用的方法。
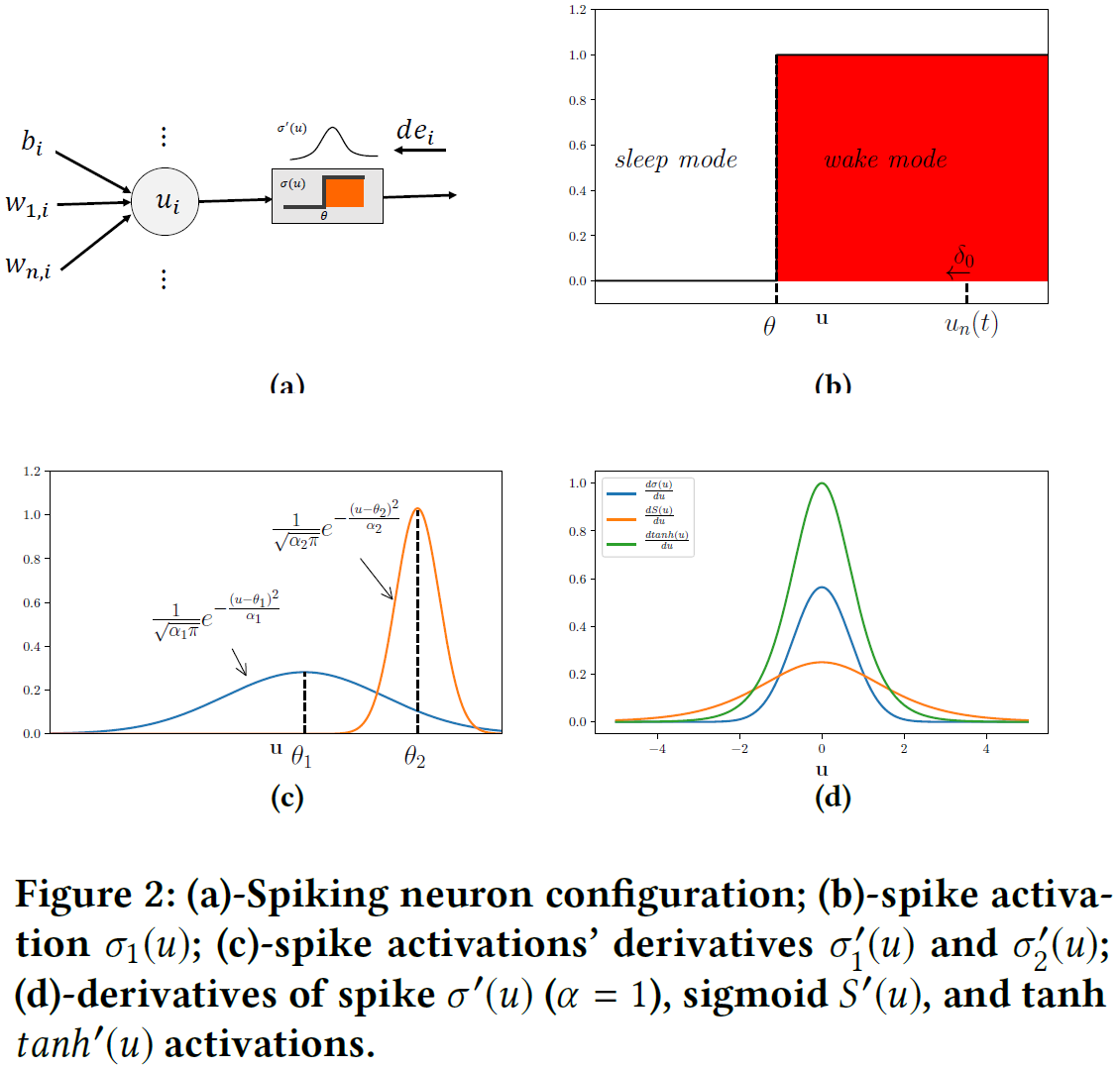
3.2 Enabling Backpropagation in LSTM SNNs
反向传播是SNN中的一个主要问题,即使不是唯一的问题。在本节中,我们继续一个示例。无论激活(σ1(u)或σ2(u))如何,都假设我们以任意随机值δ0扰动神经元的膜电位un(t)。给定un(t),神经元可以处于唤醒模式或睡眠模式。根据激活的阈值(参见图2b),这种扰动可能会切换神经元的模式。例如,在唤醒模式下,如果δ0 < 0且un(t) + δ0 ≤ θ (θ是基于激活的阈值,可以是θ1或θ2),则神经元将被迫进入睡眠模式。这样,我们可以说神经元模式的变化是膜电位与阈值的函数(|u| − |θ|)。因此,如果模式切换,输出关于un(t)的导数与![]() 成比例;否则,σ'(u + δ0) = 0。然而,模式切换的δ0值较小仍然存在问题(这等价于un(t)接近阈值)。误差反向传播将出现梯度爆炸。
成比例;否则,σ'(u + δ0) = 0。然而,模式切换的δ0值较小仍然存在问题(这等价于un(t)接近阈值)。误差反向传播将出现梯度爆炸。
为了解决这个问题,我们提出采用另一种近似方法。考虑概率密度函数(pdf) f(δ),它对应于以δ为随机变量的变化模式的pdf。给定较小的随机扰动δ0,切换模式的概率为![]() ,而保持相同模式的概率为1 − f(δ + δ0)δ0。这样,我们可以捕获σ′(u)的期望值,如下所示:
,而保持相同模式的概率为1 − f(δ + δ0)δ0。这样,我们可以捕获σ′(u)的期望值,如下所示:
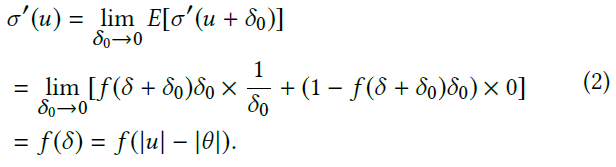
可以看出,激活的导数可以通过适当的对称(关于阈值θ)分布放松,其随机变量δ与神经元膜电位和阈值的差|u| − |θ|成比例。
