

SNN对抗攻击笔记
SNN对抗攻击笔记:
1. 解决SNN对抗攻击中脉冲与梯度数据格式不兼容性以及梯度消失问题:
- G2S Converter、Gradient Trigger[1]
2. 基于梯度的对抗攻击方式:
- FGSM[1-3]
- R-FGSM[3]
- I-FGSM[3]
- BIM[1]
- PGD[2]
3. 图像转化到脉冲序列的采样方式:
- Poisson事件生成过程[1-9]
4. SNN类型:
- SNN-conv(ANN-SNN Conversion)[2-7, 9]
- 采用的神经元模型
- IF神经元模型[2-7, 9]
- LIF神经元模型[4]
- Trick
- 阈值平衡[2-5]
- 权重归一化[5, 9]
- 采用的神经元模型
- SNN-BP[1-4, 8]
- 替代梯度法:
-
-
- 分段常数函数(迭代LIF神经元模型)[1]
-
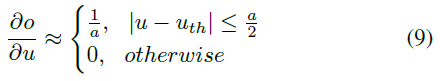
-
-
- 脉冲时间相关函数(IF/LIF神经元模型)[2, 4]
-

- 阈值相关函数(IF/LIF神经元模型)[3, 8]

![]()
5. 影响对抗攻击效果的因素分析:
- 损失函数、发放阈值(倒数第二层)[1]
- 输入量化、时间步骤数、泄漏因子[2]
6.对抗攻击类型:
- 白盒攻击、目标/非目标攻击[1]
- 白/黑盒攻击、非目标攻击(这里的黑盒攻击是由具有相同网络结构但不同初始化的ANN创建的)[2]
- 白/黑盒攻击、目标/非目标攻击[3]
7. SNN/ANN-crafted攻击的比较:
- 在独立攻击场景中,所有白盒攻击成功率都相当高[1]
- 利用ANN-crafted的对抗样本来欺骗SNN模型是非常困难的[1]
- 在黑盒设置下,ANN-crafted攻击比相应的SNN-crafted攻击强[2]
- 在白/黑盒设置中,SNN-crafted比ANN-crafted具有更强的攻击能力[3]
- 尽管在白盒设置中,SNN的精度下降要高于ANN,但SNN对黑盒攻击的抵抗力要比ANN高得多[3]
8. SNN/ANN健壮性的比较:
- 白盒攻击SNN模型比白盒攻击ANN模型需要更多的扰动,这反映了SNN模型具有更高的健壮性[1]
- 在白/黑盒攻击下,与SNN-BP网络的非脉冲对应以及SNN-conv网络相比,SNN-BP网络具有更强的健壮性[2]
- 对于白/黑盒攻击,SNN-BP比SNN-conv具有更强的健壮性[3]
9. SNN中神经元的选择:
- 在SNN(ANN)中每个卷积层、平均池化层和全连接层之后,都跟着LIF神经元(ReLU激活)[3]
- 为了避免负值,使用ReLU激活,然后用IF神经元替代ReLU激活[5-7]
10. SNN中池化的选择:
- SNN
- 在SNN中,激活是二进制的,执行最大池化将导致下一层的大量信息丢失[3-6]
- SNN-conv
- 将VGG的最大池化层用平均池化替代[2]
- 最大池化需要两层脉冲网络;在CNN中,空间最大池化被实现为在输入中的小图像邻域上获取最大输出值; 在SNN中,我们需要两层神经网络来实现此目的,同时需要横向抑制,然后合并在这些小的图像区域上;这种方法需要更多的神经元,并且由于增加的复杂性而可能导致准确性下降[7]
- 使用空间线性子采样代替空间最大池化;空间线性二次采样使用总和为1.0的均匀权重核将小图像邻域上的所有像素相加; 空间线性子采样函数可以轻松转换为脉冲域[7]
- 在这里,我们提出了一种简单的脉冲池化机制,其中输出单元包含门控函数,该函数仅允许最大发放神经元的脉冲通过,而丢弃其他神经元的脉冲;通过计算突触前发放率的估计,例如通过计算这些rate的实时或指数加权平均值,来控制门控函数;在实践中,我们发现了几种有效的方法,但是仅使用有限的脉冲响应滤波器(2x2的最大池化层)来控制门控函数以证明结果[9]
- SNN-BP
- 由于其简单性,我们使用平均池化; 在SNN的情况下,平均后会使用额外阈值以生成输出脉冲[8]
11. SNN中偏差的选择:
- SNN
- 不含偏差项,因为它们对阈值电压有间接影响,因此对SNN训练的收敛性也有间接影响[2, 4]
- 不含偏差项,因为它们对阈值电压有间接影响,因此对SNN训练的收敛性也有间接影响[2, 4]
- SNN-conv
- 没有很好的方法来表示SNN中的偏差[5-7]
- 在脉冲网络中,可以简单地以相同符号的恒定输入电流作为偏差来实现[9]
- 可以用恒定rate的外部脉冲输入表示偏差,该rate与ANN偏差成正比,尽管如此,人们可能不得不反转脉冲的符号以解决负偏差[9]
- BN的ANN-SNN转换(将BN参数整合到之前层的权重和偏差中)[9]
