
安装
pip install requests
Get/Post示例
发送Get请求
response = requests.get(url)
发送Post请求
response = requests.post(url)
求例
r = requests.get("https://www.baidu.com")
print(r.text)
请示直接被拒绝了。
查看 https://www.zhihu.com ,随便打开一篇文章,按F12查看请求头
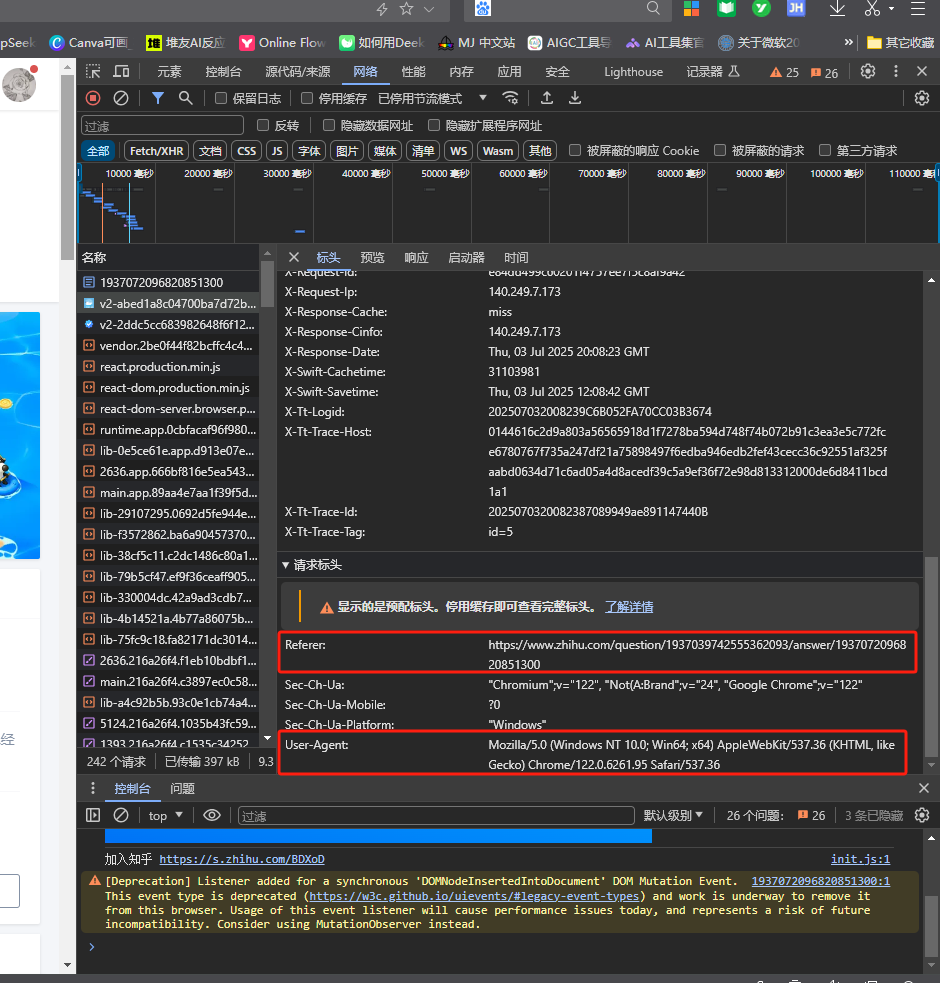
模仿知乎的请求,封装请求头
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.95 Safari/537.36",
"Referer": "https://www.zhihu.com/"
}
r = requests.get(" https://www.zhihu.com/question/1937039742555362093/answer/1937072096820851300 ,headers=headers")
print(r.text)
其他请示头
- headers={} 请求头
- params={} 请求内容
- stream=true 字节流下载,专用于下载资源文件
- timeout=10 超时时间10秒,如果超时会抛出异常 requests.exceptions.ReadTimeout
- proxies={} 设置代理
- verify=False 不强制认证,关闭ssl证书认证机制
- data={} 模拟form表单数据
- files 上传文件
返回结果response的解析
- response.encoding 判断网页的编码,可能误判
- response.text 返回源码,会自己选择编码进行解析,有时候编码方式误判会导致乱码
- response.status_code 返回请求状态码,200请求成功,
10*正在请求中,3** 重定向,400** 请求失败,500** 服务器错误 - response.content 返回源码
- response.content.decode("utf-8") 对源码自定义解码
- response.cookie 查看cookie
- response.json() 结果转成json对象,字典dic
可以使用python自带的json模块操作json数据
import json
result = json.loads(text) #把字符串转成json格式对象
str = json.dumps(infos) #把python数据对象转换成json字符串
设置代理
url = "http://httpbin.org/get"
proxies={
"http":"12.85.175.238:9999",
"https":"113.121.23.15:9999"
}
response = requests.get(url,proxies=proxies,timeout=10)
print(response.text)
若你的代理需要使用HTTP Basic Auth,可以使用 http://user:password@host/ 语法:
proxies = {
"http": "http://user:pass@10.10.1.10:3128/",
}
文件的上传和下载
r=requests.get(url,stream=True)
with open("1.jpg",'wb') as file:
for j in r.iter_content(1024): #每次读取1024字节
file.write(j)
上传示例:
fp=open("1.jpg",'rb')
files={
"img":fp
}
r=requests.post(url,files=files)
获取登录后的cookie数据
response.cookies
设置请求的cookies
cookies={
"name":"value",
"key1":"value1"
}
response = requests.get(url,cookies=cookies)
session
session的作用类似浏览器的功能,能保存用户操作出现的cookie数据,当用户再次发起请求时,会带上之前保存的cookie数据,就不需要显示地自己每次请求都设置cookies的值。
第一次访问时设置了cookie
response = requests.get(url,cookies=cookies)
s=requests.session()
使用session去再次发起post请求时,不需要带上cookie数据,就能请求成功
s.post(url,headers=headers)
如果请求登录结果,response中有set保存cookie操作的时候,session也会自动保存cookie数据。不需要自己手动获取cookie,再传入到request的请求里,方便连续的操作。
爬虫示例
-- coding: UTF-8 --
import requests,re,os
url = "http://www.xxxxx.com/index.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Referer": "http://www.xiaohuar.com/list-2-7.html"
}
response = requests.get(url,headers=headers)
正则匹配图片数据
matchObj=re.findall('',response.text)
print(matchObj)
if os.path.isdir("./images") == False:
os.makedirs("images")
for hua in matchObj:
# print(hua[0],hua[1])
img_url = hua[1]
# 图片地址不同意处理
if img_url.find("http://") == -1:
img_url="http://www.xiaohuar.com"+hua[1]
# 二进制流请求图片信息
r = requests.get(img_url,headers=headers,stream=True)
with open("./images/"+hua[0]+".jpg","wb") as file:
for j in r.iter_content(10240):
file.write(j)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号