我们凭经验观察到,这种分布的一个很好的选择是具有适当方差的高斯分布(见图2c)。此外,高斯分布的平滑度使其相对于其他众所周知的对称分布,即Laplace分布,是更好的候选。有趣的是,另一个独特属性是其曲线,该曲线在本质上对反向传播的影响与传统LSTM中的激活类似。换句话说,高斯分布具有与sigmoid和tanh激活的导数相同的形状。此外,我们可以轻松地调整与![]() 和
和![]() 对应的方差,使其具有与传统LSTM中对应的激活相同的形状(参见图2d)。
对应的方差,使其具有与传统LSTM中对应的激活相同的形状(参见图2d)。
3.3 Loss Function Derivative and Associated Parameter Updates
接下来,我们为LSTM脉冲单元的参数开发更新表达式。为此,请考虑输出层为softmax,yt = softmax(wyht + by),并且将损失函数定义为交叉熵损失。因此,损失函数关于LSTM SNN在 t 处的输出yt的导数可以表征如下:
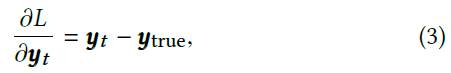
其中ytrue是真实的信号或标签。同样,具有线性输出层和最小二乘损失函数的网络具有相同的梯度。给定这一点和(1)中的表达式,损失函数关于每个门和每一层的输出的导数可以导出如下:附录A中提供了所有其他导数的详细信息。

4 EXPERIMENTS
4.1 Settings and Datasets
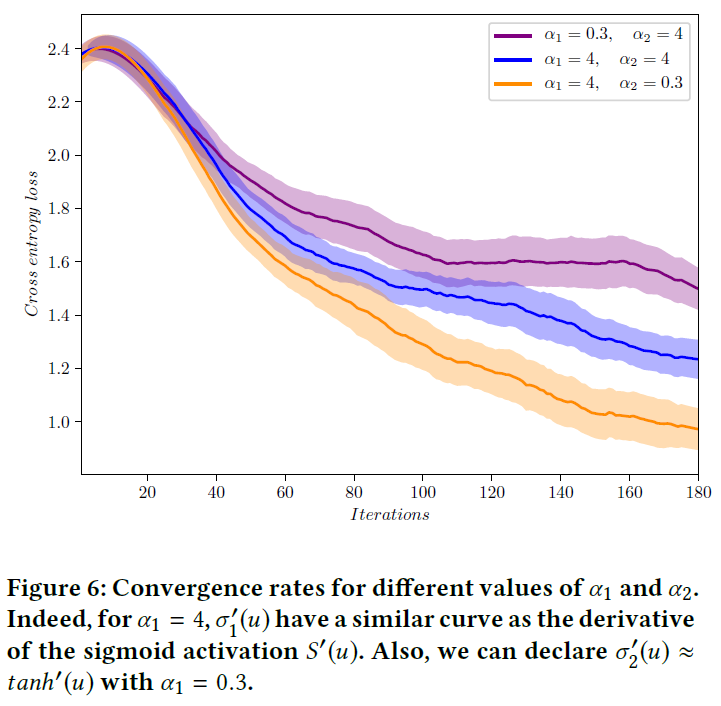
我们针对不同的数据集测试了我们提出的方法。对于所有实验,我们都基于标准正态分布初始化所有权重,并且所有偏差在开始时均初始化为零。另外,使用Adam优化器[18]训练网络,原始论文的学习率为0.001,β1 = 0.9和β2 = 0.999。脉冲激活的阈值已设置为θ1, θ2 = 0.1,这是根据经验优化的。α1和α2分别设置为4和0.3。附录B中提供了有关此选择的更多详细信息。
4.2 Toy Dataset
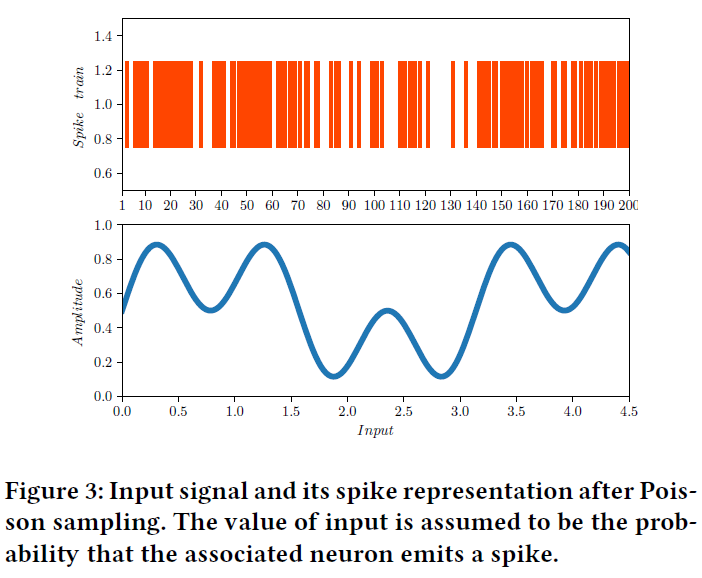
