
libsvm Minist Hog 手写体识别
统计手写数字集的HOG特征
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/
这篇文章是模式识别的小作业,利用svm实现Minist数据集手写体识别,在这里我实现了opencv中的svm和libsvm两个版本,供大家做参考。
[https://github.com/YihangLou/SVM-Minist-HandWriting-Recognition]https://github.com/YihangLou/SVM-Minist-HandWriting-Recognition Github上的工程链接
Hog特征简介
本实验中,使用开源计算机视觉库OpenCV作为图像处理的基本工具,用其提供的loadImage函数读入训练样本后,首先我们考虑如何对样本中的手写数字特征进行提取。在本实验中我们采取了方向梯度直方图(Histogram of OrientedGradient, HOG)的方法。HOG特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。在一副图像中,局部目标的表象和形状能够被梯度和边缘的方向密度分布很好地描述,而HOG通过计算和统计图像局部区域的梯度方向直方图来构成特征。
HOG特征提取算法的实现过程如下:
1)将待检测的图像灰度化;
2)采用Gamma校正法对输入图像进行颜色空间的标准化(归一化)。目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰。
3)计算图像每个像素的梯度(包括大小和方向)。主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
4)将图像划分成小cells(例如66像素/cell),并统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor。统计梯度直方图过程如下:假设我们采用9个bin的直方图来统计这66个像素的梯度信息。也就是将cell的梯度方向 分成9个方向块,
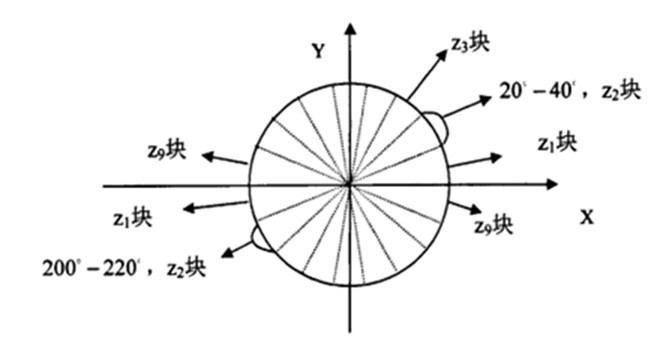
如果这个像素的梯度方向 是 或者 ,直方图第2个bin的计数就加1,这样,对cell内每个像素用梯度方向在直方图中进行加权投影(映射到固定的角度范围),就可以得到这个cell的梯度方向直方图了,就是该cell对应的9维特征向量(因为有9个bin)。梯度幅值 就是作为投影的权值的。例如说:这个像素的梯度方向是 ,然后它的梯度幅值 是2,那么直方图第2个bin的计数就不是加1了,而是加2。
4)将每几个cell组成一个block(例如3*3个cell/block),一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor;
5)将图像image内的所有block的HOG特征descriptor串联起来就可以得到该image的HOG特征descriptor了。这个就是最终的可供分类使用的特征向量了。
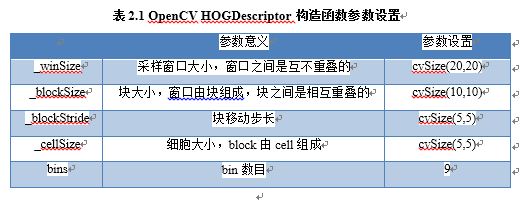
在我们的实验中使用OpenCV提供的HOG算子HOGDescriotiptor,它的构造函数HOGDescriptor * hog = new HOGDescriptor(Size _winSize,Size _blockSize, Size _blockStride ,Size _cellSize , int bins);相关参数设置如表2.1所示。接下来我们只需再调用hog->compute()函数并以Image作为参数即可计算出其特征向量descriptors。
vector
hog->compute(Image, descriptors,Size(1,1), Size(0,0));
LibSVM配置
这里SVM的原理不就做介绍了,网上也有很多的资料介绍SVM
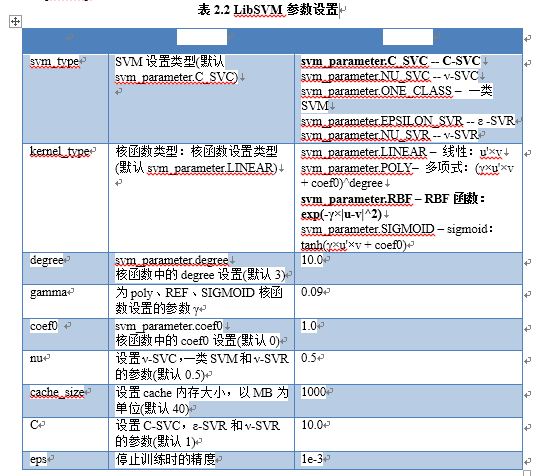
- 首先设置SVM参数。LibSVM提供了SVM参数结构svm_param,如下段代码所示,各参数意义如表2.2所示。
//配置SVM参数
svm_parameter param;
param.svm_type = C_SVC;
param.kernel_type = RBF;
param.degree = 10.0;
param.gamma = 0.09;
param.coef0 = 1.0;
param.nu = 0.5;
param.cache_size = 1000;
param.C = 10.0;
param.eps = 1e-3;
param.p = 1.0;
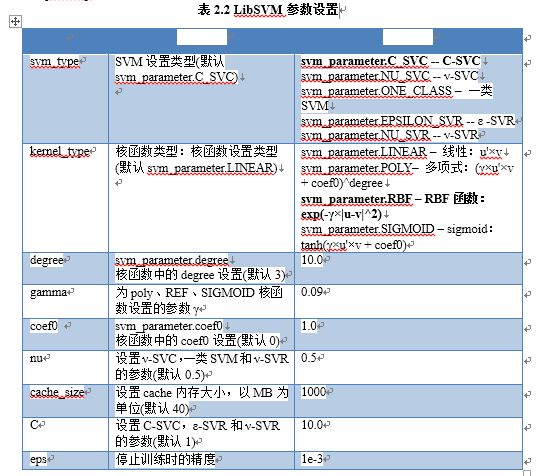
在本实验中选择了C_SVC类型的SVM,并且选择了REF核函数。
- 将待训练的特征向量整理成LibSVM使用的数据格式。2.1.1中使用OpenCV提供的HOG方法得到了特征向量descriptors,要在LibSVM中使用上还需符合LibSVM的训练数据文件格式,如下所示
<label> <index1>:<value1> <index2>:<value2> ...
