
一、re 模块的使用过程
# 导入 re 模块 import re # 使用 match 方法进行匹配操作 # re.match() 能够匹配出以 xxx 开头的字符串 result = re.match(r'正则表达式', '被匹配的字符串') if result: # 如果上一步匹配到数据的话,可以使用 group 方法来提取数据 print(result.group()) else: print('匹配失败')
- Python 中字符串前面加上 r 表示原生字符串。与大多数编程语言相同,正则表达式里使用 “\” 作为转义字符,这就可能造成反斜杠困扰。
- Python 里的原生字符串很好地解决了这个问题,同时写出来的表达式也更直观。注意 r 只服务于 “\” ,不对其他进行转义。
二、正则表达式的字符匹配
1. 匹配开头结尾
| 字符 | 介绍 |
|---|---|
^ |
匹配字符串的开头 |
$ |
匹配字符串的末尾 |
2. 匹配单个字符
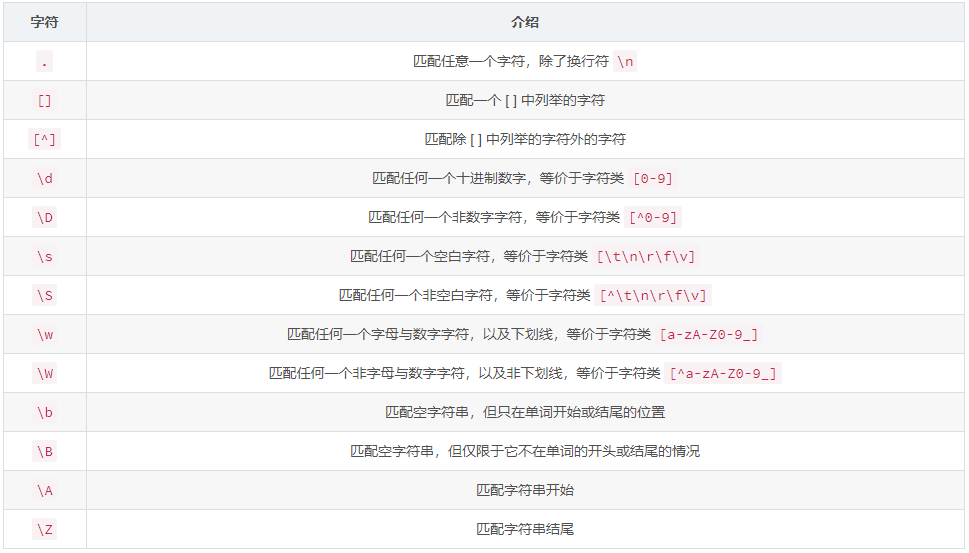
- \ 是转义特殊字符,\n 代表换行、\r 代表回车、\f 代表换页、\t 代表 Tab 键
- 通过用 ‘-’ 将两个字符连起来可以表示字符范围,比如:
- [a-z] 将匹配任何小写 ASCII 字符, [0-5][0-9] 将匹配从 00 到 59 的两位数字,[0-9A-Fa-f] 将匹配任何十六进制数位。
- 如果 - 进行了转义 (比如 [a\-z])或者它的位置在首位或末尾(如 [-a] 或 [a-]),那么它就只表示普通字符 ‘-’
- 除反斜杠外的特殊字符在 [ ] 中会失去其特殊含义,例如:[(+*)] 将匹配字符为 ( + * 或 ) 中的任何一个
3. 匹配多个字符
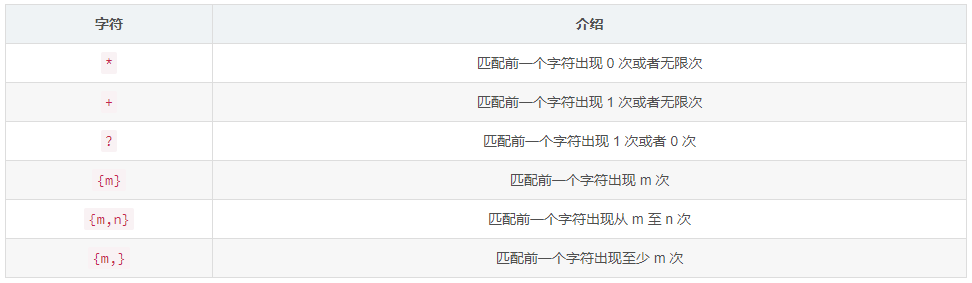
- ab* 会匹配 ‘a’,‘ab’,或者 ‘a’ 后面跟随任意个 ‘b’
- ab+ 会匹配 ‘a’ 后面跟随 1 个以上到任意个 ‘b’,它不会匹配 ‘a’
- ab? 会匹配 ‘a’ 或者 ‘ab’
- a{6} 将匹配 6 个 ‘a’ , 少于 6 个的话就会导致匹配失败
- a{3,5} 将匹配 3 到 5 个 ‘a’
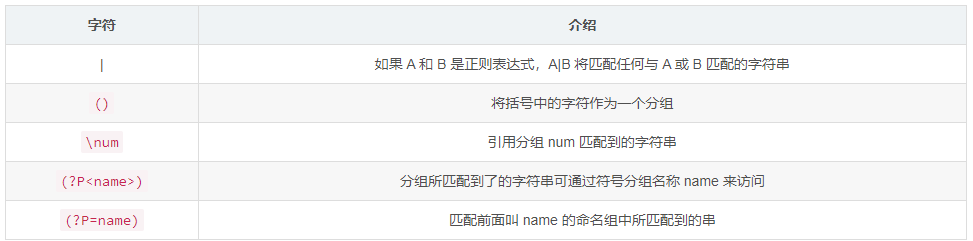
4. 匹配分组
5. Python 代码示例
- 匹配出 126、163、qq 的邮箱地址,且 @ 符号之前有 4 到 20 位数字、大写或小写字母和下划线的组合。
import re email_list = ["Alice27@163.com", "Sam_1122@gmail.com", ".Tom_12@qq.com", "Bob_1988@qq.com.com", "Elowen@126.com", "Ice@qq.com", "nicetomeetyou@qq.com"] for email in email_list: ret = re.match(r"\w{4,20}@(163|126|qq)\.com$", email) if ret: print("%s 是符合规定的邮件地址 , 匹配后的结果是 : %s" % (email, ret.group())) else: print("%s 不符合要求" % email)
结果展示:
Alice27@163.com 是符合规定的邮件地址 , 匹配后的结果是 : Alice27@163.com Sam_1122@gmail.com 不符合要求 .Tom_12@qq.com 不符合要求 Bob_1988@qq.com.com 不符合要求 Elowen@126.com 是符合规定的邮件地址 , 匹配后的结果是 : Elowen@126.com Ice@qq.com 不符合要求 nicetomeetyou@qq.com 是符合规定的邮件地址 , 匹配后的结果是 : nicetomeetyou@qq.com
- 匹配 11 位不是以 4、7 结尾的手机号码:re.match(r"1\d{9}[0-35-68-9]$", tel)
- 提取区号和电话号码:ret = re.match(r"([^-]+)-(\d+)","010-12345678") ,此时 ret.group(1) = ‘010’ ,ret.group(2) = ‘12345678’ ,ret.group(0) 等价于 ret.group() 等于 ‘010-12345678’