我们首先说明所提出的方法在周期性正弦信号上的性能。我们的目标是证明所提出的结构可以使用脉冲作为输入来学习时序依赖性。因此,我们将原始输入和目标输出设置为f(x) = 0.5 sin(3x) + 0.5 sin(6x) + 1。在这种情况下,任务是根据输入脉冲序列生成预测。为了获得此输入脉冲序列,在对信号进行采样之后,我们使用Poisson过程将采样转换为基于ON和OFF事件的值,其中每个输入的值均显示其发出脉冲的概率,如图3所示。
接下来,我们使用提出的深度LSTM脉冲单元,该单元由一个100个脉冲神经元的隐含层组成,输入大小为20。输出通过大小为1的线性层。损失函数为![]() ,其中yt和
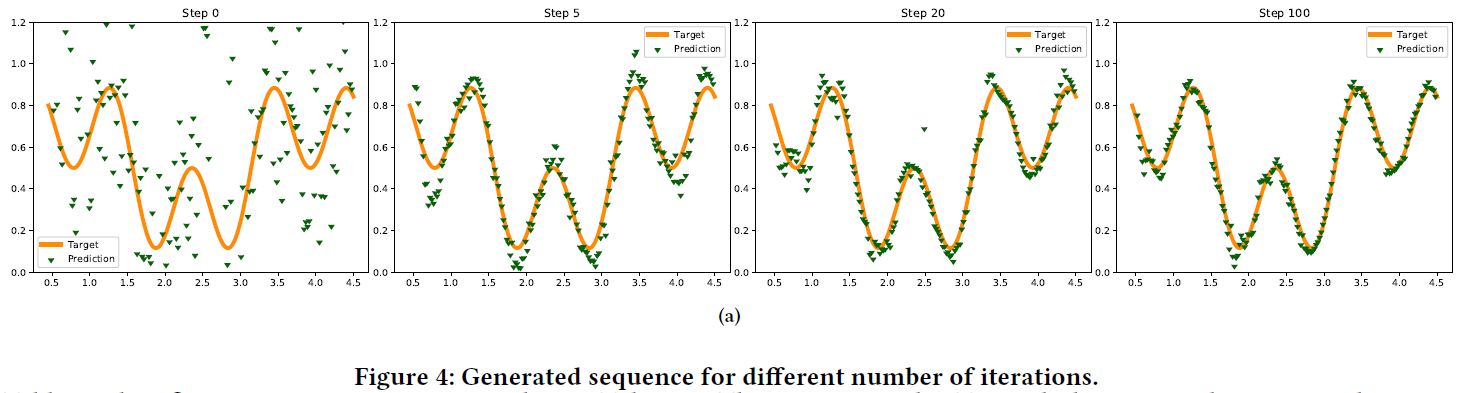
,其中yt和![]() 分别表示实际和预测输出,并且T = 100。因此,我们使用提出的方法反向传播误差。同样,我们根据经验优化α1和α2并将其分别设置为4和0.3 (对于序列MNIST数据集,将更深入地了解这些参数对收敛速度和准确性的影响)。生成的序列及其在不同迭代次数下收敛为真实信号的过程如图4所示。如图所示,网络通过几次迭代就了解样本的依赖性。
分别表示实际和预测输出,并且T = 100。因此,我们使用提出的方法反向传播误差。同样,我们根据经验优化α1和α2并将其分别设置为4和0.3 (对于序列MNIST数据集,将更深入地了解这些参数对收敛速度和准确性的影响)。生成的序列及其在不同迭代次数下收敛为真实信号的过程如图4所示。如图所示,网络通过几次迭代就了解样本的依赖性。
4.3 LSTM Spiking Network for Classification
Sequential MNIST [20]是机器学习研究人员中标准且流行的数据集。数据集由对应于60k训练图像和10k测试图像的手写数字组成。每个图像都是来自10个不同类别的28×28灰度像素。序列MNIST的主要区别在于,网络无法一次获取整个图像(请参见附录图5)。为了将每个图像转换为基于ON和OFF事件的训练样本,我们再次使用Poisson采样,其中每个像素的密度表示其发出脉冲的概率。
