正则表达式引起的性能下降
背景:在学习性能优化的知识时,发现一个因为正则表达式引起的性能下降问题,记录下来
藏在正则表达式里的陷阱
转载 藏在正则表达式里的陷阱
通过java自带的线程dump工具 发现出问题的线程 是字符串的校验
ps:也可以通过代码注释的方式,发现出问题的地方就是正则校验
其实这里导致 CPU 使用率高的关键原因就是:Java 正则表达式使用的引擎实现是 NFA 自动机,这种正则表达式引擎在进行字符匹配时会发生回溯(backtracking)。而一旦发生回溯,那其消耗的时间就会变得很长,有可能是几分钟,也有可能是几个小时,时间长短取决于回溯的次数和复杂度。
正则表达式基础知识
说起回溯陷阱,要先从正则表达式的引擎说起。正则引擎主要可以分为基本不同的两大类:一种是DFA(确定型有穷自动机),另一种是NFA(不确定型有穷自动机)。简单来讲,NFA 对应的是正则表达式主导的匹配,而 DFA 对应的是文本主导的匹配。
DFA从匹配文本入手,从左到右,每个字符不会匹配两次,它的时间复杂度是多项式的,所以通常情况下,它的速度更快,但支持的特性很少,不支持捕获组、各种引用等等;而NFA则是从正则表达式入手,不断读入字符,尝试是否匹配当前正则,不匹配则吐出字符重新尝试,通常它的速度比较慢,最优时间复杂度为多项式的,最差情况为指数级的。但NFA支持更多的特性,因而绝大多数编程场景下(包括java,js),我们面对的是NFA。
在关于数量的匹配中,有 + ? * {min,max} 四种两次,如果只是单独使用,那么它们就是贪婪模式。
如果在他们之后加多一个 ? 符号,那么原先的贪婪模式就会变成懒惰模式,即尽可能少地匹配。但是懒惰模式还是会发生回溯现象的。
如果在他们之后加多一个 + 符号,那么原先的贪婪模式就会变成独占模式,即尽可能多地匹配,但是不回溯。
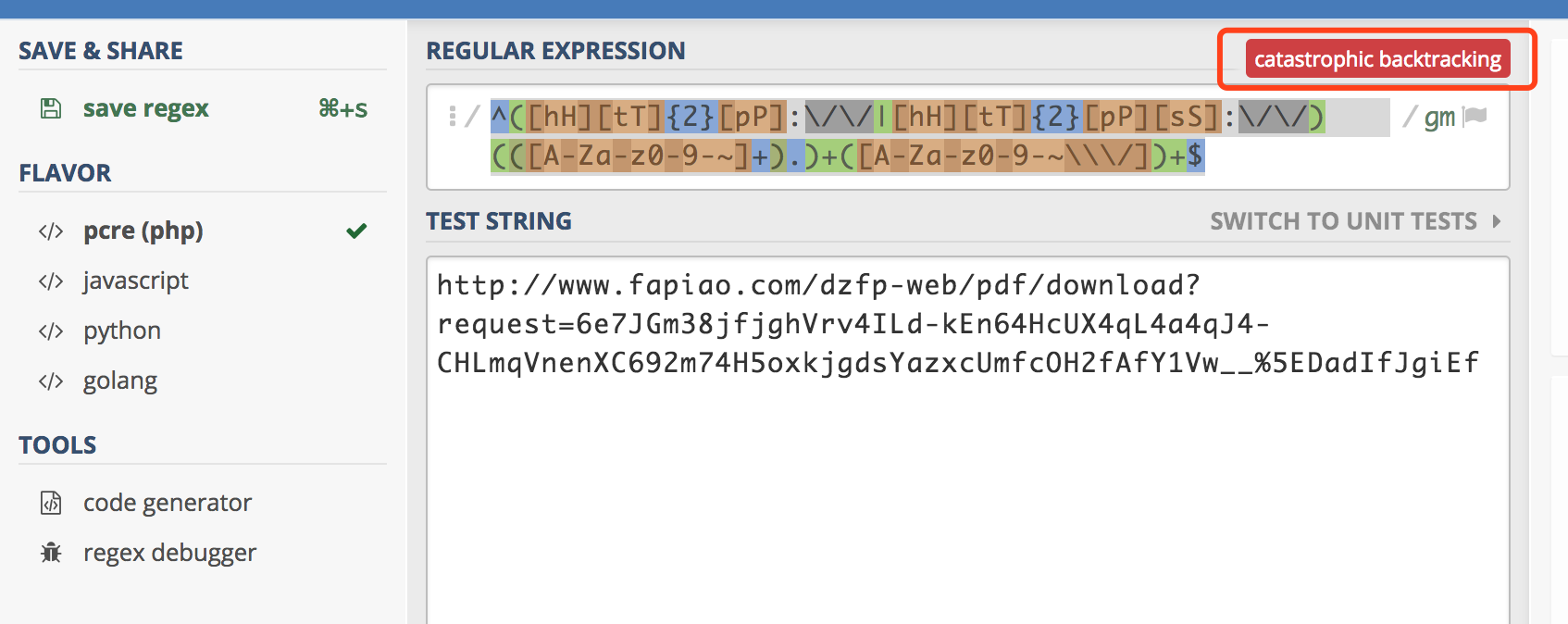
最后推荐一个网站,这个网站可以检查你写的正则表达式和对应的字符串匹配时会不会有问题。
Online regex tester and debugger: PHP, PCRE, Python, Golang and JavaScript
一个由正则表达式引发的血案 - 明志健致远 - 博客园
ps:这个文章对于 贪婪模式 懒惰模式 独占模式讲的很清晰,看完受益匪浅
也可以作为一个解决cpu 100%耗时问题的案例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号