- 匹配标签,例如:匹配 <html><h1>hello</h1></html> 并提取出 hello
import re texts = ['<html><h1>hello</h1></html>', '<html><h1>world</h1></html1html>', '<html><h1>hello</h2></html>'] def match(): for text in texts: ret = re.match(r'<([a-zA-Z]*)><([a-zA-Z0-9]*)>(\w*)</\2></\1>', text) if ret: print(f'匹配成功,标签为 {ret.group()},信息为 {ret.group(3)}') else: print(f'{text} 标签匹配失败') if __name__ == '__main__': match()
结果展示:
匹配成功,标签为 <html><h1>hello</h1></html>,信息为 hello <html><h1>world</h1></html1html> 标签匹配失败 <html><h1>hello</h2></html> 标签匹配失败
用 (?P<name>) 和 (?P=name) 改进上述示例:
re.match(r'<(?P<name1>[a-zA-Z]*)><(?P<name2>[a-zA-Z0-9]*)>(\w*)</(?P=name2)></(?P=name1)>', text)
注意:字母 P 要大写
三、re 模块的函数
1. 函数一览表
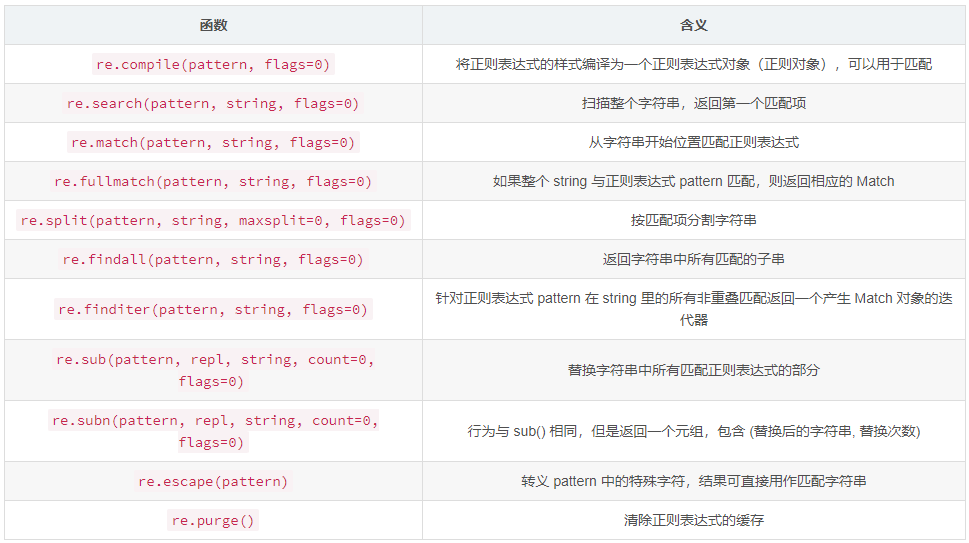
result = re.match(pattern, string) 等价于 prog = re.compile(pattern) 和 result = prog.match(string) 。
re.split 函数中如果 maxsplit 非零,则最多进行 maxsplit 次分隔,剩下的字符全部返回到列表的最后一个元素。
2. Python 代码示例
1)search 与 finditer
需求:匹配出文章阅读的次数和点赞的次数。
import re def find_second_match(pattern, text): matches = re.finditer(pattern, text) try: next(matches) # 跳过第一个匹配项 second_match = next(matches) # 获取第二个匹配项 return second_match.group() except StopIteration: return None if __name__ == '__main__': p = r"\d+" t = "阅读次数为 9999 , 点赞次数为 19999" ret = re.search(p, t) print(f'阅读次数为 {ret.group()} , 点赞次数为 {find_second_match(p, t)}')
结果展示:
阅读次数为 9999 , 点赞次数为 19999
2)findall
- 需求:统计出相应文章阅读、点赞和收藏的次数。
import re ret = re.findall(r"\d+", "read = 9999, thumbs up = 7890, collection = 12345") print(f'阅读次数 {ret[0]} ,点赞次数 {ret[1]} ,收藏次数 {ret[2]}')
结果展示:
阅读次数 9999 ,点赞次数 7890 ,收藏次数 12345
【拓展】:分组() 内加入 ?: 可以避免只返回分组内的内容。
- 需求:提取出字符串里的日期和时间 。