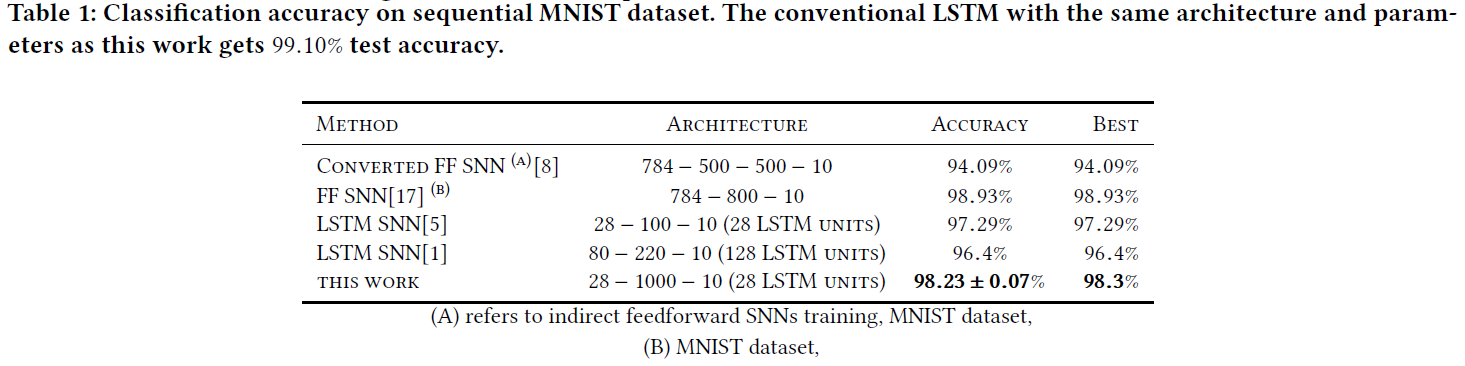
为了使MNIST成为序列数据集,我们在28个时间步骤上训练提出的LSTM脉冲网络,每个时间步骤的输入大小为28 (请参见附录图5),并执行优化并使其运行2000个epoch。表1列出了测试的准确性和相关的误差条。此外,在同一表中还列出了针对序列MNIST的其他最新循环SNN方法和针对MNIST的前馈SNN的结果。
从表1中可以看出,我们对序列MNIST的测试准确度达到98.3%,优于其他基于LSTM的SNN,并且该结果与[17]中提出的前馈SNN所获得的结果相当。应当指出的是,在[17]中,神经元后面跟随着基于时间的核,网络立即获得了整个图像。因此,我们首先注意到基于核的SNN不是瞬时的。通常,这些网络在时间t ∈ [0, T]上连续建模,然后以适当的采样时间Ts进行采样。对于每个时间实例,每个神经元都会进行卷积运算,最后,输出将通过矩阵乘法传输到下一层。对于每个时间实例ts,此过程被重复,![]() 。即使我们提出的算法以离散时间步骤运行,也应注意,与基于核的方法相比,我们模型中的时间步骤数要少得多。确实,对于基于核的方法,应该选择较小的采样时间来保证适当的采样,另一方面,这会增加时间步骤数,从而导致更多的计算成本。例如,对于MNIST数据集,我们的算法所需的时间步骤数为28 (请参见表1),而[31]中基于核的方法则需要350。此外,在功率受限的情况下, 基于核的方法的计算复杂性会使它们成为较不受欢迎的候选。但是,在我们提出的方法中,我们通过在LSTM和SNN之间绘制连接来建模神经元动态,从而消除了对这些核的需求。附录B中提供了有关α1和α2选择的更多信息。
。即使我们提出的算法以离散时间步骤运行,也应注意,与基于核的方法相比,我们模型中的时间步骤数要少得多。确实,对于基于核的方法,应该选择较小的采样时间来保证适当的采样,另一方面,这会增加时间步骤数,从而导致更多的计算成本。例如,对于MNIST数据集,我们的算法所需的时间步骤数为28 (请参见表1),而[31]中基于核的方法则需要350。此外,在功率受限的情况下, 基于核的方法的计算复杂性会使它们成为较不受欢迎的候选。但是,在我们提出的方法中,我们通过在LSTM和SNN之间绘制连接来建模神经元动态,从而消除了对这些核的需求。附录B中提供了有关α1和α2选择的更多信息。