其中<label> 是训练数据集的目标值,对于分类,它是标识某类的整数(支持多个类)。<index> 是以1开始的整数,可以是不连续的,但是必须在结尾处标记为index=-1;<value>为实数,也就是我们提取出的特征向量。例如我们处理第一张手写图片train_0_0.jpg,该图片表示的是手写数字0,那么<label>标记为0;该图片用HOG方法描述的特征向量descriptor是长度为324的vector<float>,那么将<index1>~<index324>分别标记为0,1,2...323,<index325>标记为-1表示结束;<value1>~<value324>分别赋值为descriptor[0],descriptor[1],descriptor[2]...descriptor[323]。
- 调用svm_train函数开始训练,得到训练模型svm_model,并保存于“*.model”文件。前面两个步骤已经分别设置好了SVM的一系列参数param并整理了待训练特征向量的格式svm_prob,svm_train函数以param和svm_prob作为参数开始训练。
训练过程中输出如图所示,其中, #iter为迭代次数;nu是选择的核函数类型的参数;obj为SVM文件转换为的二次规划求解得到的最小值;rho为判决函数的偏置项b;nSV为标准支持向量个数(0<a[i]<c);nBSV为边界上的支持向量个数(a[i]=c);Total nSV为支持向量总个数(对于两类来说, 因为只有一个分类模型Total nSV = nSV但是对于多类,这个是各个分类模型的nSV之和)。
得到的“*.model”文件如下所示:
svm_type c_svc //所选择的SVM类型,默认为c_svc
kernel_type rbf //训练采用的核函数类型, 此处为RBF核
gamma 0.09 //RBF核的参数γ
nr_class 10 //类别数, 此处为数字0~9,即10个分类问题
total_sv 6364 //支持向量总个数
rho 1.57532 0.87752 -0.67652 0.45041 0.659519 -0.506248 0.534779 -1.06453 0.19707 -0.584892 -1.06272 -1.54669 -0.592897 -0.583714 -0.742219 -2.47223 -1.20282 -1.79853 -0.178512 -0.215509 -0.533352 0.286281 -1.75888 0.0187612 1.11297 2.04325 0.236593 0.855722 -0.836486 1.11822 0.096519 0.95863 -0.251392 -1.09347 -1.18159 -0.620122 0.237805 -2.51107 -0.453213 -0.0407495 -1.66436 -0.209359 -1.08233 -1.12835 1.5451
//判决函数的偏置项b
label 0 1 2 3 4 5 6 7 8 9 //原始文件中的类别标识
nr_sv 427 402 677 676 791 569 489 717 805 811//每个类的支持向量机的个数
......
