

机器学习之交叉验证
交叉验证定义:交叉验证的核心思想是将数据分成多个小子集(折叠),轮流使用不同的子集进行训练和验证,来确保模型在不同的数据集上都可以有良好的表现。
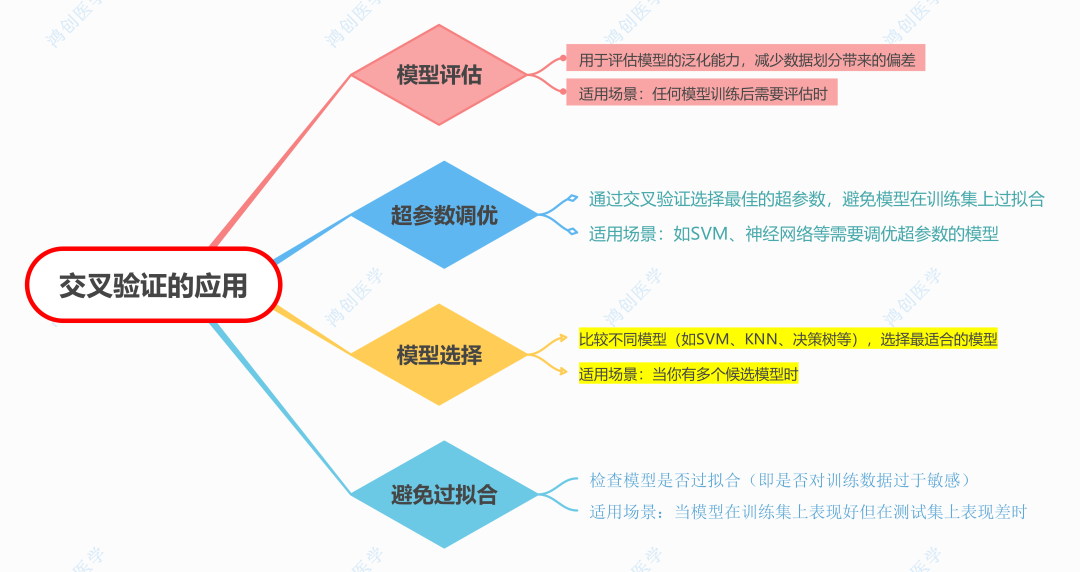
常见的交叉验证方法总结:
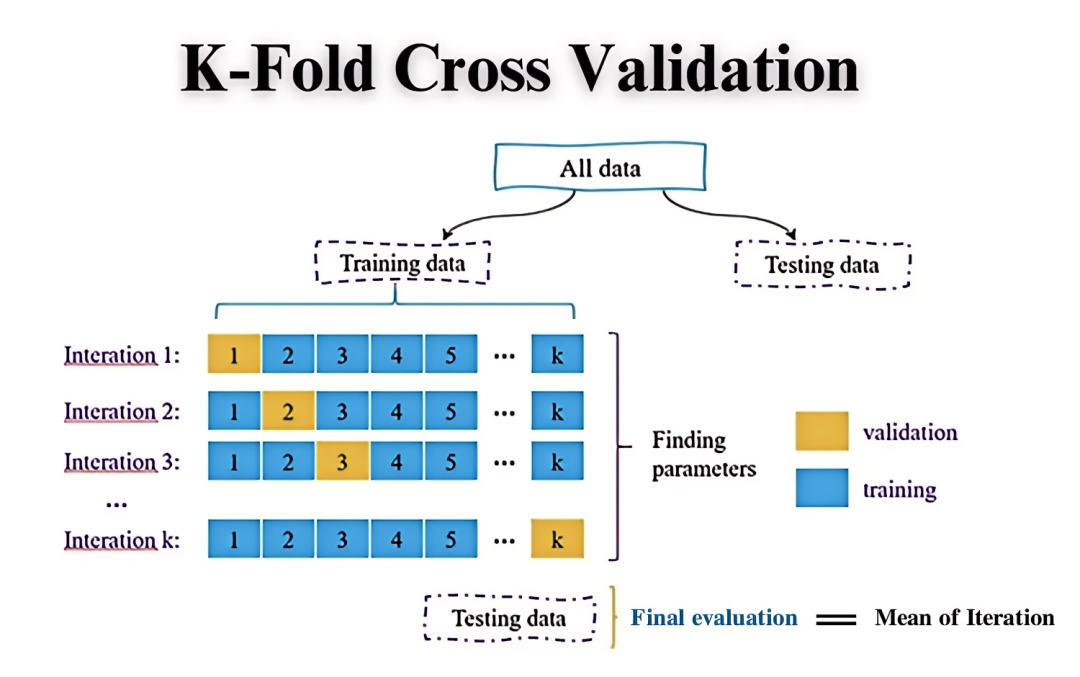
- k折交叉验证:其主要思想就是将数据集随机分成k个大小相等(或接近)的子集(folds),然后进行k次训练和验证,每次选取第k个子集作为验证集其余k-1个作为训练集一共会训练k次,有时候为了结果更加准确会进行多次分组,例如常见的5折3次交叉验证就是将数据集分为5组,这个分组操作进行了3次,每一次分完组,对于1~5的子集轮流当验证集,其余4组当训练集,最后会得到5*3一共15次训练的结果,然后取其均值得到性能评估。
![image]()