Sequential EMNIST是分类算法的另一个标准和相对较新的基准,它是MNIST的扩展版本,但在包含字母和数字的意义上更具挑战性。它接受了将近113K的训练,并来自47个不同类别的约19K测试样本。使用与序列MNIST部分相同的框架,我们将图像转换为每个图像的基于ON和OFF事件的序列数组。同样,我们训练网络进行2000次迭代。表2中列出了最终的测试准确性和相关的误差条。某些其他方法的结果也列在同一表中。尽管此数据集尚未通过其他循环SNN方法进行测试,但我们获得了与前馈SNN可比较的结果。
我们认为,FF SNN在图像分类任务中表现更好的原因有很多。其中之一是立即获取图像,为每个神经元配备基于时间的核,并多次采样输入(请参见[17]和[31])。但是,一般来说RNN,尤其是LSTM在序列学习任务中显示出了巨大的成功,这可以归因于它们为每个神经元配备了内部存储器来管理来自序列输入的信息流。此特征使RNN及其派生成为许多序列建模任务(尤其是语言建模)中的首选方法。但是,FF网络并非旨在学习序列输入的依赖关系。尽管[17]中提出的工作在图像分类中表现更好,但是如何修改其结构以进行序列学习任务并不清楚,请参见以下实验。
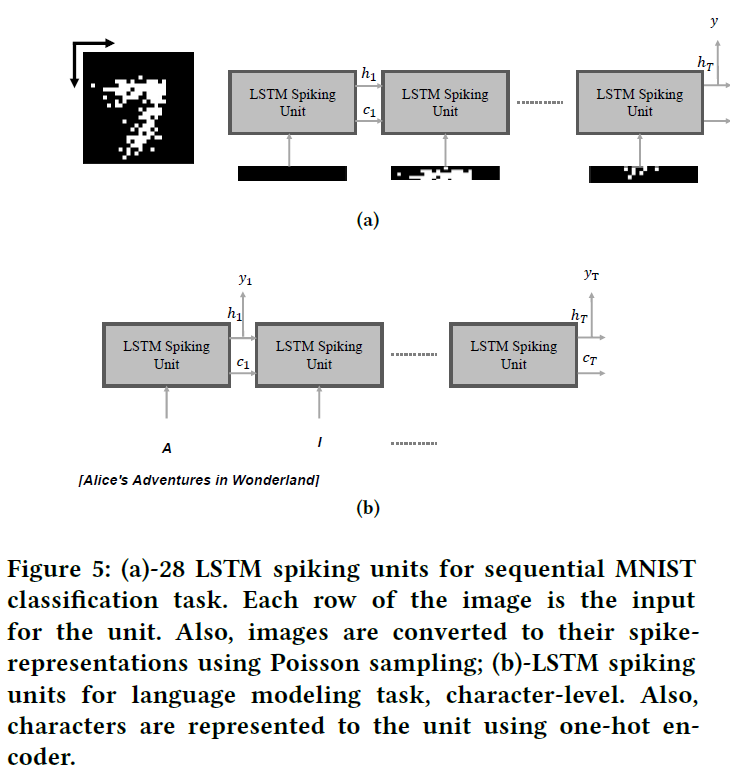
4.4 Language Modeling
本节的目的是证明所提出的LSTM SNN也能够学习高质量的语言建模任务。通过显示这一点,我们可以证明网络学习长期依赖关系的能力。特别是,我们首先使用提出的LSTM SNN对网络进行训练以进行预测,然后将其扩展为针对字符和单词级别的生成语言模型。实际上,所提出的循环SNN将学习输入字符串中的依赖关系以及给定字符序列(单词)的每个字符(单词)的条件概率。对于这两种模型,我们都使用LSTM脉冲单元,其隐含层的大小为200。同样,使用与前面提到的相同的初始化和参数。