import re if __name__ == '__main__': s = 'hello world, now is 2020/7/20 18:48, 现在是 2020年7月20日18时48分。' ret_s = re.sub(r'年|月', r'/', s) ret_s = re.sub(r'日|分', r' ', ret_s) ret_s = re.sub(r'时', r':', ret_s) # hello world, now is 2020/7/20 18:48, 现在是 2020/7/20 18:48 。 print(ret_s) # findall com1 = re.compile(r'\d{4}/[01]?[0-9]/[1-3]?[0-9]\s(0[0-9]|1[0-9]|2[0-4])\:[0-5][0-9]') ret1 = com1.findall(ret_s) print(ret1[0]) # 18 # 加 ?: com2 = re.compile(r'\d{4}/[01]?[0-9]/[1-3]?[0-9]\s(?:0[0-9]|1[0-9]|2[0-4])\:[0-5][0-9]') ret2 = com2.findall(ret_s) print(ret2[0]) # 2020/7/20 18:48 # search ret3 = re.search(r'\d{4}/[01]?[0-9]/[1-3]?[0-9]\s(0[0-9]|1[0-9]|2[0-4])\:[0-5][0-9]', ret_s) print(ret3.group()) # 2020/7/20 18:48
3)sub
将匹配到的数据进行替换。
- 需求:将匹配到的阅读次数加 1 。
import re def add(temp): str_num = temp.group() num = int(str_num) + 1 return str(num) if __name__ == '__main__': ret = re.sub(r"\d+", '998', "thumbs up = 997") print(ret) ret = re.sub(r"\d+", add, "thumbs up = 997") print(ret) ret = re.sub(r"\d+", lambda x: str(int(x.group()) + 1), "thumbs up = 997") print(ret) print('-' * 30) # count 替换次数 text = "apple apple apple apple" pattern = r"apple" replacement = "orange" new_text = re.sub(pattern, replacement, text, count=2) print(new_text)
结果展示:
thumbs up = 998 thumbs up = 998 thumbs up = 998 ------------------------------ orange orange apple apple
- 需求:删除字符串中所有的 HTML 标签和
实体,只留下纯文本内容。
import re if __name__ == '__main__': text = ('<div>' + '\n' + '<p>岗位职责:</p>' + '\n' + '<p>完成推荐算法、数据统计、接口、后台等服务器端相关工作</p>' + '\n' + '<p><br></p>' + '\n' + '<p>必备要求:</p>' + '\n' + '<p>良好的自我驱动力和职业素养,工作积极主动、结果导向</p>' + '\n' + '<p> <br></p>' + '\n' + '<p>技术要求:</p>' + '\n' + '<p>1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式</p>' + '\n' + '<p>2、掌握 HTTP 协议,熟悉 MVC、MVVM 等概念以及相关 WEB 开发框架</p>' + '\n' + '<p>3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种<br></p>' + '\n' + '<p>4、掌握 NoSQL、MQ,熟练使用对应技术解决方案</p>' + '\n' + '<p>5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js</p>' + '\n' + '<p> <br></p>' + '\n' + '<p>加分项:</p>' + '\n' + '<p>大数据,数理统计,机器学习,sklearn,高性能,大并发。</p>' + '\n' + '</div>') # print(text) sub_result = re.sub(r"<[^>]*>| ", "", text) print(sub_result)