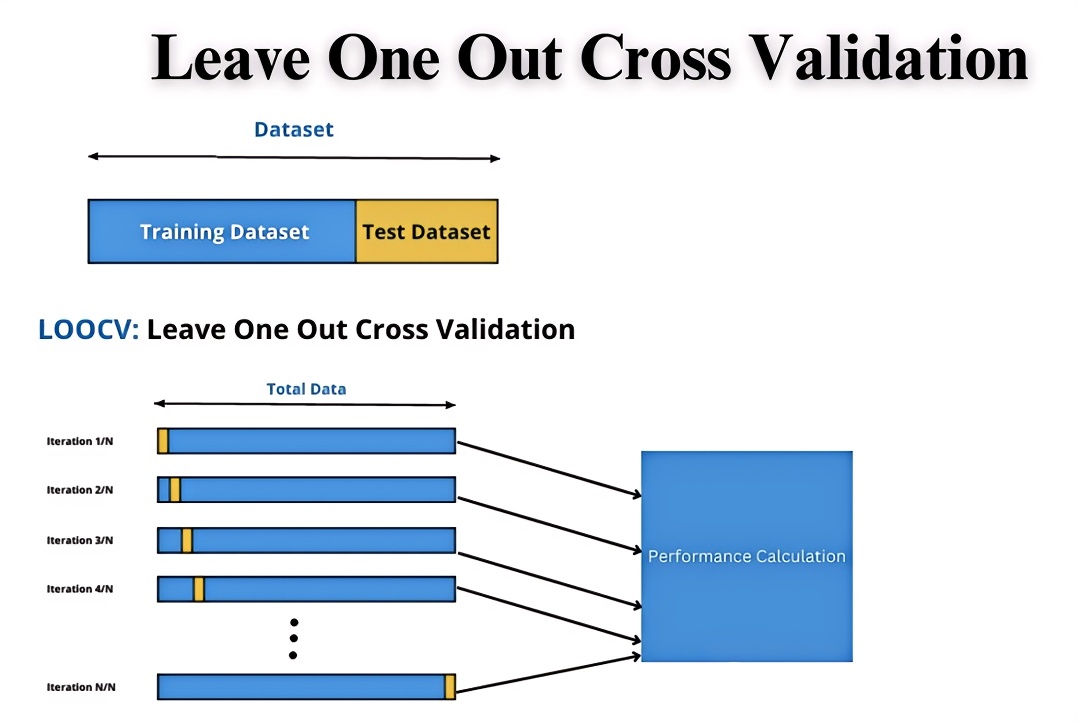
- 留一交叉验:留一交叉验证是 K 折交叉验证的一种特殊情况。在 K 折交叉验证中,当 K 的值等于数据集的样本数量时,就成为了留一交叉验证,好处是每个数据都会作为一次验证集,缺点是尤其当 K 较大时,计算成本较高。
![image]()
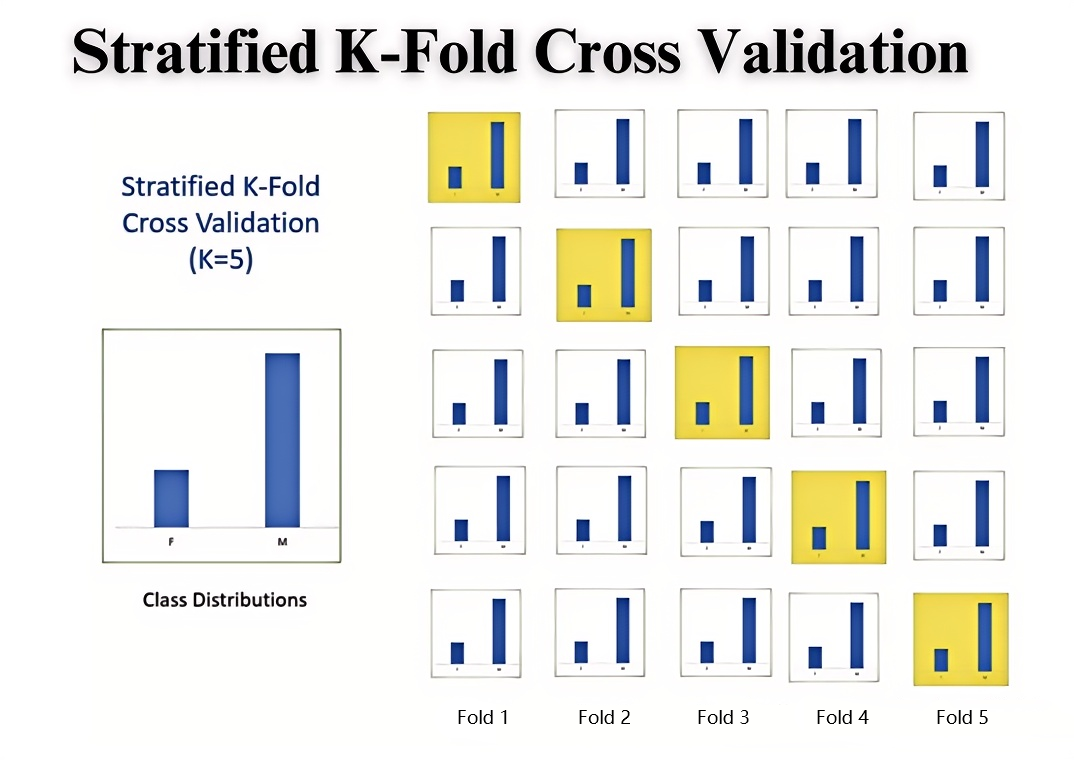
- 分层k折交叉验证:分层交叉验证在处理类别不平衡的数据时尤为适用,在用分层交叉验证时,它会保证划分出的每个子集,也就是每个 “折叠”内的各类别样本比例,都尽可能与原始整个数据集中的类别样本比例保持一致,比如原来数据集A类数据和B类数据比例为3:1,划分的子集中两类数据也要保持3:1,其余步骤和k折交叉验证一致除了子集内数据类别的比例要特殊处理一下。
![image]()
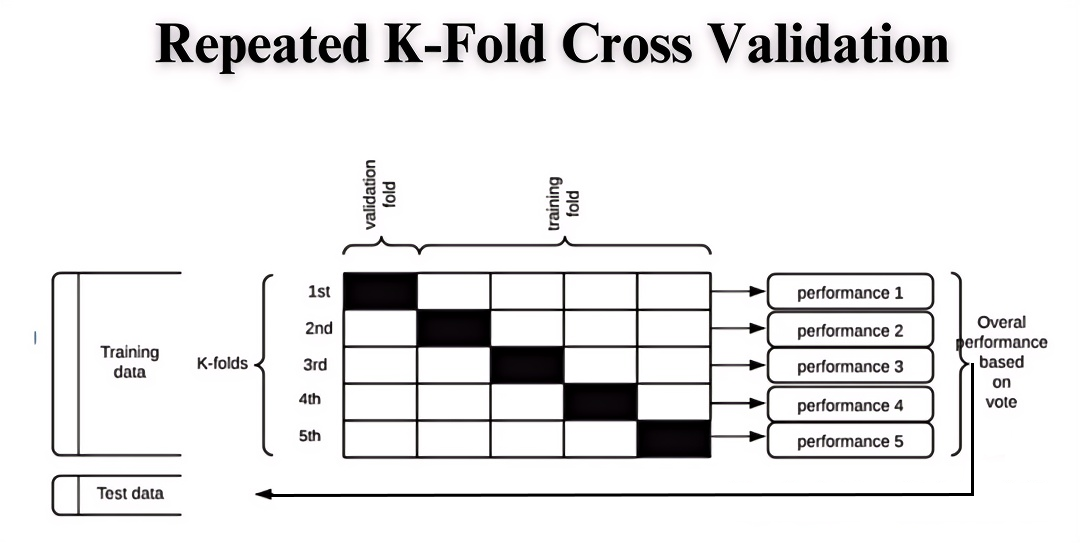