Character-level - 我们用于此部分的每个数据集都是一个字符串,包括字母,数字和标点符号。网络是一系列LSTM SNN单元,每个输入xt是一个字符的one-hot编码版本,由向量(s1, s2, ··· , sn)表示,其中n表示总字符数。因此,每个单元的输入矢量是one-hot向量,这也有利于基于脉冲的表征。给定训练序列(x1, x2, ... , xT),网络利用它返回预测序列,表示为(o1, o2, ... , oT),其中ot+1 = arg max p(xt+1 | x≤t)。应该注意的是,每个脉冲LSTM模块的最后一层是softmax。
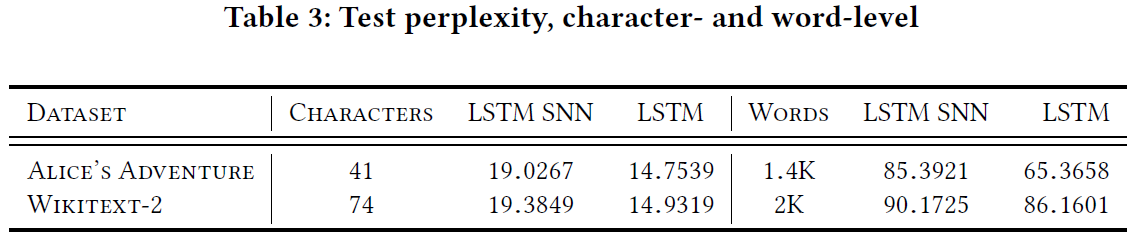
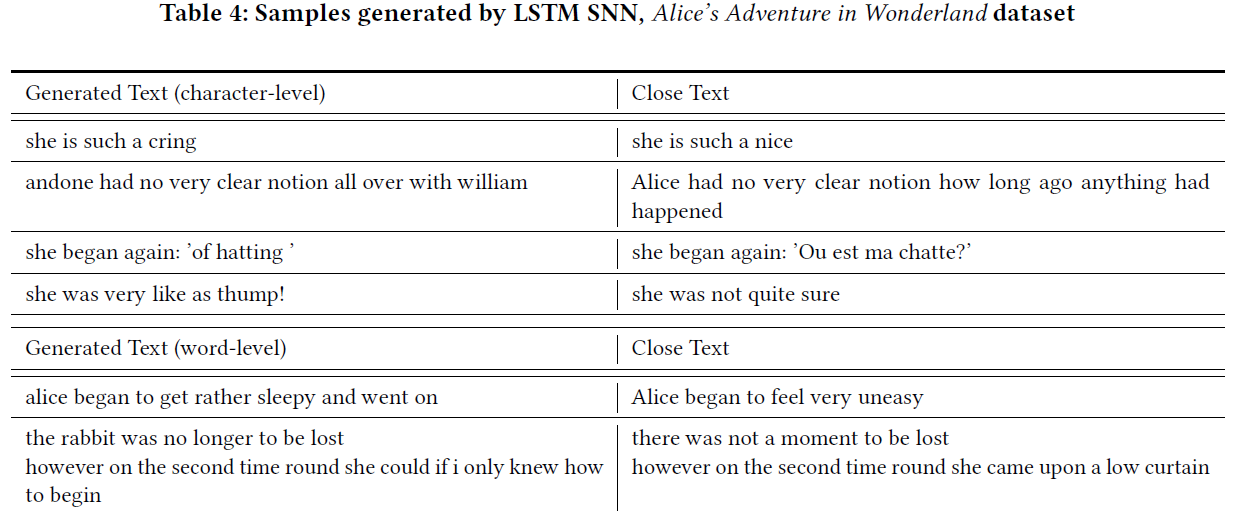
我们采用的数据集是Alice's Adventures in Wonderland和Wikitext-2。我们首先缩小这些数据集,并通过将大写字母替换为小写来清除大写字母。经过上述预处理后,Alice's Adventures in Wonderland和Wikitext-2分别包含41个和74个不同的字符。并且它们都具有52000个字符总数。此数据集的测试数据集有所不同,具有相同的不同字符,但总大小为12000。我们使用的LSTM具有字符的输入大小,一个隐含层(大小为200)和字符的输出大小。为了评估模型,表3中报告了1000次迭代后的平均困惑度(p(x1, x2, ··· , xT)−1/T)。此外,我们报告了类似数据集的常规LSTM结果。可以看出,所提出的LSTM脉冲单元可以达到可比较的结果,但是,它的优势是要更加节能和节约资源。成功学习长期依赖关系后,经过训练的模型也可以用于生成文本。因此,为了更好地了解所生成序列的质量和丰富性,表4中列出了一些样本。