- SNN-BP
- 去除所有卷积层和全连接层中的偏差[7]
12. SNN中正则器的选择
- SNN
- 在每个卷积层和全连接层之后,都跟着Dropout(0.2)[3]
- 除非后面跟着一个池化层,否则在每个ReLU/IF之后都会使用一个Dropout层[2, 4]
- 无偏差排除了Batch Normalization(BN)作为正则器使用的可能性[2, 4, 5]
- SNN-conv
- 对于VGG网络,除非有池化层紧随其后,否则在每个ReLU层之后都会使用一个Dropout层[5]
- 对于残差网络,我们仅对非等效并行路径上的ReLU使用Dropout,而在结合层处不使用[5]
- SNN-BP
- 我们使用SNN版本的Dropout技术,忽略单元的概率(p)等于0.2-0.25;请注意,与ANN相比,SNN前向传播的激活要少得多,因此SNN的最佳p值必须小于典型的ANN Dropout(p = 0.5)[8]
Reference:
[1] Liang L , Hu X , Deng L , et al. Exploring Adversarial Attack in Spiking Neural Networks with Spike-Compatible Gradient[J]. 2020.
[2] Sharmin S , Rathi N , Panda P , et al. Inherent Adversarial Robustness of Deep Spiking Neural Networks: Effects of Discrete Input Encoding and Non-Linear Activations[J]. 2020.
[3] Sharmin S , Panda P , Sarwar S S , et al. A Comprehensive Analysis on Adversarial Robustness of Spiking Neural Networks[J]. 2019.
[4] Rathi, N., Srinivasan, G., Panda, P., Roy, K.: Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation. In:ICLR (2020).
[5] Abhronil Sengupta, Yuting Ye, RobertWang, Chiao Liu, and Kaushik Roy. Going deeper in spiking neural networks: Vgg and residual architectures. Frontiers in neuroscience, 13, 2019.
[6] Peter U Diehl, Daniel Neil, Jonathan Binas, Matthew Cook, Shih-Chii Liu, and Michael Pfeiffer. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In 2015 International Joint Conference on Neural Networks (IJCNN), pp. 1–8. IEEE, 2015.
[7] Cao Y , Chen Y , Khosla D . Spiking Deep Convolutional Neural Networks for Energy-Efficient Object Recognition[J]. International Journal of Computer Vision, 2015, 113(1):54-66.
[8] Chankyu Lee, Syed Shakib Sarwar, Kaushik Roy, Enabling Spike-based Backpropagation in State-of-the-art Deep Neural Network Architectures, arXiv:1903.06379, 2019.
[9] B. Rueckauer, I.-A. Lungu, Y. Hu, M. Pfeiffer, and S.-C. Liu. Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Frontiers in neuroscience, 11:682, 2017.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号