- 重复k折交叉验证:重复k折交叉验证是在标准的k折交叉验证的基础上,重复多次进行交叉验证,并在每次重复中重新划分数据集进行训练和验证,这种方法可以进一步提高评估模型性能的稳定性,并减少因数据划分引起的波动。
![image]()
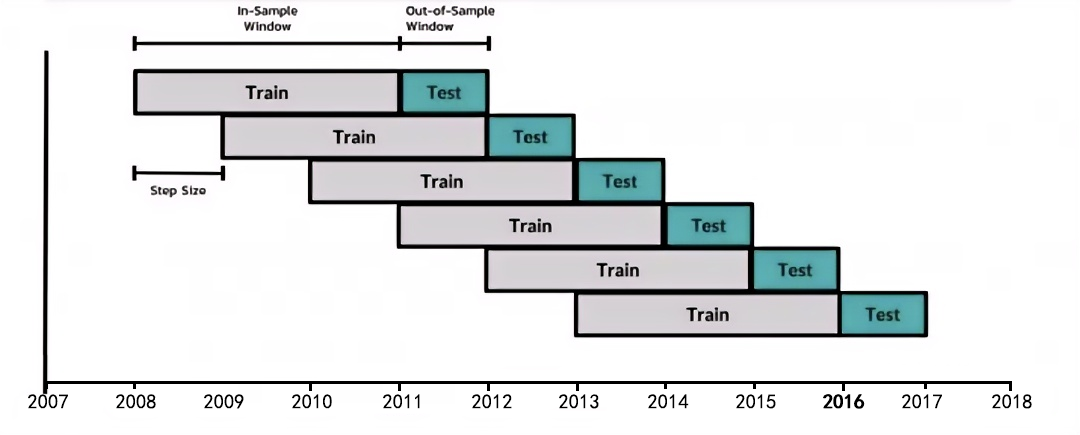
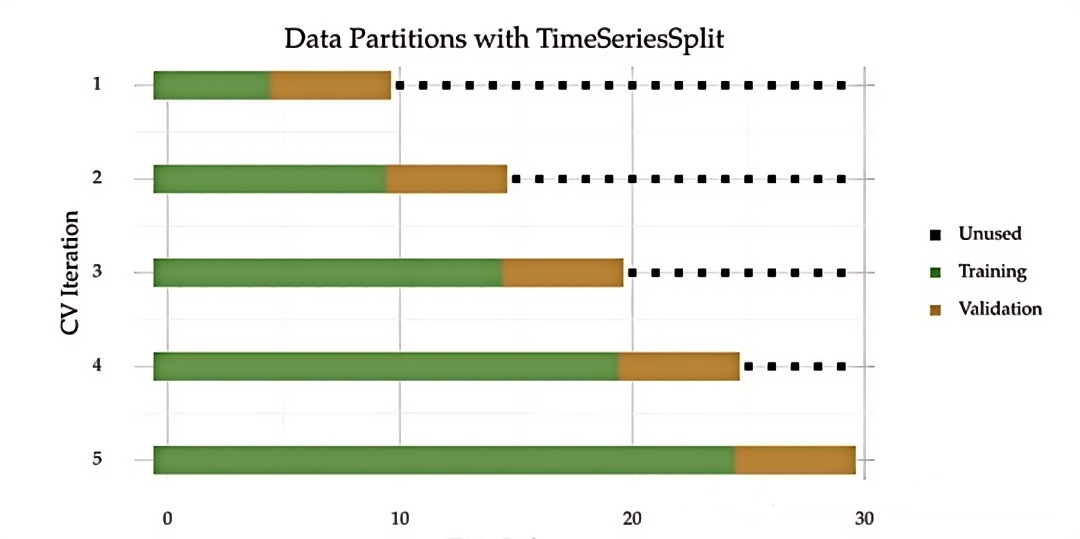
- 时间序列交叉验证:时间序列交叉验证是专门用于时间序列数据的交叉验证方法,它考虑到数据的时序性质,确保验证集中的数据不会“提前”泄露到训练集中。传统的k折交叉验证在时间序列数据中不适用,因为它可能打乱数据的时间顺序,导致数据泄漏。时间序列交叉验证通常是通过滚动窗口或扩展窗口来实现,基本步骤数据集按时间顺序进行划分,训练集和验证集的时间顺序不被打乱,训练集的大小固定不变,随着时间的推进,验证集逐步向前移动。