Word-level - 与字符级相似,我们首先清除大写字母,然后提取不同的词。但是,与字符级相比,每个单词的one-hot编码将是详尽的。为了解决这个问题,我们首先将每个单词编码为表征向量。基于单词到向量,我们使用大小为5的窗口(前后各5个单词),并训练一个前馈神经网络,该网络的一个隐含层包含100个单位,后跟一个softmax层。因此,每个单词都由大小为100的向量表征,其中具有相似上下文的不同单词彼此接近。在这种表征中,每个向量都携带来自单词的关键信息,当我们将向量转换为基于脉冲的表征时,我们预计会丢失大量信息。因此,我们具有其主要格式的输入向量,而无需转换为基于ON和OFF事件的任何形式。我们使用了与先前任务相似的数据集。但是,这里有一个LSTM脉冲单元,输入大小为100,一个包含200个神经元的隐含层,输出大小为100。与前面的部分相似,结果在表3和表4中提供。因此,对于单词级别的语言建模任务,结果也与常规LSTM相当。

4.5 Speech Classification
使用语音识别任务的目的是评估我们的结构为分类任务学习语音序列的能力。为此,我们利用以8kHz, FSDD记录的语音数据集,其中包括四个不同说话者说出的数字的录音,总大小为2000 (每个说话者大小为500)。为了有效表示要训练的每个样本,首先我们使用一维小波散射变换对样本进行变换。应用该预处理后,每个样本将变成来自10个不同类别的一维矢量(大小为338)。为此任务提出的网络是一系列8个LSTM脉冲单元,每个输入单元的大小为48,输出取自最后一个单元,后跟一个softmax层。为了评估模型,将数据集分为1800个训练样本和200个测试样本。基于这种方法,我们在训练集上达到了86.3%的准确性,在测试集上达到了83%的准确性。采用相同的结构,常规LSTM的训练和测试准确性分别为89.4%和86%。可以推断,LSTM SNN可以得到与常规LSTM相当的结果,但是以更有效的能源和资源方式。
5 CONCLUSION