结果展示:
岗位职责: 完成推荐算法、数据统计、接口、后台等服务器端相关工作 必备要求: 良好的自我驱动力和职业素养,工作积极主动、结果导向 技术要求: 1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式 2、掌握 HTTP 协议,熟悉 MVC、MVVM 等概念以及相关 WEB 开发框架 3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种 4、掌握 NoSQL、MQ,熟练使用对应技术解决方案 5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js 加分项: 大数据,数理统计,机器学习,sklearn,高性能,大并发。
解析正则表达式:r"<[^>]*>| "
- <[^>]*> :匹配一对尖括号 < > 及其内部内容,且内容不包含 > 符号,表示匹配 HTML 标签,比如 <div>, <a href=“…”> 等。
- | :表示 “或” 操作符。
- :匹配 HTML 的不间断空格实体 。
- 替换字符串是 “” ,即将匹配的内容替换为空字符串(删除)。
4)split
根据匹配进行切割字符串,并返回一个列表。需求:切割字符串 “info:xiaoZhang 33 shandong” 。
import re ret = re.split(r":| ","info:xiaoZhang 33 shandong") print(ret)
结果展示:
['info', 'xiaoZhang', '33', 'shandong']
四、贪婪与非贪婪
Python 里数量词默认是贪婪的,即总是尝试匹配尽可能多的字符,而非贪婪则相反,总是尝试匹配尽可能少的字符。
可以在 * , ? , + , {m,n} 后面加上非贪婪操作符 ? ,该操作符要求正则匹配的字符越少越好,因而可以将贪婪转变为非贪婪。
Python 代码示例:
import re if __name__ == '__main__': s = "This is a number 234-235-22-423" # 贪婪 print(re.match(r".+(\d+-\d+-\d+-\d+)", s).group(1)) print(re.match(r"aa(\d+)", "aa2343ddd").group(1)) print(re.match(r"aa(\d+)ddd", "aa2343ddd").group(1)) print('-' * 30) # 非贪婪 print(re.match(r".+?(\d+-\d+-\d+-\d+)", s).group(1)) print(re.match(r"aa(\d+?)", "aa2343ddd").group(1)) print(re.match(r"aa(\d+?)ddd", "aa2343ddd").group(1))
结果展示:
4-235-22-423 2343 2343 ------------------------------ 234-235-22-423 2 2343
五、re 模块的可选标志
Python 代码示例:
import re if __name__ == '__main__': s1 = 'hello\nworld' ret1 = re.match(r'hello.W', s1, re.S | re.I) if ret1: print(ret1.group()) # hello w else: print('no match') print('-' * 15) s2 = 'hello你好world' ret2 = re.match(r'hello\w*', s2, re.A) if ret2: print(ret2.group()) # hello else: print('no match')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号