4)读入测试集图片,提取其HOG特征并整理成LibSVM使用的数据格式svm_node。测试集格式与训练集格式的唯一不同在于测试集不需要标记label,也具有index和value属性。
5)调用svm_predict函数进行测试。首先通过svm_model * 加载训练出的模型“*.Model”,svm_model 和svm_node作为svm_predict函数的参数,该函数以返回一个int类型的数据,即预测出的类别。
OpenCV SVM
除了2.1.2介绍的LibSVM工具,我们小组还尝试了OpenCV提供的SVM工具,它是基于LibSVM软件包开发的,优点是使用起来比LibSVM更简洁,下面简要的介绍一下OpenCV中SVM的训练和测试两阶段:
1)OpenCV中的SVM在训练阶段代码如下所示:
void trainSVM(CvMat * & dataMat,CvMat * & labelMat )
{
cout<<"train svm start"<<endl;
cout<<dataMat<<endl;
CvSVM svm;
CvSVMParams param;//这里是SVM训练相关参数
CvTermCriteria criteria; //这里是迭代终止准则
criteria = cvTermCriteria( CV_TERMCRIT_EPS, 1000, FLT_EPSILON );
param = CvSVMParams( CvSVM::C_SVC, CvSVM::RBF, 10.0, 0.09, 1.0, 10.0, 0.5, 1.0, NULL, criteria );
svm.train( dataMat, labelMat, NULL, NULL, param );//训练数据
svm.save( SVMModel.c_str());
cout<<"SVM Training Complete"<<endl;
}
其中CvTermCriteria设置了迭代终止准则,最大迭代次数设为1000次,结果的精确性设为FLT_EPSILON = 1.19e-7;CvSVMParams设置了SVM相关的训练参数,参数具体设置仍如表2.1所示。与LibSVM不同的是,OpenCV不需要将特征向量整理成特定的格式,只需要特征向量按行顺序排好,给出它们的label,就可以调用训练函数svm.train()进行训练了。另外,OpenCV训练出的模型保存在“.xml”文件中而非LibSVM中的“.Model”文件,如图2.3所示。
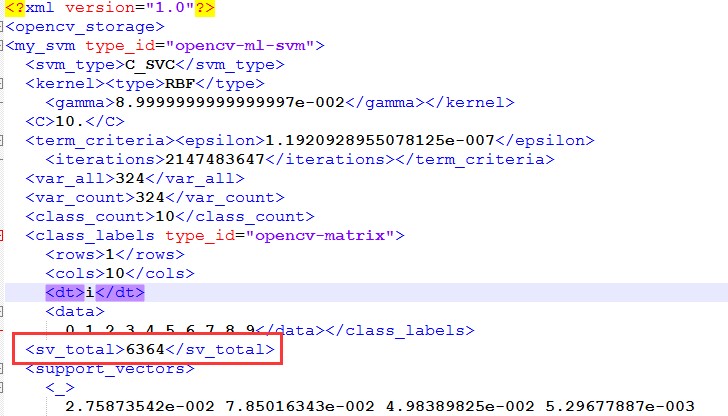
最后所有的支持向量个数为6364个,与LibSVM完全一致,印证了OpenCV SVM底层是基于LibSVM的。
2)在测试阶段,OpenCV SVM的用法与LibSVM基本一致,调用svm.predict函数进行测试。首先通过CvSVM svm加载训练出的模型“*.xml”。接着将测试集图片的HOG向量整理成一个个CvMat,它作为svm_predict函数的参数输入,该函数以返回一个int类型的数据,即预测出的类别。
代码解读
实验代码实现了LibSVM 和OpenCV SVM分类功能,完成了各个函数功能的封装,整个SVM分类器共分为8个函数,分别为:readTrainFileList、processHogFeature、trainSVM、trainLibSVM,readTestFileList,testLibSVM,testSVM,releaseAll。其中,每个函数的输入输出设置以及功能如下表所示:

实验测试
本次实验使用“MNIST DATABASE”, 数据集包含了0-9数字手写体,共有60000张训练数据集,10000张测试数据集。测试集的前5000个例子取自原始NIST训练集,后5000取自原始NIST测试集,前5000个数据要比后5000个数据更干净、容易。
预测结果是输出到txt中的,通过Python脚本来分析
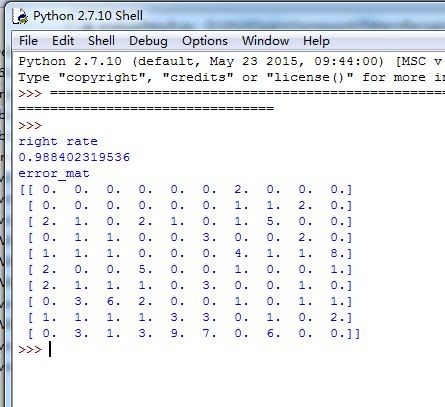
1)训练正确率
在训练集上进行正确率测试得到的结果是0.9884。
2)测试正确率
在10000张测试数据集上,我们的实验结果准确率为0.9884,其中10*10的举证结果如下,结果(i,j)代表将第i类错分为第j类的次数。
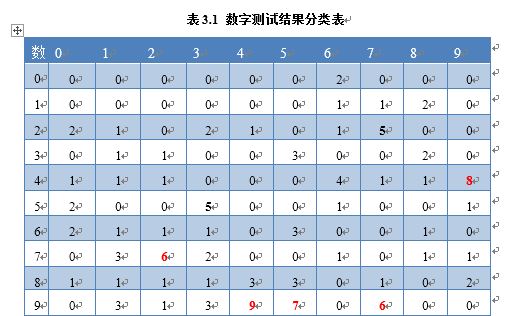
实验的主要错分类分析
实验中,有一些错分类很难避免,如4和9的错分以及7和2的错分,如下图所示。由于实验数据本身难以识别,造成的错分占据整个实验数据的1%左右。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号