在这项工作中,我们介绍了直接训练循环SNN的框架。特别是,我们开发了一类基于LSTM的SNN,它们利用了学习时序依赖性的固有LSTM功能。基于此网络,我们针对此类网络开发了反向传播框架。我们通过toy示例评估此类LSTM SNN的性能,然后进行分类任务。结果表明,与现有的循环SNN相当,该网络具有更好的性能。结果也与前馈SNN相当,而所提出的模型的计算强度较低。最后,我们使用语言建模任务测试我们的方法,以评估网络的性能以学习长期依赖关系。
A BACKPROPAGATION
我们为LSTM脉冲单元的参数开发更新表达式。为此,请考虑将输出层设为softmax,yt = softmax(wyht + by),并将损失函数定义为交叉熵损失。因此,损失函数关于LSTM SNN在 t 处的输出yt的导数可以表征如下:
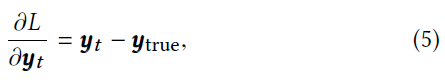
同样,具有线性输出层和最小二乘损失函数的网络具有相同的梯度。鉴于此以及损失函数关于(4)中每个门的输出的导数,我们现在可以基于每个门的损失函数的导数来更新权重:
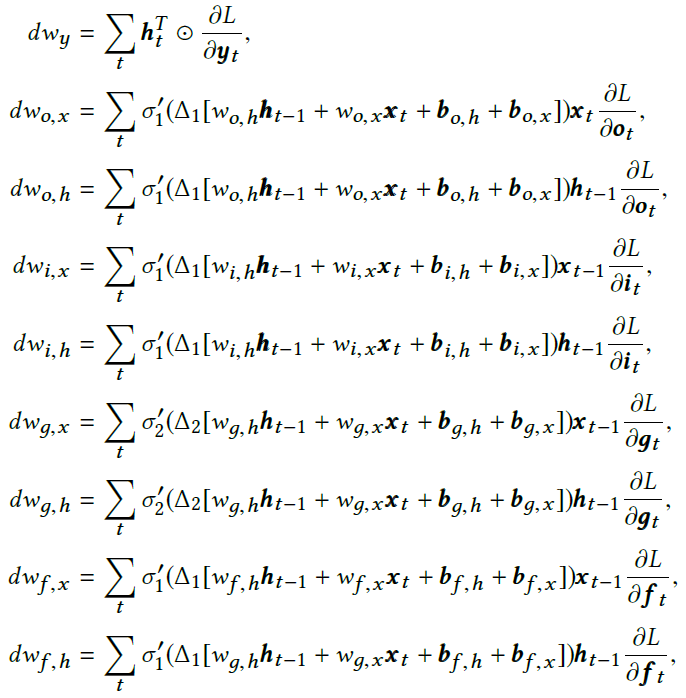
其中![]() 和
和![]() ,并且γ为1或一个小于1的正数(基于ct的值,在本文的3.1节中进行了解释)。考虑到每个时间步骤 t 的这些偏导数,我们现在可以基于损失函数关于权重和偏差的偏导数来对其进行更新。并且使用相同的方法,我们可以表示偏差的损失函数的导数。
,并且γ为1或一个小于1的正数(基于ct的值,在本文的3.1节中进行了解释)。考虑到每个时间步骤 t 的这些偏导数,我们现在可以基于损失函数关于权重和偏差的偏导数来对其进行更新。并且使用相同的方法,我们可以表示偏差的损失函数的导数。
B α1 & α2 IMPACTS
图6描绘了揭示α0和α1对调整梯度的严重影响。实际上,这两个参数控制了LSTM脉冲单元不同部分在反向传播期间的误差流。有趣的一点是,在α1 = 4且α2 = 0.3的情况下,LSTM SNN在反向传播期间变得与常规LSTM相似。我们已经在MNIST数据集上进行了这些实验。对于其他数据集,我们也观察到相同的结果。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号