滚动窗口:每次使用固定长度的训练集进行训练,然后验证集紧随其后,并逐步向前推进
![image]()
扩展窗口:每次使用从起始点到当前时间点的所有数据进行训练,验证集始终是未来的数据。![image]()
基本步骤:
- 与滚动窗口类似,但是训练集随着验证集的增加而不断扩展。
- 每次验证后,训练集不仅包括之前的训练数据,还包括最新的验证数据。验证集则始终在时间上前进。
优点:训练集不断增加,模型有更多的数据进行训练,适用于稳定长期预测
缺点:随着训练集扩大,模型的训练时间和计算量增加
- 嵌套交叉验证:嵌套交叉验证主要用于模型选择和超参数调优。它的关键区别在于它将模型的选择和超参数优化过程嵌套在外层的交叉验证中。具体来说,嵌套交叉验证通过以下步骤进行————外层交叉验证:用于评估模型的整体性能,内层交叉验证:用于在训练集上选择最佳的模型或超参数。优点是能够有效地评估模型的性能,尤其是在超参数调优时避免数据泄漏,对于需要调参的模型,嵌套交叉验证提供了更可靠的评估结果。
嵌套验证比传统的验证方法更能体现模型的泛化能力,简言之,其核心思想为把数据分为内外两层,对于外层进行一次数据划分分为多折,留一折作为验证集留在外层,然后其余的训练集放入内层,内层对于外层传入的数据重新进行一次数据的划分,分为验证集和训练集就采用多折交叉验证然后将训练好的最优参数传到外层的训练集进行泛化判断,此时外层的训练集是从来没有被模型读取的,某种程度上来说是完全未知的,这样的训练可以进行多重,即多重嵌套交叉验证。
交叉验证的结果一般会提供每一折的模型评估指标,像准确率、均方误差等等,并计算它们的平均值和标准差。这可以帮助我们解模型的表现是否稳定,并且避免过拟合。
- 平均值:可以看出模型的整体表现。
- 标准差:如果标准差很大,说明模型的表现波动较大,可能存在过拟合或欠拟合问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号